 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Variational Autoencoder for Disentanglement Learning
Apr 02, 2020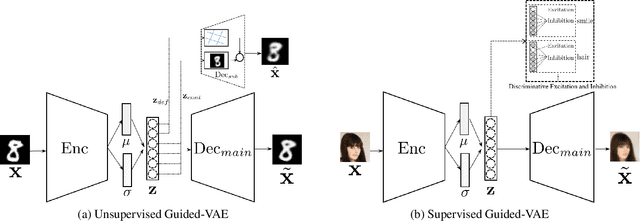
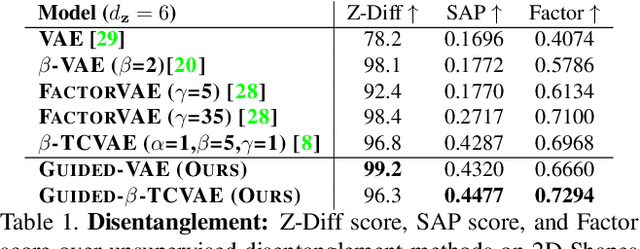

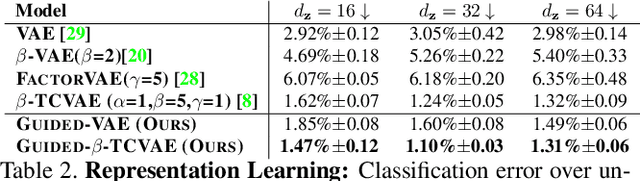
We propose an algorithm, guided variational autoencoder (Guided-VAE), that is able to learn a controllable generative model by performing latent representation disentanglement learning. The learning objective is achieved by providing signals to the latent encoding/embedding in VAE without changing its main backbone architecture, hence retaining the desirable properties of the VAE. We design an unsupervised strategy and a supervised strategy in Guided-VAE and observe enhanced modeling and controlling capability over the vanilla VAE. In the unsupervised strategy, we guide the VAE learning by introducing a lightweight decoder that learns latent geometric transformation and principal components; in the supervised strategy, we use an adversarial excitation and inhibition mechanism to encourage the disentanglement of the latent variables. Guided-VAE enjoys its transparency and simplicity for the general representation learning task, as well as disentanglement learning. On a number of experiments for representation learning, improved synthesis/sampling, better disentanglement for classification, and reduced classification errors in meta-learning have been observed.
Neural Program Synthesis By Self-Learning
Oct 13, 2019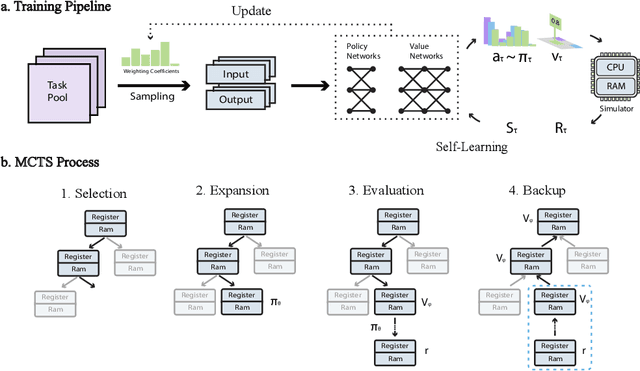
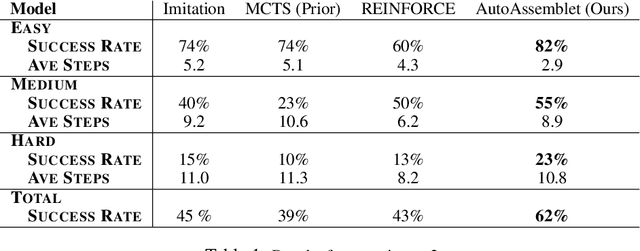

Neural inductive program synthesis is a task generating instructions that can produce desired outputs from given inputs. In this paper, we focus on the generation of a chunk of assembly code that can be executed to match a state change inside the CPU and RAM. We develop a neural program synthesis algorithm, AutoAssemblet, learned via self-learning reinforcement learning that explores the large code space efficiently. Policy networks and value networks are learned to reduce the breadth and depth of the Monte Carlo Tree Search, resulting in better synthesis performance. We also propose an effective multi-entropy policy sampling technique to alleviate online update correlations. We apply AutoAssemblet to basic programming tasks and show significant higher success rates compared to several competing baselines.
