 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEED: Self-supervised Distillation For Visual Representation
Jan 12, 2021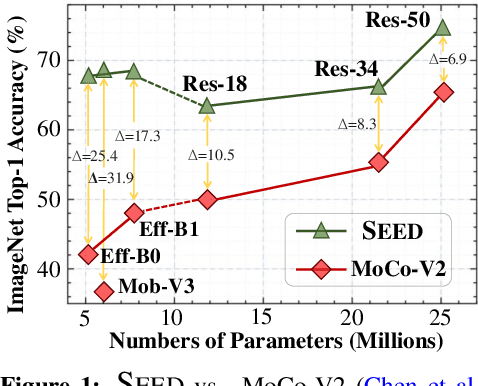
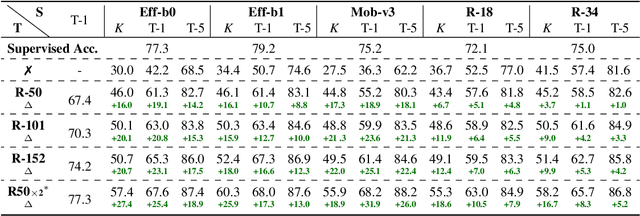
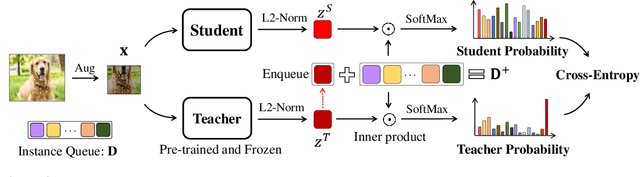

This paper is concerned with self-supervised learning for small models. The problem is motivated by our empirical studies that while the widely used contrastive self-supervised learning method has shown great progress on large model training, it does not work well for small models. To address this problem, we propose a new learning paradigm, named SElf-SupErvised Distillation (SEED), where we leverage a larger network (as Teacher) to transfer its representational knowledge into a smaller architecture (as Student) in a self-supervised fashion. Instead of directly learning from unlabeled data, we train a student encoder to mimic the similarity score distribution inferred by a teacher over a set of instances. We show that SEED dramatically boosts the performance of small networks on downstream tasks. Compared with self-supervised baselines, SEED improves the top-1 accuracy from 42.2% to 67.6% on EfficientNet-B0 and from 36.3% to 68.2% on MobileNet-v3-Large on the ImageNet-1k dataset.
Weak Supervision and Referring Attention for Temporal-Textual Association Learning
Jun 27, 2020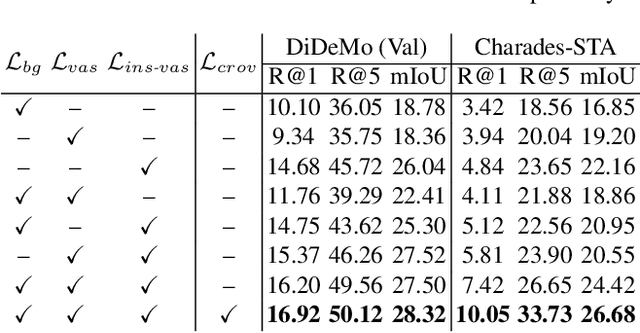
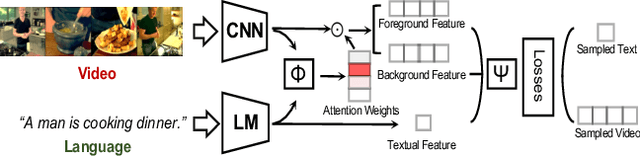
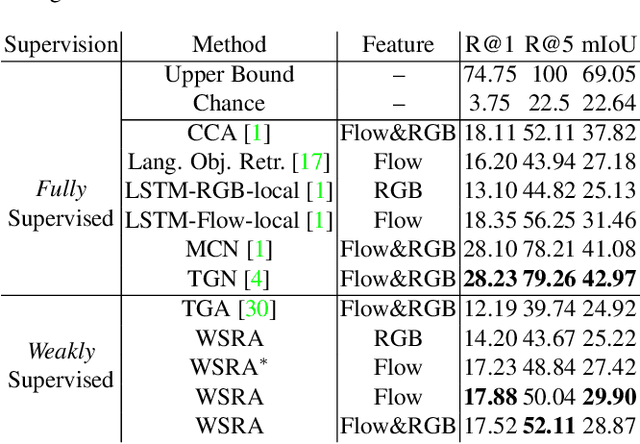
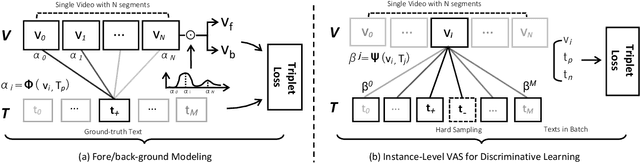
A system capturing the association between video frames and textual queries offer great potential for better video analysis. However, training such a system in a fully supervised way inevitably demands a meticulously curated video dataset with temporal-textual annotations. Therefore we provide a Weak-Supervised alternative with our proposed Referring Attention mechanism to learn temporal-textual association (dubbed WSRA). The weak supervision is simply a textual expression (e.g., short phrases or sentences) at video level, indicating this video contains relevant frames. The referring attention is our designed mechanism acting as a scoring function for grounding the given queries over frames temporally. It consists of multiple novel losses and sampling strategies for better training. The principle in our designed mechanism is to fully