 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-DCAN: Differentially Private Deep Contrastive Autoencoder Network for Single-cell Clustering
Nov 06, 2023



Single-cell RNA sequencing (scRNA-seq) is important to transcriptomic analysis of gene expression. Recently, deep learning has facilitated the analysis of high-dimensional single-cell data. Unfortunately, deep learning models may leak sensitive information about users. As a result, Differential Privacy (DP) is increasingly used to protect privacy. However, existing DP methods usually perturb whole neural networks to achieve differential privacy, and hence result in great performance overheads. To address this challenge, in this paper, we take advantage of the uniqueness of the autoencoder that it outputs only the dimension-reduced vector in the middle of the network, and design a Differentially Private Deep Contrastive Autoencoder Network (DP-DCAN) by partial network perturbation for single-cell clustering. Since only partial network is added with noise, the performance improvement is obvious and twofold: one part of network is trained with less noise due to a bigger privacy budget, and the other part is trained without any noise. Experimental results of six datasets have verified that DP-DCAN is superior to the traditional DP scheme with whole network perturbation. Moreover, DP-DCAN demonstrates strong robustness to adversarial attacks. The code is available at https://github.com/LFD-byte/DP-DCAN.
Adaptive Local Steps Federated Learning with Differential Privacy Driven by Convergence Analysis
Aug 21, 2023



Federated Learning (FL) is a distributed machine learning technique that allows model training among multiple devices or organizations without sharing data. However, while FL ensures that the raw data is not directly accessible to external adversaries, adversaries can still obtain some statistical information about the data through differential attacks. Differential Privacy (DP) has been proposed, which adds noise to the model or gradients to prevent adversaries from inferring private information from the transmitted parameters. We reconsider the framework of differential privacy federated learning in resource-constrained scenarios (privacy budget and communication resources). We analyze the convergence of federated learning with differential privacy (DPFL) on resource-constrained scenarios and propose an Adaptive Local Steps Differential Privacy Federated Learning (ALS-DPFL) algorithm. We experiment our algorithm on the FashionMNIST and Cifar-10 datasets and achieve quite good performance relative to previous work.
Adap DP-FL: Differentially Private Federated Learning with Adaptive Noise
Nov 29, 2022



Federated learning seeks to address the issue of isolated data islands by making clients disclose only their local training models. However, it was demonstrated that private information could still be inferred by analyzing local model parameters, such as deep neural network model weights. Recently, differential privacy has been applied to federated learning to protect data privacy, but the noise added may degrade the learning performance much. Typically, in previous work, training parameters were clipped equally and noises were added uniformly. The heterogeneity and convergence of training parameters were simply not considered. In this paper, we propose a differentially private scheme for federated learning with adaptive noise (Adap DP-FL). Specifically, due to the gradient heterogeneity, we conduct adaptive gradient clipping for different clients and different rounds; due to the gradient convergence, we add decreasing noises accordingly. Extensive experiments on real-world datasets demonstrate that our Adap DP-FL outperforms previous methods significantly.
SA-DPSGD: Differentially Private Stochastic Gradient Descent based on Simulated Annealing
Nov 14, 2022



Differential privacy (DP) provides a formal privacy guarantee that prevents adversaries with access to machine learning models from extracting information about individual training points. Differentially private stochastic gradient descent (DPSGD) is the most popular training method with differential privacy in image recognition. However, existing DPSGD schemes lead to significant performance degradation, which prevents the application of differential privacy. In this paper, we propose a simulated annealing-based differentially private stochastic gradient descent scheme (SA-DPSGD) which accepts a candidate update with a probability that depends both on the update quality and on the number of iterations. Through this random update screening, we make the differentially private gradient descent proceed in the right direction in each iteration, and result in a more accurate model finally. In our experiments, under the same hyperparameters, our scheme achieves test accuracies 98.35%, 87.41% and 60.92% on datasets MNIST, FashionMNIST and CIFAR10, respectively, compared to the state-of-the-art result of 98.12%, 86.33% and 59.34%. Under the freely adjusted hyperparameters, our scheme achieves even higher accuracies, 98.89%, 88.50% and 64.17%. We believe that our method has a great contribution for closing the accuracy gap between private and non-private image classification.
