 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Visuo-Lingustic Question Answering (DVLQA) Challenge
May 01, 2020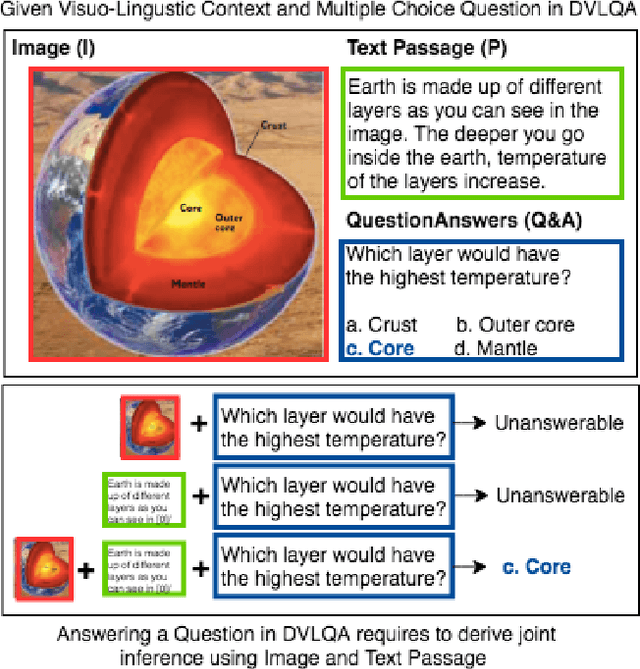
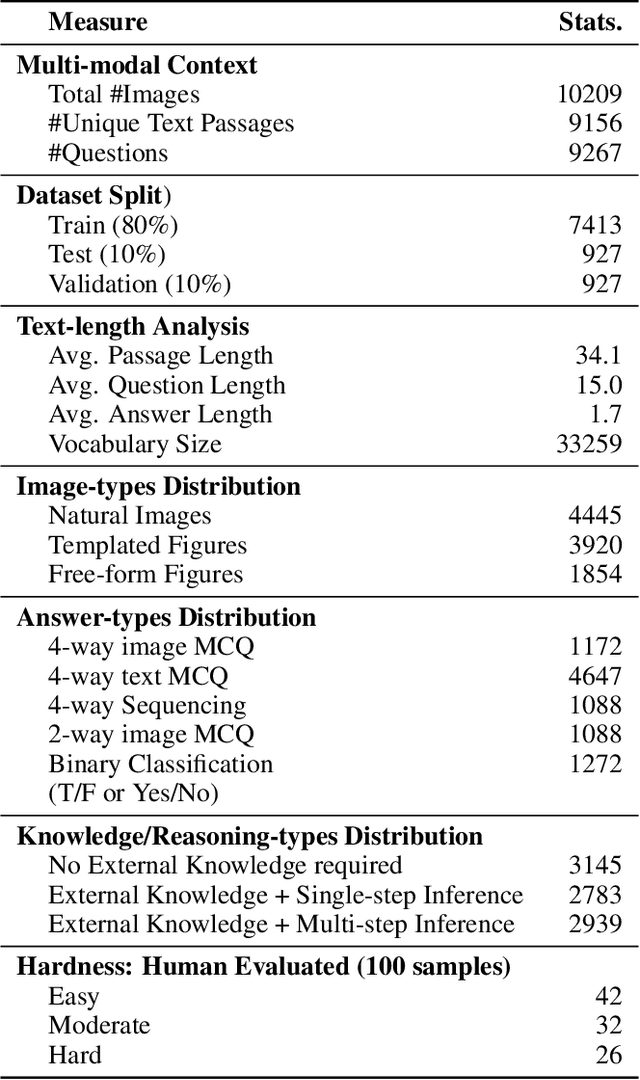
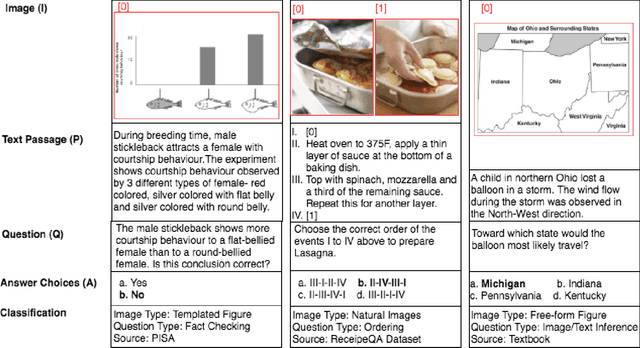

Existing question answering datasets mostly contain homogeneous contexts, based on either textual or visual information alone. On the other hand, digitalization has evolved the nature of reading which often includes integrating information across multiple heterogeneous sources. To bridge the gap between two, we compile a Diverse Visuo-Lingustic Question Answering (DVLQA) challenge corpus, where the task is to derive joint inference about the given image-text modality in a question answering setting. Each dataset item consists of an image and a reading passage, where questions are designed to combine both visual and textual information, i.e. ignoring either of them would make the question unanswerable. We first explore the combination of best existing deep learning architectures for visual question answering and machine comprehension to solve DVLQA subsets and show that they are unable to reason well on the joint task. We then develop a modular method which demonstrates slightly better baseline performance and offers more transparency for interpretation of intermediate outputs. However, this is still far behind the human performance, therefore we believe DVLQA will be a challenging benchmark for question answering involving reasoning over visuo-linguistic context. The dataset, code and public leaderboard will be made available at https://github.com/shailaja183/DVLQA.