exploit 1) the weak supervision by considering informative and discriminative cues from intra-video segments anchored with the textual query, 2) multiple queries compared to the single video, and 3) cross-video visual similarities. We validate our WSRA through extensive experiments for temporally grounding by languages, demonstrating that it outperforms the state-of-the-art weakly-supervised methods notably.
HRDNet: High-resolution Detection Network for Small Objects
Jun 13, 2020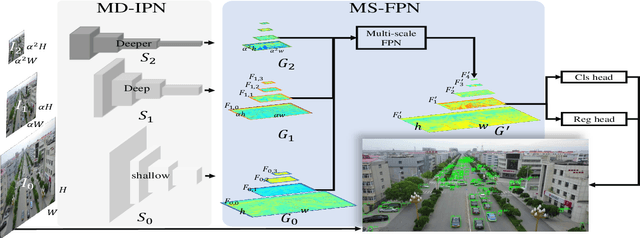

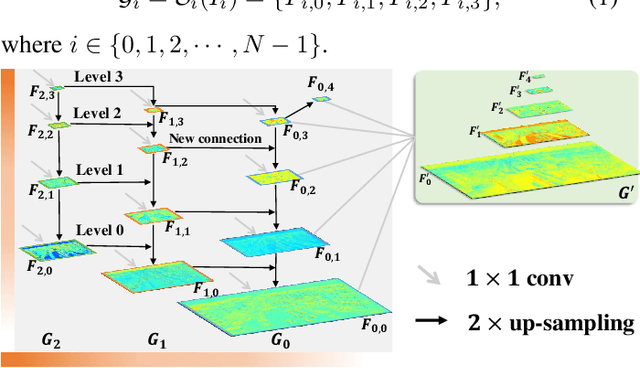
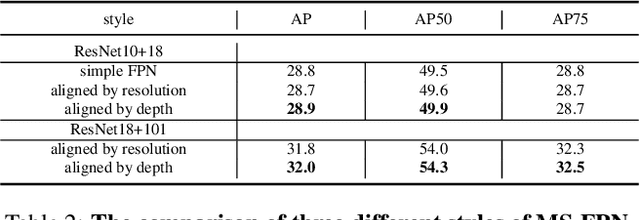
Small object detection is challenging because small objects do not contain detailed information and may even disappear in the deep network. Usually, feeding high-resolution images into a network can alleviate this issue. However, simply enlarging the resolution will cause more problems, such as that, it aggravates the large variant of object scale and introduces unbearable computation cost. To keep the benefits of high-resolution images without bringing up new problems, we proposed the High-Resolution Detection Network (HRDNet). HRDNet takes multiple resolution inputs using multi-depth backbones. To fully take advantage of multiple features, we proposed Multi-Depth Image Pyramid Network (MD-IPN) and Multi-Scale Feature Pyramid Network (MS-FPN) in HRDNet. MD-IPN maintains multiple position information using multiple depth backbones. Specifically, high-resolution input will be fed into a shallow network to reserve more positional information and reducing the computational cost while low-resolution input will be fed into a deep network to extract more semantics. By extracting various features from high to low resolutions, the MD-IPN is able to improve the performance of small object detection as well as maintaining the performance of middle and large objects. MS-FPN is proposed to align and fuse multi-scale feature groups generated by MD-IPN to reduce the information imbalance between these multi-scale multi-level features. Extensive experiments and ablation studies are conducted on the standard benchmark dataset MS COCO2017, Pascal VOC2007/2012 and a typical small object dataset, VisDrone 2019. Notably, our proposed HRDNet achieves the state-of-the-art on these datasets and it performs better on small objects.
