 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower-law Dynamic arising from machine learning
Jun 16, 2023We study a kind of new SDE that was arisen from the research on optimization in machine learning, we call it power-law dynamic because its stationary distribution cannot have sub-Gaussian tail and obeys power-law. We prove that the power-law dynamic is ergodic with unique stationary distribution, provided the learning rate is small enough. We investigate its first exist time. In particular, we compare the exit times of the (continuous) power-law dynamic and its discretization. The comparison can help guide machine learning algorithm.
Convergence of AdaGrad for Non-convex Objectives: Simple Proofs and Relaxed Assumptions
May 29, 2023We provide a simple convergence proof for AdaGrad optimizing non-convex objectives under only affine noise variance and bounded smoothness assumptions. The proof is essentially based on a novel auxiliary function $\xi$ that helps eliminate the complexity of handling the correlation between the numerator and denominator of AdaGrad's update. Leveraging simple proofs, we are able to obtain tighter results than existing results \citep{faw2022power} and extend the analysis to several new and important cases. Specifically, for the over-parameterized regime, we show that AdaGrad needs only $\mathcal{O}(\frac{1}{\varepsilon^2})$ iterations to ensure the gradient norm smaller than $\varepsilon$, which matches the rate of SGD and significantly tighter than existing rates $\mathcal{O}(\frac{1}{\varepsilon^4})$ for AdaGrad. We then discard the bounded smoothness assumption and consider a realistic assumption on smoothness called $(L_0,L_1)$-smooth condition, which allows local smoothness to grow with the gradient norm. Again based on the auxiliary function $\xi$, we prove that AdaGrad succeeds in converging under $(L_0,L_1)$-smooth condition as long as the learning rate is lower than a threshold. Interestingly, we further show that the requirement on learning rate under the $(L_0,L_1)$-smooth condition is necessary via proof by contradiction, in contrast with the case of uniform smoothness conditions where convergence is guaranteed regardless of learning rate choices. Together, our analyses broaden the understanding of AdaGrad and demonstrate the power of the new auxiliary function in the investigations of AdaGrad.
A new perspective on building efficient and expressive 3D equivariant graph neural networks
Apr 07, 2023Geometric deep learning enables the encoding of physical symmetries in modeling 3D objects. Despite rapid progress in encoding 3D symmetries into Graph Neural Networks (GNNs), a comprehensive evaluation of the expressiveness of these networks through a local-to-global analysis lacks today. In this paper, we propose a local hierarchy of 3D isomorphism to evaluate the expressive power of equivariant GNNs and investigate the process of representing global geometric information from local patches. Our work leads to two crucial modules for designing expressive and efficient geometric GNNs; namely local substructure encoding (LSE) and frame transition encoding (FTE). To demonstrate the applicability of our theory, we propose LEFTNet which effectively implements these modules and achieves state-of-the-art performance on both scalar-valued and vector-valued molecular property prediction tasks. We further point out the design space for future developments of equivariant graph neural networks. Our codes are available at \url{https://github.com/yuanqidu/LeftNet}.
Monte Carlo Neural Operator for Learning PDEs via Probabilistic Representation
Feb 10, 2023



Neural operators, which use deep neural networks to approximate the solution mappings of partial differential equation (PDE) systems, are emerging as a new paradigm for PDE simulation. The neural operators could be trained in supervised or unsupervised ways, i.e., by using the generated data or the PDE information. The unsupervised training approach is essential when data generation is costly or the data is less qualified (e.g., insufficient and noisy). However, its performance and efficiency have plenty of room for improvement. To this end, we design a new loss function based on the Feynman-Kac formula and call the developed neural operator Monte-Carlo Neural Operator (MCNO), which can allow larger temporal steps and efficiently handle fractional diffusion operators. Our analyses show that MCNO has advantages in handling complex spatial conditions and larger temporal steps compared with other unsupervised methods. Furthermore, MCNO is more robust with the perturbation raised by the numerical scheme and operator approximation. Numerical experiments on the diffusion equation and Navier-Stokes equation show significant accuracy improvement compared with other unsupervised baselines, especially for the vibrated initial condition and long-time simulation settings.
