 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time X-ray Phase-contrast Imaging Using SPINNet -- A Speckle-based Phase-contrast Imaging Neural Network
Jan 18, 2022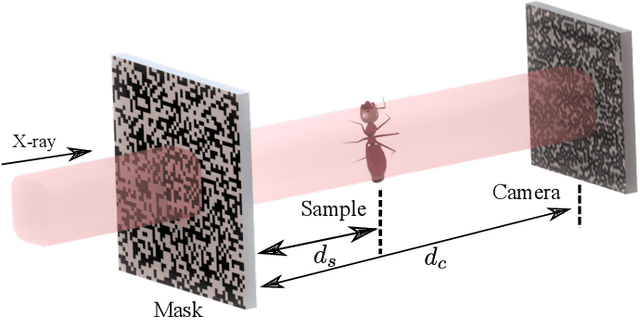
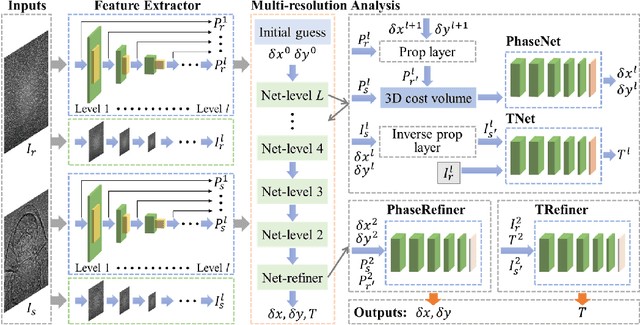
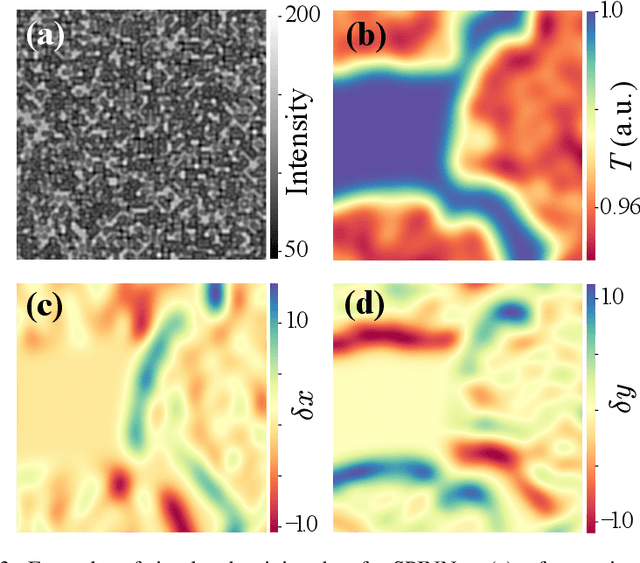
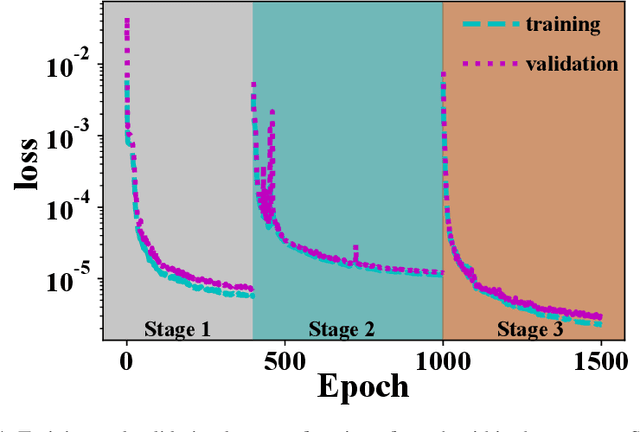
X-ray phase-contrast imaging has become indispensable for visualizing samples with low absorption contrast. In this regard, speckle-based techniques have shown significant advantages in spatial resolution, phase sensitivity, and implementation flexibility compared with traditional methods. However, their computational cost has hindered their wider adoption. By exploiting the power of deep learning, we developed a new speckle-based phase-contrast imaging neural network (SPINNet) that boosts the phase retrieval speed by at least two orders of magnitude compared to existing methods. To achieve this performance, we combined SPINNet with a novel coded-mask-based technique, an enhanced version of the speckle-based method. Using this scheme, we demonstrate a simultaneous reconstruction of absorption and phase images on the order of 100 ms, where a traditional correlation-based analysis would take several minutes even with a cluster. In addition to significant improvement in speed, our experimental results show that the imaging resolution and phase retrieval quality of SPINNet outperform existing single-shot speckle-based methods. Furthermore, we successfully demonstrate its application in 3D X-ray phase-contrast tomography. Our result shows that SPINNet could enable many applications requiring high-resolution and fast data acquisition and processing, such as in-situ and in-operando 2D and 3D phase-contrast imaging and real-time at-wavelength metrology and wavefront sensing.
