 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Continual Deepfake Detection Benchmark: Dataset, Methods, and Essentials
May 14, 2022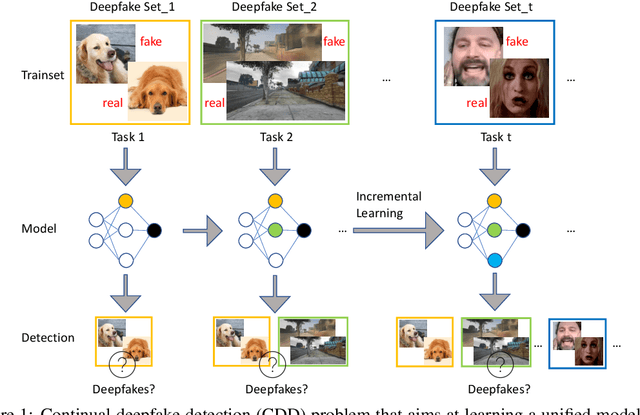

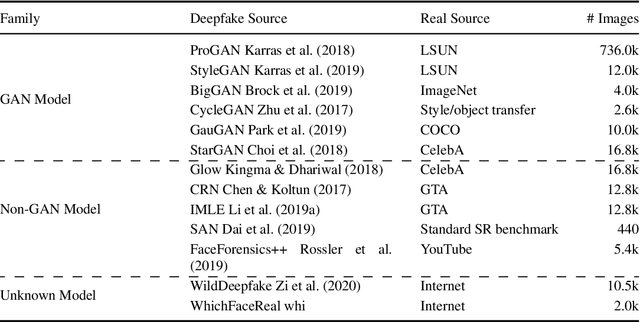
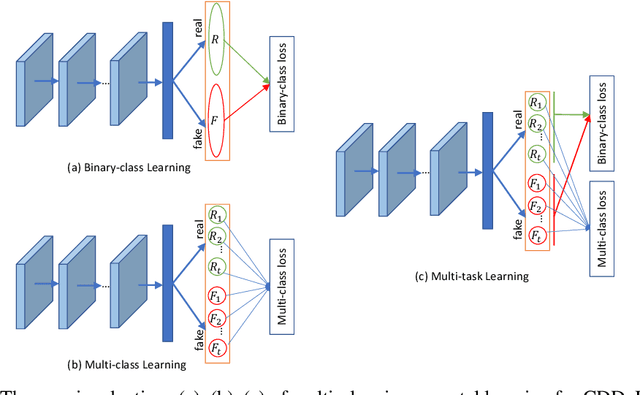
There have been emerging a number of benchmarks and techniques for the detection of deepfakes. However, very few works study the detection of incrementally appearing deepfakes in the real-world scenarios. To simulate the wild scenes, this paper suggests a continual deepfake detection benchmark (CDDB) over a new collection of deepfakes from both known and unknown generative models. The suggested CDDB designs multiple evaluations on the detection over easy, hard, and long sequence of deepfake tasks, with a set of appropriate measures. In addition, we exploit multiple approaches to adapt multiclass incremental learning methods, commonly used in the continual visual recognition, to the continual deepfake detection problem. We evaluate several methods, including the adapted ones, on the proposed CDDB. Within the proposed benchmark, we explore some commonly known essentials of standard continual learning. Our study provides new insights on these essentials in the context of continual deepfake detection. The suggested CDDB is clearly more challenging than the existing benchmarks, which thus offers a suitable evaluation avenue to the future research. Our benchmark dataset and the source code will be made publicly available.