Provable Adaptivity in Adam
Aug 21, 2022


Adaptive Moment Estimation (Adam) optimizer is widely used in deep learning tasks because of its fast convergence properties. However, the convergence of Adam is still not well understood. In particular, the existing analysis of Adam cannot clearly demonstrate the advantage of Adam over SGD. We attribute this theoretical embarrassment to $L$-smooth condition (i.e., assuming the gradient is globally Lipschitz continuous with constant $L$) adopted by literature, which has been pointed out to often fail in practical neural networks. To tackle this embarrassment, we analyze the convergence of Adam under a relaxed condition called $(L_0,L_1)$ smoothness condition, which allows the gradient Lipschitz constant to change with the local gradient norm. $(L_0,L_1)$ is strictly weaker than $L$-smooth condition and it has been empirically verified to hold for practical deep neural networks. Under the $(L_0,L_1)$ smoothness condition, we establish the convergence for Adam with practical hyperparameters. Specifically, we argue that Adam can adapt to the local smoothness condition, justifying the \emph{adaptivity} of Adam. In contrast, SGD can be arbitrarily slow under this condition. Our result might shed light on the benefit of adaptive gradient methods over non-adaptive ones.
Improved OOD Generalization via Conditional Invariant Regularizer
Jul 14, 2022
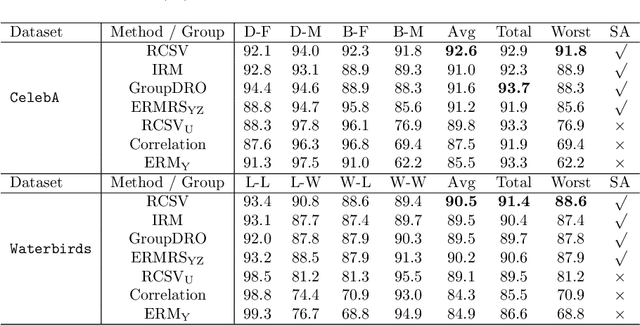
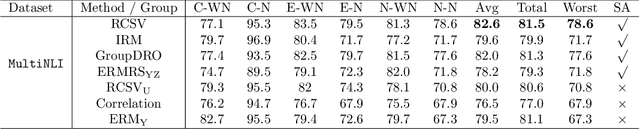

Recently, generalization on out-of-distribution (OOD) data with correlation shift has attracted great attention. The correlation shift is caused by the spurious attributes that correlate to the class label, as the correlation between them may vary in training and test data. For such a problem, we show that given the class label, the conditionally independent models of spurious attributes are OOD generalizable. Based on this, a metric Conditional Spurious Variation (CSV) which controls OOD generalization error, is proposed to measure such conditional independence. To improve the OOD generalization, we regularize the training process with the proposed CSV. Under mild assumptions, our training objective can be formulated as a nonconvex-concave mini-max problem. An algorithm with provable convergence rate is proposed to solve the problem. Extensive empirical results verify our algorithm's efficacy in improving OOD generalization.
