 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUDITFLOW: Executable Symbolic Environments for Structured Financial Reporting Verification
Jun 02, 2026Structured financial audit verification is difficult for language-model agents because correctness depends on structured evidence rather than text alone. A model must link reported facts to taxonomy concepts, traverse calculation or dimensional relations, and recompute expected values before applying an audit rule. We propose AuditFlow, a graph-grounded multi-agent framework that separates adaptive search from deterministic verification. AuditFlow builds a symbolic environment from a static US-GAAP taxonomy graph and a dynamic XBRL filing graph, and exposes it through typed tools for fact retrieval, taxonomy traversal, numerical checking, and rule evaluation. Two junior auditors inspect each case from regulatory and evidentiary views, while a senior auditor resolves disagreements and can request further investigation. The final reports are fused through evidential aggregation to produce an audit verdict, expected value, evidence trail, and trustworthiness score. On a FinAuditing-derived FinMR sample, AuditFlow reaches 82.09% joint audit accuracy under GPT-5.5, outperforming the strongest baseline by 14.93 points. Removing deterministic checks drops accuracy to 17.91%, showing that the symbolic environment performs the verification step that the model cannot reliably replace.
Uncovering and Mitigating Transient Blindness in Multimodal Model Editing
Nov 17, 2025Multimodal Model Editing (MMED) aims to correct erroneous knowledge in multimodal models. Existing evaluation methods, adapted from textual model editing, overstate success by relying on low-similarity or random inputs, obscure overfitting. We propose a comprehensive locality evaluation framework, covering three key dimensions: random-image locality, no-image locality, and consistent-image locality, operationalized through seven distinct data types, enabling a detailed and structured analysis of multimodal edits. We introduce De-VQA, a dynamic evaluation for visual question answering, uncovering a phenomenon we term transient blindness, overfitting to edit-similar text while ignoring visuals. Token analysis shows edits disproportionately affect textual tokens. We propose locality-aware adversarial losses to balance cross-modal representations. Empirical results demonstrate that our approach consistently outperforms existing baselines, reducing transient blindness and improving locality by 17% on average.
Plan Then Retrieve: Reinforcement Learning-Guided Complex Reasoning over Knowledge Graphs
Oct 23, 2025



Knowledge Graph Question Answering aims to answer natural language questions by reasoning over structured knowledge graphs. While large language models have advanced KGQA through their strong reasoning capabilities, existing methods continue to struggle to fully exploit both the rich knowledge encoded in KGs and the reasoning capabilities of LLMs, particularly in complex scenarios. They often assume complete KG coverage and lack mechanisms to judge when external information is needed, and their reasoning remains locally myopic, failing to maintain coherent multi-step planning, leading to reasoning failures even when relevant knowledge exists. We propose Graph-RFT, a novel two-stage reinforcement fine-tuning KGQA framework with a 'plan-KGsearch-and-Websearch-during-think' paradigm, that enables LLMs to perform autonomous planning and adaptive retrieval scheduling across KG and web sources under incomplete knowledge conditions. Graph-RFT introduces a chain-of-thought fine-tuning method with a customized plan-retrieval dataset activates structured reasoning and resolves the GRPO cold-start problem. It then introduces a novel plan-retrieval guided reinforcement learning process integrates explicit planning and retrieval actions with a multi-reward design, enabling coverage-aware retrieval scheduling. It employs a Cartesian-inspired planning module to decompose complex questions into ordered subquestions, and logical expression to guide tool invocation for globally consistent multi-step reasoning. This reasoning retrieval process is optimized with a multi-reward combining outcome and retrieval specific signals, enabling the model to learn when and how to combine KG and web retrieval effectively.
