 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Embarrassingly Simple Approach to Training Ternary Weight Networks
Nov 01, 2020

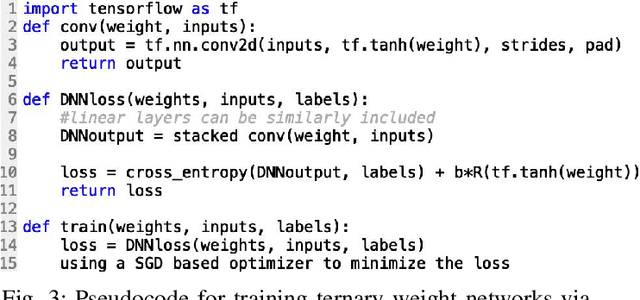
Deep neural networks (DNNs) have achieved great successes in various domains of artificial intelligence, but they require large amounts of memory and computational power. This severely restricts their implementation on resource-limited hardware. One approach to solving this problem is to train DNNs with ternary weights \{-1, 0, +1\}, thus avoiding multiplications and dramatically reducing the memory and computation requirements. However, the existing approaches to training ternary weight networks either have a large performance gap to the full precision counterparts or have a complex training process, which makes ternary weight networks not widely used. In this paper, we propose an embarrassingly simple approach (ESA) to training ternary weight networks. Specifically, ESA first parameterizes the weights $W$ in a DNN with $\tanh(\Theta)$ where $\Theta$ are the parameters, so that the weight values are limited in the range between -1 and +1, and then a weight discretization regularization (WDR) is used to force the weights to be ternary. Consequently, ESA has an extremely high code reuse rate when converting a full precision weight DNN to the ternary version. More importantly, ESA is able to control the sparsity (i.e., the percentage of 0s) of the ternary weights through a controller $\alpha$ in WDR. We theoretically and empirically show that the sparsity of the trained ternary weights is positively related to $\alpha$. To the best of our knowledge, ESA is the first sparsity-controlling approach to training ternary weight networks. Extensive experiments on several benchmark datasets demonstrate that ESA beats the state-of-the-art approaches significantly and matches the performances of the full precision weight networks.
SBAT: Video Captioning with Sparse Boundary-Aware Transformer
Jul 23, 2020
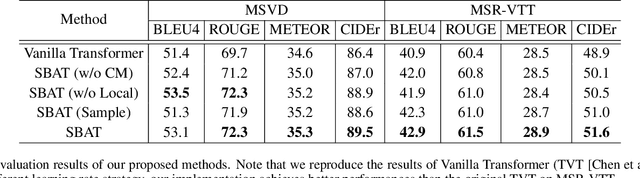
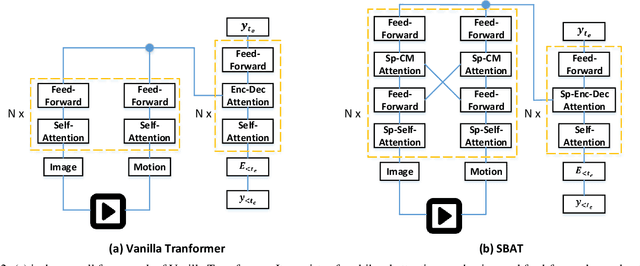
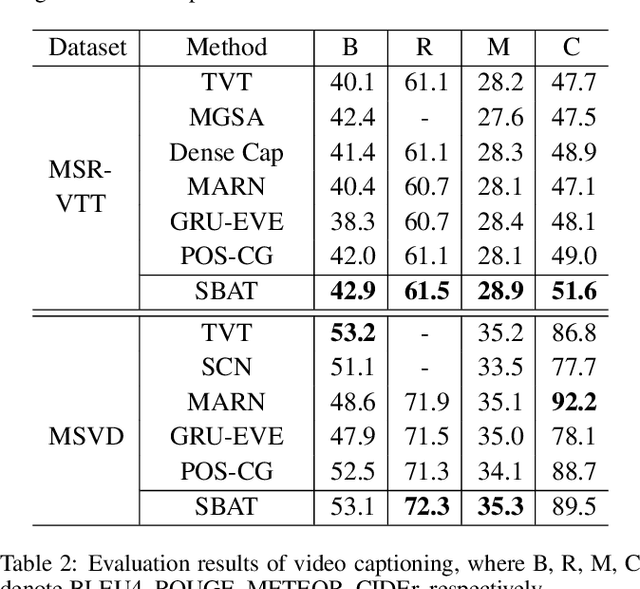
In this paper, we focus on the problem of applying the transformer structure to video captioning effectively. The vanilla transformer is proposed for uni-modal language generation task such as machine translation. However, video captioning is a multimodal learning problem, and the video features have much redundancy between different time steps. Based on these concerns, we propose a novel method called sparse boundary-aware transformer (SBAT) to reduce the redundancy in video representation. SBAT employs boundary-aware pooling operation for scores from multihead attention and selects diverse features from different scenarios. Also, SBAT includes a local correlation scheme to compensate for the local information loss brought by sparse operation. Based on SBAT, we further propose an aligned cross-modal encoding scheme to boost the multimodal interaction. Experimental results on two benchmark datasets show that SBAT outperforms the state-of-the-art methods under most of the metrics.