Blocksworld Revisited: Learning and Reasoning to Generate Event-Sequences from Image Pairs
May 28, 2019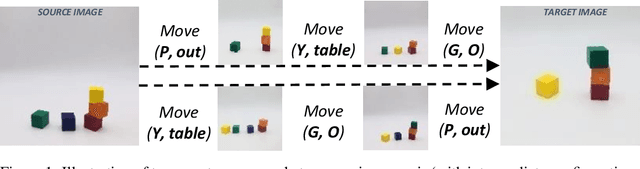
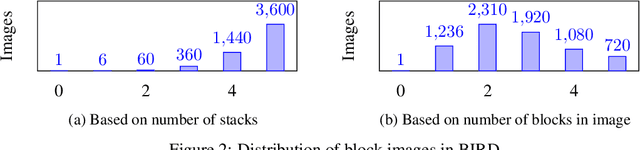
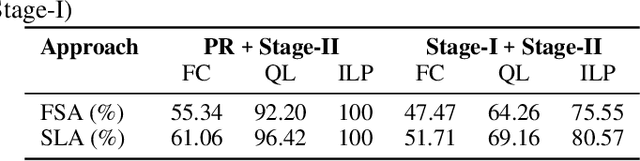
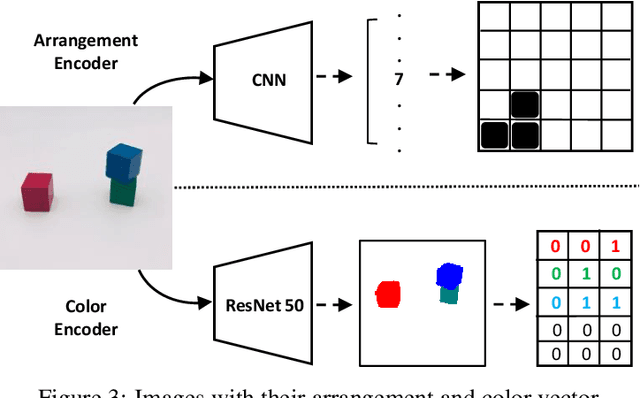
The process of identifying changes or transformations in a scene along with the ability of reasoning about their causes and effects, is a key aspect of intelligence. In this work we go beyond recent advances in computational perception, and introduce a more challenging task, Image-based Event-Sequencing (IES). In IES, the task is to predict a sequence of actions required to rearrange objects from the configuration in an input source image to the one in the target image. IES also requires systems to possess inductive generalizability. Motivated from evidence in cognitive development, we compile the first IES dataset, the Blocksworld Image Reasoning Dataset (BIRD) which contains images of wooden blocks in different configurations, and the sequence of moves to rearrange one configuration to the other. We first explore the use of existing deep learning architectures and show that these end-to-end methods under-perform in inferring temporal event-sequences and fail at inductive generalization. We then propose a modular two-step approach: Visual Perception followed by Event-Sequencing, and demonstrate improved performance by combining learning and reasoning. Finally, by showing an extension of our approach on natural images, we seek to pave the way for future research on event sequencing for real world scenes.