Point Cloud Compression with Sibling Context and Surface Priors
May 02, 2022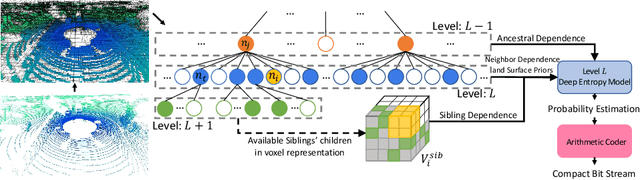
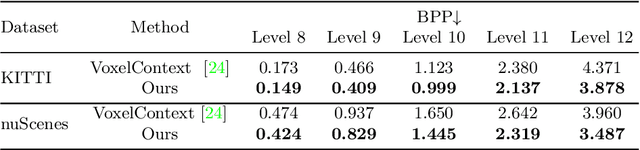
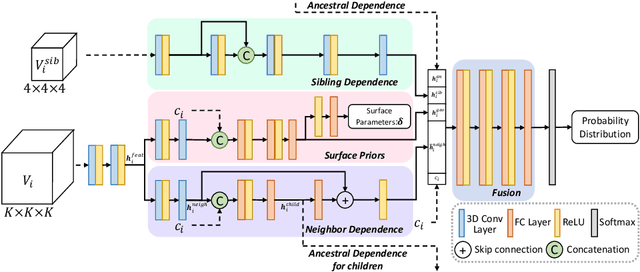
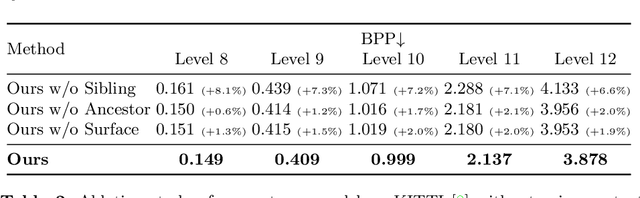
We present a novel octree-based multi-level framework for large-scale point cloud compression, which can organize sparse and unstructured point clouds in a memory-efficient way. In this framework, we propose a new entropy model that explores the hierarchical dependency in an octree using the context of siblings' children, ancestors, and neighbors to encode the occupancy information of each non-leaf octree node into a bitstream. Moreover, we locally fit quadratic surfaces with a voxel-based geometry-aware module to provide geometric priors in entropy encoding. These strong priors empower our entropy framework to encode the octree into a more compact bitstream. In the decoding stage, we apply a two-step heuristic strategy to restore point clouds with better reconstruction quality. The quantitative evaluation shows that our method outperforms state-of-the-art baselines with a bitrate improvement of 11-16% and 12-14% on the KITTI Odometry and nuScenes datasets, respectively.
HoliCity: A City-Scale Data Platform for Learning Holistic 3D Structures
Aug 07, 2020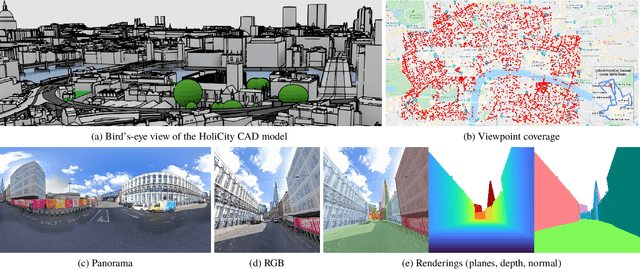


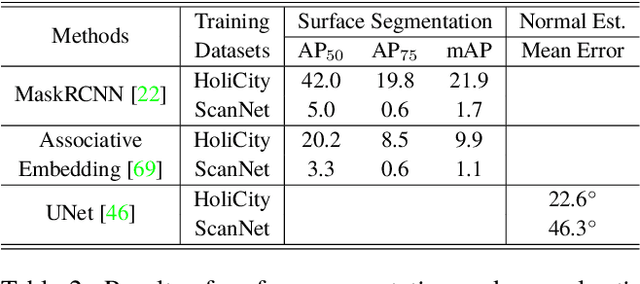
We present HoliCity, a city-scale 3D dataset with rich structural information. Currently, this dataset has 6,300 real-world panoramas of resolution $13312 \times 6656$ that are accurately aligned with the CAD model of downtown London with an area of more than 20 km$^2$, in which the median reprojection error of the alignment of an average image is less than half a degree. This dataset aims to be an all-in-one data platform for research of learning abstracted high-level holistic 3D structures that can be derived from city CAD models, e.g., corners, lines, wireframes, planes, and cuboids, with the ultimate goal of supporting real-world applications including city-scale reconstruction, localization, mapping, and augmented reality. The accurate alignment of the 3D CAD models and panoramas also benefits low-level 3D vision tasks such as surface normal estimation, as the surface normal extracted from previous LiDAR-based datasets is often noisy. We conduct experiments to demonstrate the applications of HoliCity, such as predicting surface segmentation, normal maps, depth maps, and vanishing points, as well as test the generalizability of methods trained on HoliCity and other related datasets. HoliCity is available at https://holicity.io.