Deep Random Vortex Method for Simulation and Inference of Navier-Stokes Equations
Jun 20, 2022
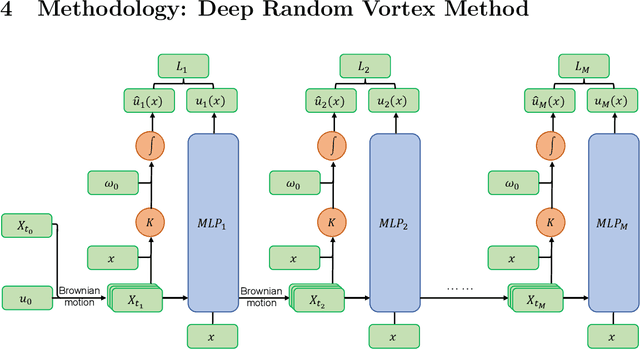
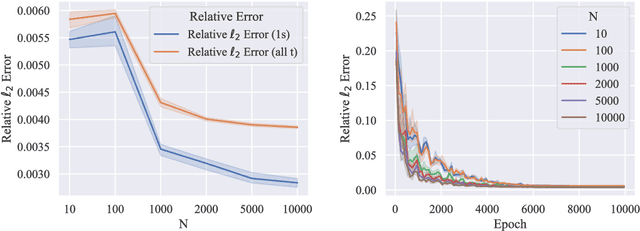
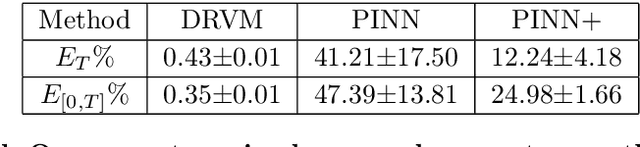
Navier-Stokes equations are significant partial differential equations that describe the motion of fluids such as liquids and air. Due to the importance of Navier-Stokes equations, the development on efficient numerical schemes is important for both science and engineer. Recently, with the development of AI techniques, several approaches have been designed to integrate deep neural networks in simulating and inferring the fluid dynamics governed by incompressible Navier-Stokes equations, which can accelerate the simulation or inferring process in a mesh-free and differentiable way. In this paper, we point out that the capability of existing deep Navier-Stokes informed methods is limited to handle non-smooth or fractional equations, which are two critical situations in reality. To this end, we propose the \emph{Deep Random Vortex Method} (DRVM), which combines the neural network with a random vortex dynamics system equivalent to the Navier-Stokes equation. Specifically, the random vortex dynamics motivates a Monte Carlo based loss function for training the neural network, which avoids the calculation of derivatives through auto-differentiation. Therefore, DRVM not only can efficiently solve Navier-Stokes equations involving rough path, non-differentiable initial conditions and fractional operators, but also inherits the mesh-free and differentiable benefits of the deep-learning-based solver. We conduct experiments on the Cauchy problem, parametric solver learning, and the inverse problem of both 2-d and 3-d incompressible Navier-Stokes equations. The proposed method achieves accurate results for simulation and inference of Navier-Stokes equations. Especially for the cases that include singular initial conditions, DRVM significantly outperforms existing PINN method.
Neural Operator with Regularity Structure for Modeling Dynamics Driven by SPDEs
Apr 14, 2022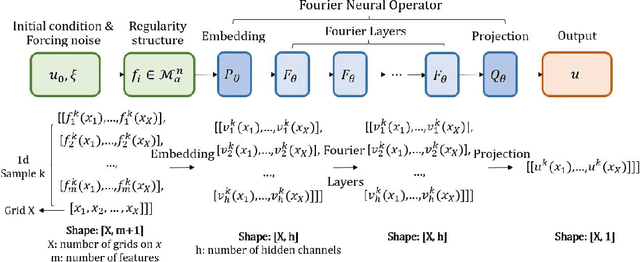

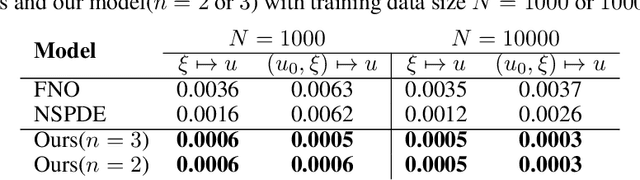
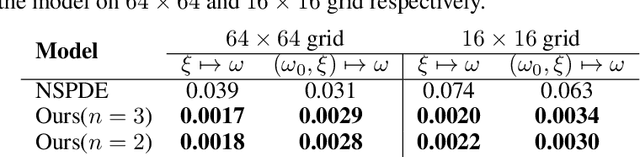
Stochastic partial differential equations (SPDEs) are significant tools for modeling dynamics in many areas including atmospheric sciences and physics. Neural Operators, generations of neural networks with capability of learning maps between infinite-dimensional spaces, are strong tools for solving parametric PDEs. However, they lack the ability to modeling SPDEs which usually have poor regularity due to the driving noise. As the theory of regularity structure has achieved great successes in analyzing SPDEs and provides the concept model feature vectors that well-approximate SPDEs' solutions, we propose the Neural Operator with Regularity Structure (NORS) which incorporates the feature vectors for modeling dynamics driven by SPDEs. We conduct experiments on various of SPDEs including the dynamic Phi41 model and the 2d stochastic Navier-Stokes equation, and the results demonstrate that the NORS is resolution-invariant, efficient, and achieves one order of magnitude lower error with a modest amount of data.
