 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinding Language Models in Symbolic Languages
Oct 06, 2022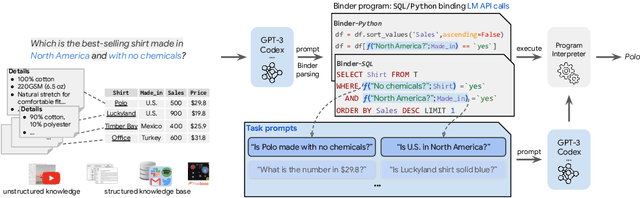
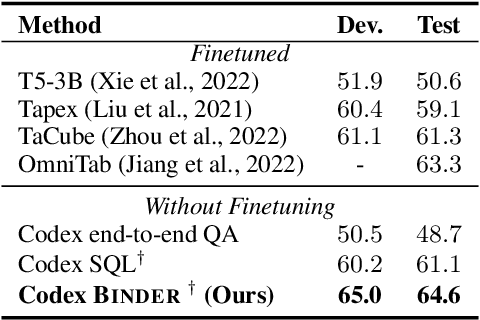

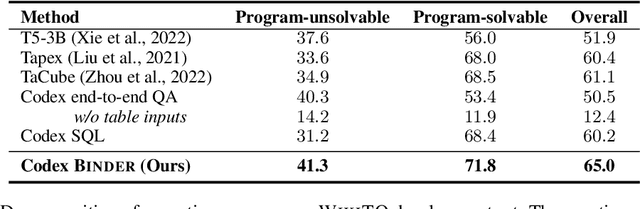
Though end-to-end neural approaches have recently been dominating NLP tasks in both performance and ease-of-use, they lack interpretability and robustness. We propose Binder, a training-free neural-symbolic framework that maps the task input to a program, which (1) allows binding a unified API of language model (LM) functionalities to a programming language (e.g., SQL, Python) to extend its grammar coverage and thus tackle more diverse questions, (2) adopts an LM as both the program parser and the underlying model called by the API during execution, and (3) requires only a few in-context exemplar annotations. Specifically, we employ GPT-3 Codex as the LM. In the parsing stage, with only a few in-context exemplars, Codex is able to identify the part of the task input that cannot be answerable by the original programming language, correctly generate API calls to prompt Codex to solve the unanswerable part, and identify where to place the API calls while being compatible with the original grammar. In the execution stage, Codex can perform versatile functionalities (e.g., commonsense QA, information extraction) given proper prompts in the API calls. Binder achieves state-of-the-art results on WikiTableQuestions and TabFact datasets, with explicit output programs that benefit human debugging. Note that previous best systems are all finetuned on tens of thousands of task-specific samples, while Binder only uses dozens of annotations as in-context exemplars without any training. Our code is available at https://github.com/HKUNLP/Binder .
TaCube: Pre-computing Data Cubes for Answering Numerical-Reasoning Questions over Tabular Data
May 25, 2022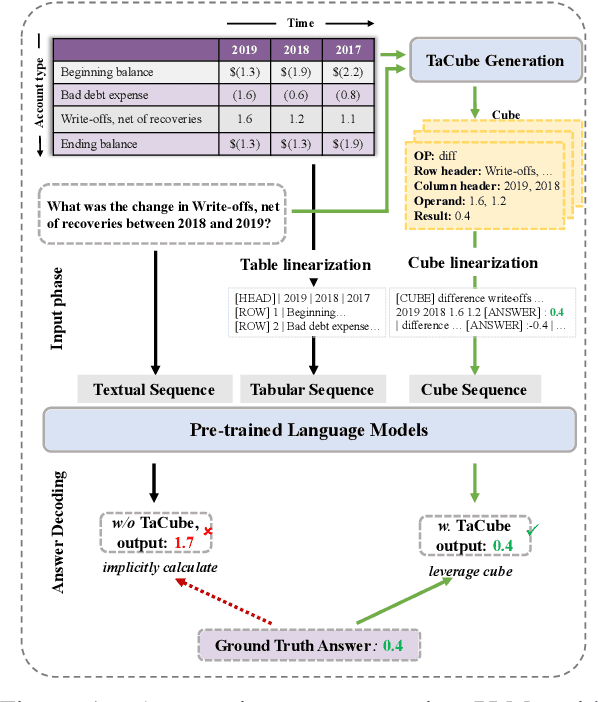

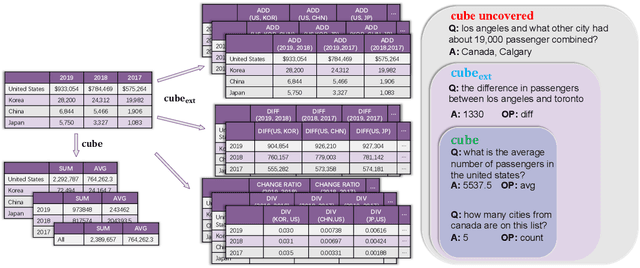
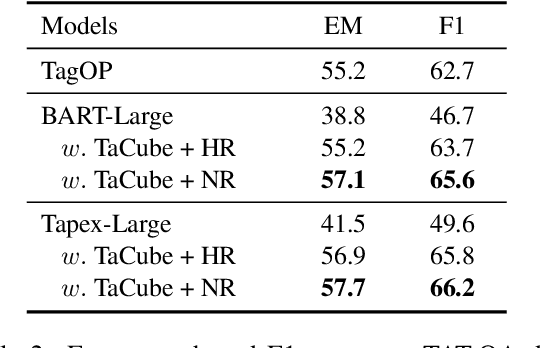
Existing auto-regressive pre-trained language models (PLMs) like T5 and BART, have been well applied to table question answering by UNIFIEDSKG and TAPEX, respectively, and demonstrated state-of-the-art results on multiple benchmarks. However, auto-regressive PLMs are challenged by recent emerging numerical reasoning datasets, such as TAT-QA, due to the error-prone implicit calculation. In