Multi-agent Actor-Critic with Time Dynamical Opponent Model
Apr 12, 2022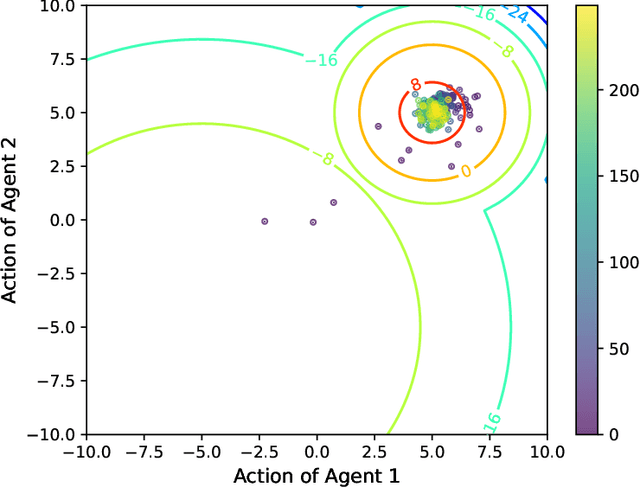

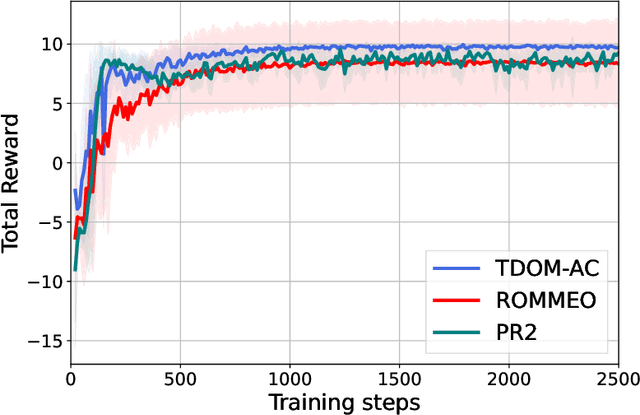

In multi-agent reinforcement learning, multiple agents learn simultaneously while interacting with a common environment and each other. Since the agents adapt their policies during learning, not only the behavior of a single agent becomes non-stationary, but also the environment as perceived by the agent. This renders it particularly challenging to perform policy improvement. In this paper, we propose to exploit the fact that the agents seek to improve their expected cumulative reward and introduce a novel \textit{Time Dynamical Opponent Model} (TDOM) to encode the knowledge that the opponent policies tend to improve over time. We motivate TDOM theoretically by deriving a lower bound of the log objective of an individual agent and further propose \textit{Multi-Agent Actor-Critic with Time Dynamical Opponent Model} (TDOM-AC). We evaluate the proposed TDOM-AC on a differential game and the Multi-agent Particle Environment. We show empirically that TDOM achieves superior opponent behavior prediction during test time. The proposed TDOM-AC methodology outperforms state-of-the-art Actor-Critic methods on the performed experiments in cooperative and \textbf{especially} in mixed cooperative-competitive environments. TDOM-AC results in a more stable training and a faster convergence.
MSNet: A Deep Multi-scale Submanifold Network for Visual Classification
Jan 29, 2022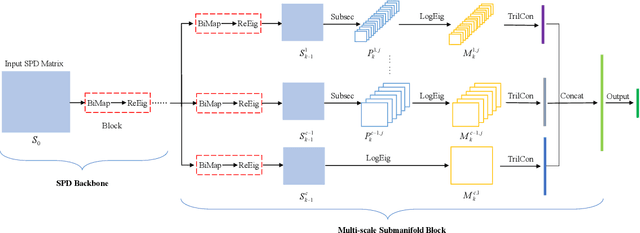
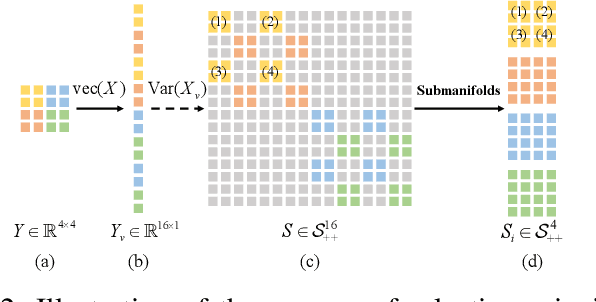


The Symmetric Positive Definite (SPD) matrix has received wide attention as a tool for visual data representation in computer vision. Although there are many different attempts to develop effective deep architectures for data processing on the Riemannian manifold of SPD matrices, a very few solutions explicitly mine the local geometrical information in deep SPD feature representations. While CNNs have demonstrated the potential of hierarchical local pattern extraction even for SPD represented data, we argue that it is of utmost importance to ensure the preservation of local geometric information in the SPD networks. Accordingly, in this work we propose an SPD network designed with this objective in mind. In particular, we propose an architecture, referred to as MSNet, which fuses geometrical multi-scale information. We first analyse the convolution operator commonly used for mapping the local information in Euclidean deep networks from the perspective of a higher level of abstraction afforded by the Category Theory. Based on this analysis, we postulate a submanifold selection principle to guide the design of our MSNet. In particular, we use it to design a submanifold fusion block to take advantage of the rich local geometry encoded in the network layers. The experiments involving multiple visual tasks show that our algorithm outperforms most Riemannian SOTA competitors.