Rethinking Exposure Bias In Language Modeling
Oct 13, 2019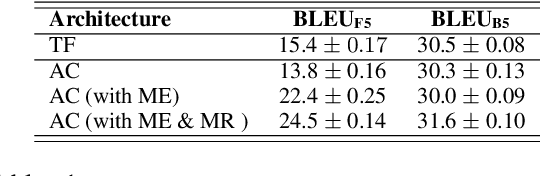
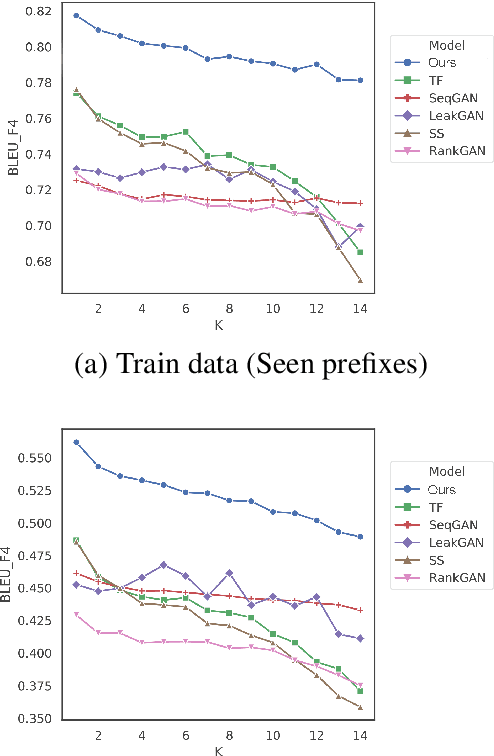


Exposure bias describes the phenomenon that a language model trained under the teacher forcing schema may perform poorly at the inference stage when its predictions are conditioned on its previous predictions unseen from the training corpus. Recently, several generative adversarial networks (GANs) and reinforcement learning (RL) methods have been introduced to alleviate this problem. Nonetheless, a common issue in RL and GANs training is the sparsity of reward signals. In this paper, we adopt two simple strategies, multi-range reinforcing, and multi-entropy sampling, to amplify and denoise the reward signal. Our model produces an improvement over competing models with regards to BLEU scores and road exam, a new metric we designed to measure the robustness against exposure bias in language models.
Unaligned Image-to-Sequence Transformation with Loop Consistency
Oct 09, 2019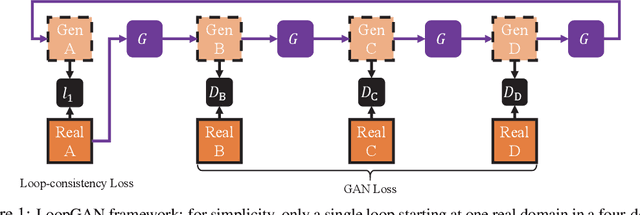
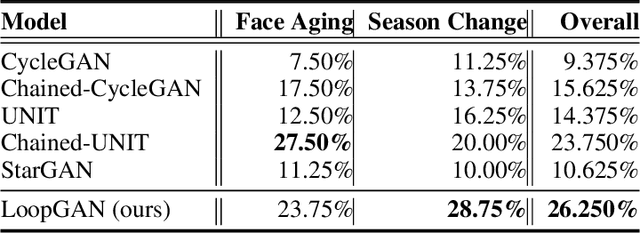
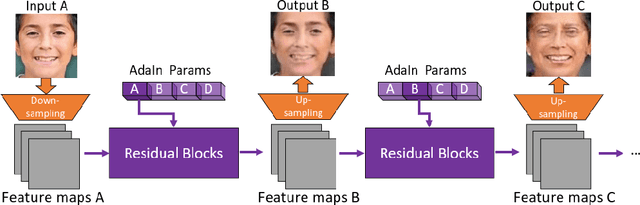

We tackle the problem of modeling sequential visual phenomena. Given examples of a phenomena that can be divided into discrete time steps, we aim to take an input from any such time and realize this input at all other time steps in the sequence. Furthermore, we aim to do this without ground-truth aligned sequences -- avoiding the difficulties needed for gathering aligned data. This generalizes the unpaired image-to-image problem from generating pairs to generating sequences. We extend cycle consistency to loop consistency and alleviate difficulties associated with learning in the resulting long chains of computation. We show competitive results compared to existing image-to-image techniques when modeling several different data sets including the Earth's seasons and aging of human faces.
