 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlbedoEdit: Unified Instance-Level Video Editing with Albedo Guidance
May 31, 2026Video generative models have achieved remarkable progress in synthesizing photorealistic video sequences. However, enabling broader and more creative downstream applications requires fine-grained instance-level video editing, including object insertion, object removal, and texture editing, which has emerged as a prominent yet challenging problem. Existing approaches either propose unified generative frameworks with only coarse semantic control, or design task-specific frameworks for individual editing tasks, limiting their flexibility and applicability across diverse real-world scenarios. To address these limitations, we propose AlbedoEdit, a unified generative video editing framework that jointly supports object insertion, object removal, and texture editing. Our key insight is that the intrinsic albedo map, which is invariant to lighting and contains no specularity, shadowing and inter-reflection effects, provides an effective and user-friendly mechanism for specifying fine-grained appearance edits. Built upon video foundation models, AlbedoEdit is fine-tuned to translate source RGB videos into edited RGB videos, conditioned on a user-edited first-frame albedo. Trained on a new paired synthetic dataset covering all three editing tasks, AlbedoEdit implicitly learns to harmonize edited contents and simulate complex real-world visual effects triggered by editing operations, including specular highlights, soft shadows, and mirror reflections. AlbedoEdit demonstrates superior performance over state-of-the-art video editing approaches, both qualitatively and quantitatively. Project webpage is https://vcai.mpi-inf.mpg.de/projects/AlbedoEdit/.
Traceable Knowledge Graph Reasoning Enables LLM-Assisted Decision Support for Industrial VOCs in the Steel Industry
May 26, 2026Key knowledge for steel-industry volatile organic compounds (VOCs) governance is scattered across unstructured scientific literature, making it difficult to integrate process, pollutant, and control-technology evidence and increasing the risk of hallucination when general large language models (LLMs) answer low-frequency industrial questions. Here we developed Chat-ISV, a knowledge graph (KG) enhanced multi-agent Q&A system that parses a curated steel-industry VOCs literature corpus, constructs a Neo4j KG with 27180 nodes and 81779 semantic edges, and combines prompt-constrained extraction, chunk-centered topology optimization, multi-agent routing, source-backtracking retrieval, local literature retrieval, open-domain knowledge access, and interactive subgraph visualization. Benchmark tests and 400 expert blind evaluations showed that topology optimization reduced isolated nodes from 57% to 4.08% and that Chat-ISV achieved high factual reliability, with 96.93% precision, 72.63% recall, an F1-score of 0.830, and a mean score of 1.69/2.00. By converting fragmented environmental-engineering literature into traceable, queryable, and decision-support-oriented knowledge, Chat-ISV establishes a scalable environmental-informatics paradigm for reliable LLM deployment and intelligent pollution-control decision support in specialized industrial domains.
VideoMatGen: PBR Materials through Joint Generative Modeling
Mar 17, 2026We present a method for generating physically-based materials for 3D shapes based on a video diffusion transformer architecture. Our method is conditioned on input geometry and a text description, and jointly models multiple material properties (base color, roughness, metallicity, height map) to form physically plausible materials. We further introduce a custom variational auto-encoder which encodes multiple material modalities into a compact latent space, which enables joint generation of multiple modalities without increasing the number of tokens. Our pipeline generates high-quality materials for 3D shapes given a text prompt, compatible with common content creation tools.
Neural Image Space Tessellation
Feb 27, 2026We present Neural Image-Space Tessellation (NIST), a lightweight screen-space post-processing approach that produces the visual effect of tessellated geometry while rendering only the original low-polygon meshes. Inspired by our observation from Phong tessellation, NIST leverages the discrepancy between geometric normals and shading normals as a minimal, view-dependent cue for silhouette refinement. At its core, NIST performs multi-scale neural tessellation by progressively deforming image-space contours with convolutional operators, while jointly reassigning appearance information through an implicit warping mechanism to preserve texture coherence and visual fidelity. Experiments demonstrate that our approach produces smooth, visually coherent silhouettes comparable to geometric tessellation, while incurring a constant per-frame cost and fully decoupled from geometric complexity, making it well-suited for large-scale real-time rendering scenarios. To the best of our knowledge, our NIST is the first work to reformulate tessellation as a post-processing operation, shifting it from a pre-rendering geometry pipeline to a screen space neural post-processing stage.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
VideoNeuMat: Neural Material Extraction from Generative Video Models
Feb 06, 2026Creating photorealistic materials for 3D rendering requires exceptional artistic skill. Generative models for materials could help, but are currently limited by the lack of high-quality training data. While recent video generative models effortlessly produce realistic material appearances, this knowledge remains entangled with geometry and lighting. We present VideoNeuMat, a two-stage pipeline that extracts reusable neural material assets from video diffusion models. First, we finetune a large video model (Wan 2.1 14B) to generate material sample videos under controlled camera and lighting trajectories, effectively creating a "virtual gonioreflectometer" that preserves the model's material realism while learning a structured measurement pattern. Second, we reconstruct compact neural materials from these videos through a Large Reconstruction Model (LRM) finetuned from a smaller Wan 1.3B video backbone. From 17 generated video frames, our LRM performs single-pass inference to predict neural material parameters that generalize to novel viewing and lighting conditions. The resulting materials exhibit realism and diversity far exceeding the limited synthetic training data, demonstrating that material knowledge can be successfully transferred from internet-scale video models into standalone, reusable neural 3D assets.
