 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Weakly Supervised Multimodal Video Anomaly Detection through Text Guidance
Feb 11, 2026Weakly supervised multimodal video anomaly detection has gained significant attention, yet the potential of the text modality remains under-explored. Text provides explicit semantic information that can enhance anomaly characterization and reduce false alarms. However, extracting effective text features is challenging due to the inability of general-purpose language models to capture anomaly-specific nuances and the scarcity of relevant descriptions. Furthermore, multimodal fusion often suffers from redundancy and imbalance. To address these issues, we propose a novel text-guided framework. First, we introduce an in-context learning-based multi-stage text augmentation mechanism to generate high-quality anomaly text samples for fine-tuning the text feature extractor. Second, we design a multi-scale bottleneck Transformer fusion module that uses compressed bottleneck tokens to progressively integrate information across modalities, mitigating redundancy and imbalance. Experiments on UCF-Crime and XD-Violence demonstrate state-of-the-art performance.
Adversarial Training of Reward Models
Apr 08, 2025



Reward modeling has emerged as a promising approach for the scalable alignment of language models. However, contemporary reward models (RMs) often lack robustness, awarding high rewards to low-quality, out-of-distribution (OOD) samples. This can lead to reward hacking, where policies exploit unintended shortcuts to maximize rewards, undermining alignment. To address this challenge, we introduce Adv-RM, a novel adversarial training framework that automatically identifies adversarial examples -- responses that receive high rewards from the target RM but are OOD and of low quality. By leveraging reinforcement learning, Adv-RM trains a policy to generate adversarial examples that reliably expose vulnerabilities in large state-of-the-art reward models such as Nemotron 340B RM. Incorporating these adversarial examples into the reward training process improves the robustness of RMs, mitigating reward hacking and enhancing downstream performance in RLHF. We demonstrate that Adv-RM significantly outperforms conventional RM training, increasing stability and enabling more effective RLHF training in both synthetic and real-data settings.
Nemotron-4 340B Technical Report
Jun 17, 2024



We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
Multi-scale Bottleneck Transformer for Weakly Supervised Multimodal Violence Detection
May 08, 2024



Weakly supervised multimodal violence detection aims to learn a violence detection model by leveraging multiple modalities such as RGB, optical flow, and audio, while only video-level annotations are available. In the pursuit of effective multimodal violence detection (MVD), information redundancy, modality imbalance, and modality asynchrony are identified as three key challenges. In this work, we propose a new weakly supervised MVD method that explicitly addresses these challenges. Specifically, we introduce a multi-scale bottleneck transformer (MSBT) based fusion module that employs a reduced number of bottleneck tokens to gradually condense information and fuse each pair of modalities and utilizes a bottleneck token-based weighting scheme to highlight more important fused features. Furthermore, we propose a temporal consistency contrast loss to semantically align pairwise fused features. Experiments on the largest-scale XD-Violence dataset demonstrate that the proposed method achieves state-of-the-art performance. Code is available at https://github.com/shengyangsun/MSBT.
NeMo-Aligner: Scalable Toolkit for Efficient Model Alignment
May 02, 2024



Aligning Large Language Models (LLMs) with human values and preferences is essential for making them helpful and safe. However, building efficient tools to perform alignment can be challenging, especially for the largest and most competent LLMs which often contain tens or hundreds of billions of parameters. We create NeMo-Aligner, a toolkit for model alignment that can efficiently scale to using hundreds of GPUs for training. NeMo-Aligner comes with highly optimized and scalable implementations for major paradigms of model alignment such as: Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO), SteerLM, and Self-Play Fine-Tuning (SPIN). Additionally, our toolkit supports running most of the alignment techniques in a Parameter Efficient Fine-Tuning (PEFT) setting. NeMo-Aligner is designed for extensibility, allowing support for other alignment techniques with minimal effort. It is open-sourced with Apache 2.0 License and we invite community contributions at https://github.com/NVIDIA/NeMo-Aligner
Long-Short Temporal Co-Teaching for Weakly Supervised Video Anomaly Detection
Apr 04, 2023Weakly supervised video anomaly detection (WS-VAD) is a challenging problem that aims to learn VAD models only with video-level annotations. In this work, we propose a Long-Short Temporal Co-teaching (LSTC) method to address the WS-VAD problem. It constructs two tubelet-based spatio-temporal transformer networks to learn from short- and long-term video clips respectively. Each network is trained with respect to a multiple instance learning (MIL)-based ranking loss, together with a cross-entropy loss when clip-level pseudo labels are available. A co-teaching strategy is adopted to train the two networks. That is, clip-level pseudo labels generated from each network are used to supervise the other one at the next training round, and the two networks are learned alternatively and iteratively. Our proposed method is able to better deal with the anomalies with varying durations as well as subtle anomalies. Extensive experiments on three public datasets demonstrate that our method outperforms state-of-the-art WS-VAD methods.
