 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVol-Mark: A Watermark for 3D Medical Volume Data Via Cubic Difference Expansion and Contrastive Learning
May 06, 2026Today, advances in medical technology extensively utilize 3D volume data for accurate and efficient diagnostics. However, sharing these data across networks in telemedicine poses significant security risks of data tampering and unauthorized copying. To address these challenges, this paper proposes a novel reversible-zero watermarking approach, termed Vol-Mark, for medical volume data to protect their ownership and authenticity in telemedicine. The proposed Vol-Mark method offers two key benefits: 1) it designs a volume data feature extractor that leverages contrastive learning to efficiently extract discriminative and stable volumetric features, ensuring robustness against 3D attacks; 2) it introduces the cubic difference expansion (c-DE) technique, which leverages the 3D integer wavelet transform to embed watermark bits into neighboring voxels within cubes at low-frequency coefficients. The voxel differences within each cube are expanded to create embedding space, and a majority voting mechanism is employed during extraction to enhance reliability. The embedding process incurs low distortion and supports lossless removal, thereby preserving the integrity and diagnostic accuracy of medical volume data. Through these two benefits, Vol-Mark enables both integrity verification and ownership verification. Integrity verification is first performed, and ownership verification through hypothesis testing is further conducted to enhance reliability, particularly under data tampering or watermark removal attacks. Comprehensive experimental results show the effectiveness of the proposed method and its superior robustness against conventional, geometric, and hybrid attacks on medical volume data. In particular, through multiple tasks evaluations, Vol-Mark consistently achieves an ACC above 0.90 in most attack scenarios, outperforming existing methods by a clear margin.
Differentially Private and Communication Efficient Large Language Model Split Inference via Stochastic Quantization and Soft Prompt
Feb 12, 2026Large Language Models (LLMs) have achieved remarkable performance and received significant research interest. The enormous computational demands, however, hinder the local deployment on devices with limited resources. The current prevalent LLM inference paradigms require users to send queries to the service providers for processing, which raises critical privacy concerns. Existing approaches propose to allow the users to obfuscate the token embeddings before transmission and utilize local models for denoising. Nonetheless, transmitting the token embeddings and deploying local models may result in excessive communication and computation overhead, preventing practical implementation. In this work, we propose \textbf{DEL}, a framework for \textbf{D}ifferentially private and communication \textbf{E}fficient \textbf{L}LM split inference. More specifically, an embedding projection module and a differentially private stochastic quantization mechanism are proposed to reduce the communication overhead in a privacy-preserving manner. To eliminate the need for local models, we adapt soft prompt at the server side to compensate for the utility degradation caused by privacy. To the best of our knowledge, this is the first work that utilizes soft prompt to improve the trade-off between privacy and utility in LLM inference, and extensive experiments on text generation and natural language understanding benchmarks demonstrate the effectiveness of the proposed method.
Gradient Compression May Hurt Generalization: A Remedy by Synthetic Data Guided Sharpness Aware Minimization
Feb 12, 2026It is commonly believed that gradient compression in federated learning (FL) enjoys significant improvement in communication efficiency with negligible performance degradation. In this paper, we find that gradient compression induces sharper loss landscapes in federated learning, particularly under non-IID data distributions, which suggests hindered generalization capability. The recently emerging Sharpness Aware Minimization (SAM) effectively searches for a flat minima by incorporating a gradient ascent step (i.e., perturbing the model with gradients) before the celebrated stochastic gradient descent. Nonetheless, the direct application of SAM in FL suffers from inaccurate estimation of the global perturbation due to data heterogeneity. Existing approaches propose to utilize the model update from the previous communication round as a rough estimate. However, its effectiveness is hindered when model update compression is incorporated. In this paper, we propose FedSynSAM, which leverages the global model trajectory to construct synthetic data and facilitates an accurate estimation of the global perturbation. The convergence of the proposed algorithm is established, and extensive experiments are conducted to validate its effectiveness.
