 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Regularized Competitive Equilibria of Heterogeneous Agent Macroeconomic Models with Reinforcement Learning
Feb 24, 2023

We study a heterogeneous agent macroeconomic model with an infinite number of households and firms competing in a labor market. Each household earns income and engages in consumption at each time step while aiming to maximize a concave utility subject to the underlying market conditions. The households aim to find the optimal saving strategy that maximizes their discounted cumulative utility given the market condition, while the firms determine the market conditions through maximizing corporate profit based on the household population behavior. The model captures a wide range of applications in macroeconomic studies, and we propose a data-driven reinforcement learning framework that finds the regularized competitive equilibrium of the model. The proposed algorithm enjoys theoretical guarantees in converging to the equilibrium of the market at a sub-linear rate.
Offline Policy Optimization in RL with Variance Regularizaton
Dec 29, 2022



Learning policies from fixed offline datasets is a key challenge to scale up reinforcement learning (RL) algorithms towards practical applications. This is often because off-policy RL algorithms suffer from distributional shift, due to mismatch between dataset and the target policy, leading to high variance and over-estimation of value functions. In this work, we propose variance regularization for offline RL algorithms, using stationary distribution corrections. We show that by using Fenchel duality, we can avoid double sampling issues for computing the gradient of the variance regularizer. The proposed algorithm for offline variance regularization (OVAR) can be used to augment any existing offline policy optimization algorithms. We show that the regularizer leads to a lower bound to the offline policy optimization objective, which can help avoid over-estimation errors, and explains the benefits of our approach across a range of continuous control domains when compared to existing state-of-the-art algorithms.
Offline Reinforcement Learning for Human-Guided Human-Machine Interaction with Private Information
Dec 23, 2022



Motivated by the human-machine interaction such as training chatbots for improving customer satisfaction, we study human-guided human-machine interaction involving private information. We model this interaction as a two-player turn-based game, where one player (Alice, a human) guides the other player (Bob, a machine) towards a common goal. Specifically, we focus on offline reinforcement learning (RL) in this game, where the goal is to find a policy pair for Alice and Bob that maximizes their expected total rewards based on an offline dataset collected a priori. The offline setting presents two challenges: (i) We cannot collect Bob's private information, leading to a confounding bias when using standard RL methods, and (ii) a distributional mismatch between the behavior policy used to collect data and the desired policy we aim to learn. To tackle the confounding bias, we treat Bob's previous action as an instrumental variable for Alice's current decision making so as to adjust for the unmeasured confounding. We develop a novel identification result and use it to propose a new off-policy evaluation (OPE) method for evaluating policy pairs in this two-player turn-based game. To tackle the distributional mismatch, we leverage the idea of pessimism and use our OPE method to develop an off-policy learning algorithm for finding a desirable policy pair for both Alice and Bob. Finally, we prove that under mild assumptions such as partial coverage of the offline data, the policy pair obtained through our method converges to the optimal one at a satisfactory rate.
Policy learning "without'' overlap: Pessimism and generalized empirical Bernstein's inequality
Dec 19, 2022



This paper studies offline policy learning, which aims at utilizing observations collected a priori (from either fixed or adaptively evolving behavior policies) to learn an optimal individualized decision rule that achieves the best overall outcomes for a given population. Existing policy learning methods rely on a uniform overlap assumption, i.e., the propensities of exploring all actions for all individual characteristics are lower bounded in the offline dataset; put differently, the performance of the existing methods depends on the worst-case propensity in the offline dataset. As one has no control over the data collection process, this assumption can be unrealistic in many situations, especially when the behavior policies are allowed to evolve over time with diminishing propensities for certain actions. In this paper, we propose a new algorithm that optimizes lower confidence bounds (LCBs) -- instead of point estimates -- of the policy values. The LCBs are constructed using knowledge of the behavior policies for collecting the offline data. Without assuming any uniform overlap condition, we establish a data-dependent upper bound for the suboptimality of our algorithm, which only depends on (i) the overlap for the optimal policy, and (ii) the complexity of the policy class we optimize over. As an implication, for adaptively collected data, we ensure efficient policy learning as long as the propensities for optimal actions are lower bounded over time, while those for suboptimal ones are allowed to diminish arbitrarily fast. In our theoretical analysis, we develop a new self-normalized type concentration inequality for inverse-propensity-weighting estimators, generalizing the well-known empirical Bernstein's inequality to unbounded and non-i.i.d. data.