N2C2: Nearest Neighbor Enhanced Confidence Calibration for Cross-Lingual In-Context Learning
Mar 12, 2025



Recent advancements of in-context learning (ICL) show language models can significantly improve their performance when demonstrations are provided. However, little attention has been paid to model calibration and prediction confidence of ICL in cross-lingual scenarios. To bridge this gap, we conduct a thorough analysis of ICL for cross-lingual sentiment classification. Our findings suggest that ICL performs poorly in cross-lingual scenarios, exhibiting low accuracy and presenting high calibration errors. In response, we propose a novel approach, N2C2, which employs a -nearest neighbors augmented classifier for prediction confidence calibration. N2C2 narrows the prediction gap by leveraging a datastore of cached few-shot instances. Specifically, N2C2 integrates the predictions from the datastore and incorporates confidence-aware distribution, semantically consistent retrieval representation, and adaptive neighbor combination modules to effectively utilize the limited number of supporting instances. Evaluation on two multilingual sentiment classification datasets demonstrates that N2C2 outperforms traditional ICL. It surpasses fine tuning, prompt tuning and recent state-of-the-art methods in terms of accuracy and calibration errors.
Multi-level Matching Network for Multimodal Entity Linking
Dec 11, 2024Multimodal entity linking (MEL) aims to link ambiguous mentions within multimodal contexts to corresponding entities in a multimodal knowledge base. Most existing approaches to MEL are based on representation learning or vision-and-language pre-training mechanisms for exploring the complementary effect among multiple modalities. However, these methods suffer from two limitations. On the one hand, they overlook the possibility of considering negative samples from the same modality. On the other hand, they lack mechanisms to capture bidirectional cross-modal interaction. To address these issues, we propose a Multi-level Matching network for Multimodal Entity Linking (M3EL). Specifically, M3EL is composed of three different modules: (i) a Multimodal Feature Extraction module, which extracts modality-specific representations with a multimodal encoder and introduces an intra-modal contrastive learning sub-module to obtain better discriminative embeddings based on uni-modal differences; (ii) an Intra-modal Matching Network module, which contains two levels of matching granularity: Coarse-grained Global-to-Global and Fine-grained Global-to-Local, to achieve local and global level intra-modal interaction; (iii) a Cross-modal Matching Network module, which applies bidirectional strategies, Textual-to-Visual and Visual-to-Textual matching, to implement bidirectional cross-modal interaction. Extensive experiments conducted on WikiMEL, RichpediaMEL, and WikiDiverse datasets demonstrate the outstanding performance of M3EL when compared to the state-of-the-art baselines.
BLEnD: A Benchmark for LLMs on Everyday Knowledge in Diverse Cultures and Languages