Learning Instance Occlusion for Panoptic Segmentation
Jun 13, 2019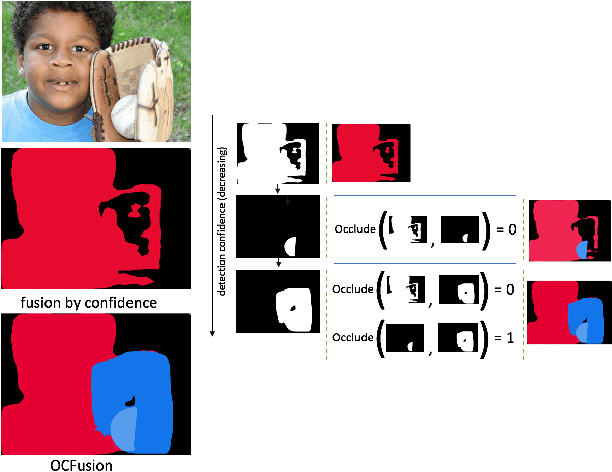
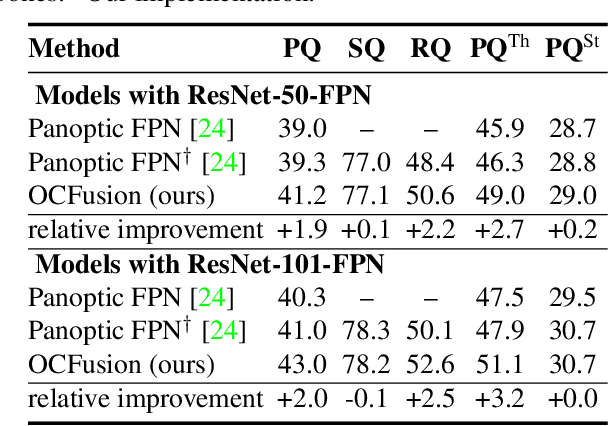

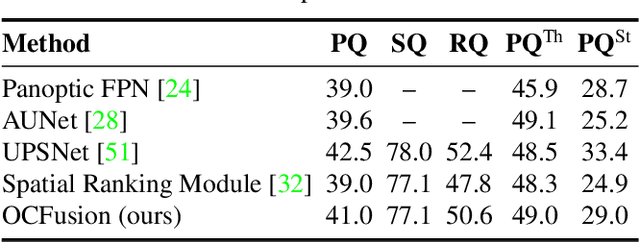
Recently, the vision community has shown renewed interest in the effort of panoptic segmentation --- previously known as image parsing. While a large amount of progress has been made within both the instance and semantic segmentation tasks separately, panoptic segmentation implies knowledge of both (countable) "things" and semantic "stuff" within a single output. A common approach involves the fusion of respective instance and semantic segmentations proposals, however, this method has not explicitly addressed the jump from instance segmentation to non-overlapping placement within a single output and often fails to layout overlapping instances adequately. We propose a straightforward extension to the Mask R-CNN framework that is tasked with resolving how two instance masks should overlap one another in the fused output as a binary relation. We show competitive increases in overall panoptic quality (PQ) and particular gains in the "things" portion of the standard panoptic segmentation benchmark, reaching state-of-the-art against methods with comparable architectures.