this paper, we present TaCube, to pre-compute aggregation/arithmetic results for the table in advance, so that they are handy and readily available for PLMs to answer numerical reasoning questions. TaCube systematically and comprehensively covers a collection of computational operations over table segments. By simply concatenating TaCube to the input sequence of PLMs, it shows significant experimental effectiveness. TaCube promotes the F1 score from 49.6% to 66.2% on TAT-QA and achieves new state-of-the-art results on WikiTQ (59.6% denotation accuracy). TaCube's improvements on numerical reasoning cases are even more notable: on TAT-QA, TaCube promotes the exact match accuracy of BART-large by 39.6% on sum, 52.5% on average, 36.6% on substraction, and 22.2% on division. We believe that TaCube is a general and portable pre-computation solution that can be potentially integrated to various numerical reasoning frameworks
Table Pre-training: A Survey on Model Architectures, Pretraining Objectives, and Downstream Tasks
Jan 27, 2022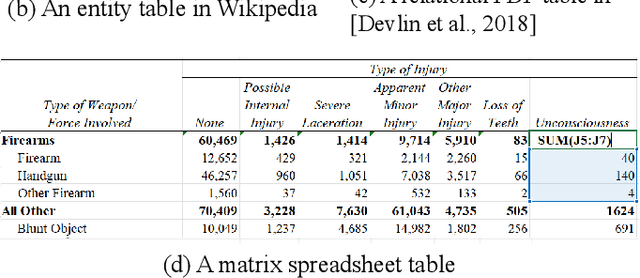


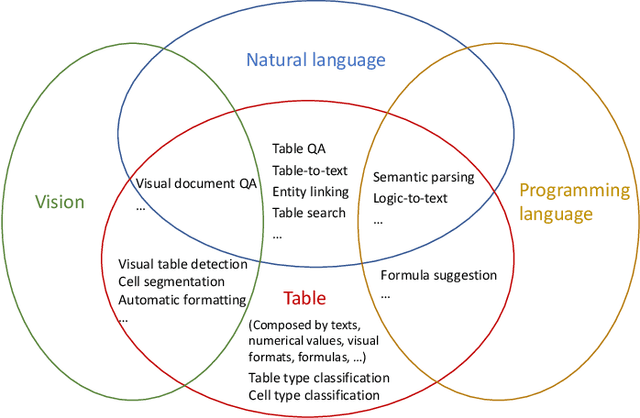
Since a vast number of tables can be easily collected from web pages, spreadsheets, PDFs, and various other document types, a flurry of table pre-training frameworks have been proposed following the success of text and images, and they have achieved new state-of-the-arts on various tasks such as table question answering, table type recognition, column relation classification, table search, formula prediction, etc. To fully use the supervision signals in unlabeled tables, a variety of pre-training objectives have been designed and evaluated, for example, denoising cell values, predicting numerical relationships, and implicitly executing SQLs. And to best leverage the characteristics of (semi-)structured tables, various tabular language models, particularly with specially-designed attention mechanisms, have been explored. Since tables usually appear and interact with free-form text, table pre-training usually takes the form of table-text joint pre-training, which attracts significant research interests from multiple domains. This survey aims to provide a comprehensive review of different model designs, pre-training objectives, and downstream tasks for table pre-training, and we further share our thoughts and vision on existing challenges and future opportunities.