PIMNet: A Parallel, Iterative and Mimicking Network for Scene Text Recognition
Sep 09, 2021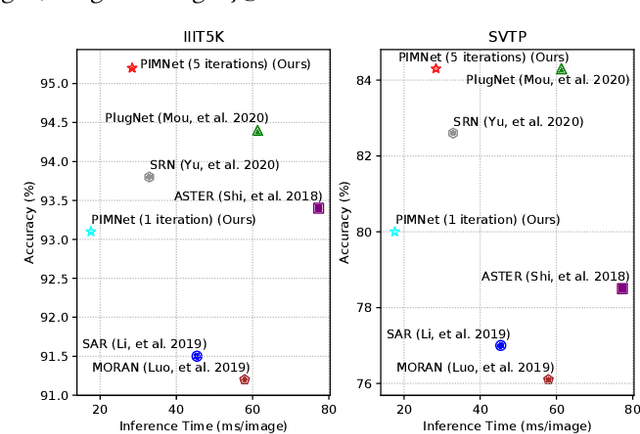
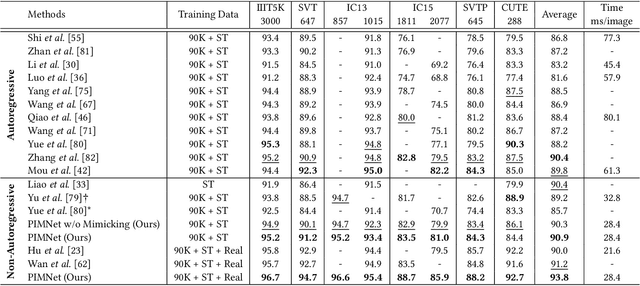
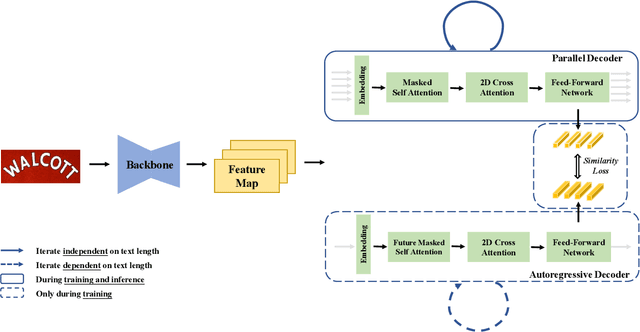

Nowadays, scene text recognition has attracted more and more attention due to its various applications. Most state-of-the-art methods adopt an encoder-decoder framework with attention mechanism, which generates text autoregressively from left to right. Despite the convincing performance, the speed is limited because of the one-by-one decoding strategy. As opposed to autoregressive models, non-autoregressive models predict the results in parallel with a much shorter inference time, but the accuracy falls behind the autoregressive counterpart considerably. In this paper, we propose a Parallel, Iterative and Mimicking Network (PIMNet) to balance accuracy and efficiency. Specifically, PIMNet adopts a parallel attention mechanism to predict the text faster and an iterative generation mechanism to make the predictions more accurate. In each iteration, the context information is fully explored. To improve learning of the hidden layer, we exploit the mimicking learning in the training phase, where an additional autoregressive decoder is adopted and the parallel decoder mimics the autoregressive decoder with fitting outputs of the hidden layer. With the shared backbone between the two decoders, the proposed PIMNet can be trained end-to-end without pre-training. During inference, the branch of the autoregressive decoder is removed for a faster speed. Extensive experiments on public benchmarks demonstrate the effectiveness and efficiency of PIMNet. Our code will be available at https://github.com/Pay20Y/PIMNet.