Neural Architecture Search for Efficient Uncalibrated Deep Photometric Stereo
Oct 11, 2021

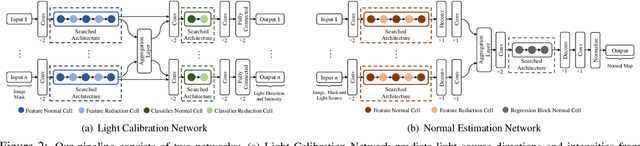

We present an automated machine learning approach for uncalibrated photometric stereo (PS). Our work aims at discovering lightweight and computationally efficient PS neural networks with excellent surface normal accuracy. Unlike previous uncalibrated deep PS networks, which are handcrafted and carefully tuned, we leverage differentiable neural architecture search (NAS) strategy to find uncalibrated PS architecture automatically. We begin by defining a discrete search space for a light calibration network and a normal estimation network, respectively. We then perform a continuous relaxation of this search space and present a gradient-based optimization strategy to find an efficient light calibration and normal estimation network. Directly applying the NAS methodology to uncalibrated PS is not straightforward as certain task-specific constraints must be satisfied, which we impose explicitly. Moreover, we search for and train the two networks separately to account for the Generalized Bas-Relief (GBR) ambiguity. Extensive experiments on the DiLiGenT dataset show that the automatically searched neural architectures performance compares favorably with the state-of-the-art uncalibrated PS methods while having a lower memory footprint.
Generative Flows with Invertible Attentions
Jun 26, 2021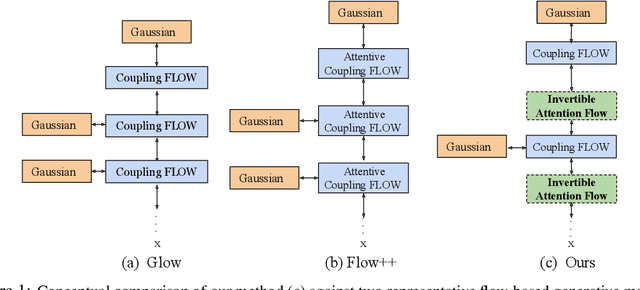
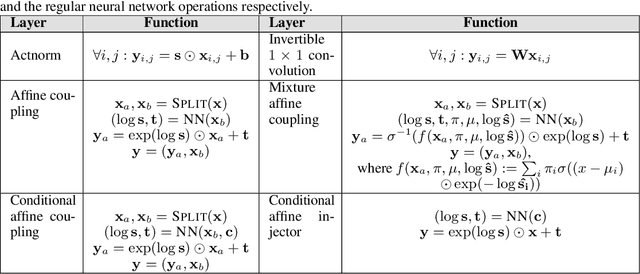
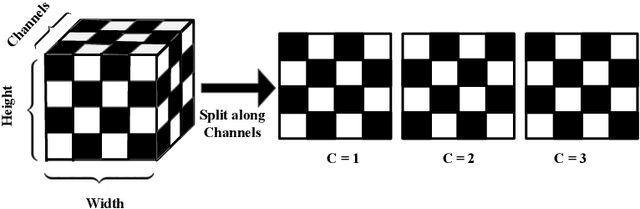
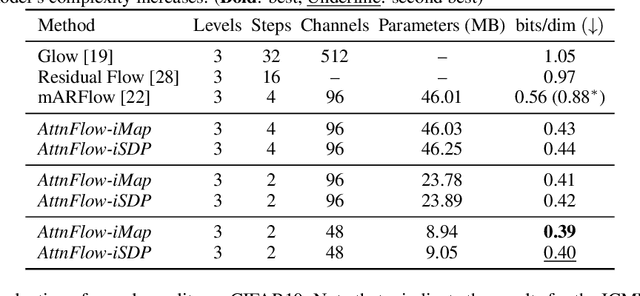
Flow-based generative models have shown excellent ability to explicitly learn the probability density function of data via a sequence of invertible transformations. Yet, modeling long-range dependencies over normalizing flows remains understudied. To fill the gap, in this paper, we introduce two types of invertible attention mechanisms for generative flow models. To be precise, we propose map-based and scaled dot-product attention for unconditional and conditional generative flow models. The key idea is to exploit split-based attention mechanisms to learn the attention weights and input representations on every two splits of flow feature maps. Our method provides invertible attention modules with tractable Jacobian determinants, enabling seamless integration of it at any positions of the flow-based models. The proposed attention mechanism can model the global data dependencies, leading to more comprehensive flow models. Evaluation on multiple generation tasks demonstrates that the introduced attention flow idea results in efficient flow models and compares favorably against the state-of-the-art unconditional and conditional generative flow methods.