ViTAA: Visual-Textual Attributes Alignment in Person Search by Natural Language
May 15, 2020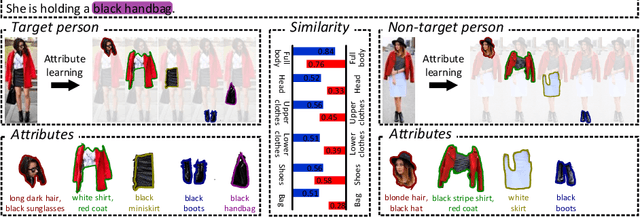
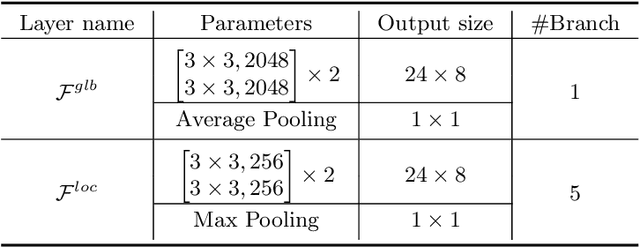

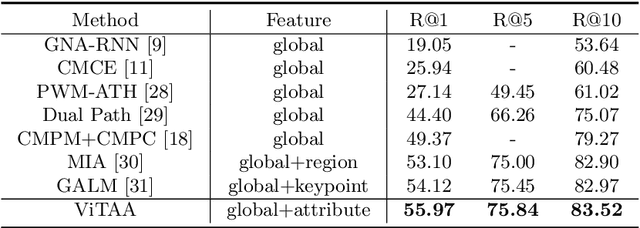
Person search by natural language aims at retrieving a specific person in a large-scale image pool that matches the given textual descriptions. While most of the current methods treat the task as a holistic visual and textual feature matching one, we approach it from an attribute-aligning perspective that allows grounding specific attribute phrases to the corresponding visual regions. We achieve success as well as the performance boosting by a robust feature learning that the referred identity can be accurately bundled by multiple attribute visual cues. To be concrete, our Visual-Textual Attribute Alignment model (dubbed as ViTAA) learns to disentangle the feature space of a person into subspaces corresponding to attributes using a light auxiliary attribute segmentation computing branch. It then aligns these visual features with the textual attributes parsed from the sentences by using a novel contrastive learning loss. Upon that, we validate our ViTAA framework through extensive experiments on tasks of person search by natural language and by attribute-phrase queries, on which our system achieves state-of-the-art performances. Code will be publicly available upon publication.