The Sample Complexity of Online Contract Design
Nov 10, 2022We study the hidden-action principal-agent problem in an online setting. In each round, the principal posts a contract that specifies the payment to the agent based on each outcome. The agent then makes a strategic choice of action that maximizes her own utility, but the action is not directly observable by the principal. The principal observes the outcome and receives utility from the agent's choice of action. Based on past observations, the principal dynamically adjusts the contracts with the goal of maximizing her utility. We introduce an online learning algorithm and provide an upper bound on its Stackelberg regret. We show that when the contract space is $[0,1]^m$, the Stackelberg regret is upper bounded by $\widetilde O(\sqrt{m} \cdot T^{1-C/m})$, and lower bounded by $\Omega(T^{1-1/(m+2)})$. This result shows that exponential-in-$m$ samples are both sufficient and necessary to learn a near-optimal contract, resolving an open problem on the hardness of online contract design. When contracts are restricted to some subset $\mathcal{F} \subset [0,1]^m$, we define an intrinsic dimension of $\mathcal{F}$ that depends on the covering number of the spherical code in the space and bound the regret in terms of this intrinsic dimension. When $\mathcal{F}$ is the family of linear contracts, the Stackelberg regret grows exactly as $\Theta(T^{2/3})$. The contract design problem is challenging because the utility function is discontinuous. Bounding the discretization error in this setting has been an open problem. In this paper, we identify a limited set of directions in which the utility function is continuous, allowing us to design a new discretization method and bound its error. This approach enables the first upper bound with no restrictions on the contract and action space.
A Posterior Sampling Framework for Interactive Decision Making
Nov 03, 2022

We study sample efficient reinforcement learning (RL) under the general framework of interactive decision making, which includes Markov decision process (MDP), partially observable Markov decision process (POMDP), and predictive state representation (PSR) as special cases. Toward finding the minimum assumption that empowers sample efficient learning, we propose a novel complexity measure, generalized eluder coefficient (GEC), which characterizes the fundamental tradeoff between exploration and exploitation in online interactive decision making. In specific, GEC captures the hardness of exploration by comparing the error of predicting the performance of the updated policy with the in-sample training error evaluated on the historical data. We show that RL problems with low GEC form a remarkably rich class, which subsumes low Bellman eluder dimension problems, bilinear class, low witness rank problems, PO-bilinear class, and generalized regular PSR, where generalized regular PSR, a new tractable PSR class identified by us, includes nearly all known tractable POMDPs. Furthermore, in terms of algorithm design, we propose a generic posterior sampling algorithm, which can be implemented in both model-free and model-based fashion, under both fully observable and partially observable settings. The proposed algorithm modifies the standard posterior sampling algorithm in two aspects: (i) we use an optimistic prior distribution that biases towards hypotheses with higher values and (ii) a loglikelihood function is set to be the empirical loss evaluated on the historical data, where the choice of loss function supports both model-free and model-based learning. We prove that the proposed algorithm is sample efficient by establishing a sublinear regret upper bound in terms of GEC. In summary, we provide a new and unified understanding of both fully observable and partially observable RL.
A Reinforcement Learning Approach in Multi-Phase Second-Price Auction Design
Oct 19, 2022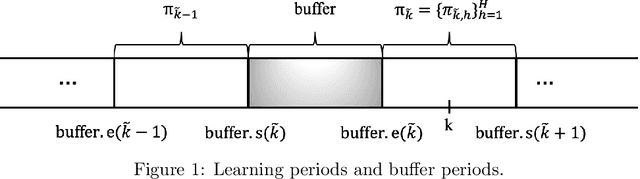
We study reserve price optimization in multi-phase second price auctions, where seller's prior actions affect the bidders' later valuations through a Markov Decision Process (MDP). Compared to the bandit setting in existing works, the setting in ours involves three challenges. First, from the seller's perspective, we need to efficiently explore the environment in the presence of potentially nontruthful bidders who aim to manipulates seller's policy. Second, we want to minimize the seller's revenue regret when the market noise distribution is unknown. Third, the seller's per-step revenue is unknown, nonlinear, and cannot even be directly observed from the environment. We propose a mechanism addressing all three challenges. To address the first challenge, we use a combination of a new technique named "buffer periods" and inspirations from Reinforcement Learning (RL) with low switching cost to limit bidders' surplus from untruthful bidding, thereby incentivizing approximately truthful bidding. The second one is tackled by a novel algorithm that removes the need for pure exploration when the market noise distribution is unknown. The third challenge is resolved by an extension of LSVI-UCB, where we use the auction's underlying structure to control the uncertainty of the revenue function. The three techniques culminate in the $\underline{\rm C}$ontextual-$\underline{\rm L}$SVI-$\underline{\rm U}$CB-$\underline{\rm B}$uffer (CLUB) algorithm which achieves $\tilde{ \mathcal{O}}(H^{5/2}\sqrt{K})$ revenue regret when the market noise is known and $\tilde{ \mathcal{O}}(H^{3}\sqrt{K})$ revenue regret when the noise is unknown with no assumptions on bidders' truthfulness.