PyHealth: A Python Library for Health Predictive Models
Jan 11, 2021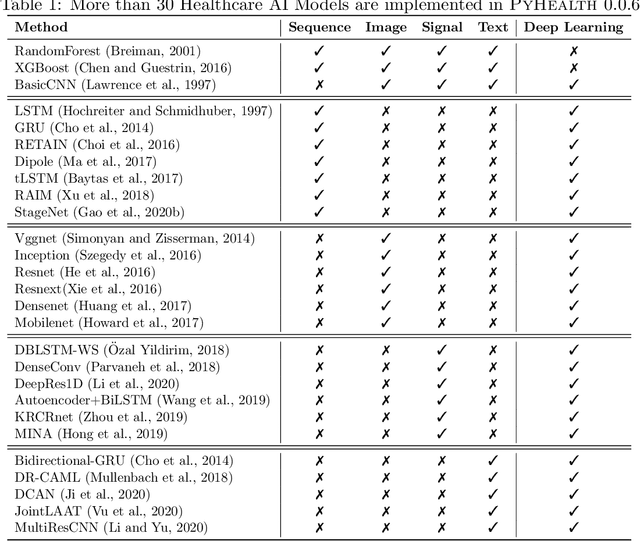
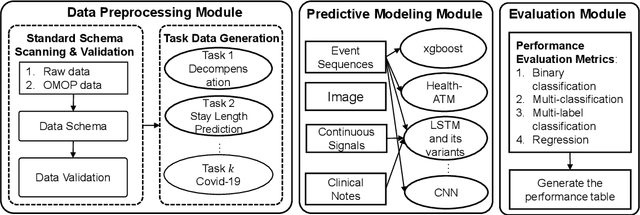
Despite the explosion of interest in healthcare AI research, the reproducibility and benchmarking of those research works are often limited due to the lack of standard benchmark datasets and diverse evaluation metrics. To address this reproducibility challenge, we develop PyHealth, an open-source Python toolbox for developing various predictive models on healthcare data. PyHealth consists of data preprocessing module, predictive modeling module, and evaluation module. The target users of PyHealth are both computer science researchers and healthcare data scientists. With PyHealth, they can conduct complex machine learning pipelines on healthcare datasets with fewer than ten lines of code. The data preprocessing module enables the transformation of complex healthcare datasets such as longitudinal electronic health records, medical images, continuous signals (e.g., electrocardiogram), and clinical notes into machine learning friendly formats. The predictive modeling module provides more than 30 machine learning models, including established ensemble trees and deep neural network-based approaches, via a unified but extendable API designed for both researchers and practitioners. The evaluation module provides various evaluation strategies (e.g., cross-validation and train-validation-test split) and predictive model metrics. With robustness and scalability in mind, best practices such as unit testing, continuous integration, code coverage, and interactive examples are introduced in the library's development. PyHealth can be installed through the Python Package Index (PyPI) or https://github.com/yzhao062/PyHealth .