Video2Commonsense: Generating Commonsense Descriptions to Enrich Video Captioning
Mar 17, 2020
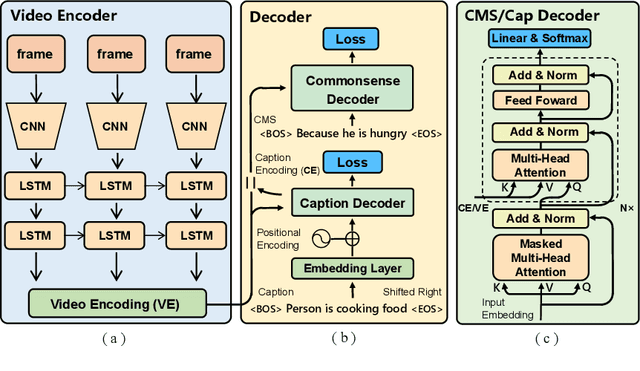
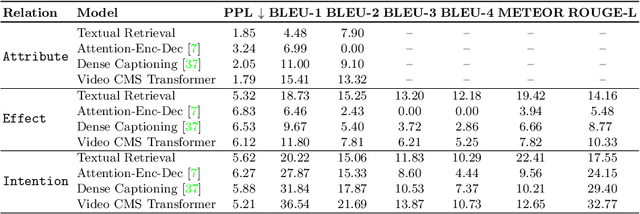
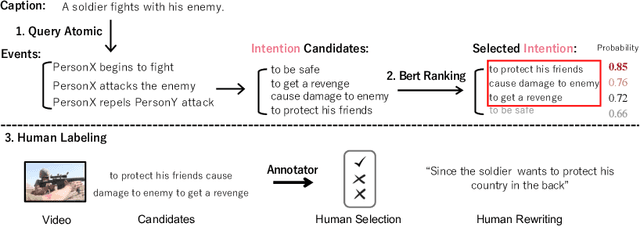
Captioning is a crucial and challenging task for video understanding. In videos that involve active agents such as humans, the agent's actions can bring about myriad changes in the scene. These changes can be observable, such as movements, manipulations, and transformations of the objects in the scene -- these are reflected in conventional video captioning. However, unlike images, actions in videos are also inherently linked to social and commonsense aspects such as intentions (why the action is taking place), attributes (such as who is doing the action, on whom, where, using what etc.) and effects (how the world changes due to the action, the effect of the action on other agents). Thus for video understanding, such as when captioning videos or when answering question about videos, one must have an understanding of these commonsense aspects. We present the first work on generating \textit{commonsense} captions directly from videos, in order to describe latent aspects such as intentions, attributes, and effects. We present a new dataset "Video-to-Commonsense (V2C)" that contains 9k videos of human agents performing various actions, annotated with 3 types of commonsense descriptions. Additionally we explore the use of open-ended video-based commonsense question answering (V2C-QA) as a way to enrich our captions. We finetune our commonsense generation models on the V2C-QA task where we ask questions about the latent aspects in the video. Both the generation task and the QA task can be used to enrich video captions.