Controllable Top-down Feature Transformer
Nov 04, 2018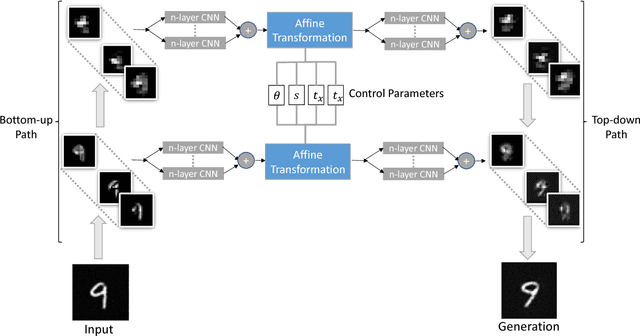
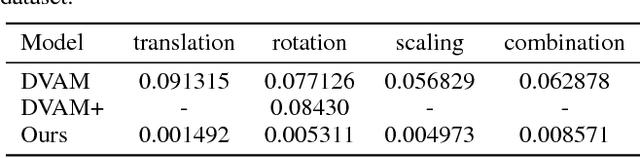
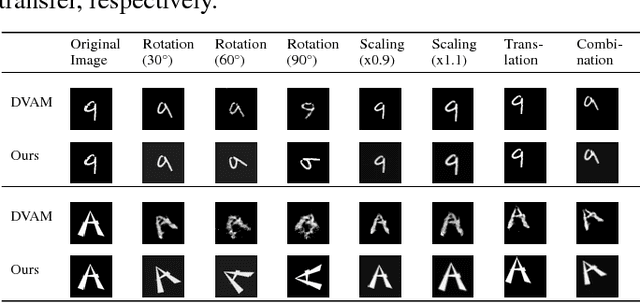

We study the intrinsic transformation of feature maps across convolutional network layers with explicit top-down control. To this end, we develop top-down feature transformer (TFT), under controllable parameters, that are able to account for the hidden layer transformation while maintaining the overall consistency across layers. The learned generators capture the underlying feature transformation processes that are independent of particular training images. Our proposed TFT framework brings insights to and helps the understanding of, an important problem of studying the CNN internal feature representation and transformation under the top-down processes. In the case of spatial transformations, we demonstrate the significant advantage of TFT over existing data-driven approaches in building data-independent transformations. We also show that it can be adopted in other applications such as data augmentation and image style transfer.
Rethinking Spatiotemporal Feature Learning: Speed-Accuracy Trade-offs in Video Classification
Jul 27, 2018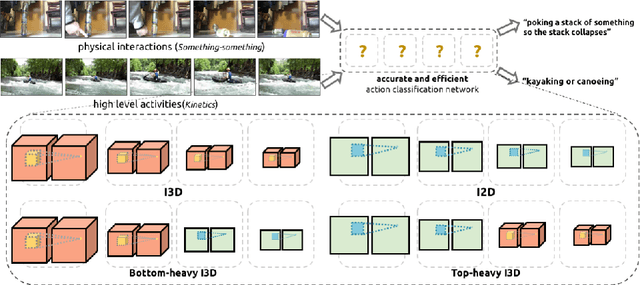
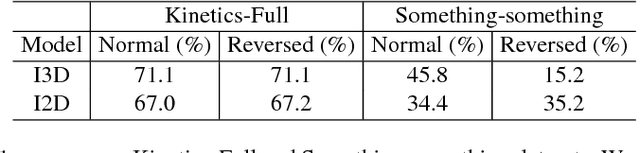
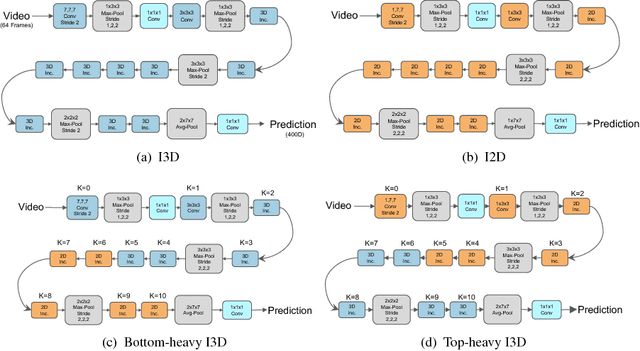
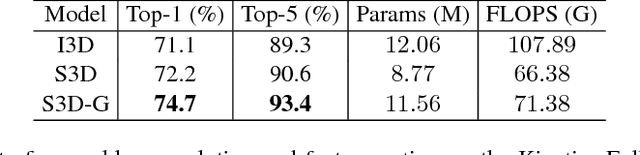
Despite the steady progress in video analysis led by the adoption of convolutional neural networks (CNNs), the relative improvement has been less drastic as that in 2D static image classification. Three main challenges exist including spatial (image) feature representation, temporal information representation, and model/computation complexity. It was recently shown by Carreira and Zisserman that 3D CNNs, inflated from 2D networks and pretrained on ImageNet, could be a promising way for spatial and temporal representation learning. However, as for model/computation complexity, 3D CNNs are much more expensive than 2D CNNs and prone to overfit. We seek a balance between speed and accuracy by building an effective and efficient video classification system