FLANNEL: Focal Loss Based Neural Network Ensemble for COVID-19 Detection
Oct 30, 2020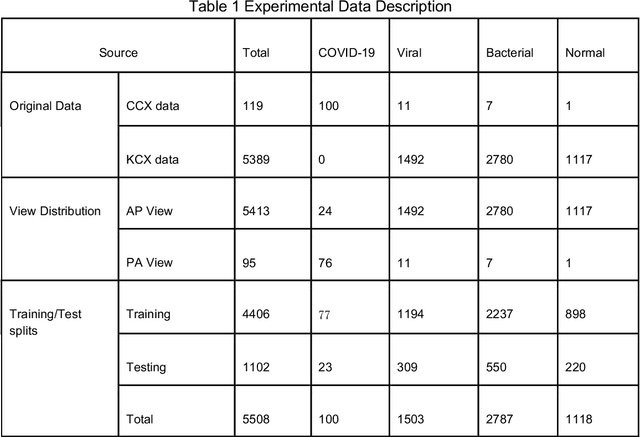
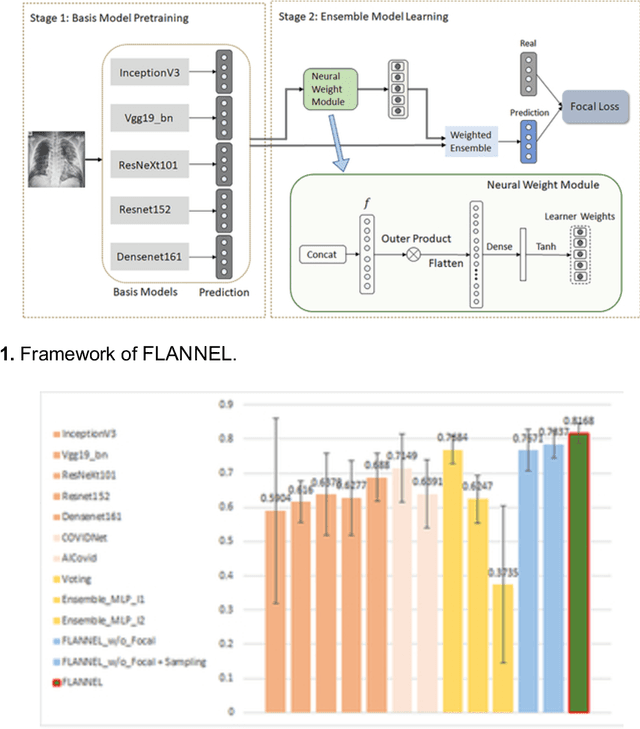
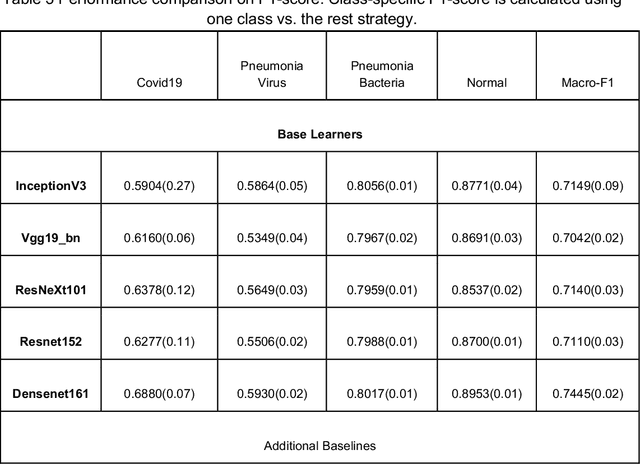
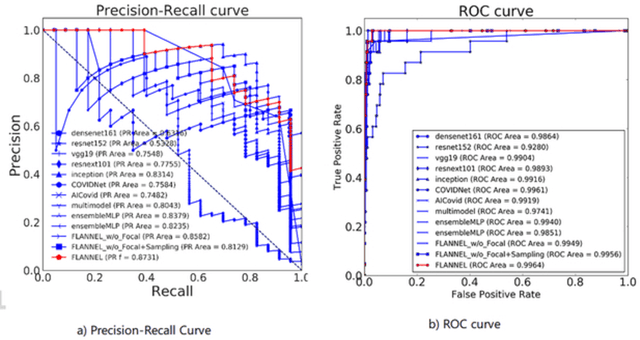
To test the possibility of differentiating chest x-ray images of COVID-19 against other pneumonia and healthy patients using deep neural networks. We construct the X-ray imaging data from two publicly available sources, which include 5508 chest x-ray images across 2874 patients with four classes: normal, bacterial pneumonia, non-COVID-19 viral pneumonia, and COVID-19. To identify COVID-19, we propose a Focal Loss Based Neural Ensemble Network (FLANNEL), a flexible module to ensemble several convolutional neural network (CNN) models and fuse with a focal loss for accurate COVID-19 detection on class imbalance data. FLANNEL consistently outperforms baseline models on COVID-19 identification task in all metrics. Compared with the best baseline, FLANNEL shows a higher macro-F1 score with 6% relative increase on Covid-19 identification task where it achieves 0.7833(0.07) in Precision, 0.8609(0.03) in Recall, and 0.8168(0.03) F1 score.