Blocksworld Revisited: Learning and Reasoning to Generate Event-Sequences from Image Pairs
May 28, 2019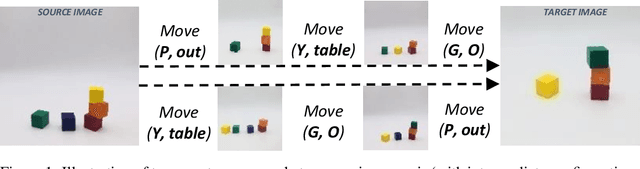
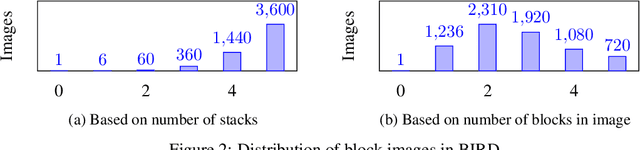
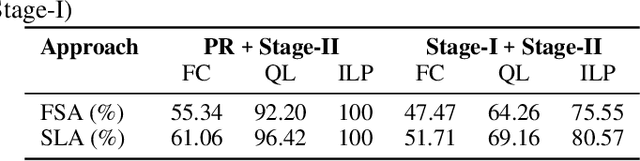
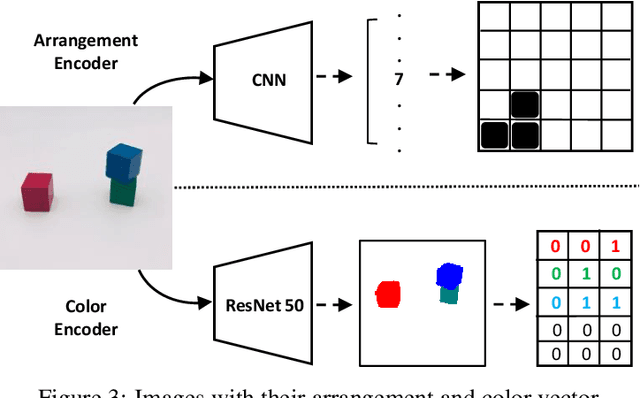
The process of identifying changes or transformations in a scene along with the ability of reasoning about their causes and effects, is a key aspect of intelligence. In this work we go beyond recent advances in computational perception, and introduce a more challenging task, Image-based Event-Sequencing (IES). In IES, the task is to predict a sequence of actions required to rearrange objects from the configuration in an input source image to the one in the target image. IES also requires systems to possess inductive generalizability. Motivated from evidence in cognitive development, we compile the first IES dataset, the Blocksworld Image Reasoning Dataset (BIRD) which contains images of wooden blocks in different configurations, and the sequence of moves to rearrange one configuration to the other. We first explore the use of existing deep learning architectures and show that these end-to-end methods under-perform in inferring temporal event-sequences and fail at inductive generalization. We then propose a modular two-step approach: Visual Perception followed by Event-Sequencing, and demonstrate improved performance by combining learning and reasoning. Finally, by showing an extension of our approach on natural images, we seek to pave the way for future research on event sequencing for real world scenes.
Modularized Textual Grounding for Counterfactual Resilience
Apr 07, 2019
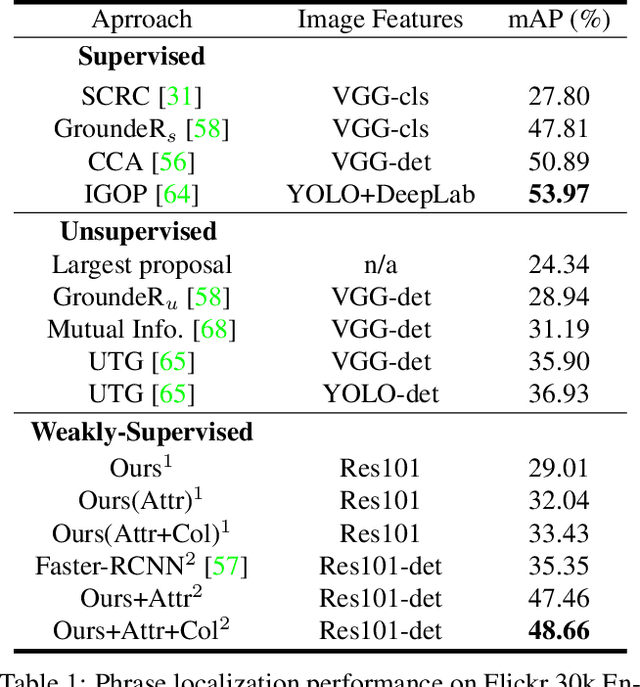
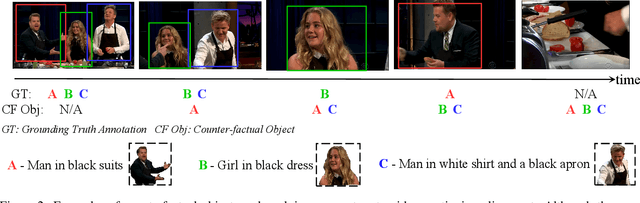
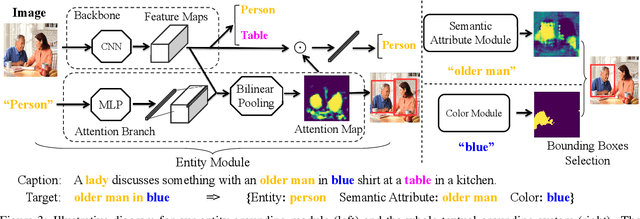
Computer Vision applications often require a textual grounding module with precision, interpretability, and resilience to counterfactual inputs/queries. To achieve high grounding precision, current textual grounding methods heavily rely on large-scale training data with manual annotations at the pixel level. Such annotations are expensive to obtain and thus severely narrow the model's scope of real-world applications. Moreover, most of these methods