BicKD: Bilateral Contrastive Knowledge Distillation
Feb 01, 2026Knowledge distillation (KD) is a machine learning framework that transfers knowledge from a teacher model to a student model. The vanilla KD proposed by Hinton et al. has been the dominant approach in logit-based distillation and demonstrates compelling performance. However, it only performs sample-wise probability alignment between teacher and student's predictions, lacking an mechanism for class-wise comparison. Besides, vanilla KD imposes no structural constraint on the probability space. In this work, we propose a simple yet effective methodology, bilateral contrastive knowledge distillation (BicKD). This approach introduces a novel bilateral contrastive loss, which intensifies the orthogonality among different class generalization spaces while preserving consistency within the same class. The bilateral formulation enables explicit comparison of both sample-wise and class-wise prediction patterns between teacher and student. By emphasizing probabilistic orthogonality, BicKD further regularizes the geometric structure of the predictive distribution. Extensive experiments show that our BicKD method enhances knowledge transfer, and consistently outperforms state-of-the-art knowledge distillation techniques across various model architectures and benchmarks.
Smark: A Watermark for Text-to-Speech Diffusion Models via Discrete Wavelet Transform
Dec 21, 2025



Text-to-Speech (TTS) diffusion models generate high-quality speech, which raises challenges for the model intellectual property protection and speech tracing for legal use. Audio watermarking is a promising solution. However, due to the structural differences among various TTS diffusion models, existing watermarking methods are often designed for a specific model and degrade audio quality, which limits their practical applicability. To address this dilemma, this paper proposes a universal watermarking scheme for TTS diffusion models, termed Smark. This is achieved by designing a lightweight watermark embedding framework that operates in the common reverse diffusion paradigm shared by all TTS diffusion models. To mitigate the impact on audio quality, Smark utilizes the discrete wavelet transform (DWT) to embed watermarks into the relatively stable low-frequency regions of the audio, which ensures seamless watermark-audio integration and is resistant to removal during the reverse diffusion process. Extensive experiments are conducted to evaluate the audio quality and watermark performance in various simulated real-world attack scenarios. The experimental results show that Smark achieves superior performance in both audio quality and watermark extraction accuracy.
PAD-FT: A Lightweight Defense for Backdoor Attacks via Data Purification and Fine-Tuning
Sep 18, 2024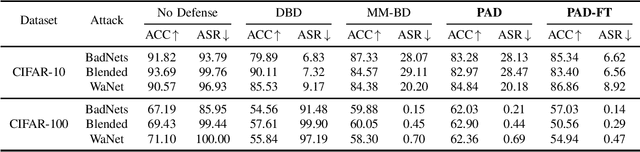
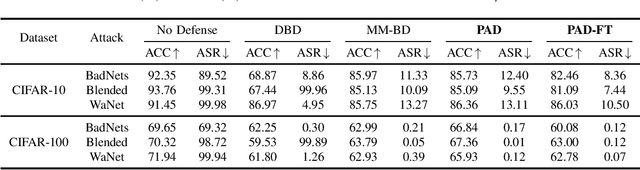

Backdoor attacks pose a significant threat to deep neural networks, particularly as recent advancements have led to increasingly subtle implantation, making the defense more challenging. Existing defense mechanisms typically rely on an additional clean dataset as a standard reference and involve retraining an auxiliary model or fine-tuning the entire victim model. However, these approaches are often computationally expensive and not always feasible in practical applications. In this paper, we propose a novel and lightweight defense mechanism, termed PAD-FT, that does not require an additional clean dataset and fine-tunes only a very small part of the model to disinfect the victim model. To achieve this, our approach first introduces a simple data purification process to identify and select the most-likely clean data from the poisoned training dataset. The self-purified clean dataset is then used for activation clipping and fine-tuning only the last classification layer of the victim model. By integrating data purification, activation clipping, and classifier fine-tuning, our mechanism PAD-FT demonstrates superior effectiveness across multiple backdoor attack methods and datasets, as confirmed through extensive experimental evaluation.
