 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLORE++: Logical Location Regression Network for Table Structure Recognition with Pre-training
Jan 03, 2024



Table structure recognition (TSR) aims at extracting tables in images into machine-understandable formats. Recent methods solve this problem by predicting the adjacency relations of detected cell boxes or learning to directly generate the corresponding markup sequences from the table images. However, existing approaches either count on additional heuristic rules to recover the table structures, or face challenges in capturing long-range dependencies within tables, resulting in increased complexity. In this paper, we propose an alternative paradigm. We model TSR as a logical location regression problem and propose a new TSR framework called LORE, standing for LOgical location REgression network, which for the first time regresses logical location as well as spatial location of table cells in a unified network. Our proposed LORE is conceptually simpler, easier to train, and more accurate than other paradigms of TSR. Moreover, inspired by the persuasive success of pre-trained models on a number of computer vision and natural language processing tasks, we propose two pre-training tasks to enrich the spatial and logical representations at the feature level of LORE, resulting in an upgraded version called LORE++. The incorporation of pre-training in LORE++ has proven to enjoy significant advantages, leading to a substantial enhancement in terms of accuracy, generalization, and few-shot capability compared to its predecessor. Experiments on standard benchmarks against methods of previous paradigms demonstrate the superiority of LORE++, which highlights the potential and promising prospect of the logical location regression paradigm for TSR.
Efficient Monaural Speech Enhancement using Spectrum Attention Fusion
Aug 04, 2023Speech enhancement is a demanding task in automated speech processing pipelines, focusing on separating clean speech from noisy channels. Transformer based models have recently bested RNN and CNN models in speech enhancement, however at the same time they are much more computationally expensive and require much more high quality training data, which is always hard to come by. In this paper, we present an improvement for speech enhancement models that maintains the expressiveness of self-attention while significantly reducing model complexity, which we have termed Spectrum Attention Fusion. We carefully construct a convolutional module to replace several self-attention layers in a speech Transformer, allowing the model to more efficiently fuse spectral features. Our proposed model is able to achieve comparable or better results against SOTA models but with significantly smaller parameters (0.58M) on the Voice Bank + DEMAND dataset.
Predicting Human Attention using Computational Attention
Apr 04, 2023



Most models of visual attention are aimed at predicting either top-down or bottom-up control, as studied using different visual search and free-viewing tasks. We propose Human Attention Transformer (HAT), a single model predicting both forms of attention control. HAT is the new state-of-the-art (SOTA) in predicting the scanpath of fixations made during target-present and target-absent search, and matches or exceeds SOTA in the prediction of taskless free-viewing fixation scanpaths. HAT achieves this new SOTA by using a novel transformer-based architecture and a simplified foveated retina that collectively create a spatio-temporal awareness akin to the dynamic visual working memory of humans. Unlike previous methods that rely on a coarse grid of fixation cells and experience information loss due to fixation discretization, HAT features a dense-prediction architecture and outputs a dense heatmap for each fixation, thus avoiding discretizing fixations. HAT sets a new standard in computational attention, which emphasizes both effectiveness and generality. HAT's demonstrated scope and applicability will likely inspire the development of new attention models that can better predict human behavior in various attention-demanding scenarios.
Modeling Entities as Semantic Points for Visual Information Extraction in the Wild
Mar 29, 2023



Recently, Visual Information Extraction (VIE) has been becoming increasingly important in both the academia and industry, due to the wide range of real-world applications. Previously, numerous works have been proposed to tackle this problem. However, the benchmarks used to assess these methods are relatively plain, i.e., scenarios with real-world complexity are not fully represented in these benchmarks. As the first contribution of this work, we curate and release a new dataset for VIE, in which the document images are much more challenging in that they are taken from real applications, and difficulties such as blur, partial occlusion, and printing shift are quite common. All these factors may lead to failures in information extraction. Therefore, as the second contribution, we explore an alternative approach to precisely and robustly extract key information from document images under such tough conditions. Specifically, in contrast to previous methods, which usually either incorporate visual information into a multi-modal architecture or train text spotting and information extraction in an end-to-end fashion, we explicitly model entities as semantic points, i.e., center points of entities are enriched with semantic information describing the attributes and relationships of different entities, which could largely benefit entity labeling and linking. Extensive experiments on standard benchmarks in this field as well as the proposed dataset demonstrate that the proposed method can achieve significantly enhanced performance on entity labeling and linking, compared with previous state-of-the-art models. Dataset is available at https://www.modelscope.cn/datasets/damo/SIBR/summary.