Intuitive, Interactive Beard and Hair Synthesis with Generative Models
Apr 15, 2020



We present an interactive approach to synthesizing realistic variations in facial hair in images, ranging from subtle edits to existing hair to the addition of complex and challenging hair in images of clean-shaven subjects. To circumvent the tedious and computationally expensive tasks of modeling, rendering and compositing the 3D geometry of the target hairstyle using the traditional graphics pipeline, we employ a neural network pipeline that synthesizes realistic and detailed images of facial hair directly in the target image in under one second. The synthesis is controlled by simple and sparse guide strokes from the user defining the general structural and color properties of the target hairstyle. We qualitatively and quantitatively evaluate our chosen method compared to several alternative approaches. We show compelling interactive editing results with a prototype user interface that allows novice users to progressively refine the generated image to match their desired hairstyle, and demonstrate that our approach also allows for flexible and high-fidelity scalp hair synthesis.
Anatomy-aware 3D Human Pose Estimation in Videos
Mar 17, 2020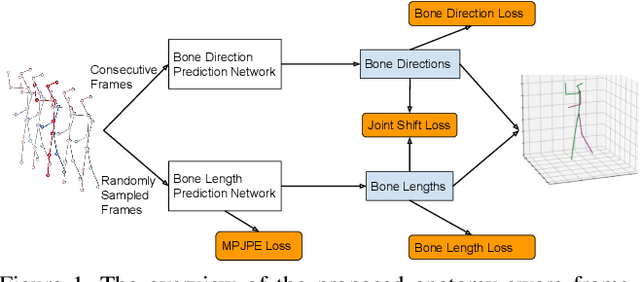
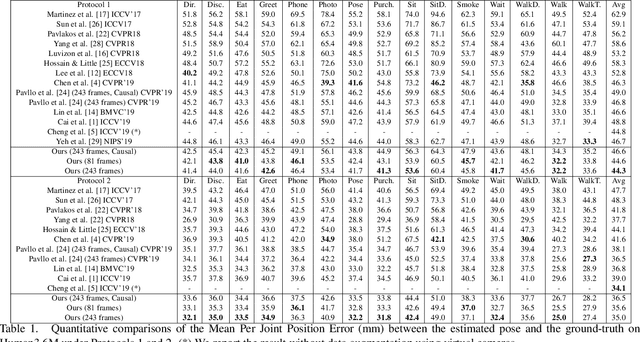
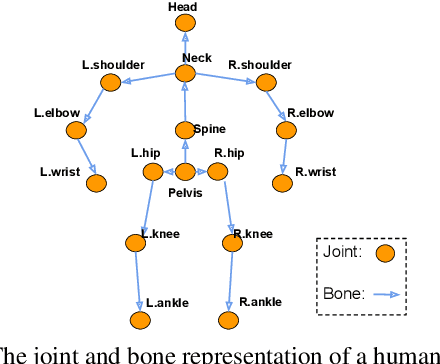
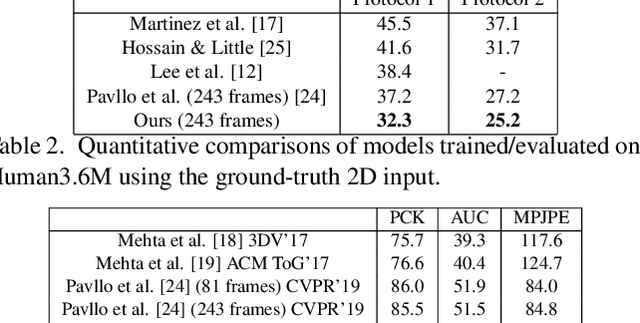
In this work, we propose a new solution for 3D human pose estimation in videos. Instead of directly regressing the 3D joint locations, we draw inspiration from the human skeleton anatomy and decompose the task into bone direction prediction and bone length prediction, from which the 3D joint locations can be completely derived. Our motivation is the fact that the bone lengths of a human skeleton remain consistent across time. This promotes us to develop effective techniques to utilize global information across {\it all} the frames in a video for high-accuracy bone length prediction. Moreover, for the bone direction prediction network, we propose a fully-convolutional propagating architecture with long skip connections. Essentially, it predicts the directions of different bones hierarchically without using any time-consuming memory units (e.g. LSTM). A novel joint shift loss is further introduced to bridge the training of the bone length and bone direction prediction networks. Finally, we employ an implicit attention mechanism to feed the 2D keypoint visibility scores into the model as extra guidance, which significantly mitigates the depth ambiguity in many challenging poses. Our full model outperforms the previous best results on Human3.6M and MPI-INF-3DHP datasets, where comprehensive evaluation validates the effectiveness of our model.
Learning to Reconstruct 3D Manhattan Wireframes from a Single Image
May 17, 2019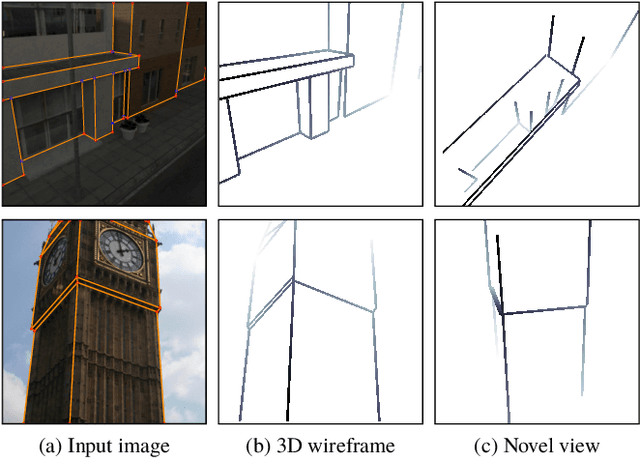
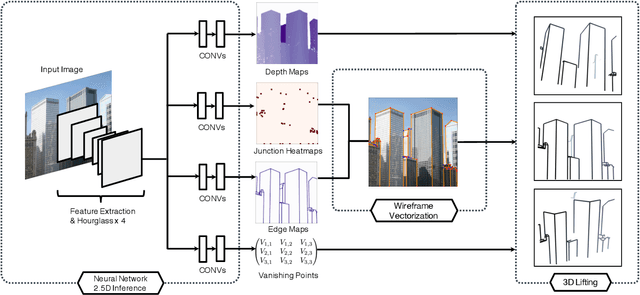
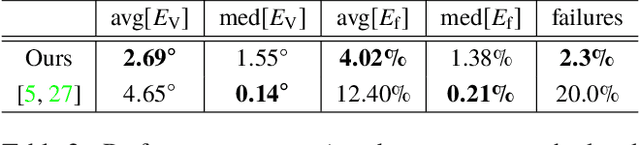
In this paper, we propose a method to obtain a compact and accurate 3D wireframe representation from a single image by effectively exploiting global structural regularities. Our method trains a convolutional neural network to simultaneously detect salient junctions and straight lines, as well as predict their 3D depth and vanishing points. Compared with the state-of-the-art learning-based wireframe detection methods, our network is much simpler and more unified, leading to better 2D wireframe detection. With global structural priors such as Manhattan assumption, our method further reconstructs a full 3D wireframe model, a compact vector representation suitable for a variety of high-level vision tasks such as AR and CAD. We conduct extensive evaluations on a large synthetic dataset of urban scenes as well as real images. Our code and datasets will be released.