sacrifice interpretability, generalizability, and they neglect the importance of being resilient to counterfactual inputs. To address these issues, we propose a visual grounding system which is 1) end-to-end trainable in a weakly supervised fashion with only image-level annotations, and 2) counterfactually resilient owing to the modular design. Specifically, we decompose textual descriptions into three levels: entity, semantic attribute, color information, and perform compositional grounding progressively. We validate our model through a series of experiments and demonstrate its improvement over the state-of-the-art methods. In particular, our model's performance not only surpasses other weakly/un-supervised methods and even approaches the strongly supervised ones, but also is interpretable for decision making and performs much better in face of counterfactual classes than all the others.
Weakly Supervised Attention Learning for Textual Phrases Grounding
May 01, 2018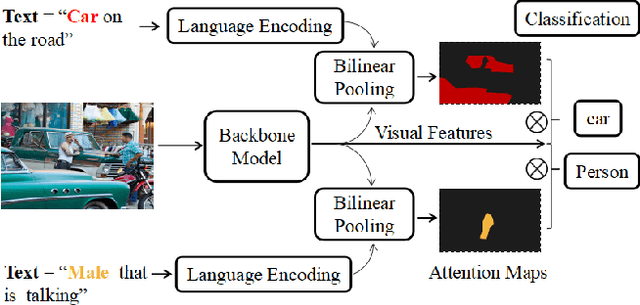

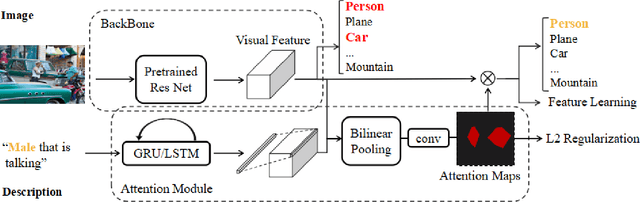

Grounding textual phrases in visual content is a meaningful yet challenging problem with various potential applications such as image-text inference or text-driven multimedia interaction. Most of the current existing methods adopt the supervised learning mechanism which requires ground-truth at pixel level during training. However, fine-grained level ground-truth annotation is quite time-consuming and severely narrows the scope for more general applications. In this extended abstract, we explore methods to localize flexibly image regions from the top-down signal (in a form of one-hot label or natural languages) with a weakly supervised attention learning mechanism. In our model, two types of modules are utilized: a backbone module for visual feature capturing, and an attentive module generating maps based on regularized bilinear pooling. We construct the model in an end-to-end fashion which is trained by encouraging the spatial attentive map to shift and focus on the region that consists of the best matched visual features with the top-down signal. We demonstrate the preliminary yet promising results on a testbed that is synthesized with multi-label MNIST data.
