 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeDeRA:Efficient Fine-tuning of Language Models in Federated Learning Leveraging Weight Decomposition
Apr 30, 2024Pre-trained Language Models (PLMs) have shown excellent performance on various downstream tasks after fine-tuning. Nevertheless, the escalating concerns surrounding user privacy have posed significant challenges to centralized training reliant on extensive data collection. Federated learning, which only requires training on the clients and aggregates weights on the server without sharing data, has emerged as a solution. However, the substantial parameter size of PLMs places a significant burden on the computational resources of client devices, while also leading to costly communication expenses. Introducing Parameter-Efficient Fine-Tuning(PEFT) into federated learning can effectively address this problem. However, we observe that the non-IID data in federated learning leads to a gap in performance between the PEFT method and full parameter fine-tuning(FFT). To overcome this, we propose FeDeRA, an improvement over the Low-Rank Adaption(LoRA) method in federated learning. FeDeRA uses the same adapter module as LoRA. However, the difference lies in FeDeRA's initialization of the adapter module by performing Singular Value Decomposition (SVD) on the pre-trained matrix and selecting its principal components. We conducted extensive experiments, using RoBERTa and DeBERTaV3, on six datasets, comparing the methods including FFT and the other three different PEFT methods. FeDeRA outperforms all other PEFT methods and is comparable to or even surpasses the performance of FFT method. We also deployed federated learning on Jetson AGX Orin and compared the time required by different methods to achieve the target accuracy on specific tasks. Compared to FFT, FeDeRA reduces the training time by 95.9\%, 97.9\%, 96.9\% and 97.3\%, 96.5\%, 96.5\% respectively on three tasks using RoBERTa and DeBERTaV3. The overall experiments indicate that FeDeRA achieves good performance while also maintaining efficiency.
SAM-PD: How Far Can SAM Take Us in Tracking and Segmenting Anything in Videos by Prompt Denoising
Mar 07, 2024Recently, promptable segmentation models, such as the Segment Anything Model (SAM), have demonstrated robust zero-shot generalization capabilities on static images. These promptable models exhibit denoising abilities for imprecise prompt inputs, such as imprecise bounding boxes. In this paper, we explore the potential of applying SAM to track and segment objects in videos where we recognize the tracking task as a prompt denoising task. Specifically, we iteratively propagate the bounding box of each object's mask in the preceding frame as the prompt for the next frame. Furthermore, to enhance SAM's denoising capability against position and size variations, we propose a multi-prompt strategy where we provide multiple jittered and scaled box prompts for each object and preserve the mask prediction with the highest semantic similarity to the template mask. We also introduce a point-based refinement stage to handle occlusions and reduce cumulative errors. Without involving tracking modules, our approach demonstrates comparable performance in video object/instance segmentation tasks on three datasets: DAVIS2017, YouTubeVOS2018, and UVO, serving as a concise baseline and endowing SAM-based downstream applications with tracking capabilities.
AccEPT: An Acceleration Scheme for Speeding Up Edge Pipeline-parallel Training
Nov 10, 2023



It is usually infeasible to fit and train an entire large deep neural network (DNN) model using a single edge device due to the limited resources. To facilitate intelligent applications across edge devices, researchers have proposed partitioning a large model into several sub-models, and deploying each of them to a different edge device to collaboratively train a DNN model. However, the communication overhead caused by the large amount of data transmitted from one device to another during training, as well as the sub-optimal partition point due to the inaccurate latency prediction of computation at each edge device can significantly slow down training. In this paper, we propose AccEPT, an acceleration scheme for accelerating the edge collaborative pipeline-parallel training. In particular, we propose a light-weight adaptive latency predictor to accurately estimate the computation latency of each layer at different devices, which also adapts to unseen devices through continuous learning. Therefore, the proposed latency predictor leads to better model partitioning which balances the computation loads across participating devices. Moreover, we propose a bit-level computation-efficient data compression scheme to compress the data to be transmitted between devices during training. Our numerical results demonstrate that our proposed acceleration approach is able to significantly speed up edge pipeline parallel training up to 3 times faster in the considered experimental settings.
The Model Inversion Eavesdropping Attack in Semantic Communication Systems
Aug 08, 2023In recent years, semantic communication has been a popular research topic for its superiority in communication efficiency. As semantic communication relies on deep learning to extract meaning from raw messages, it is vulnerable to attacks targeting deep learning models. In this paper, we introduce the model inversion eavesdropping attack (MIEA) to reveal the risk of privacy leaks in the semantic communication system. In MIEA, the attacker first eavesdrops the signal being transmitted by the semantic communication system and then performs model inversion attack to reconstruct the raw message, where both the white-box and black-box settings are considered. Evaluation results show that MIEA can successfully reconstruct the raw message with good quality under different channel conditions. We then propose a defense method based on random permutation and substitution to defend against MIEA in order to achieve secure semantic communication. Our experimental results demonstrate the effectiveness of the proposed defense method in preventing MIEA.
WCCNet: Wavelet-integrated CNN with Crossmodal Rearranging Fusion for Fast Multispectral Pedestrian Detection
Aug 02, 2023