Gaussian Constrained Attention Network for Scene Text Recognition
Oct 19, 2020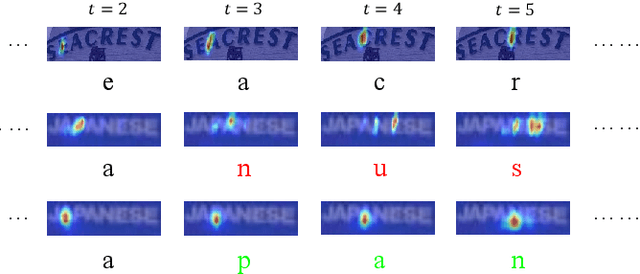
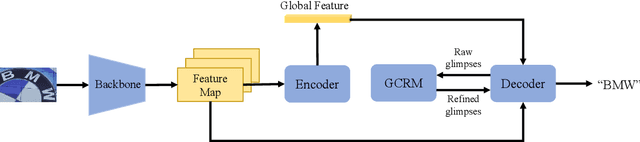
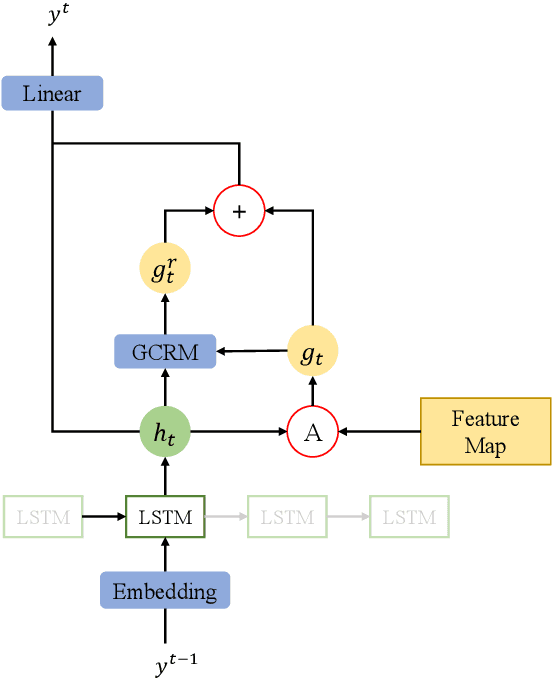
Scene text recognition has been a hot topic in computer vision. Recent methods adopt the attention mechanism for sequence prediction which achieve convincing results. However, we argue that the existing attention mechanism faces the problem of attention diffusion, in which the model may not focus on a certain character area. In this paper, we propose Gaussian Constrained Attention Network to deal with this problem. It is a 2D attention-based method integrated with a novel Gaussian Constrained Refinement Module, which predicts an additional Gaussian mask to refine the attention weights. Different from adopting an additional supervision on the attention weights simply, our proposed method introduces an explicit refinement. In this way, the attention weights will be more concentrated and the attention-based recognition network achieves better performance. The proposed Gaussian Constrained Refinement Module is flexible and can be applied to existing attention-based methods directly. The experiments on several benchmark datasets demonstrate the effectiveness of our proposed method. Our code has been available at https://github.com/Pay20Y/GCAN.