Hierarchical Semantic Contrast for Scene-aware Video Anomaly Detection
Mar 23, 2023Increasing scene-awareness is a key challenge in video anomaly detection (VAD). In this work, we propose a hierarchical semantic contrast (HSC) method to learn a scene-aware VAD model from normal videos. We first incorporate foreground object and background scene features with high-level semantics by taking advantage of pre-trained video parsing models. Then, building upon the autoencoder-based reconstruction framework, we introduce both scene-level and object-level contrastive learning to enforce the encoded latent features to be compact within the same semantic classes while being separable across different classes. This hierarchical semantic contrast strategy helps to deal with the diversity of normal patterns and also increases their discrimination ability. Moreover, for the sake of tackling rare normal activities, we design a skeleton-based motion augmentation to increase samples and refine the model further. Extensive experiments on three public datasets and scene-dependent mixture datasets validate the effectiveness of our proposed method.
Information-theoretic Online Memory Selection for Continual Learning
Apr 10, 2022
A challenging problem in task-free continual learning is the online selection of a representative replay memory from data streams. In this work, we investigate the online memory selection problem from an information-theoretic perspective. To gather the most information, we propose the \textit{surprise} and the \textit{learnability} criteria to pick informative points and to avoid outliers. We present a Bayesian model to compute the criteria efficiently by exploiting rank-one matrix structures. We demonstrate that these criteria encourage selecting informative points in a greedy algorithm for online memory selection. Furthermore, by identifying the importance of \textit{the timing to update the memory}, we introduce a stochastic information-theoretic reservoir sampler (InfoRS), which conducts sampling among selective points with high information. Compared to reservoir sampling, InfoRS demonstrates improved robustness against data imbalance. Finally, empirical performances over continual learning benchmarks manifest its efficiency and efficacy.
Scalable Variational Gaussian Processes via Harmonic Kernel Decomposition
Jun 10, 2021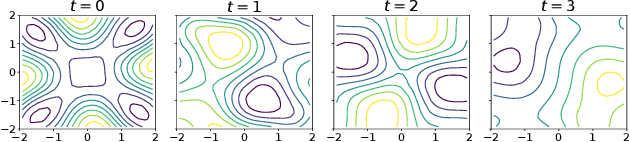
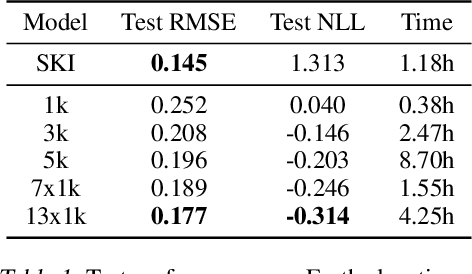
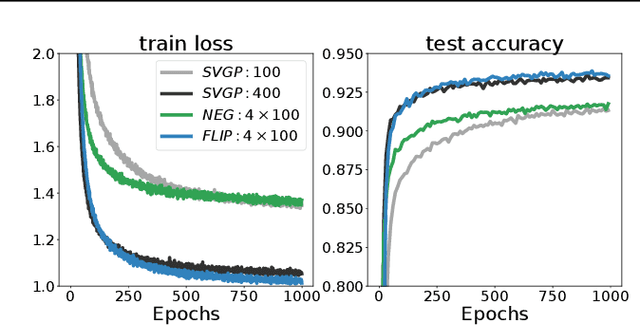
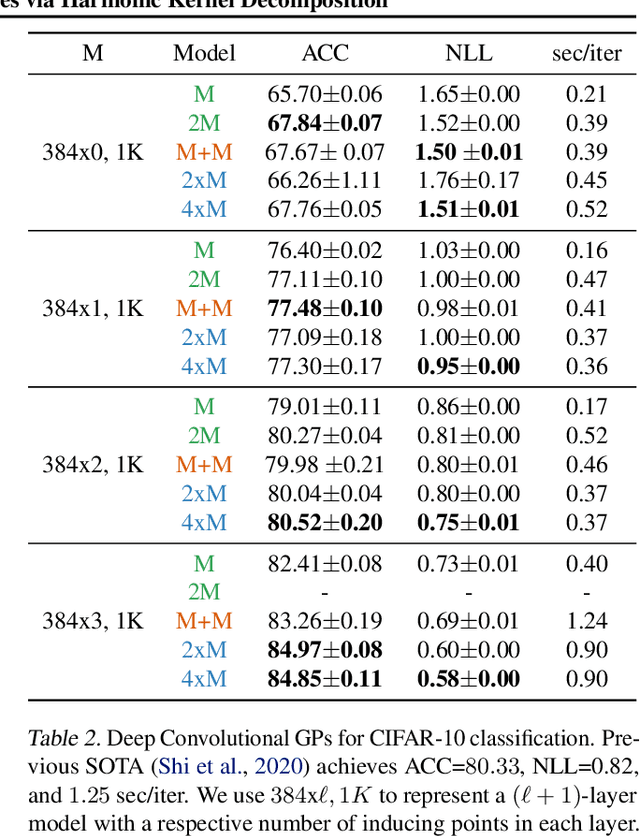
We introduce a new scalable variational Gaussian process approximation which provides a high fidelity approximation while retaining general applicability. We propose the harmonic kernel decomposition (HKD), which uses Fourier series to decompose a kernel as a sum of orthogonal kernels. Our variational approximation exploits this orthogonality to enable a large number of inducing points at a low computational cost. We demonstrate that, on a range of regression and classification problems, our approach can exploit input space symmetries such as translations and reflections, and it significantly outperforms standard variational methods in scalability and accuracy. Notably, our approach achieves state-of-the-art results on CIFAR-10 among pure GP models.
