 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Inverted-Index Routing for Granular Mixtures-of-Experts
May 06, 2026Mixture-of-experts (MoE) models enable scalable transformer architectures by activating only a subset of experts per token. Recent evidence suggests that performance improves with increasingly granular experts, i.e., many small experts instead of a few large ones. However, this regime substantially increases routing cost, which can dominate computation. We introduce adaptive inverted-index routing for MoE (AIR-MoE), an inverted-index-inspired routing architecture based on vector quantization (VQ). In a first stage, AIR-MoE performs coarse shortlisting by assigning tokens to VQ codewords to construct a candidate set of experts. In a second stage, fine scoring computes exact routing scores restricted to this shortlist. This two-stage procedure approximates true top-k routing while avoiding full expert scoring and, in contrast to prior work, imposing no structural constraints on expert parameters. AIR-MoE serves as a drop-in replacement for standard routers and requires no modifications to the model architecture or loss function. We further provide a lower bound on the mass recall achieved by AIR-MoE that yields insights into its inner workings. Empirically, we demonstrate that AIR-MoE achieves improved performance compared to existing routing approaches in granular MoE settings.
A Critical Perspective on Finite Sample Conformal Prediction Theory in Medical Applications
Dec 09, 2025Machine learning (ML) is transforming healthcare, but safe clinical decisions demand reliable uncertainty estimates that standard ML models fail to provide. Conformal prediction (CP) is a popular tool that allows users to turn heuristic uncertainty estimates into uncertainty estimates with statistical guarantees. CP works by converting predictions of a ML model, together with a calibration sample, into prediction sets that are guaranteed to contain the true label with any desired probability. An often cited advantage is that CP theory holds for calibration samples of arbitrary size, suggesting that uncertainty estimates with practically meaningful statistical guarantees can be achieved even if only small calibration sets are available. We question this promise by showing that, although the statistical guarantees hold for calibration sets of arbitrary size, the practical utility of these guarantees does highly depend on the size of the calibration set. This observation is relevant in medical domains because data is often scarce and obtaining large calibration sets is therefore infeasible. We corroborate our critique in an empirical demonstration on a medical image classification task.
PENEX: AdaBoost-Inspired Neural Network Regularization
Oct 02, 2025AdaBoost sequentially fits so-called weak learners to minimize an exponential loss, which penalizes mislabeled data points more severely than other loss functions like cross-entropy. Paradoxically, AdaBoost generalizes well in practice as the number of weak learners grows. In the present work, we introduce Penalized Exponential Loss (PENEX), a new formulation of the multi-class exponential loss that is theoretically grounded and, in contrast to the existing formulation, amenable to optimization via first-order methods. We demonstrate both empirically and theoretically that PENEX implicitly maximizes margins of data points. Also, we show that gradient increments on PENEX implicitly parameterize weak learners in the boosting framework. Across computer vision and language tasks, we show that PENEX exhibits a regularizing effect often better than established methods with similar computational cost. Our results highlight PENEX's potential as an AdaBoost-inspired alternative for effective training and fine-tuning of deep neural networks.
Conformal Generative Modeling with Improved Sample Efficiency through Sequential Greedy Filtering
Oct 02, 2024



Generative models lack rigorous statistical guarantees for their outputs and are therefore unreliable in safety-critical applications. In this work, we propose Sequential Conformal Prediction for Generative Models (SCOPE-Gen), a sequential conformal prediction method producing prediction sets that satisfy a rigorous statistical guarantee called conformal admissibility control. This guarantee states that with high probability, the prediction sets contain at least one admissible (or valid) example. To this end, our method first samples an initial set of i.i.d. examples from a black box generative model. Then, this set is iteratively pruned via so-called greedy filters. As a consequence of the iterative generation procedure, admissibility of the final prediction set factorizes as a Markov chain. This factorization is crucial, because it allows to control each factor separately, using conformal prediction. In comparison to prior work, our method demonstrates a large reduction in the number of admissibility evaluations during calibration. This reduction is important in safety-critical applications, where these evaluations must be conducted manually by domain experts and are therefore costly and time consuming. We highlight the advantages of our method in terms of admissibility evaluations and cardinality of the prediction sets through experiments in natural language generation and molecular graph extension tasks.
Deep Backtracking Counterfactuals for Causally Compliant Explanations
Oct 11, 2023