Understanding Pixel-level 2D Image Semantics with 3D Keypoint Knowledge Engine
Nov 21, 2021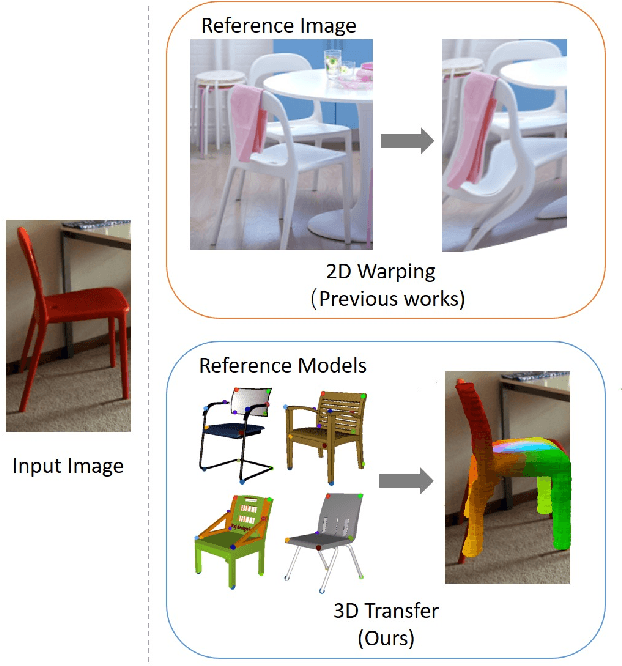

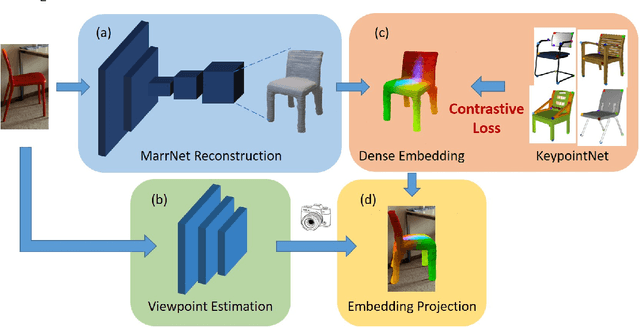

Pixel-level 2D object semantic understanding is an important topic in computer vision and could help machine deeply understand objects (e.g. functionality and affordance) in our daily life. However, most previous methods directly train on correspondences in 2D images, which is end-to-end but loses plenty of information in 3D spaces. In this paper, we propose a new method on predicting image corresponding semantics in 3D domain and then projecting them back onto 2D images to achieve pixel-level understanding. In order to obtain reliable 3D semantic labels that are absent in current image datasets, we build a large scale keypoint knowledge engine called KeypointNet, which contains 103,450 keypoints and 8,234 3D models from 16 object categories. Our method leverages the advantages in 3D vision and can explicitly reason about objects self-occlusion and visibility. We show that our method gives comparative and even superior results on standard semantic benchmarks.