Probabilistic Matrix Factorization with Personalized Differential Privacy
Oct 19, 2018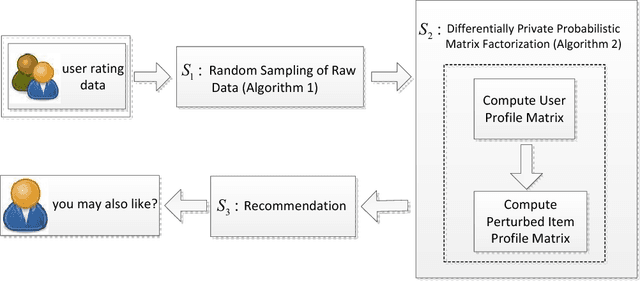
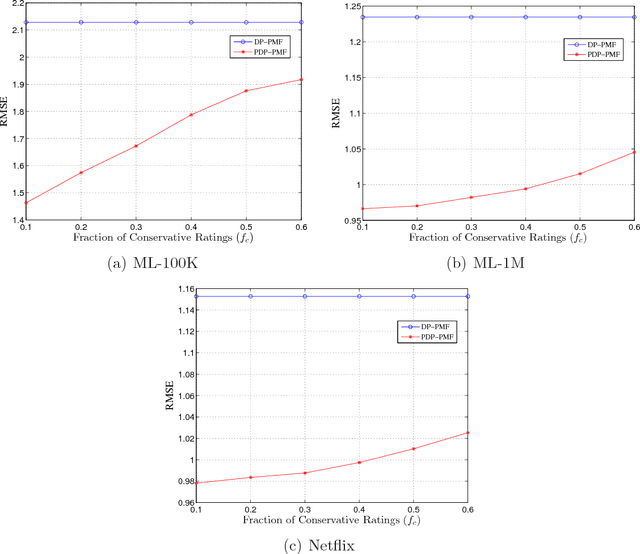

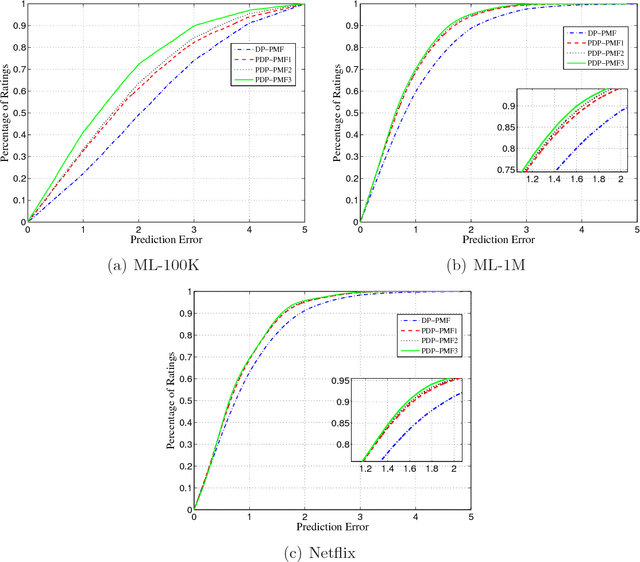
Probabilistic matrix factorization (PMF) plays a crucial role in recommendation systems. It requires a large amount of user data (such as user shopping records and movie ratings) to predict personal preferences, and thereby provides users high-quality recommendation services, which expose the risk of leakage of user privacy. Differential privacy, as a provable privacy protection framework, has been applied widely to recommendation systems. It is common that different individuals have different levels of privacy requirements on items. However, traditional differential privacy can only provide a uniform level of privacy protection for all users. In this paper, we mainly propose a probabilistic matrix factorization recommendation scheme with personalized differential privacy (PDP-PMF). It aims to meet users' privacy requirements specified at the item-level instead of giving the same level of privacy guarantees for all. We then develop a modified sampling mechanism (with bounded differential privacy) for achieving PDP. We also perform a theoretical analysis of the PDP-PMF scheme and demonstrate the privacy of the PDP-PMF scheme. In addition, we implement the probabilistic matrix factorization schemes both with traditional and with personalized differential privacy (DP-PMF, PDP-PMF) and compare them through a series of experiments. The results show that the PDP-PMF scheme performs well on protecting the privacy of each user and its recommendation quality is much better than the DP-PMF scheme.