Gazeformer: Scalable, Effective and Fast Prediction of Goal-Directed Human Attention
Mar 27, 2023



Predicting human gaze is important in Human-Computer Interaction (HCI). However, to practically serve HCI applications, gaze prediction models must be scalable, fast, and accurate in their spatial and temporal gaze predictions. Recent scanpath prediction models focus on goal-directed attention (search). Such models are limited in their application due to a common approach relying on trained target detectors for all possible objects, and the availability of human gaze data for their training (both not scalable). In response, we pose a new task called ZeroGaze, a new variant of zero-shot learning where gaze is predicted for never-before-searched objects, and we develop a novel model, Gazeformer, to solve the ZeroGaze problem. In contrast to existing methods using object detector modules, Gazeformer encodes the target using a natural language model, thus leveraging semantic similarities in scanpath prediction. We use a transformer-based encoder-decoder architecture because transformers are particularly useful for generating contextual representations. Gazeformer surpasses other models by a large margin on the ZeroGaze setting. It also outperforms existing target-detection models on standard gaze prediction for both target-present and target-absent search tasks. In addition to its improved performance, Gazeformer is more than five times faster than the state-of-the-art target-present visual search model.
Taking a Respite from Representation Learning for Molecular Property Prediction
Oct 07, 2022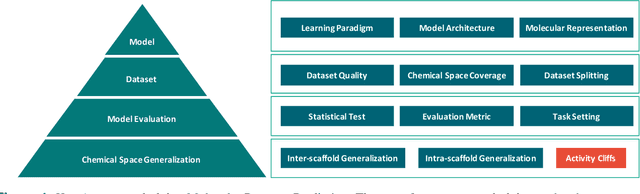
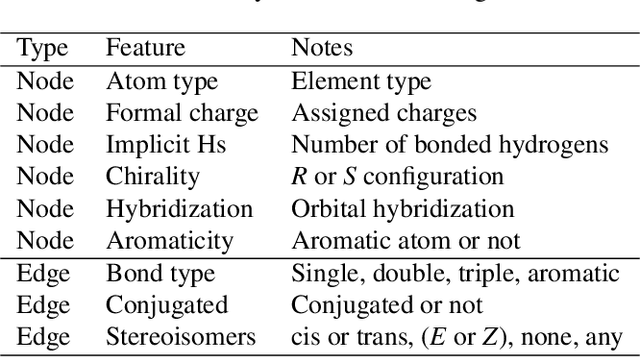
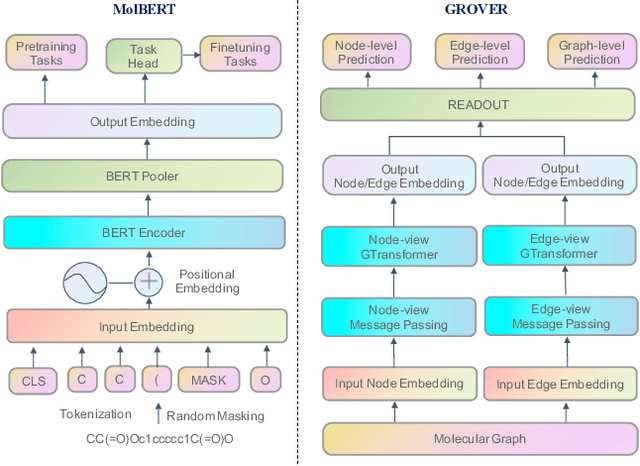
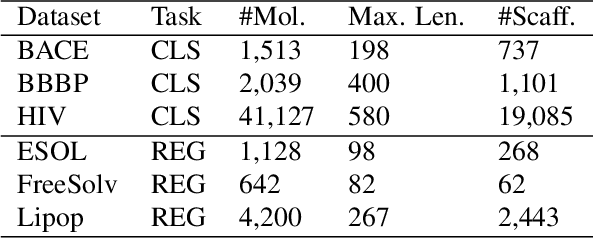
Artificial intelligence (AI) has been widely applied in drug discovery with a major task as molecular property prediction. Despite the boom of AI techniques in molecular representation learning, some key aspects underlying molecular property prediction haven't been carefully examined yet. In this study, we conducted a systematic comparison on three representative models, random forest, MolBERT and GROVER, which utilize three major molecular representations, extended-connectivity fingerprints, SMILES strings and molecular graphs, respectively. Notably, MolBERT and GROVER, are pretrained on large-scale unlabelled molecule corpuses in a self-supervised manner. In addition to the commonly used MoleculeNet benchmark datasets, we also assembled a suite of opioids-related datasets for downstream prediction evaluation. We first conducted dataset profiling on label distribution and structural analyses; we also examined the activity cliffs issue in the opioids-related datasets. Then, we trained 4,320 predictive models and evaluated the usefulness of the learned representations. Furthermore, we explored into the model evaluation by studying the effect of statistical tests, evaluation metrics and task settings. Finally, we dissected the chemical space generalization into inter-scaffold and intra-scaffold generalization and measured prediction performance to evaluate model generalizbility under both settings. By taking this respite, we reflected on the key aspects underlying molecular property prediction, the awareness of which can, hopefully, bring better AI techniques in this field.