Direct Differentiable Augmentation Search
Apr 09, 2021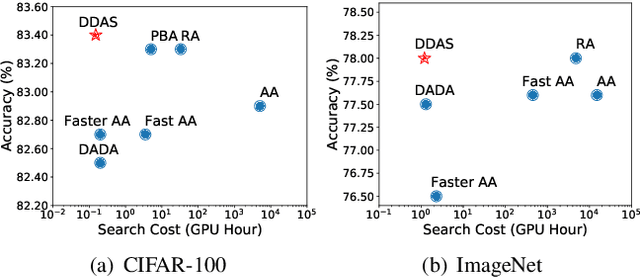

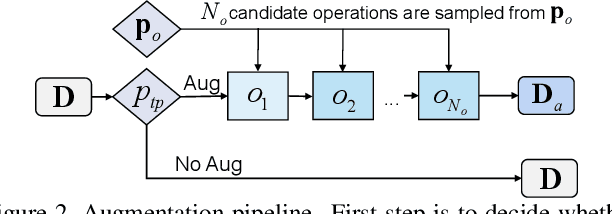
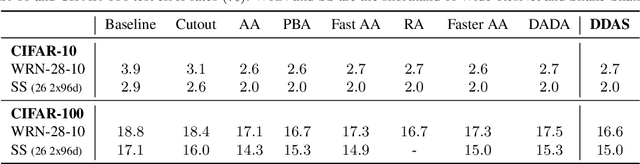
Data augmentation has been an indispensable tool to improve the performance of deep neural networks, however the augmentation can hardly transfer among different tasks and datasets. Consequently, a recent trend is to adopt AutoML technique to learn proper augmentation policy without extensive hand-crafted tuning. In this paper, we propose an efficient differentiable search algorithm called Direct Differentiable Augmentation Search (DDAS). It exploits meta-learning with one-step gradient update and continuous relaxation to the expected training loss for efficient search. Our DDAS can achieve efficient augmentation search without relying on approximations such as Gumbel Softmax or second order gradient approximation. To further reduce the adverse effect of improper augmentations, we organize the search space into a two level hierarchy, in which we first decide whether to apply augmentation, and then determine the specific augmentation policy. On standard image classification benchmarks, our DDAS achieves state-of-the-art performance and efficiency tradeoff while reducing the search cost dramatically, e.g. 0.15 GPU hours for CIFAR-10. In addition, we also use DDAS to search augmentation for object detection task and achieve comparable performance with AutoAugment, while being 1000x faster.
Spectral Tensor Train Parameterization of Deep Learning Layers
Mar 07, 2021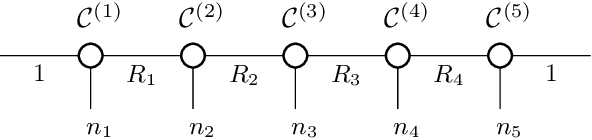


We study low-rank parameterizations of weight matrices with embedded spectral properties in the Deep Learning context. The low-rank property leads to parameter efficiency and permits taking computational shortcuts when computing mappings. Spectral properties are often subject to constraints in optimization problems, leading to better models and stability of optimization. We start by looking at the compact SVD parameterization of weight matrices and identifying redundancy sources in the parameterization. We further apply the Tensor Train (TT) decomposition to the compact SVD components, and propose a non-redundant differentiable parameterization of fixed TT-rank tensor manifolds, termed the Spectral Tensor Train Parameterization (STTP). We demonstrate the effects of neural network compression in the image classification setting and both compression and improved training stability in the generative adversarial training setting.