Range Loss for Deep Face Recognition with Long-tail
Nov 28, 2016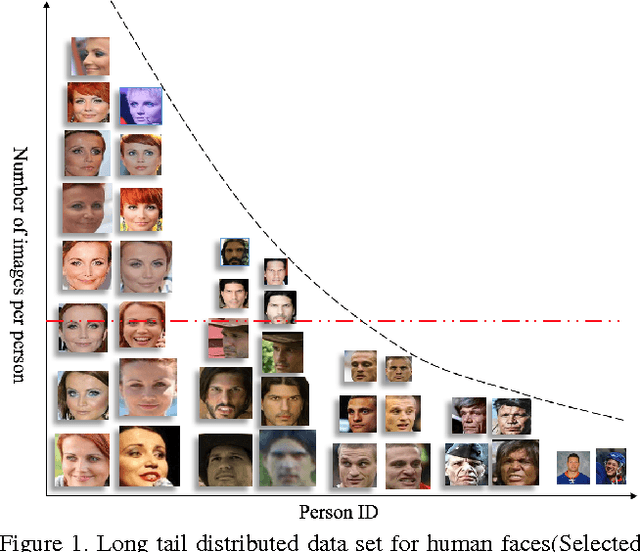
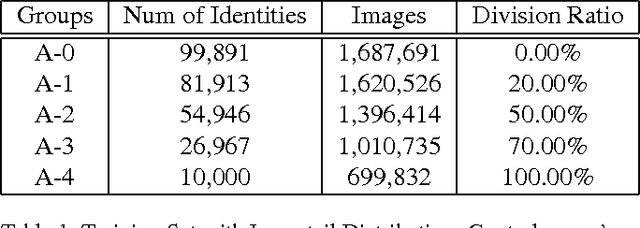
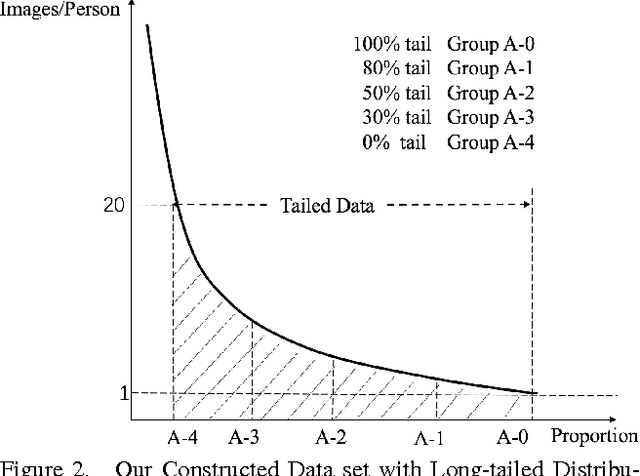
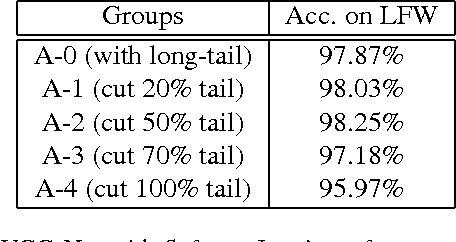
Convolutional neural networks have achieved great improvement on face recognition in recent years because of its extraordinary ability in learning discriminative features of people with different identities. To train such a well-designed deep network, tremendous amounts of data is indispensable. Long tail distribution specifically refers to the fact that a small number of generic entities appear frequently while other objects far less existing. Considering the existence of long tail distribution of the real world data, large but uniform distributed data are usually hard to retrieve. Empirical experiences and analysis show that classes with more samples will pose greater impact on the feature learning process and inversely cripple the whole models feature extracting ability on tail part data. Contrary to most of the existing works that alleviate this problem by simply cutting the tailed data for uniform distributions across the classes, this paper proposes a new loss function called range loss to effectively utilize the whole long tailed data in training process. More specifically, range loss is designed to reduce overall intra-personal variations while enlarging inter-personal differences within one mini-batch simultaneously when facing even extremely unbalanced data. The optimization objective of range loss is the $k$ greatest range's harmonic mean values in one class and the shortest inter-class distance within one batch. Extensive experiments on two famous and challenging face recognition benchmarks (Labeled Faces in the Wild (LFW) and YouTube Faces (YTF) not only demonstrate the effectiveness of the proposed approach in overcoming the long tail effect but also show the good generalization ability of the proposed approach.