SEED: Semantics Enhanced Encoder-Decoder Framework for Scene Text Recognition
May 22, 2020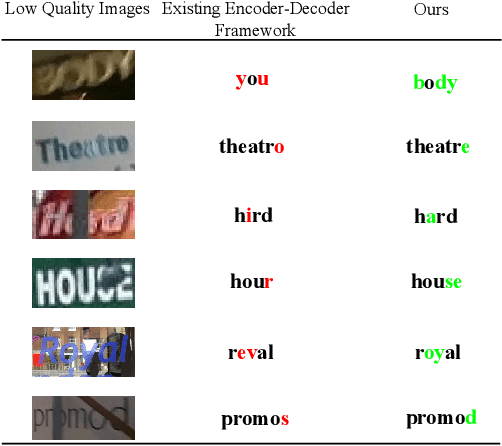
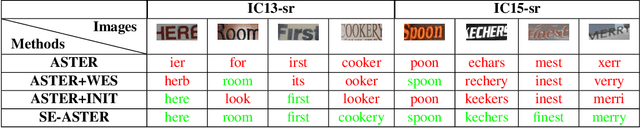
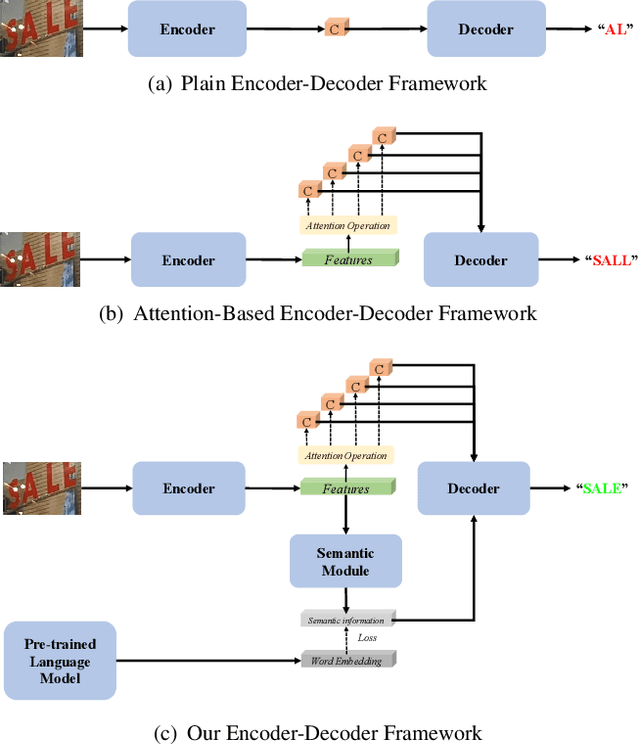

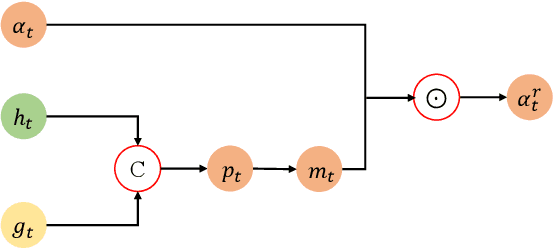
Scene text recognition is a hot research topic in computer vision. Recently, many recognition methods based on the encoder-decoder framework have been proposed, and they can handle scene texts of perspective distortion and curve shape. Nevertheless, they still face lots of challenges like image blur, uneven illumination, and incomplete characters. We argue that most encoder-decoder methods are based on local visual features without explicit global semantic information. In this work, we propose a semantics enhanced encoder-decoder framework to robustly recognize low-quality scene texts. The semantic information is used both in the encoder module for supervision and in the decoder module for initializing. In particular, the state-of-the art ASTER method is integrated into the proposed framework as an exemplar. Extensive experiments demonstrate that the proposed framework is more robust for low-quality text images, and achieves state-of-the-art results on several benchmark datasets.
Combining GHOST and Casper
May 11, 2020
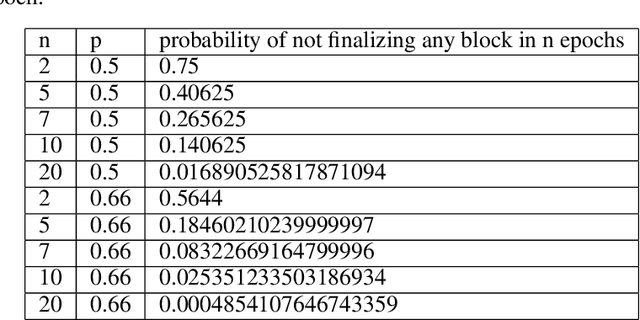
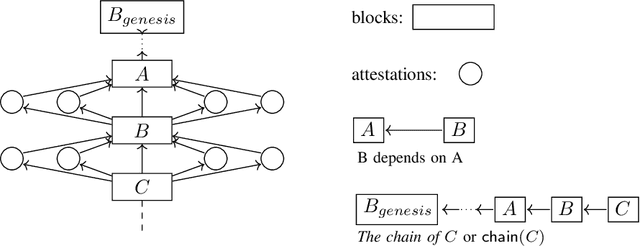
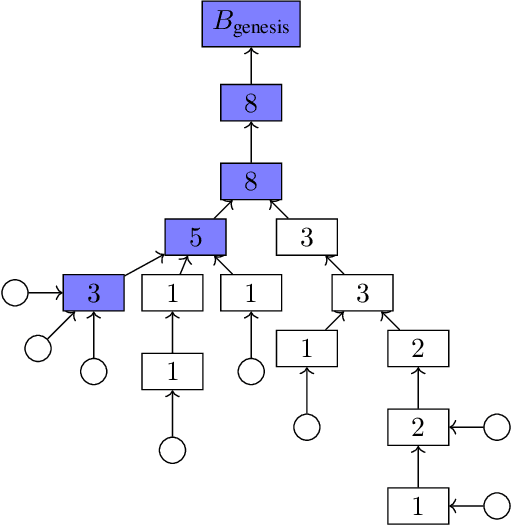
We present "Gasper," a proof-of-stake-based consensus protocol, which is an idealized version of the proposed Ethereum 2.0 beacon chain. The protocol combines Casper FFG, a finality tool, with LMD GHOST, a fork-choice rule. We prove safety, plausible liveness, and probabilistic liveness under different sets of assumptions.