Momentum Doesn't Change the Implicit Bias
Oct 08, 2021
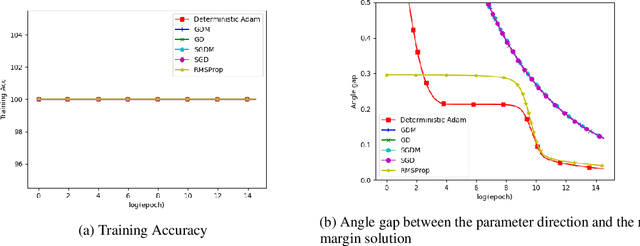
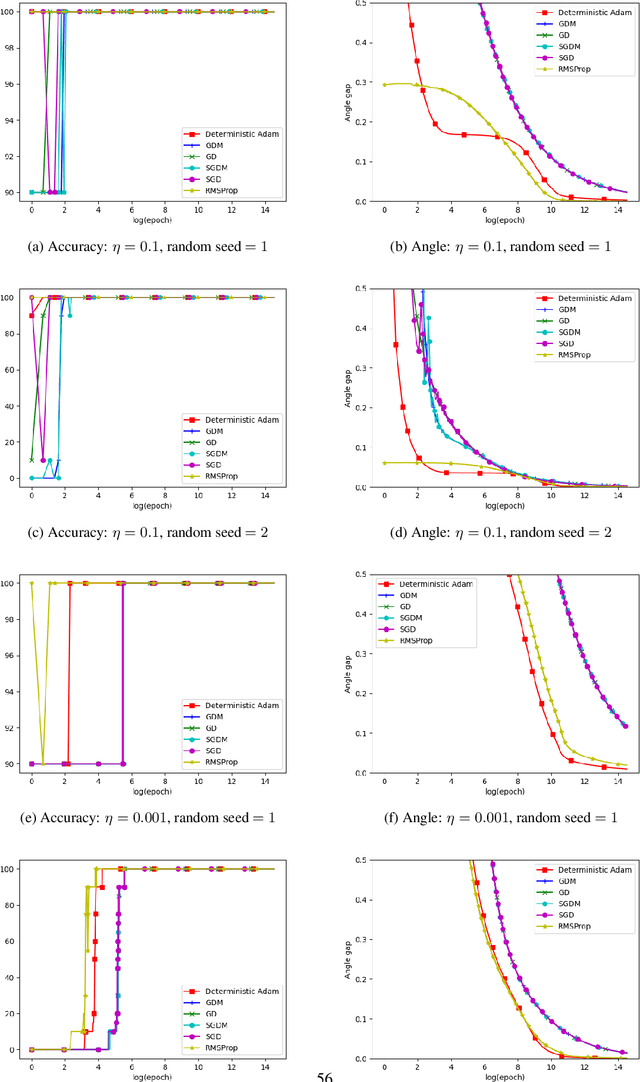
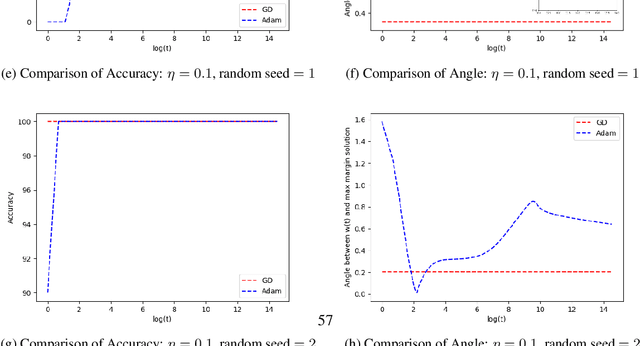
The momentum acceleration technique is widely adopted in many optimization algorithms. However, the theoretical understanding of how the momentum affects the generalization performance of the optimization algorithms is still unknown. In this paper, we answer this question through analyzing the implicit bias of momentum-based optimization. We prove that both SGD with momentum and Adam converge to the $L_2$ max-margin solution for exponential-tailed loss, which is the same as vanilla gradient descent. That means, these optimizers with momentum acceleration still converge to a model with low complexity, which provides guarantees on their generalization. Technically, to overcome the difficulty brought by the error accumulation in analyzing the momentum, we construct new Lyapunov functions as a tool to analyze the gap between the model parameter and the max-margin solution.