FORTAP: Using Formulae for Numerical-Reasoning-Aware Table Pretraining
Sep 15, 2021
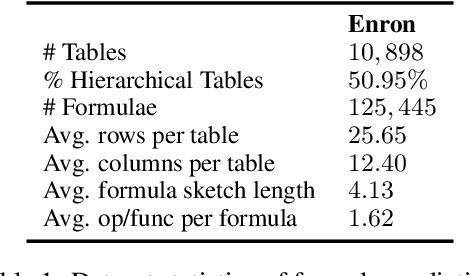
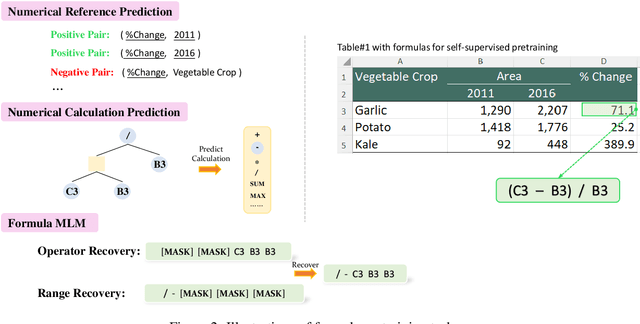
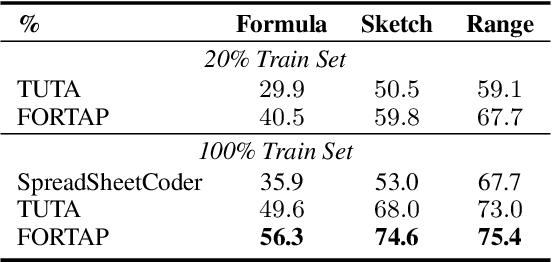
Tables store rich numerical data, but numerical reasoning over tables is still a challenge. In this paper, we find that the spreadsheet formula, which performs calculations on numerical values in tables, is naturally a strong supervision of numerical reasoning. More importantly, large amounts of spreadsheets with expert-made formulae are available on the web and can be obtained easily. FORTAP is the first method for numerical-reasoning-aware table pretraining by leveraging large corpus of spreadsheet formulae. We design two formula pretraining tasks to explicitly guide FORTAP to learn numerical reference and calculation in semi-structured tables. FORTAP achieves state-of-the-art results on two representative downstream tasks, cell type classification and formula prediction, showing great potential of numerical-reasoning-aware pretraining.
HiTab: A Hierarchical Table Dataset for Question Answering and Natural Language Generation
Aug 30, 2021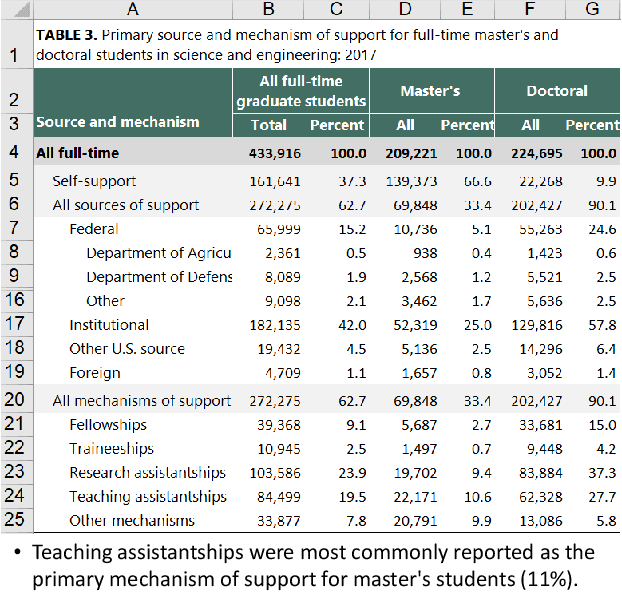
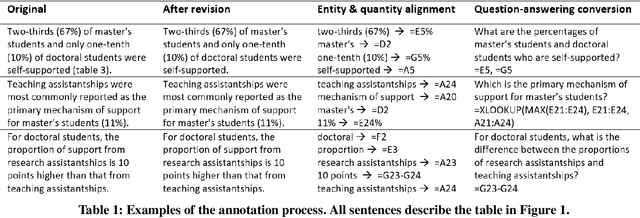

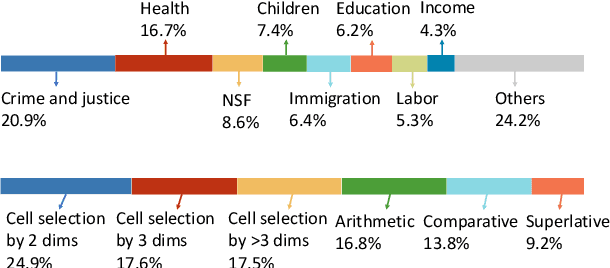
Tables are often created with hierarchies, but existing works on table reasoning mainly focus on flat tables and neglect hierarchical tables. Hierarchical tables challenge existing methods by hierarchical indexing, as well as implicit relationships of calculation and semantics. This work presents HiTab, a free and open dataset to study question answering (QA) and natural language generation (NLG) over hierarchical tables. HiTab is a cross-domain dataset constructed from a wealth of statistical reports (analyses) and Wikipedia pages, and has unique characteristics: (1) nearly all tables are hierarchical, and (2) both target sentences for NLG and questions for QA are revised from original, meaningful, and diverse descriptive sentences authored by analysts and professions of reports. (3) to reveal complex numerical reasoning in statistical analyses, we provide fine-grained annotations of entity and quantity alignment. HiTab provides 10,686 QA pairs and descriptive sentences with well-annotated quantity and entity alignment on 3,597 tables with broad coverage of table hierarchies and numerical reasoning types. Targeting hierarchical structure, we devise a novel hierarchy-aware logical form for symbolic reasoning over tables, which shows high effectiveness. Targeting complex numerical reasoning, we propose partially supervised training given annotations of entity and quantity alignment, which helps models to largely reduce spurious predictions in the QA task. In the NLG task, we find that entity and quantity alignment also helps NLG models to generate better results in a conditional generation setting. Experiment results of state-of-the-art baselines suggest that this dataset presents a strong challenge and a valuable benchmark for future research.