Multitask Non-Autoregressive Model for Human Motion Prediction
Jul 13, 2020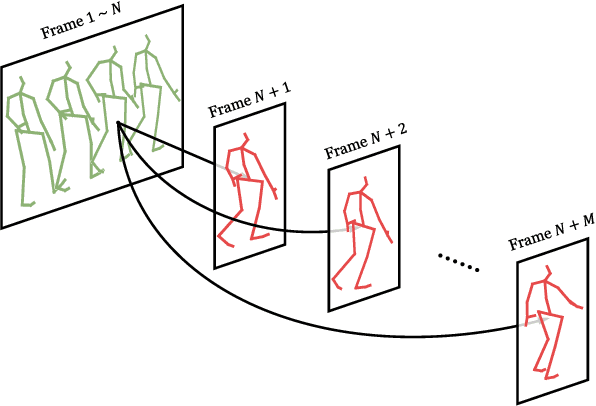
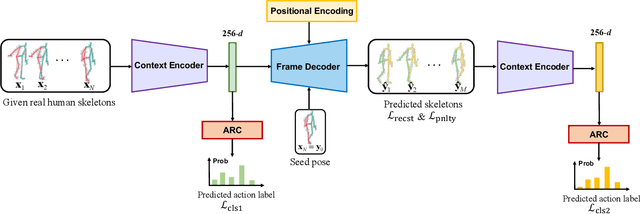
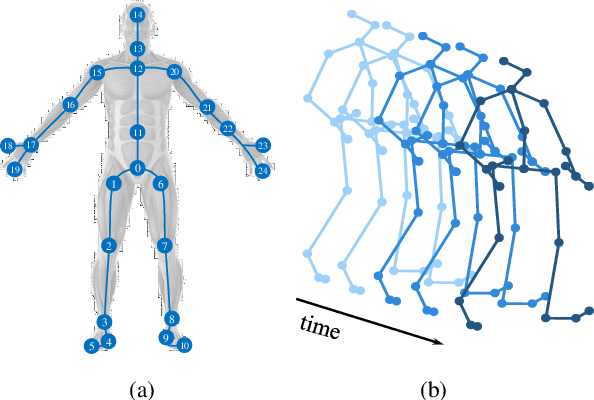
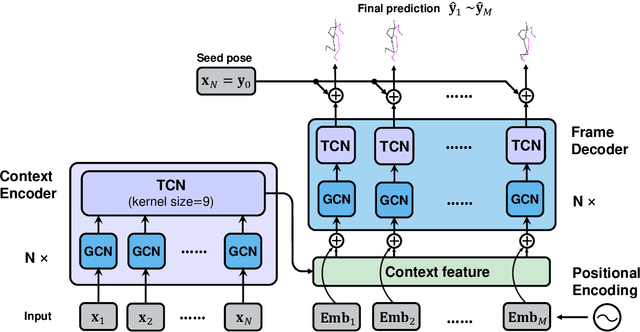
Human motion prediction, which aims at predicting future human skeletons given the past ones, is a typical sequence-to-sequence problem. Therefore, extensive efforts have been continued on exploring different RNN-based encoder-decoder architectures. However, by generating target poses conditioned on the previously generated ones, these models are prone to bringing issues such as error accumulation problem. In this paper, we argue that such issue is mainly caused by adopting autoregressive manner. Hence, a novel Non-auToregressive Model (NAT) is proposed with a complete non-autoregressive decoding scheme, as well as a context encoder and a positional encoding module. More specifically, the context encoder embeds the given poses from temporal and spatial perspectives. The frame decoder is responsible for predicting each future pose independently. The positional encoding module injects positional signal into the model to indicate temporal order. Moreover, a multitask training paradigm is presented for both low-level human skeleton prediction and high-level human action recognition, resulting in the convincing improvement for the prediction task. Our approach is evaluated on Human3.6M and CMU-Mocap benchmarks and outperforms state-of-the-art autoregressive methods.