Incorporating NODE with Pre-trained Neural Differential Operator for Learning Dynamics
Jun 09, 2021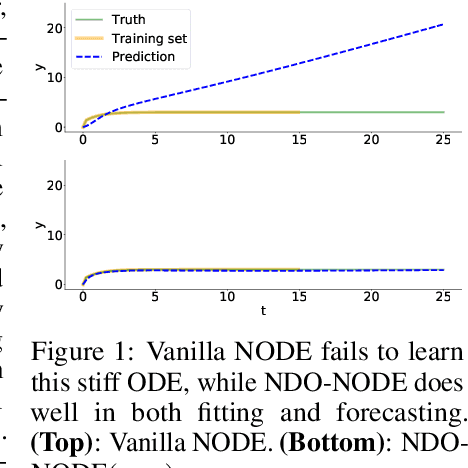
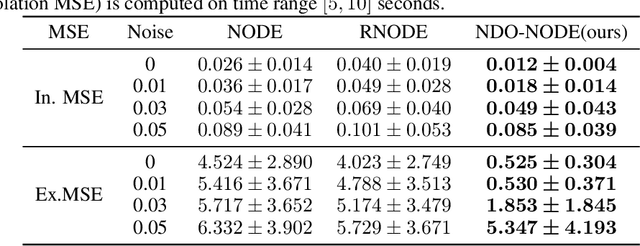
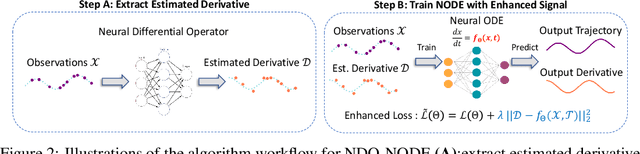
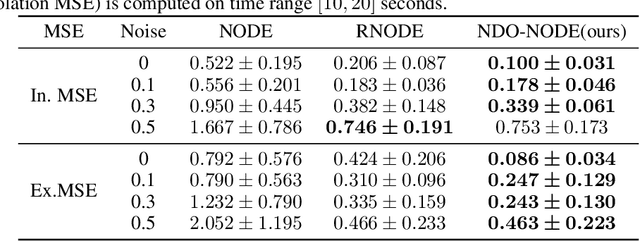
Learning dynamics governed by differential equations is crucial for predicting and controlling the systems in science and engineering. Neural Ordinary Differential Equation (NODE), a deep learning model integrated with differential equations, learns the dynamics directly from the samples on the trajectory and shows great promise in the scientific field. However, the training of NODE highly depends on the numerical solver, which can amplify numerical noise and be unstable, especially for ill-conditioned dynamical systems. In this paper, to reduce the reliance on the numerical solver, we propose to enhance the supervised signal in learning dynamics. Specifically, beyond learning directly from the trajectory samples, we pre-train a neural differential operator (NDO) to output an estimation of the derivatives to serve as an additional supervised signal. The NDO is pre-trained on a class of symbolic functions, and it learns the mapping between the trajectory samples of these functions to their derivatives. We provide theoretical guarantee on that the output of NDO can well approximate the ground truth derivatives by proper tuning the complexity of the library. To leverage both the trajectory signal and the estimated derivatives from NDO, we propose an algorithm called NDO-NODE, in which the loss function contains two terms: the fitness on the true trajectory samples and the fitness on the estimated derivatives that are output by the pre-trained NDO. Experiments on various of dynamics show that our proposed NDO-NODE can consistently improve the forecasting accuracy.