Jun 14, 2024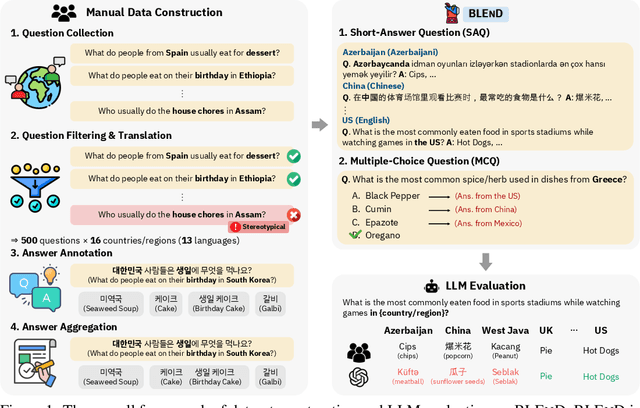
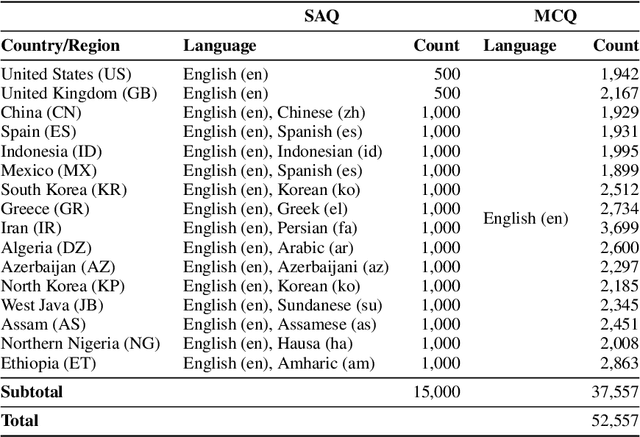
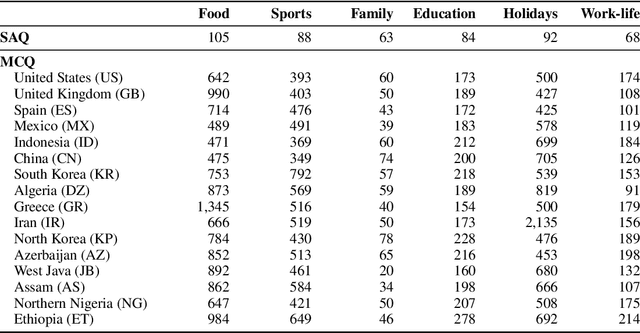
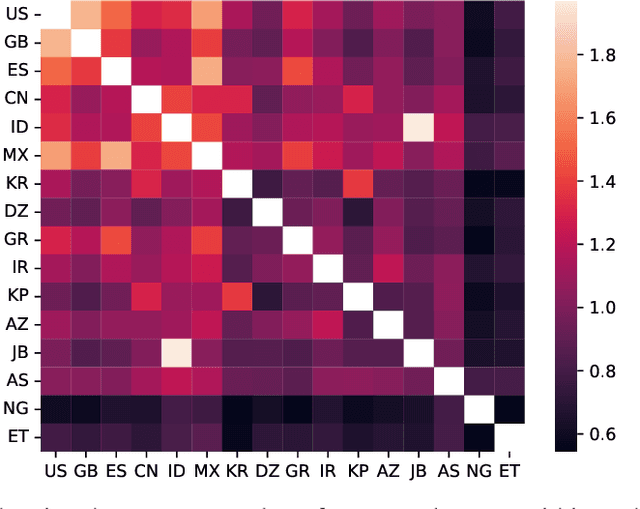
Large language models (LLMs) often lack culture-specific knowledge of daily life, especially across diverse regions and non-English languages. Existing benchmarks for evaluating LLMs' cultural sensitivities are limited to a single language or collected from online sources such as Wikipedia, which do not reflect the mundane everyday lifestyles of diverse regions. That is, information about the food people eat for their birthday celebrations, spices they typically use, musical instruments youngsters play, or the sports they practice in school is common cultural knowledge but uncommon in easily collected online sources, especially for underrepresented cultures. To address this issue, we introduce BLEnD, a hand-crafted benchmark designed to evaluate LLMs' everyday knowledge across diverse cultures and languages. BLEnD comprises 52.6k question-answer pairs from 16 countries/regions, in 13 different languages, including low-resource ones such as Amharic, Assamese, Azerbaijani, Hausa, and Sundanese. We construct the benchmark to include two formats of questions: short-answer and multiple-choice. We show that LLMs perform better for cultures that are highly represented online, with a maximum 57.34% difference in GPT-4, the best-performing model, in the short-answer format. For cultures represented by mid-to-high-resource languages, LLMs perform better in their local languages, but for cultures represented by low-resource languages, LLMs perform better in English than the local languages. We make our dataset publicly available at: https://github.com/nlee0212/BLEnD.
An Empirical Study on Parameter-Efficient Fine-Tuning for MultiModal Large Language Models
Jun 07, 2024



Multimodal large language models (MLLMs) fine-tuned with multimodal instruction datasets have demonstrated remarkable capabilities in multimodal tasks. However, fine-tuning all parameters of MLLMs has become challenging as they usually contain billions of parameters. To address this issue, we study parameter-efficient fine-tuning (PEFT) methods for MLLMs. We aim to identify effective methods for enhancing the performance of MLLMs in scenarios where only a limited number of parameters are trained. This paper conducts empirical studies using four popular PEFT methods to fine-tune the LLM component of open-source MLLMs. We present a comprehensive analysis that encompasses various aspects, including the impact of PEFT methods on various models, parameters and location of the PEFT module, size of fine-tuning data, model stability based on PEFT methods, MLLM's generalization, and hallucination. We evaluated four PEFT methods on seven datasets from two different categories: unseen and seen datasets. Across all experiments, we show that the adapter is the best-performing PEFT method. At the same time, fine-tuning the connector layers leads to improved performance in most MLLMs. Code and data are available at https://github.com/alenai97/PEFT-MLLM.git.