Shape-Aware Organ Segmentation by Predicting Signed Distance Maps
Dec 09, 2019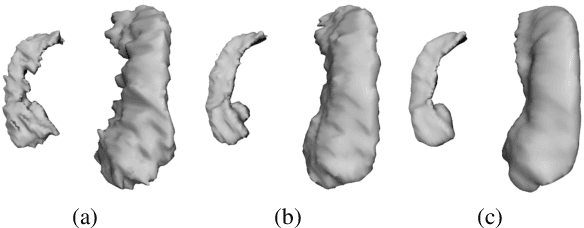
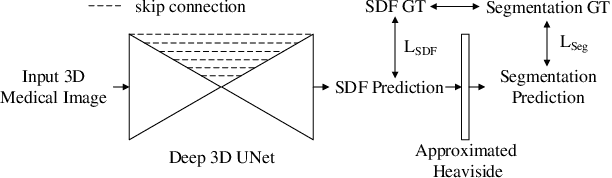
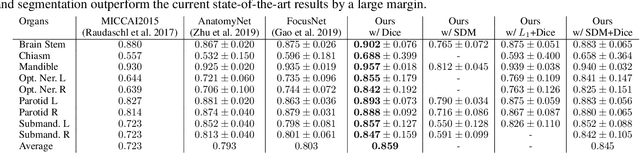
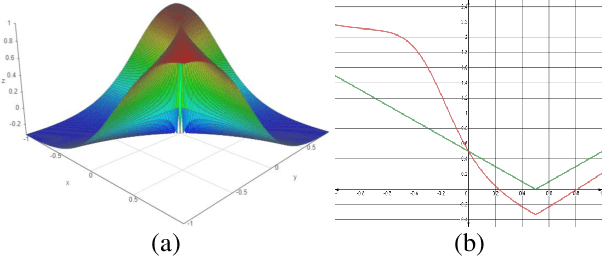
In this work, we propose to resolve the issue existing in current deep learning based organ segmentation systems that they often produce results that do not capture the overall shape of the target organ and often lack smoothness. Since there is a rigorous mapping between the Signed Distance Map (SDM) calculated from object boundary contours and the binary segmentation map, we exploit the feasibility of learning the SDM directly from medical scans. By converting the segmentation task into predicting an SDM, we show that our proposed method retains superior segmentation performance and has better smoothness and continuity in shape. To leverage the complementary information in traditional segmentation training, we introduce an approximated Heaviside function to train the model by predicting SDMs and segmentation maps simultaneously. We validate our proposed models by conducting extensive experiments on a hippocampus segmentation dataset and the public MICCAI 2015 Head and Neck Auto Segmentation Challenge dataset with multiple organs. While our carefully designed backbone 3D segmentation network improves the Dice coefficient by more than 5% compared to current state-of-the-arts, the proposed model with SDM learning produces smoother segmentation results with smaller Hausdorff distance and average surface distance, thus proving the effectiveness of our method.