Is the Meta-Learning Idea Able to Improve the Generalization of Deep Neural Networks on the Standard Supervised Learning?
Feb 27, 2020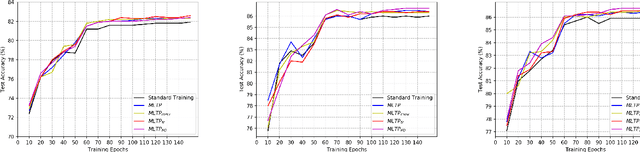
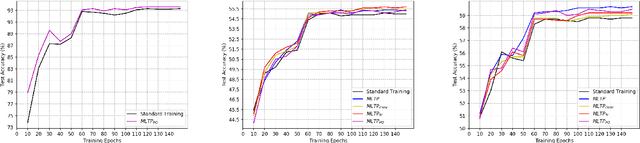
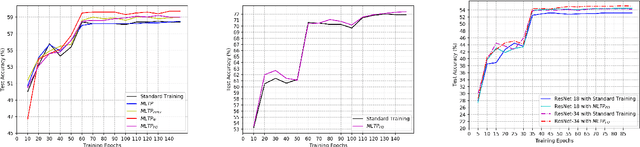
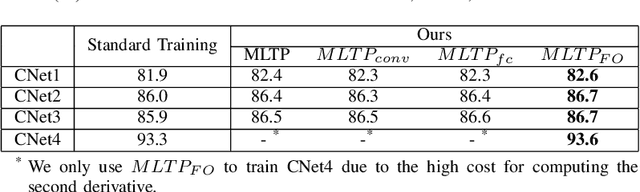
Substantial efforts have been made on improving the generalization abilities of deep neural networks (DNNs) in order to obtain better performances without introducing more parameters. On the other hand, meta-learning approaches exhibit powerful generalization on new tasks in few-shot learning. Intuitively, few-shot learning is more challenging than the standard supervised learning as each target class only has a very few or no training samples. The natural question that arises is whether the meta-learning idea can be used for improving the generalization of DNNs on the standard supervised learning. In this paper, we propose a novel meta-learning based training procedure (MLTP) for DNNs and demonstrate that the meta-learning idea can indeed improve the generalization abilities of DNNs. MLTP simulates the meta-training process by considering a batch of training samples as a task. The key idea is that the gradient descent step for improving the current task performance should also improve a new task performance, which is ignored by the current standard procedure for training neural networks. MLTP also benefits from all the existing training techniques such as dropout, weight decay, and batch normalization. We evaluate MLTP by training a variety of small and large neural networks on three benchmark datasets, i.e., CIFAR-10, CIFAR-100, and Tiny ImageNet. The experimental results show a consistently improved generalization performance on all the DNNs with different sizes, which verifies the promise of MLTP and demonstrates that the meta-learning idea is indeed able to improve the generalization of DNNs on the standard supervised learning.