Multispectral pedestrian detection achieves better visibility in challenging conditions and thus has a broad application in various tasks, for which both the accuracy and computational cost are of paramount importance. Most existing approaches treat RGB and infrared modalities equally, typically adopting two symmetrical CNN backbones for multimodal feature extraction, which ignores the substantial differences between modalities and brings great difficulty for the reduction of the computational cost as well as effective crossmodal fusion. In this work, we propose a novel and efficient framework named WCCNet that is able to differentially extract rich features of different spectra with lower computational complexity and semantically rearranges these features for effective crossmodal fusion. Specifically, the discrete wavelet transform (DWT) allowing fast inference and training speed is embedded to construct a dual-stream backbone for efficient feature extraction. The DWT layers of WCCNet extract frequency components for infrared modality, while the CNN layers extract spatial-domain features for RGB modality. This methodology not only significantly reduces the computational complexity, but also improves the extraction of infrared features to facilitate the subsequent crossmodal fusion. Based on the well extracted features, we elaborately design the crossmodal rearranging fusion module (CMRF), which can mitigate spatial misalignment and merge semantically complementary features of spatially-related local regions to amplify the crossmodal complementary information. We conduct comprehensive evaluations on KAIST and FLIR benchmarks, in which WCCNet outperforms state-of-the-art methods with considerable computational efficiency and competitive accuracy. We also perform the ablation study and analyze thoroughly the impact of different components on the performance of WCCNet.
Semantic-aware Transmission for Robust Point Cloud Classification
Jun 23, 2023



As three-dimensional (3D) data acquisition devices become increasingly prevalent, the demand for 3D point cloud transmission is growing. In this study, we introduce a semantic-aware communication system for robust point cloud classification that capitalizes on the advantages of pre-trained Point-BERT models. Our proposed method comprises four main components: the semantic encoder, channel encoder, channel decoder, and semantic decoder. By employing a two-stage training strategy, our system facilitates efficient and adaptable learning tailored to the specific classification tasks. The results show that the proposed system achieves classification accuracy of over 89\% when SNR is higher than 10 dB and still maintains accuracy above 66.6\% even at SNR of 4 dB. Compared to the existing method, our approach performs at 0.8\% to 48\% better across different SNR values, demonstrating robustness to channel noise. Our system also achieves a balance between accuracy and speed, being computationally efficient while maintaining high classification performance under noisy channel conditions. This adaptable and resilient approach holds considerable promise for a wide array of 3D scene understanding applications, effectively addressing the challenges posed by channel noise.
Cooperative Task-Oriented Communication for Multi-Modal Data with Transmission Control
Feb 06, 2023Real-time intelligence applications in Internet of Things (IoT) environment depend on timely data communication. However, it is challenging to transmit and analyse massive data of various modalities. Recently proposed task-oriented communication methods based on deep learning have showed its superiority in communication efficiency. In this paper, we propose a cooperative task-oriented communication method for the transmission of multi-modal data from multiple end devices to a central server. In particular, we use the transmission result of data of one modality, which is with lower rate, to control the transmission of other modalities with higher rate in order to reduce the amount of transmitted date. We take the human activity recognition (HAR) task in a smart home environment and design the semantic-oriented transceivers for the transmission of monitoring videos of different rooms and acceleration data of the monitored human. The numerical results demonstrate that by using the transmission control based on the obtained results of the received acceleration data, the transmission is reduced to 2% of that without transmission control while preserving the performance on the HAR task.
Generative Model Based Highly Efficient Semantic Communication Approach for Image Transmission
Nov 18, 2022



Deep learning (DL) based semantic communication methods have been explored to transmit images efficiently in recent years. In this paper, we propose a generative model based semantic communication to further improve the efficiency of image transmission and protect private information. In particular, the transmitter extracts the interpretable latent representation from the original image by a generative model exploiting the GAN inversion method. We also employ a privacy filter and a knowledge base to erase private information and replace it with natural features in the knowledge base. The simulation results indicate that our proposed method achieves comparable quality of received images while significantly reducing communication costs compared to the existing methods.
HDNet: Hierarchical Dynamic Network for Gait Recognition using Millimeter-Wave Radar
Nov 01, 2022