Enforcing Hard Constraints with Soft Barriers: Safe Reinforcement Learning in Unknown Stochastic Environments
Sep 29, 2022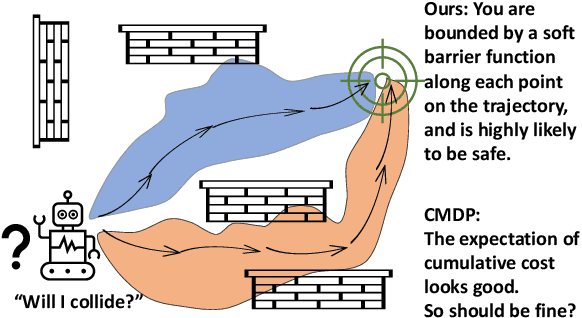
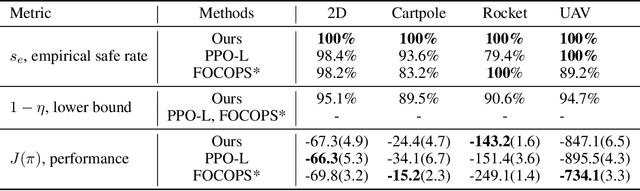
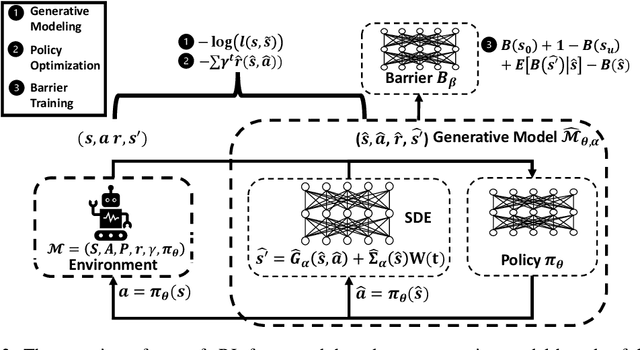
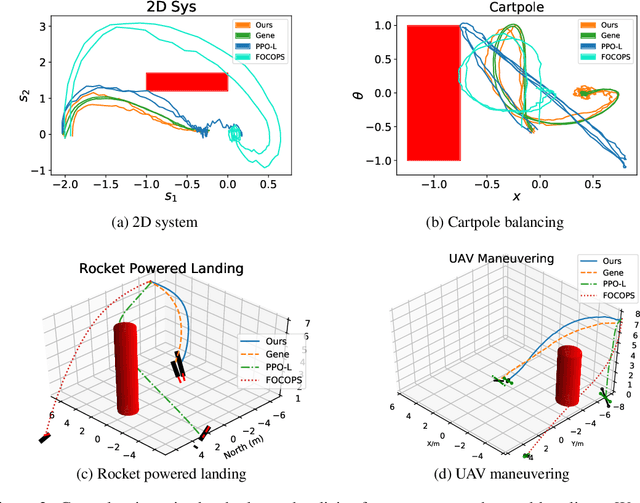
It is quite challenging to ensure the safety of reinforcement learning (RL) agents in an unknown and stochastic environment under hard constraints that require the system state not to reach certain specified unsafe regions. Many popular safe RL methods such as those based on the Constrained Markov Decision Process (CMDP) paradigm formulate safety violations in a cost function and try to constrain the expectation of cumulative cost under a threshold. However, it is often difficult to effectively capture and enforce hard reachability-based safety constraints indirectly with such constraints on safety violation costs. In this work, we leverage the notion of barrier function to explicitly encode the hard safety constraints, and given that the environment is unknown, relax them to our design of \emph{generative-model-based soft barrier functions}. Based on such soft barriers, we propose a safe RL approach that can jointly learn the environment and optimize the control policy, while effectively avoiding unsafe regions with safety probability optimization. Experiments on a set of examples demonstrate that our approach can effectively enforce hard safety constraints and significantly outperform CMDP-based baseline methods in system safe rate measured via simulations.