Efficient Conditional GAN Transfer with Knowledge Propagation across Classes
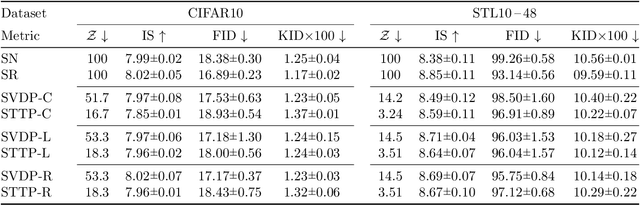
Feb 12, 2021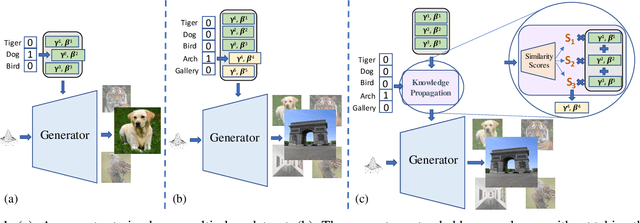



Generative adversarial networks (GANs) have shown impressive results in both unconditional and conditional image generation. In recent literature, it is shown that pre-trained GANs, on a different dataset, can be transferred to improve the image generation from a small target data. The same, however, has not been well-studied in the case of conditional GANs (cGANs), which provides new opportunities for knowledge transfer compared to unconditional setup. In particular, the new classes may borrow knowledge from the related old classes, or share knowledge among themselves to improve the training. This motivates us to study the problem of efficient conditional GAN transfer with knowledge propagation across classes. To address this problem, we introduce a new GAN transfer method to explicitly propagate the knowledge from the old classes to the new classes. The key idea is to enforce the popularly used conditional batch normalization (BN) to learn the class-specific information of the new classes from that of the old classes, with implicit knowledge sharing among the new ones. This allows for an efficient knowledge propagation from the old classes to the new classes, with the BN parameters increasing linearly with the number of new classes. The extensive evaluation demonstrates the clear superiority of the proposed method over state-of-the-art competitors for efficient conditional GAN transfer tasks. The code will be available at: https://github.com/mshahbazi72/cGANTransfer
Trilevel Neural Architecture Search for Efficient Single Image Super-Resolution
Jan 17, 2021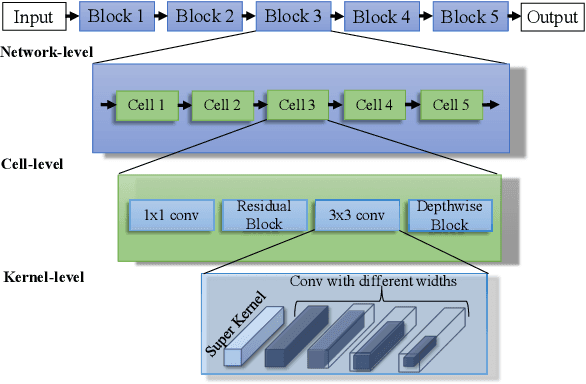
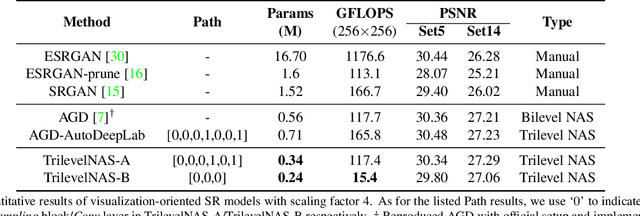
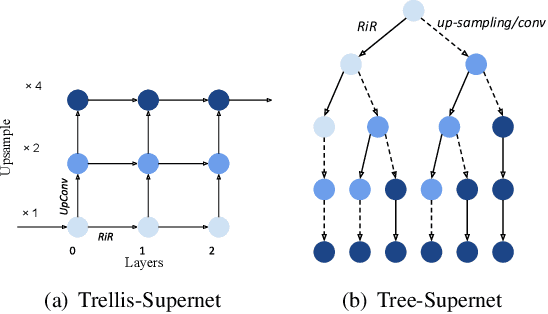
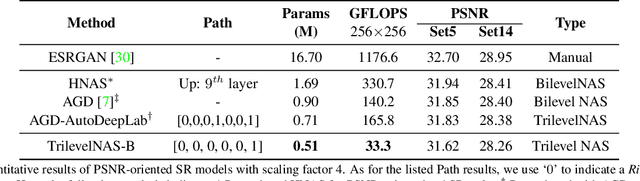
This paper proposes a trilevel neural architecture search (NAS) method for efficient single image super-resolution (SR). For that, we first define the discrete search space at three-level, i.e., at network-level, cell-level, and kernel-level (convolution-kernel). For modeling the discrete search space, we apply a new continuous relaxation on the discrete search spaces to build a hierarchical mixture of network-path, cell-operations, and kernel-width. Later an efficient search algorithm is proposed to perform optimization in a hierarchical supernet manner that provides a globally optimized and compressed network via joint convolution kernel width pruning, cell structure search, and network path optimization. Unlike current NAS methods, we exploit a sorted sparsestmax activation to let the three-level neural structures contribute sparsely. Consequently, our NAS optimization progressively converges to those neural structures with dominant contributions to the supernet. Additionally, our proposed optimization construction enables a simultaneous search and training in a single phase, which dramatically reduces search and train time compared to the traditional NAS algorithms. Experiments on the standard benchmark datasets demonstrate that our NAS algorithm provides SR models that are significantly lighter in terms of the number of parameters and FLOPS with PSNR value comparable to the current state-of-the-art.