Target-absent Human Attention
Jul 04, 2022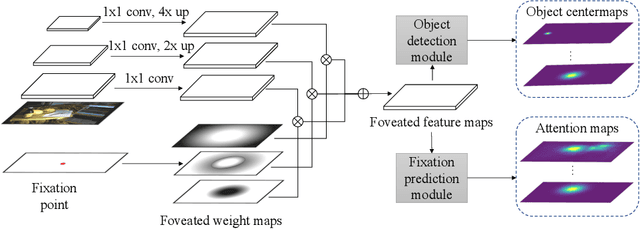
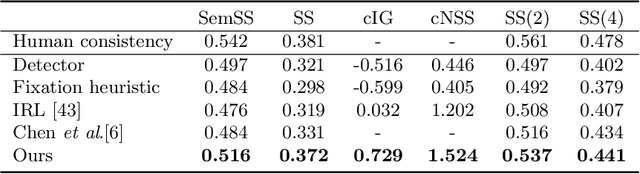


The prediction of human gaze behavior is important for building human-computer interactive systems that can anticipate a user's attention. Computer vision models have been developed to predict the fixations made by people as they search for target objects. But what about when the image has no target? Equally important is to know how people search when they cannot find a target, and when they would stop searching. In this paper, we propose the first data-driven computational model that addresses the search-termination problem and predicts the scanpath of search fixations made by people searching for targets that do not appear in images. We model visual search as an imitation learning problem and represent the internal knowledge that the viewer acquires through fixations using a novel state representation that we call Foveated Feature Maps (FFMs). FFMs integrate a simulated foveated retina into a pretrained ConvNet that produces an in-network feature pyramid, all with minimal computational overhead. Our method integrates FFMs as the state representation in inverse reinforcement learning. Experimentally, we improve the state of the art in predicting human target-absent search behavior on the COCO-Search18 dataset
Vision-Language Pre-Training for Boosting Scene Text Detectors
Apr 29, 2022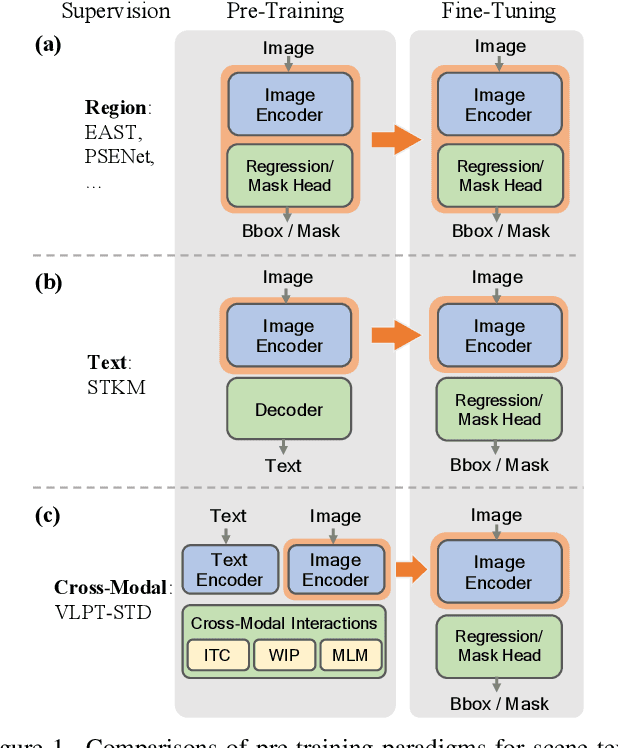
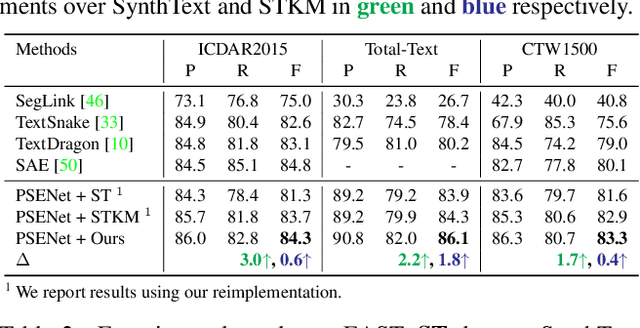
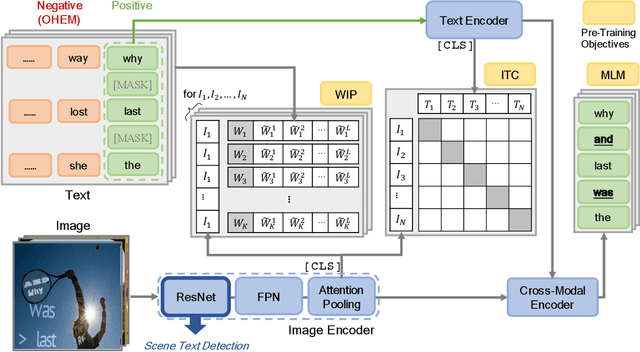
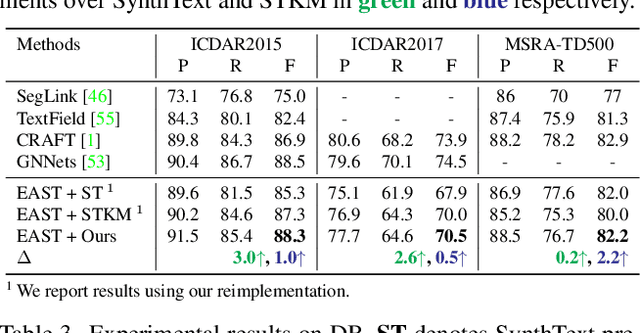
Recently, vision-language joint representation learning has proven to be highly effective in various scenarios. In this paper, we specifically adapt vision-language joint learning for scene text detection, a task that intrinsically involves cross-modal interaction between the two modalities: vision and language, since text is the written form of language. Concretely, we propose to learn contextualized, joint representations through vision-language pre-training, for the sake of enhancing