through systematic exploration of critical network design choices. In particular, we show that it is possible to replace many of the 3D convolutions by low-cost 2D convolutions. Rather surprisingly, best result (in both speed and accuracy) is achieved when replacing the 3D convolutions at the bottom of the network, suggesting that temporal representation learning on high-level semantic features is more useful. Our conclusion generalizes to datasets with very different properties. When combined with several other cost-effective designs including separable spatial/temporal convolution and feature gating, our system results in an effective video classification system that that produces very competitive results on several action classification benchmarks (Kinetics, Something-something, UCF101 and HMDB), as well as two action detection (localization) benchmarks (JHMDB and UCF101-24).
Wasserstein Introspective Neural Networks
Apr 07, 2018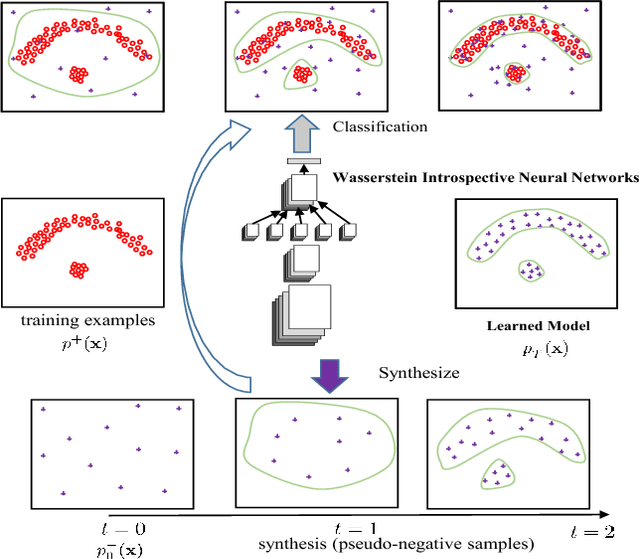
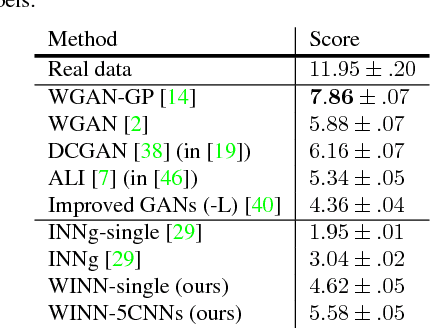

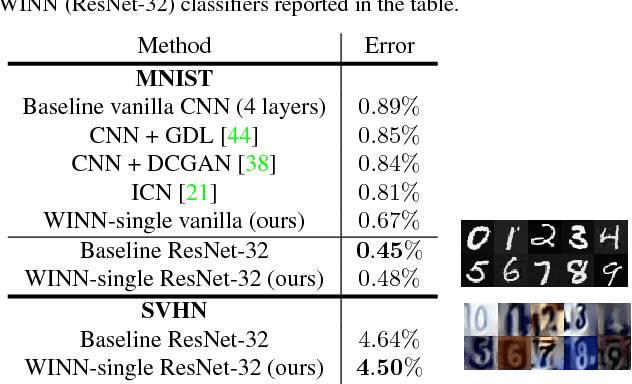
We present Wasserstein introspective neural networks (WINN) that are both a generator and a discriminator within a single model. WINN provides a significant improvement over the recent introspective neural networks (INN) method by enhancing INN's generative modeling capability. WINN has three interesting properties: (1) A mathematical connection between the formulation of the INN algorithm and that of Wasserstein generative adversarial networks (WGAN) is made. (2) The explicit adoption of the Wasserstein distance into INN results in a large enhancement to INN, achieving compelling results even with a single classifier --- e.g., providing nearly a 20 times reduction in model size over INN for unsupervised generative modeling. (3) When applied to supervised classification, WINN also gives rise to improved robustness against adversarial examples in terms of the error reduction. In the experiments, we report encouraging results on unsupervised learning problems including texture, face, and object modeling, as well as a supervised classification task against adversarial attacks.