Beyond Marginal Uncertainty: How Accurately can Bayesian Regression Models Estimate Posterior Predictive Correlations?
Nov 06, 2020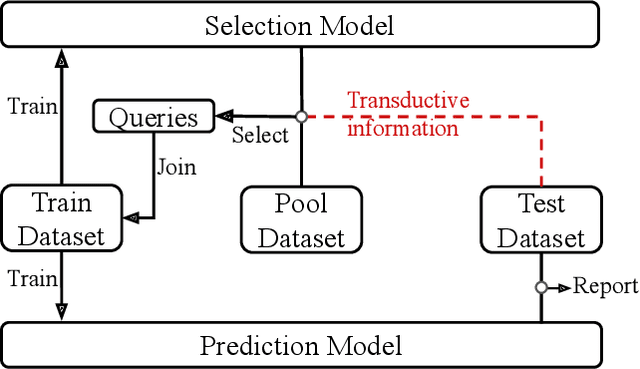
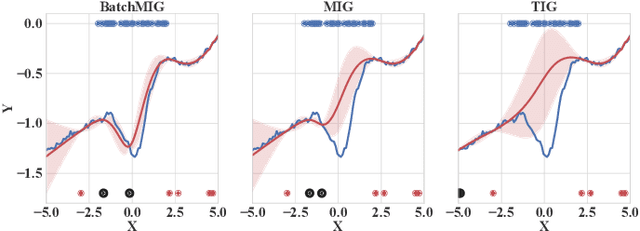
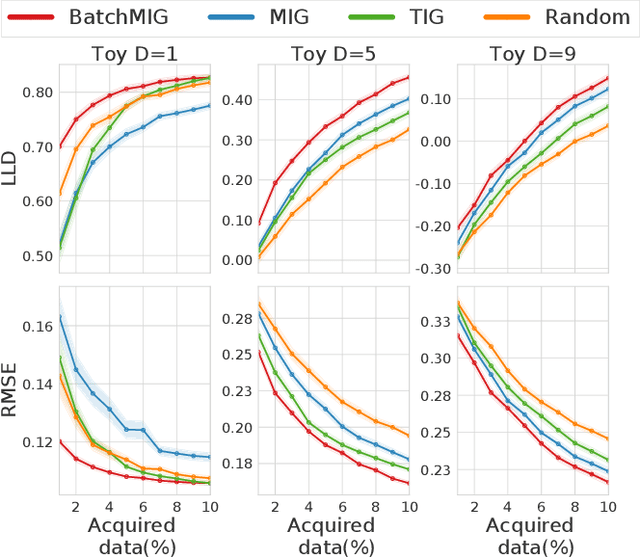
While uncertainty estimation is a well-studied topic in deep learning, most such work focuses on marginal uncertainty estimates, i.e. the predictive mean and variance at individual input locations. But it is often more useful to estimate predictive correlations between the function values at different input locations. In this paper, we consider the problem of benchmarking how accurately Bayesian models can estimate predictive correlations. We first consider a downstream task which depends on posterior predictive correlations: transductive active learning (TAL). We find that TAL makes better use of models' uncertainty estimates than ordinary active learning, and recommend this as a benchmark for evaluating Bayesian models. Since TAL is too expensive and indirect to guide development of algorithms, we introduce two metrics which more directly evaluate the predictive correlations and which can be computed efficiently: meta-correlations (i.e. the correlations between the models correlation estimates and the true values), and cross-normalized likelihoods (XLL). We validate these metrics by demonstrating their consistency with TAL performance and obtain insights about the relative performance of current Bayesian neural net and Gaussian process models.