Low-Rank HOCA: Efficient High-Order Cross-Modal Attention for Video Captioning
Nov 01, 2019
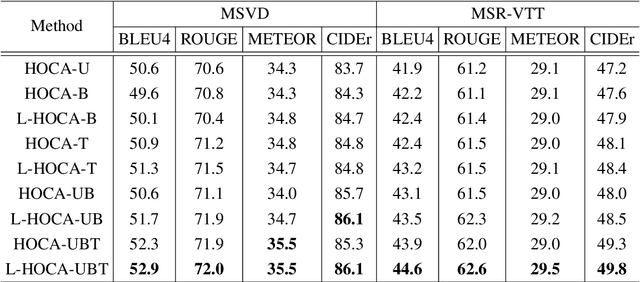
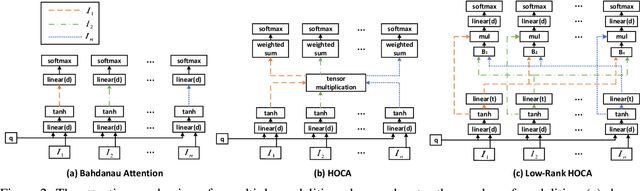
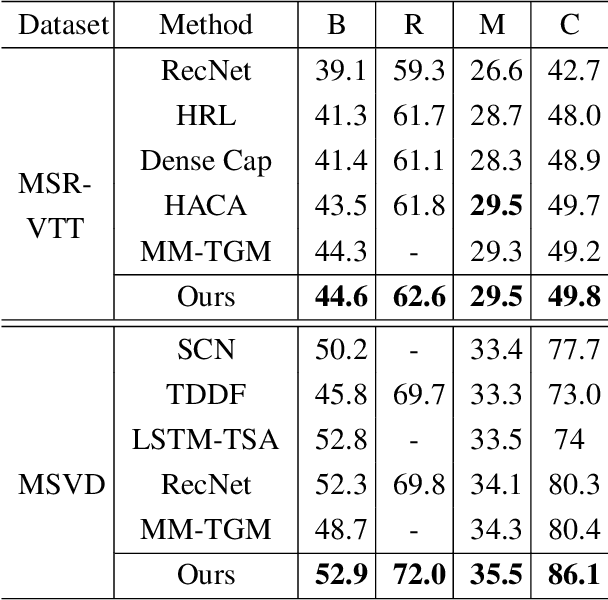
This paper addresses the challenging task of video captioning which aims to generate descriptions for video data. Recently, the attention-based encoder-decoder structures have been widely used in video captioning. In existing literature, the attention weights are often built from the information of an individual modality, while, the association relationships between multiple modalities are neglected. Motivated by this observation, we propose a video captioning model with High-Order Cross-Modal Attention (HOCA) where the attention weights are calculated based on the high-order correlation tensor to capture the frame-level cross-modal interaction of different modalities sufficiently. Furthermore, we novelly introduce Low-Rank HOCA which adopts tensor decomposition to reduce the extremely large space requirement of HOCA, leading to a practical and efficient implementation in real-world applications. Experimental results on two benchmark datasets, MSVD and MSR-VTT, show that Low-rank HOCA establishes a new state-of-the-art.