Semantic Correspondence via 2D-3D-2D Cycle
Apr 20, 2020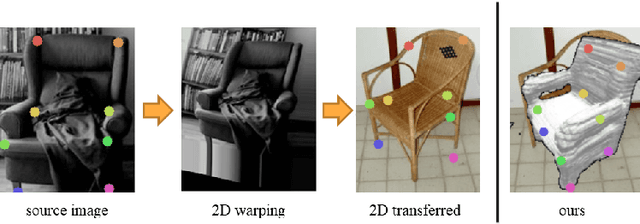
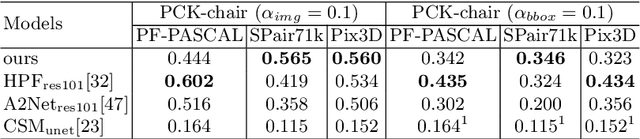
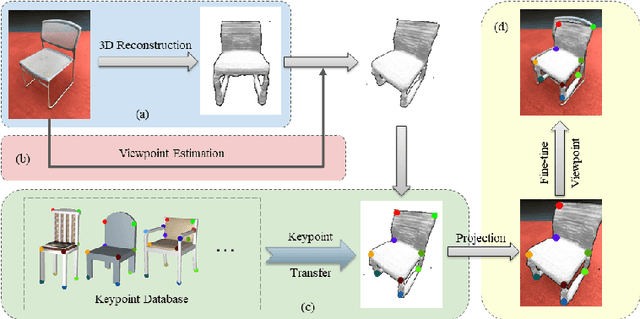

Visual semantic correspondence is an important topic in computer vision and could help machine understand objects in our daily life. However, most previous methods directly train on correspondences in 2D images, which is end-to-end but loses plenty of information in 3D spaces. In this paper, we propose a new method on predicting semantic correspondences by leveraging it to 3D domain and then project corresponding 3D models back to 2D domain, with their semantic labels. Our method leverages the advantages in 3D vision and can explicitly reason about objects self-occlusion and visibility. We show that our method gives comparative and even superior results on standard semantic benchmarks. We also conduct thorough and detailed experiments to analyze our network components. The code and experiments are publicly available at https://github.com/qq456cvb/SemanticTransfer.