Gait recognition is widely used in diversified practical applications. Currently, the most prevalent approach is to recognize human gait from RGB images, owing to the progress of computer vision technologies. Nevertheless, the perception capability of RGB cameras deteriorates in rough circumstances, and visual surveillance may cause privacy invasion. Due to the robustness and non-invasive feature of millimeter wave (mmWave) radar, radar-based gait recognition has attracted increasing attention in recent years. In this research, we propose a Hierarchical Dynamic Network (HDNet) for gait recognition using mmWave radar. In order to explore more dynamic information, we propose point flow as a novel point clouds descriptor. We also devise a dynamic frame sampling module to promote the efficiency of computation without deteriorating performance noticeably. To prove the superiority of our methods, we perform extensive experiments on two public mmWave radar-based gait recognition datasets, and the results demonstrate that our model is superior to existing state-of-the-art methods.
Ziv-Zakai Bound for DOAs Estimation
Sep 09, 2022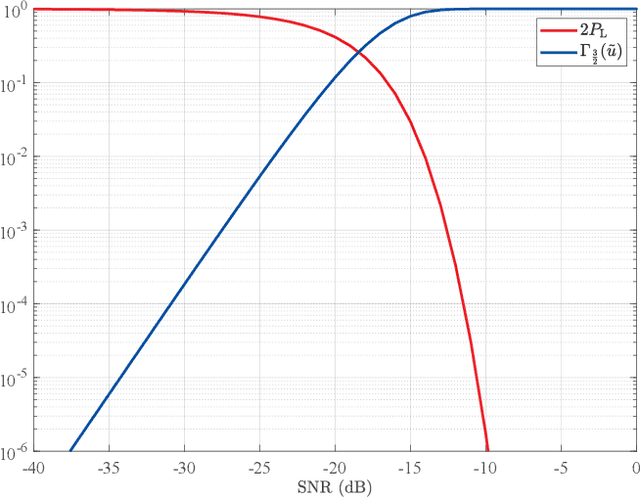
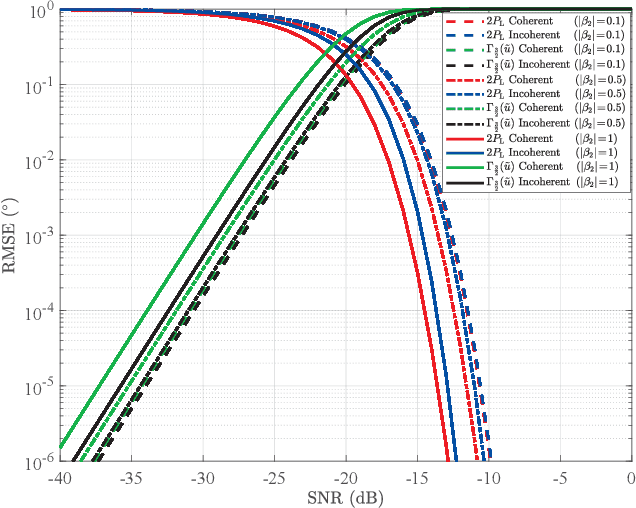
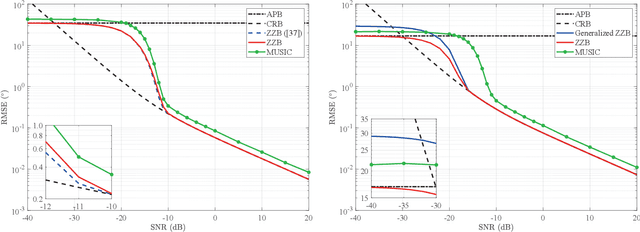
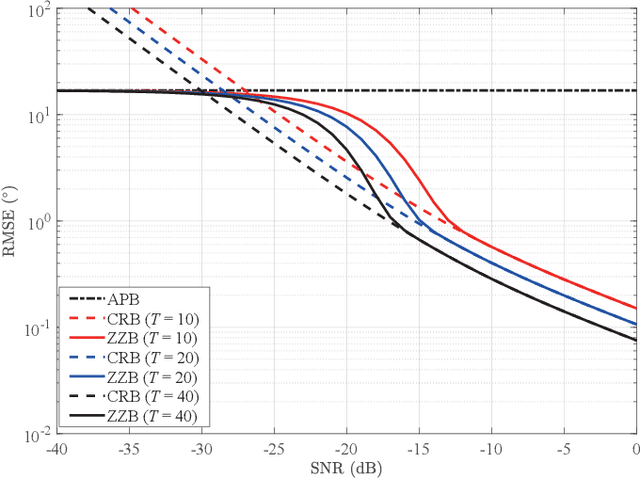
Lower bounds on the mean square error (MSE) play an important role in evaluating the estimation performance of nonlinear parameters including direction-of-arrival (DOA). Among numerous known bounds, the well-accepted Cramer-Rao bound (CRB) lower bounds the MSE in the asymptotic region only, due to its locality. By contrast, the less-adopted Ziv-Zakai bound (ZZB) is restricted by the single source assumption, although it is global tight. In this paper, we first derive an explicit ZZB applicable for hybrid coherent/incoherent multiple sources DOA estimation. In detail, we incorporate Woodbury matrix identity and Sylvester's determinant theorem to generalize the ZZB from single source DOA estimation to multiple sources DOA estimation, which, unfortunately, becomes invalid when it is far away from the asymptotic region. We then introduce the order statistics to describe the effect of ordering process during MSE calculation on the change of a priori distribution of DOAs, such that the derived ZZB can keep a tight bound on the MSE outside the asymptotic region. The derived ZZB is for the first time formulated as the function of the coherent coefficients between the coherent sources, and reveals the relationship between the MSE convergency in the a priori performance region and the number of sources. Moreover, the derived ZZB also provides a unified tight bound for both overdetermined DOAs estimation and underdetermined DOAs estimation. Simulation results demonstrate the obvious advantages of the derived ZZB over the CRB on evaluating and predicting the estimation performance of multiple sources DOA.