Local Binary Pattern Networks
Mar 22, 2018
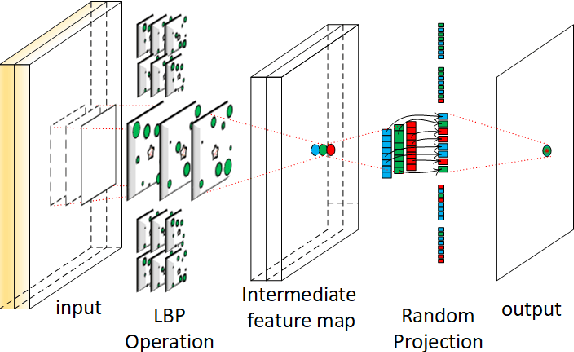
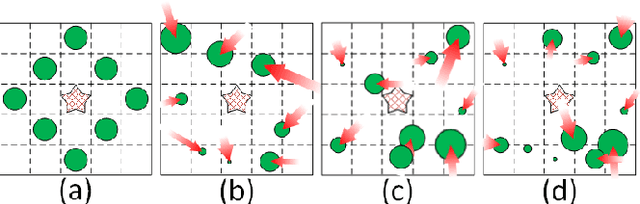
Memory and computation efficient deep learning architec- tures are crucial to continued proliferation of machine learning capabili- ties to new platforms and systems. Binarization of operations in convo- lutional neural networks has shown promising results in reducing model size and computing efficiency. In this paper, we tackle the problem us- ing a strategy different from the existing literature by proposing local binary pattern networks or LBPNet, that is able to learn and perform binary operations in an end-to-end fashion. LBPNet1 uses local binary comparisons and random projection in place of conventional convolu- tion (or approximation of convolution) operations. These operations can be implemented efficiently on different platforms including direct hard- ware implementation. We applied LBPNet and its variants on standard benchmarks. The results are promising across benchmarks while provid- ing an important means to improve memory and speed efficiency that is particularly suited for small footprint devices and hardware accelerators.
Deeply supervised salient object detection with short connections
Mar 16, 2018


Recent progress on saliency detection is substantial, benefiting mostly from the explosive development of Convolutional Neural Networks (CNNs). Semantic segmentation and saliency detection algorithms developed lately have been mostly based on Fully Convolutional Neural Networks (FCNs). There is still a large room for improvement over the generic FCN models that do not explicitly deal with the scale-space problem. Holistically-Nested Edge Detector (HED) provides a skip-layer structure with deep supervision for edge and boundary detection, but the performance gain of HED on salience detection is not obvious. In this paper, we propose a new method for saliency detection by introducing short connections to the skip-layer structures within the HED architecture. Our framework provides rich multi-scale feature maps at each layer, a property that is critically needed to perform segment detection. Our method produces state-of-the-art results on 5 widely tested salient object detection benchmarks, with advantages in terms of efficiency (0.15 seconds per image), effectiveness, and simplicity over the existing algorithms.
* IEEE TPAMI 2018 (IEEE CVPR 2017)