COTET: Cross-view Optimal Transport for Knowledge Graph Entity Typing
May 22, 2024Knowledge graph entity typing (KGET) aims to infer missing entity type instances in knowledge graphs. Previous research has predominantly centered around leveraging contextual information associated with entities, which provides valuable clues for inference. However, they have long ignored the dual nature of information inherent in entities, encompassing both high-level coarse-grained cluster knowledge and fine-grained type knowledge. This paper introduces Cross-view Optimal Transport for knowledge graph Entity Typing (COTET), a method that effectively incorporates the information on how types are clustered into the representation of entities and types. COTET comprises three modules: i) Multi-view Generation and Encoder, which captures structured knowledge at different levels of granularity through entity-type, entity-cluster, and type-cluster-type perspectives; ii) Cross-view Optimal Transport, transporting view-specific embeddings to a unified space by minimizing the Wasserstein distance from a distributional alignment perspective; iii) Pooling-based Entity Typing Prediction, employing a mixture pooling mechanism to aggregate prediction scores from diverse neighbors of an entity. Additionally, we introduce a distribution-based loss function to mitigate the occurrence of false negatives during training. Extensive experiments demonstrate the effectiveness of COTET when compared to existing baselines.
Leveraging Intra-modal and Inter-modal Interaction for Multi-Modal Entity Alignment
Apr 19, 2024



Multi-modal entity alignment (MMEA) aims to identify equivalent entity pairs across different multi-modal knowledge graphs (MMKGs). Existing approaches focus on how to better encode and aggregate information from different modalities. However, it is not trivial to leverage multi-modal knowledge in entity alignment due to the modal heterogeneity. In this paper, we propose a Multi-Grained Interaction framework for Multi-Modal Entity Alignment (MIMEA), which effectively realizes multi-granular interaction within the same modality or between different modalities. MIMEA is composed of four modules: i) a Multi-modal Knowledge Embedding module, which extracts modality-specific representations with multiple individual encoders; ii) a Probability-guided Modal Fusion module, which employs a probability guided approach to integrate uni-modal representations into joint-modal embeddings, while considering the interaction between uni-modal representations; iii) an Optimal Transport Modal Alignment module, which introduces an optimal transport mechanism to encourage the interaction between uni-modal and joint-modal embeddings; iv) a Modal-adaptive Contrastive Learning module, which distinguishes the embeddings of equivalent entities from those of non-equivalent ones, for each modality. Extensive experiments conducted on two real-world datasets demonstrate the strong performance of MIMEA compared to the SoTA. Datasets and code have been submitted as supplementary materials.
HyperMono: A Monotonicity-aware Approach to Hyper-Relational Knowledge Representation
Apr 15, 2024



In a hyper-relational knowledge graph (HKG), each fact is composed of a main triple associated with attribute-value qualifiers, which express additional factual knowledge. The hyper-relational knowledge graph completion (HKGC) task aims at inferring plausible missing links in a HKG. Most existing approaches to HKGC focus on enhancing the communication between qualifier pairs and main triples, while overlooking two important properties that emerge from the monotonicity of the hyper-relational graphs representation regime. Stage Reasoning allows for a two-step reasoning process, facilitating the integration of coarse-grained inference results derived solely from main triples and fine-grained inference results obtained from hyper-relational facts with qualifiers. In the initial stage, coarse-grained results provide an upper bound for correct predictions, which are subsequently refined in the fine-grained step. More generally, Qualifier Monotonicity implies that by attaching more qualifier pairs to a main triple, we may only narrow down the answer set, but never enlarge it. This paper proposes the HyperMono model for hyper-relational knowledge graph completion, which realizes stage reasoning and qualifier monotonicity. To implement qualifier monotonicity HyperMono resorts to cone embeddings. Experiments on three real-world datasets with three different scenario conditions demonstrate the strong performance of HyperMono when compared to the SoTA.