the performance of scene text detectors. Towards this end, we devise a pre-training architecture with an image encoder, a text encoder and a cross-modal encoder, as well as three pretext tasks: image-text contrastive learning (ITC), masked language modeling (MLM) and word-in-image prediction (WIP). The pre-trained model is able to produce more informative representations with richer semantics, which could readily benefit existing scene text detectors (such as EAST and PSENet) in the down-stream text detection task. Extensive experiments on standard benchmarks demonstrate that the proposed paradigm can significantly improve the performance of various representative text detectors, outperforming previous pre-training approaches. The code and pre-trained models will be publicly released.
Revisiting Document Image Dewarping by Grid Regularization
Mar 31, 2022

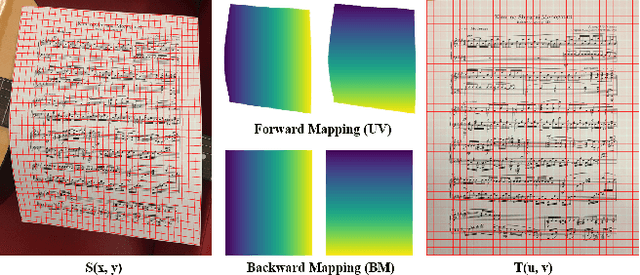
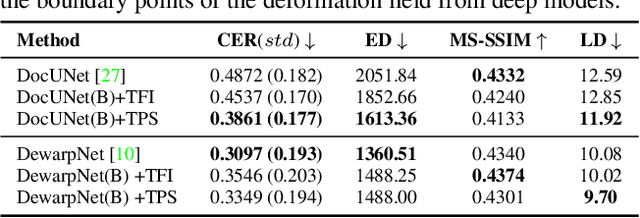
This paper addresses the problem of document image dewarping, which aims at eliminating the geometric distortion in document images for document digitization. Instead of designing a better neural network to approximate the optical flow fields between the inputs and outputs, we pursue the best readability by taking the text lines and the document boundaries into account from a constrained optimization perspective. Specifically, our proposed method first learns the boundary points and the pixels in the text lines and then follows the most simple observation that the boundaries and text lines in both horizontal and vertical directions should be kept after dewarping to introduce a novel grid regularization scheme. To obtain the final forward mapping for dewarping, we solve an optimization problem with our proposed grid regularization. The experiments comprehensively demonstrate that our proposed approach outperforms the prior arts by large margins in terms of readability (with the metrics of Character Errors Rate and the Edit Distance) while maintaining the best image quality on the publicly-available DocUNet benchmark.