FreeMark: A Non-Invasive White-Box Watermarking for Deep Neural Networks
Sep 16, 2024Deep neural networks (DNNs) have achieved significant success in real-world applications. However, safeguarding their intellectual property (IP) remains extremely challenging. Existing DNN watermarking for IP protection often require modifying DNN models, which reduces model performance and limits their practicality. This paper introduces FreeMark, a novel DNN watermarking framework that leverages cryptographic principles without altering the original host DNN model, thereby avoiding any reduction in model performance. Unlike traditional DNN watermarking methods, FreeMark innovatively generates secret keys from a pre-generated watermark vector and the host model using gradient descent. These secret keys, used to extract watermark from the model's activation values, are securely stored with a trusted third party, enabling reliable watermark extraction from suspect models. Extensive experiments demonstrate that FreeMark effectively resists various watermark removal attacks while maintaining high watermark capacity.
Privacy-Preserving Heterogeneous Federated Learning for Sensitive Healthcare Data
Jun 15, 2024


In the realm of healthcare where decentralized facilities are prevalent, machine learning faces two major challenges concerning the protection of data and models. The data-level challenge concerns the data privacy leakage when centralizing data with sensitive personal information. While the model-level challenge arises from the heterogeneity of local models, which need to be collaboratively trained while ensuring their confidentiality to address intellectual property concerns. To tackle these challenges, we propose a new framework termed Abstention-Aware Federated Voting (AAFV) that can collaboratively and confidentially train heterogeneous local models while simultaneously protecting the data privacy. This is achieved by integrating a novel abstention-aware voting mechanism and a differential privacy mechanism onto local models' predictions. In particular, the proposed abstention-aware voting mechanism exploits a threshold-based abstention method to select high-confidence votes from heterogeneous local models, which not only enhances the learning utility but also protects model confidentiality. Furthermore, we implement AAFV on two practical prediction tasks of diabetes and in-hospital patient mortality. The experiments demonstrate the effectiveness and confidentiality of AAFV in testing accuracy and privacy protection.
DPDR: Gradient Decomposition and Reconstruction for Differentially Private Deep Learning
Jun 04, 2024Differentially Private Stochastic Gradients Descent (DP-SGD) is a prominent paradigm for preserving privacy in deep learning. It ensures privacy by perturbing gradients with random noise calibrated to their entire norm at each training step. However, this perturbation suffers from a sub-optimal performance: it repeatedly wastes privacy budget on the general converging direction shared among gradients from different batches, which we refer as common knowledge, yet yields little information gain. Motivated by this, we propose a differentially private training framework with early gradient decomposition and reconstruction (DPDR), which enables more efficient use of the privacy budget. In essence, it boosts model utility by focusing on incremental information protection and recycling the privatized common knowledge learned from previous gradients at early training steps. Concretely, DPDR incorporates three steps. First, it disentangles common knowledge and incremental information in current gradients by decomposing them based on previous noisy gradients. Second, most privacy budget is spent on protecting incremental information for higher information gain. Third, the model is updated with the gradient reconstructed from recycled common knowledge and noisy incremental information. Theoretical analysis and extensive experiments show that DPDR outperforms state-of-the-art baselines on both convergence rate and accuracy.
The Impact of Prompts on Zero-Shot Detection of AI-Generated Text
Mar 29, 2024In recent years, there have been significant advancements in the development of Large Language Models (LLMs). While their practical applications are now widespread, their potential for misuse, such as generating fake news and committing plagiarism, has posed significant concerns. To address this issue, detectors have been developed to evaluate whether a given text is human-generated or AI-generated. Among others, zero-shot detectors stand out as effective approaches that do not require additional training data and are often likelihood-based. In chat-based applications, users commonly input prompts and utilize the AI-generated texts. However, zero-shot detectors typically analyze these texts in isolation, neglecting the impact of the original prompts. It is conceivable that this approach may lead to a discrepancy in likelihood assessments between the text generation phase and the detection phase. So far, there remains an unverified gap concerning how the presence or absence of prompts impacts detection accuracy for zero-shot detectors. In this paper, we introduce an evaluative framework to empirically analyze the impact of prompts on the detection accuracy of AI-generated text. We assess various zero-shot detectors using both white-box detection, which leverages the prompt, and black-box detection, which operates without prompt information. Our experiments reveal the significant influence of prompts on detection accuracy. Remarkably, compared with black-box detection without prompts, the white-box methods using prompts demonstrate an increase in AUC of at least $0.1$ across all zero-shot detectors tested. Code is available: \url{https://github.com/kaito25atugich/Detector}.