RGB$\leftrightarrow$X: Image decomposition and synthesis using material- and lighting-aware diffusion models
May 01, 2024



The three areas of realistic forward rendering, per-pixel inverse rendering, and generative image synthesis may seem like separate and unrelated sub-fields of graphics and vision. However, recent work has demonstrated improved estimation of per-pixel intrinsic channels (albedo, roughness, metallicity) based on a diffusion architecture; we call this the RGB$\rightarrow$X problem. We further show that the reverse problem of synthesizing realistic images given intrinsic channels, X$\rightarrow$RGB, can also be addressed in a diffusion framework. Focusing on the image domain of interior scenes, we introduce an improved diffusion model for RGB$\rightarrow$X, which also estimates lighting, as well as the first diffusion X$\rightarrow$RGB model capable of synthesizing realistic images from (full or partial) intrinsic channels. Our X$\rightarrow$RGB model explores a middle ground between traditional rendering and generative models: we can specify only certain appearance properties that should be followed, and give freedom to the model to hallucinate a plausible version of the rest. This flexibility makes it possible to use a mix of heterogeneous training datasets, which differ in the available channels. We use multiple existing datasets and extend them with our own synthetic and real data, resulting in a model capable of extracting scene properties better than previous work and of generating highly realistic images of interior scenes.
Information-driven Path Planning for Hybrid Aerial Underwater Vehicles
Apr 08, 2022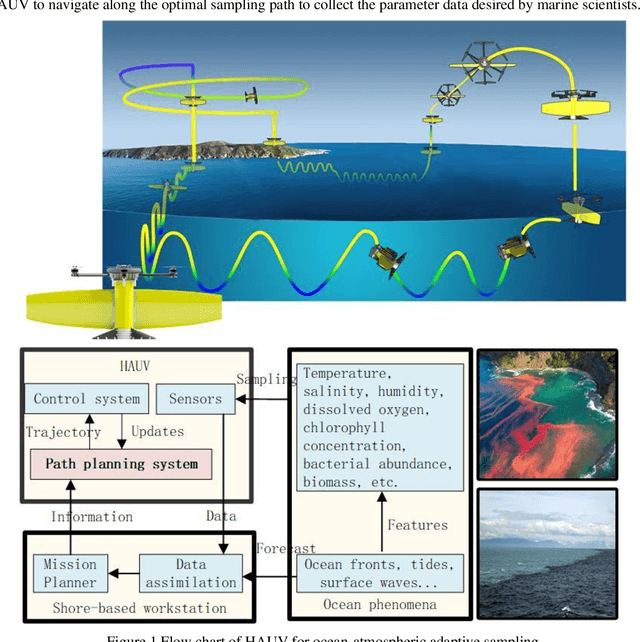
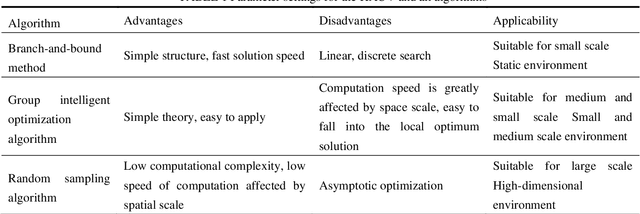

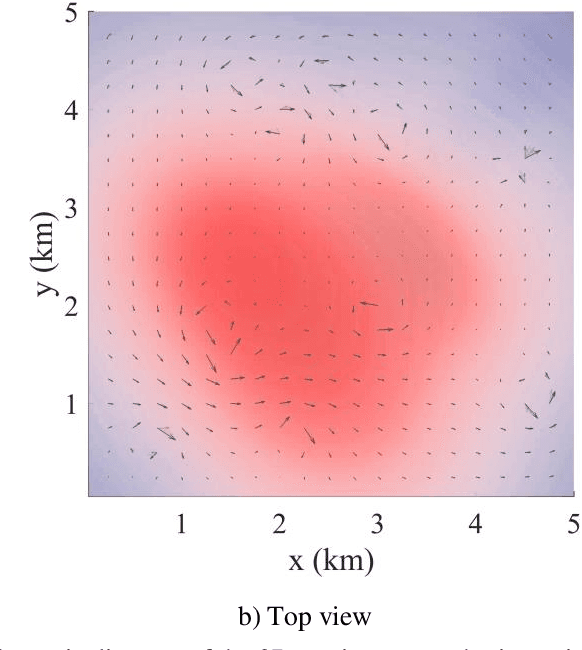
This paper presents a novel Rapidly-exploring Adaptive Sampling Tree (RAST) algorithm for the adaptive sampling mission of a hybrid aerial underwater vehicle (HAUV) in an air-sea 3D environment. This algorithm innovatively combines the tournament-based point selection sampling strategy, the information heuristic search process and the framework of Rapidly-exploring Random Tree (RRT) algorithm. Hence can guide the vehicle to the region of interest to scientists for sampling and generate a collision-free path for maximizing information collection by the HAUV under the constraints of environmental effects of currents or wind and limited budget. The simulation results show that the fast search adaptive sampling tree algorithm has higher optimization performance, faster solution speed and better stability than the Rapidly-exploring Information Gathering Tree (RIGT) algorithm and the particle swarm optimization (PSO) algorithm.