Meta-Transfer Networks for Zero-Shot Learning
Sep 08, 2019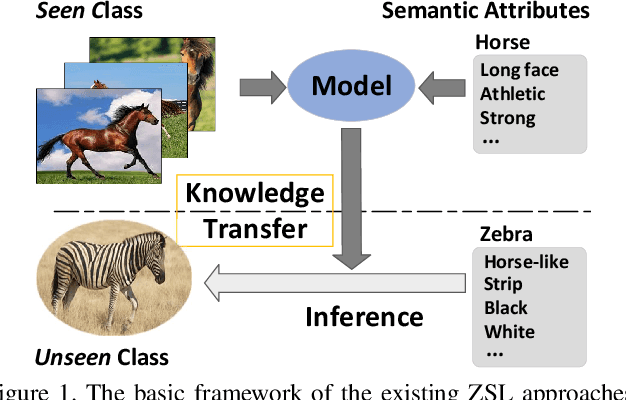
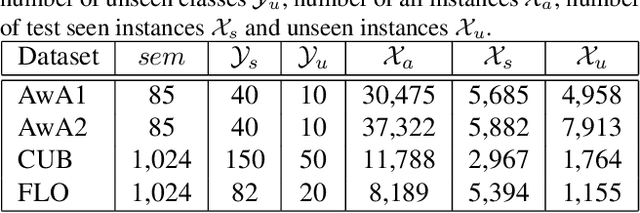
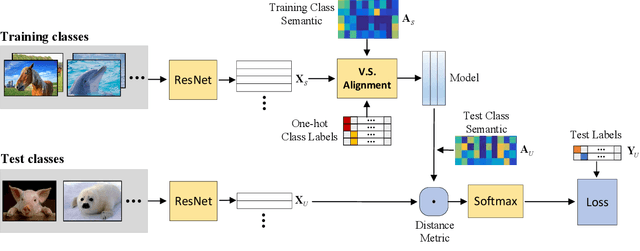

Zero-Shot Learning (ZSL) aims at recognizing unseen categories using some class semantics of the categories. The existing studies mostly leverage the seen categories to learn a visual-semantic interaction model to infer the unseen categories. However, the disjointness between the seen and unseen categories cannot ensure that the models trained on the seen categories generalize well to the unseen categories. In this work, we propose an episode-based approach to accumulate experiences on addressing disjointness issue by mimicking extensive classification scenarios where training classes and test classes are disjoint. In each episode, a visual-semantic interaction model is first trained on a subset of seen categories as a learner that provides an initial prediction for the rest disjoint seen categories and then a meta-learner fine-tunes the learner by minimizing the differences between the prediction and the ground-truth labels in a pre-defined space. By training extensive episodes on the seen categories, the model is trained to be an expert in predicting the mimetic unseen categories, which will generalize well to the real unseen categories. Extensive experiments on four datasets under both the traditional ZSL and generalized ZSL tasks show that our framework outperforms the state-of-the-art approaches by large margins.
A Semantics-Guided Class Imbalance Learning Model for Zero-Shot Classification
Aug 26, 2019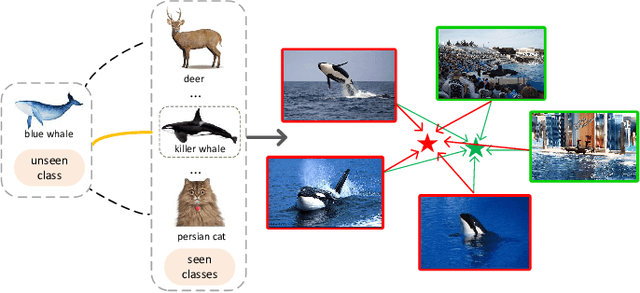
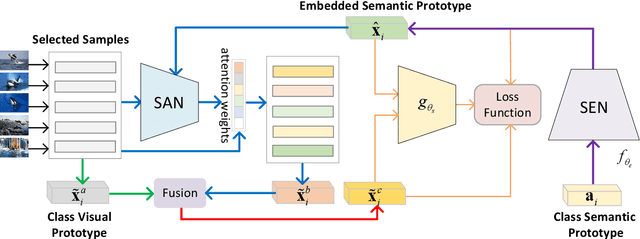
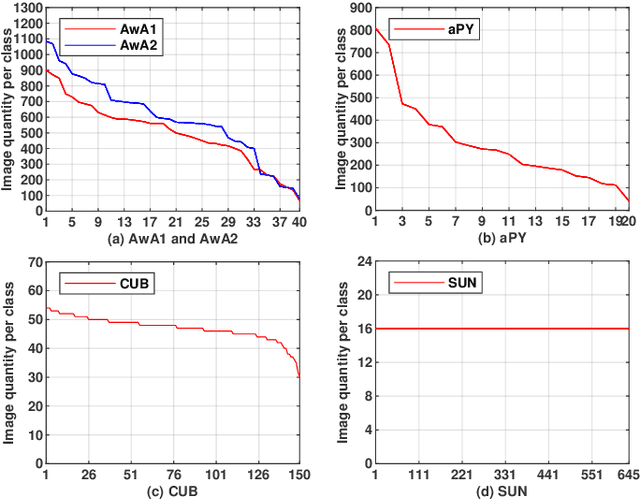
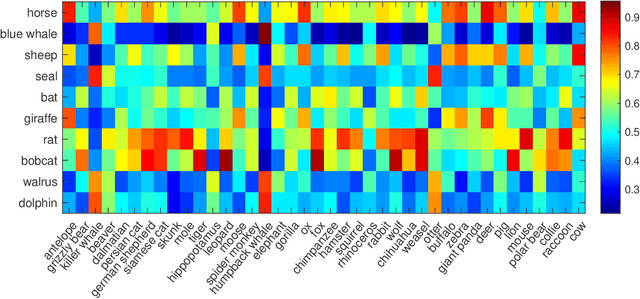
Zero-Shot Classification (ZSC) equips the learned model with the ability to recognize the visual instances from the novel classes via constructing the interactions between the visual and the semantic modalities. In contrast to the traditional image classification, ZSC is easily suffered from the class-imbalance issue since it is more concerned with the class-level knowledge transfer capability. In the real world, the class samples follow a long-tailed distribution, and the discriminative information in the sample-scarce seen classes is hard to be transferred to the related unseen classes in the traditional