KeypointNet: A Large-scale 3D Keypoint Dataset Aggregated from Numerous Human Annotations
Mar 21, 2020

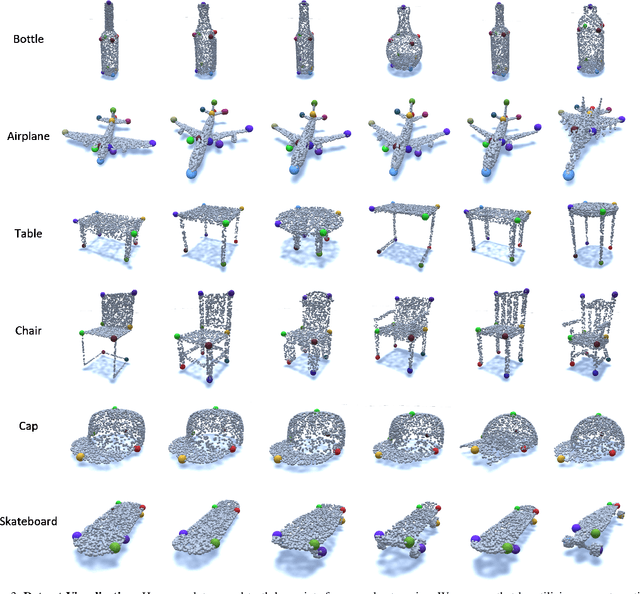
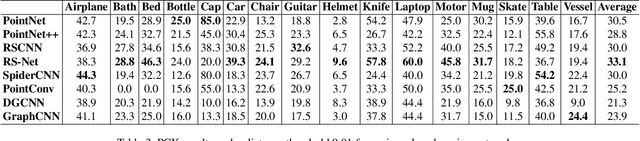
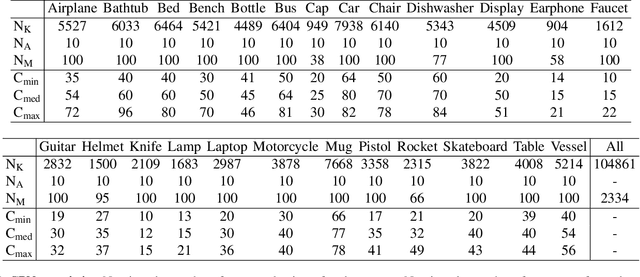
Detecting 3D objects keypoints is of great interest to the areas of both graphics and computer vision. There have been several 2D and 3D keypoint datasets aiming to address this problem in a data-driven way. These datasets, however, either lack scalability or bring ambiguity to the definition of keypoints. Therefore, we present KeypointNet: the first large-scale and diverse 3D keypoint dataset that contains 83,231 keypoints and 8,329 3D models from 16 object categories, by leveraging numerous human annotations. To handle the inconsistency between annotations from different people, we propose a novel method to aggregate these keypoints automatically, through minimization of a fidelity loss. Finally, ten state-of-the-art methods are benchmarked on our proposed dataset.
Fine-grained Object Semantic Understanding from Correspondences
Dec 29, 2019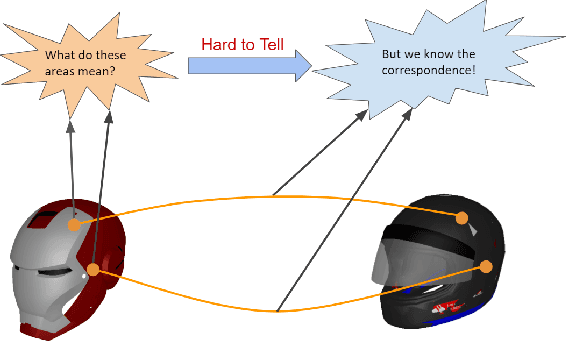
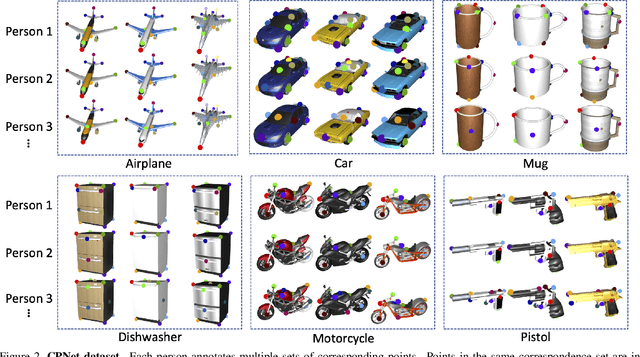
Fine-grained semantic understanding of 3D objects is crucial in many applications such as object manipulation. However, it is hard to give a universal definition of point-level semantics that everyone would agree on. We observe that people are pretty sure about semantic correspondences between two areas from different objects, but less certain about what each area means in semantics. Therefore, we argue that by providing human labeled correspondences between different objects from the same category, one can recover rich semantic information of an object. In this paper, we propose a method that outputs dense semantic embeddings based on a novel geodesic consistency loss. Accordingly, a new dataset named CorresPondenceNet and its corresponding benchmark are designed. Several state-of-the-art networks are evaluated based on our proposed method. We show that our method could boost the fine-grained understanding of heterogeneous objects and the inference of dense semantic information is possible.