Counterfactuals can offer valuable insights by answering what would have been observed under altered circumstances, conditional on a factual observation. Whereas the classical interventional interpretation of counterfactuals has been studied extensively, backtracking constitutes a less studied alternative the backtracking principle has emerged as an alternative philosophy where all causal laws are kept intact. In the present work, we introduce a practical method for computing backtracking counterfactuals in structural causal models that consist of deep generative components. To this end, we impose conditions on the structural assignments that enable the generation of counterfactuals by solving a tractable constrained optimization problem in the structured latent space of a causal model. Our formulation also facilitates a comparison with methods in the field of counterfactual explanations. Compared to these, our method represents a versatile, modular and causally compliant alternative. We demonstrate these properties experimentally on a modified version of MNIST and CelebA.
Causal Effect Estimation from Observational and Interventional Data Through Matrix Weighted Linear Estimators
Jun 09, 2023



We study causal effect estimation from a mixture of observational and interventional data in a confounded linear regression model with multivariate treatments. We show that the statistical efficiency in terms of expected squared error can be improved by combining estimators arising from both the observational and interventional setting. To this end, we derive methods based on matrix weighted linear estimators and prove that our methods are asymptotically unbiased in the infinite sample limit. This is an important improvement compared to the pooled estimator using the union of interventional and observational data, for which the bias only vanishes if the ratio of observational to interventional data tends to zero. Studies on synthetic data confirm our theoretical findings. In settings where confounding is substantial and the ratio of observational to interventional data is large, our estimators outperform a Stein-type estimator and various other baselines.
Multi-agent Actor-Critic with Time Dynamical Opponent Model
Apr 12, 2022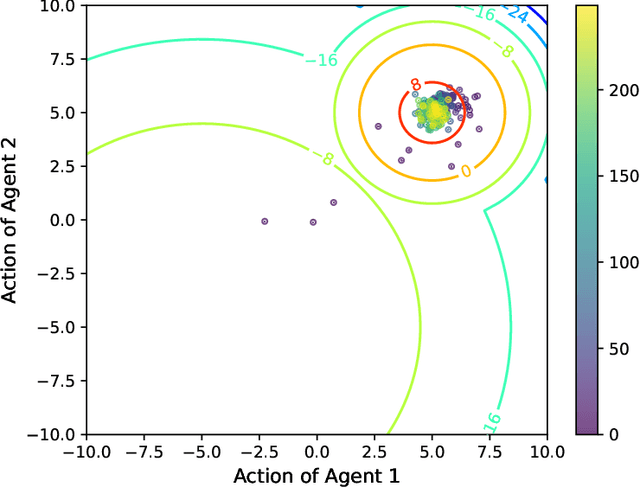

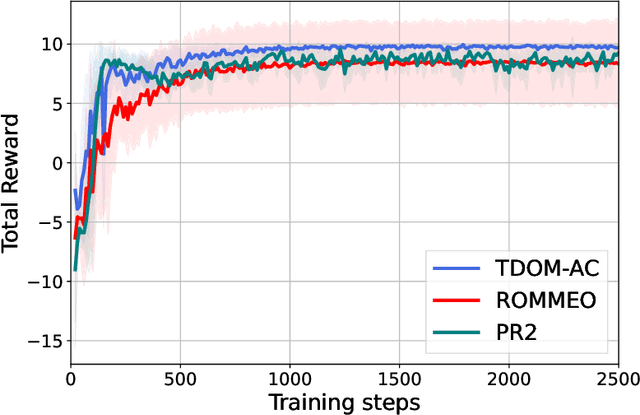

In multi-agent reinforcement learning, multiple agents learn simultaneously while interacting with a common environment and each other. Since the agents adapt their policies during learning, not only the behavior of a single agent becomes non-stationary, but also the environment as perceived by the agent. This renders it particularly challenging to perform policy improvement. In this paper, we propose to exploit the fact that the agents seek to improve their expected cumulative reward and introduce a novel \textit{Time Dynamical Opponent Model} (TDOM) to encode the knowledge that the opponent policies tend to improve over time. We motivate TDOM theoretically by deriving a lower bound of the log objective of an individual agent and further propose \textit{Multi-Agent Actor-Critic with Time Dynamical Opponent Model} (TDOM-AC). We evaluate the proposed TDOM-AC on a differential game and the Multi-agent Particle Environment. We show empirically that TDOM achieves superior opponent behavior prediction during test time. The proposed TDOM-AC methodology outperforms state-of-the-art Actor-Critic methods on the performed experiments in cooperative and \textbf{especially} in mixed cooperative-competitive environments. TDOM-AC results in a more stable training and a faster convergence.