batch-based training manner, which degrades the overall generalization ability a lot. Towards alleviating the class imbalance issue in ZSC, we propose a sample-balanced training process to encourage all training classes to contribute equally to the learned model. Specifically, we randomly select the same number of images from each class across all training classes to form a training batch to ensure that the sample-scarce classes contribute equally as those classes with sufficient samples during each iteration. Considering that the instances from the same class differ in class representativeness, we further develop an efficient semantics-guided feature fusion model to obtain discriminative class visual prototype for the following visual-semantic interaction process via distributing different weights to the selected samples based on their class representativeness. Extensive experiments on three imbalanced ZSC benchmark datasets for both the Traditional ZSC (TZSC) and the Generalized ZSC (GZSC) tasks demonstrate our approach achieves promising results especially for the unseen categories those are closely related to the sample-scarce seen categories.
Text Guided Person Image Synthesis
Apr 10, 2019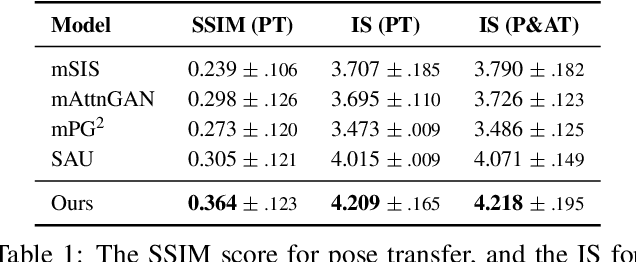
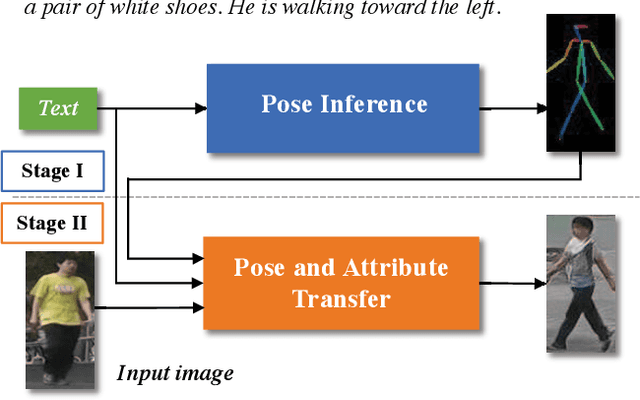
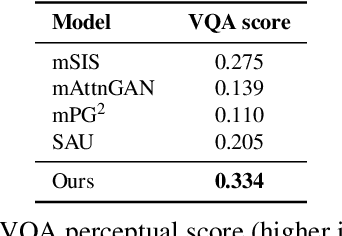
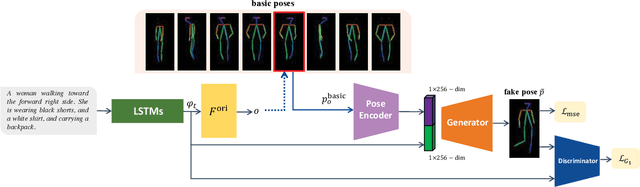
This paper presents a novel method to manipulate the visual appearance (pose and attribute) of a person image according to natural language descriptions. Our method can be boiled down to two stages: 1) text guided pose generation and 2) visual appearance transferred image synthesis. In the first stage, our method infers a reasonable target human pose based on the text. In the second stage, our method synthesizes a realistic and appearance transferred person image according to the text in conjunction with the target pose. Our method extracts sufficient information from the text and establishes a mapping between the image space and the language space, making generating and editing images corresponding to the description possible. We conduct extensive experiments to reveal the effectiveness of our method, as well as using the VQA Perceptual Score as a metric for evaluating the method. It shows for the first time that we can automatically edit the person image from the natural language descriptions.