Relational Reasoning via Set Transformers: Provable Efficiency and Applications to MARL
Sep 26, 2022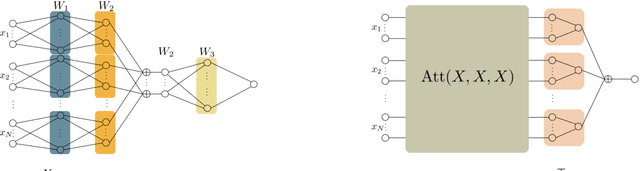
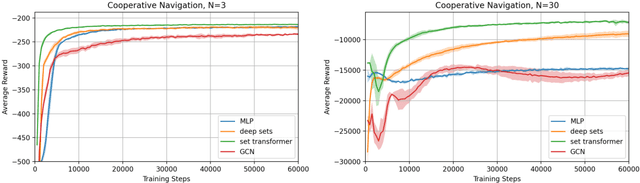
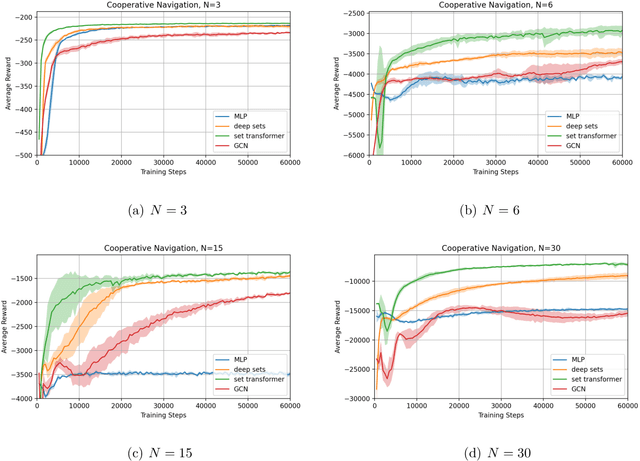
The cooperative Multi-A gent R einforcement Learning (MARL) with permutation invariant agents framework has achieved tremendous empirical successes in real-world applications. Unfortunately, the theoretical understanding of this MARL problem is lacking due to the curse of many agents and the limited exploration of the relational reasoning in existing works. In this paper, we verify that the transformer implements complex relational reasoning, and we propose and analyze model-free and model-based offline MARL algorithms with the transformer approximators. We prove that the suboptimality gaps of the model-free and model-based algorithms are independent of and logarithmic in the number of agents respectively, which mitigates the curse of many agents. These results are consequences of a novel generalization error bound of the transformer and a novel analysis of the Maximum Likelihood Estimate (MLE) of the system dynamics with the transformer. Our model-based algorithm is the first provably efficient MARL algorithm that explicitly exploits the permutation invariance of the agents.
Offline Reinforcement Learning with Instrumental Variables in Confounded Markov Decision Processes
Sep 18, 2022
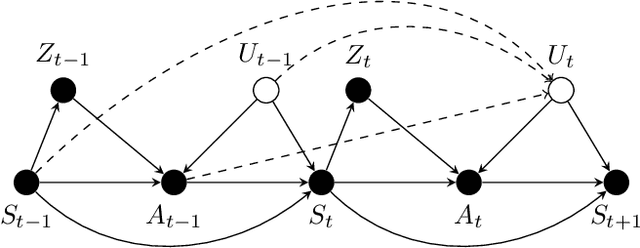
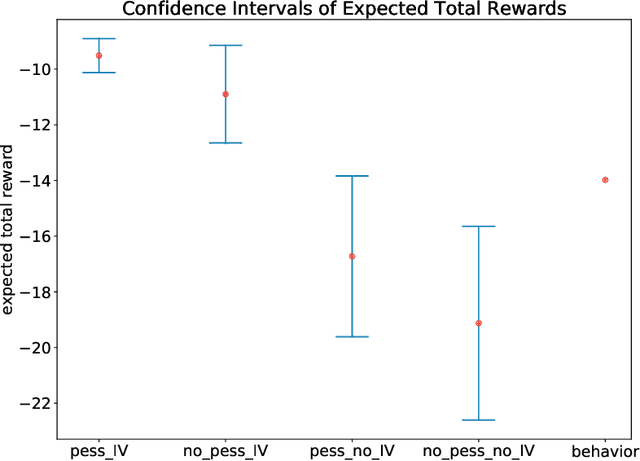
We study the offline reinforcement learning (RL) in the face of unmeasured confounders. Due to the lack of online interaction with the environment, offline RL is facing the following two significant challenges: (i) the agent may be confounded by the unobserved state variables; (ii) the offline data collected a prior does not provide sufficient coverage for the environment. To tackle the above challenges, we study the policy learning in the confounded MDPs with the aid of instrumental variables. Specifically, we first establish value function (VF)-based and marginalized importance sampling (MIS)-based identification results for the expected total reward in the confounded MDPs. Then by leveraging pessimism and our identification results, we propose various policy learning methods with the finite-sample suboptimality guarantee of finding the optimal in-class policy under minimal data coverage and modeling assumptions. Lastly, our extensive theoretical investigations and one numerical study motivated by the kidney transplantation demonstrate the promising performance of the proposed methods.