ARTS: Eliminating Inconsistency between Text Detection and Recognition with Auto-Rectification Text Spotter
Oct 20, 2021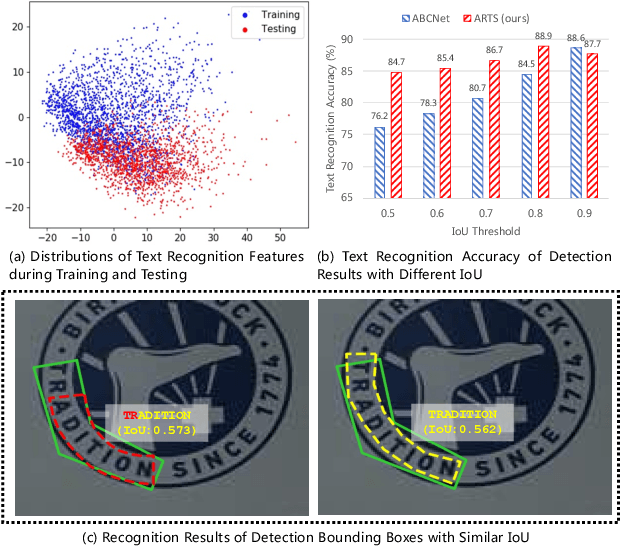
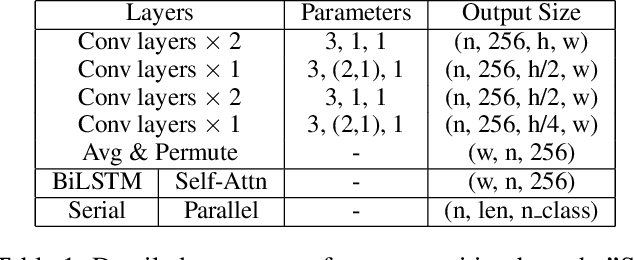
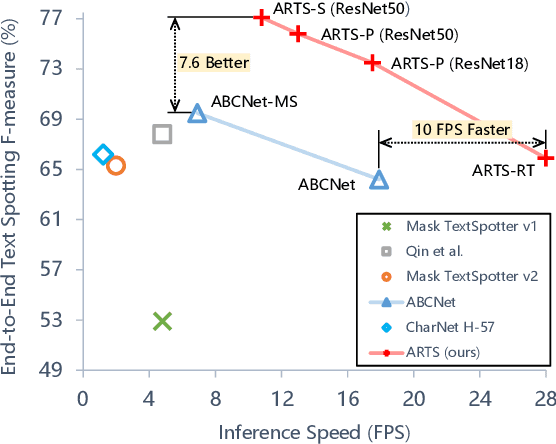
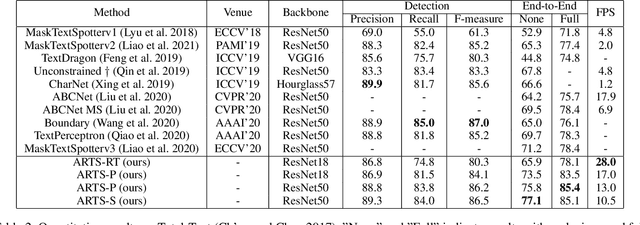
Recent approaches for end-to-end text spotting have achieved promising results. However, most of the current spotters were plagued by the inconsistency problem between text detection and recognition. In this work, we introduce and prove the existence of the inconsistency problem and analyze it from two aspects: (1) inconsistency of text recognition features between training and testing, and (2) inconsistency of optimization targets between text detection and recognition. To solve the aforementioned issues, we propose a differentiable Auto-Rectification Module (ARM) together with a new training strategy to enable propagating recognition loss back into detection branch, so that our detection branch can be jointly optimized by detection and recognition targets, which largely alleviates the inconsistency problem between text detection and recognition. Based on these designs, we present a simple yet robust end-to-end text spotting framework, termed Auto-Rectification Text Spotter (ARTS), to detect and recognize arbitrarily-shaped text in natural scenes. Extensive experiments demonstrate the superiority of our method. In particular, our ARTS-S achieves 77.1% end-to-end text spotting F-measure on Total-Text at a competitive speed of 10.5 FPS, which significantly outperforms previous methods in both accuracy and inference speed.