Cross-relation Cross-bag Attention for Distantly-supervised Relation Extraction
Dec 27, 2018
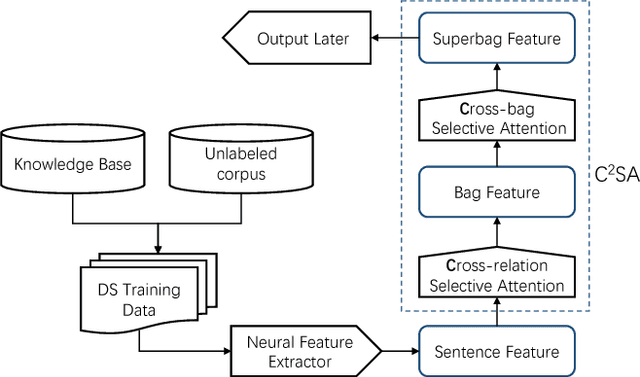
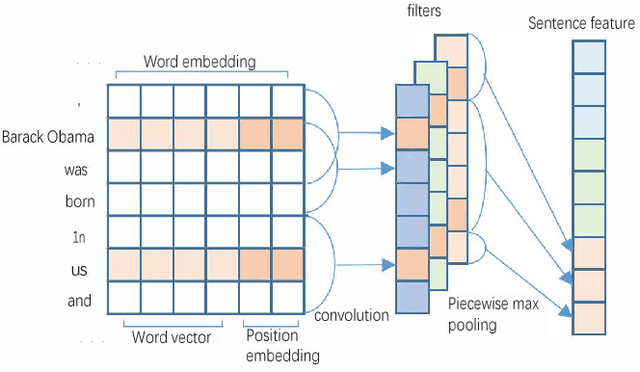
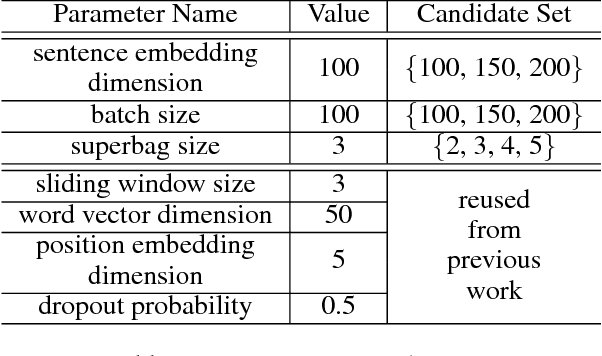
Distant supervision leverages knowledge bases to automatically label instances, thus allowing us to train relation extractor without human annotations. However, the generated training data typically contain massive noise, and may result in poor performances with the vanilla supervised learning. In this paper, we propose to conduct multi-instance learning with a novel Cross-relation Cross-bag Selective Attention (C$^2$SA), which leads to noise-robust training for distant supervised relation extractor. Specifically, we employ the sentence-level selective attention to reduce the effect of noisy or mismatched sentences, while the correlation among relations were captured to improve the quality of attention weights. Moreover, instead of treating all entity-pairs equally, we try to pay more attention to entity-pairs with a higher quality. Similarly, we adopt the selective attention mechanism to achieve this goal. Experiments with two types of relation extractor demonstrate the superiority of the proposed approach over the state-of-the-art, while further ablation studies verify our intuitions and demonstrate the effectiveness of our proposed two techniques.