An Efficient Recurrent Adversarial Framework for Unsupervised Real-Time Video Enhancement
Dec 24, 2020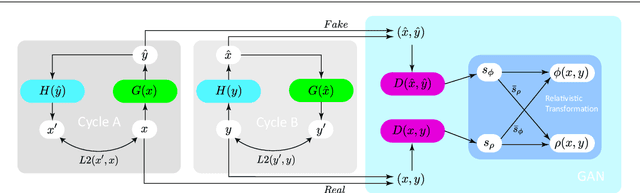
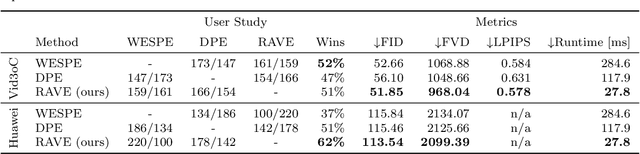

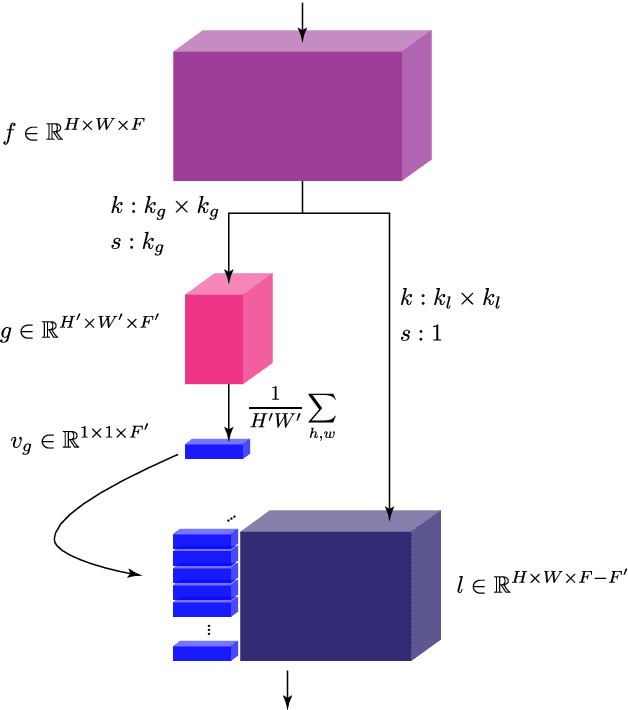
Video enhancement is a challenging problem, more than that of stills, mainly due to high computational cost, larger data volumes and the difficulty of achieving consistency in the spatio-temporal domain. In practice, these challenges are often coupled with the lack of example pairs, which inhibits the application of supervised learning strategies. To address these challenges, we propose an efficient adversarial video enhancement framework that learns directly from unpaired video examples. In particular, our framework introduces new recurrent cells that consist of interleaved local and global modules for implicit integration of spatial and temporal information. The proposed design allows our recurrent cells to efficiently propagate spatio-temporal information across frames and reduces the need for high complexity networks. Our setting enables learning from unpaired videos in a cyclic adversarial manner, where the proposed recurrent units are employed in all architectures. Efficient training is accomplished by introducing one single discriminator that learns the joint distribution of source and target domain simultaneously. The enhancement results demonstrate clear superiority of the proposed video enhancer over the state-of-the-art methods, in all terms of visual quality, quantitative metrics, and inference speed. Notably, our video enhancer is capable of enhancing over 35 frames per second of FullHD video (1080x1920).