Perceiving Physical Equation by Observing Visual Scenarios
Nov 29, 2018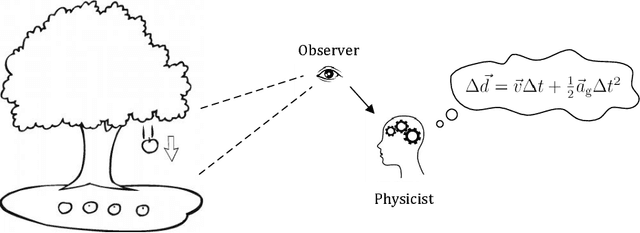
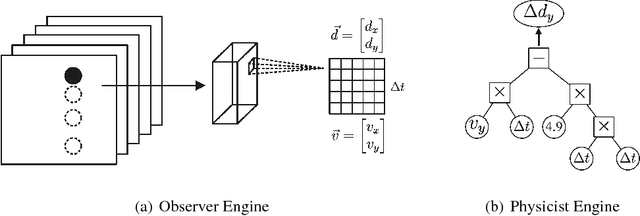
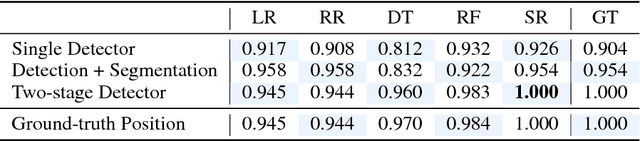
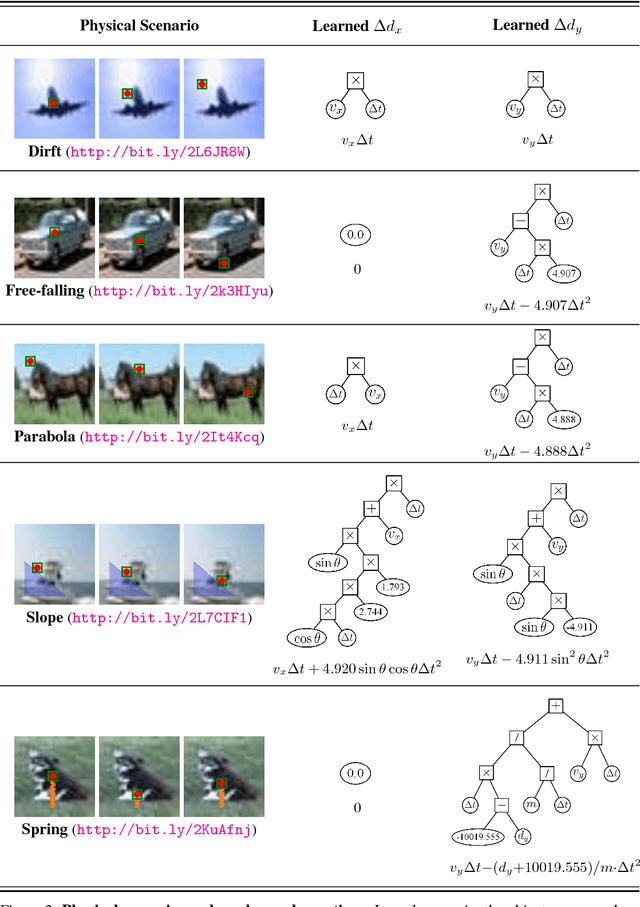
Inferring universal laws of the environment is an important ability of human intelligence as well as a symbol of general AI. In this paper, we take a step toward this goal such that we introduce a new challenging problem of inferring invariant physical equation from visual scenarios. For instance, teaching a machine to automatically derive the gravitational acceleration formula by watching a free-falling object. To tackle this challenge, we present a novel pipeline comprised of an Observer Engine and a Physicist Engine by respectively imitating the actions of an observer and a physicist in the real world. Generally, the Observer Engine watches the visual scenarios and then extracting the physical properties of objects. The Physicist Engine analyses these data and then summarizing the inherent laws of object dynamics. Specifically, the learned laws are expressed by mathematical equations such that they are more interpretable than the results given by common probabilistic models. Experiments on synthetic videos have shown that our pipeline is able to discover physical equations on various physical worlds with different visual appearances.