 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical Layer Security in FAS-aided Wireless Powered NOMA Systems
Jan 15, 2025



The rapid evolution of communication technologies and the emergence of sixth-generation (6G) networks have introduced unprecedented opportunities for ultra-reliable, low-latency, and energy-efficient communication. However, the integration of advanced technologies like non-orthogonal multiple access (NOMA) and wireless powered communication networks (WPCNs) brings significant challenges, particularly in terms of energy constraints and security vulnerabilities. Traditional antenna systems and orthogonal multiple access schemes struggle to meet the increasing demands for performance and security in such environments. To address this gap, this paper investigates the impact of emerging fluid antenna systems (FAS) on the performance of physical layer security (PLS) in WPCNs. Specifically, we consider a scenario in which a transmitter, powered by a power beacon via an energy link, transmits confidential messages to legitimate FAS-aided users over information links while an external eavesdropper attempts to decode the transmitted signals. Additionally, users leverage the NOMA scheme, where the far user may also act as an internal eavesdropper. For the proposed model, we first derive the distributions of the equivalent channels at each node and subsequently obtain compact expressions for the secrecy outage probability (SOP) and average secrecy capacity (ASC), using the Gaussian quadrature methods. Our results reveal that incorporating the FAS for NOMA users, instead of the TAS, enhances the performance of the proposed secure WPCN.
Long or Short or Both? An Exploration on Lookback Time Windows of Behavioral Features in Product Search Ranking
Sep 26, 2024



Customer shopping behavioral features are core to product search ranking models in eCommerce. In this paper, we investigate the effect of lookback time windows when aggregating these features at the (query, product) level over history. By studying the pros and cons of using long and short time windows, we propose a novel approach to integrating these historical behavioral features of different time windows. In particular, we address the criticality of using query-level vertical signals in ranking models to effectively aggregate all information from different behavioral features. Anecdotal evidence for the proposed approach is also provided using live product search traffic on Walmart.com.
Towards More Relevant Product Search Ranking Via Large Language Models: An Empirical Study
Sep 26, 2024



Training Learning-to-Rank models for e-commerce product search ranking can be challenging due to the lack of a gold standard of ranking relevance. In this paper, we decompose ranking relevance into content-based and engagement-based aspects, and we propose to leverage Large Language Models (LLMs) for both label and feature generation in model training, primarily aiming to improve the model's predictive capability for content-based relevance. Additionally, we introduce different sigmoid transformations on the LLM outputs to polarize relevance scores in labeling, enhancing the model's ability to balance content-based and engagement-based relevances and thus prioritize highly relevant items overall. Comprehensive online tests and offline evaluations are also conducted for the proposed design. Our work sheds light on advanced strategies for integrating LLMs into e-commerce product search ranking model training, offering a pathway to more effective and balanced models with improved ranking relevance.
A White-Box Deep-Learning Method for Electrical Energy System Modeling Based on Kolmogorov-Arnold Network
Sep 12, 2024



Deep learning methods have been widely used as an end-to-end modeling strategy of electrical energy systems because of their conveniency and powerful pattern recognition capability. However, due to the "black-box" nature, deep learning methods have long been blamed for their poor interpretability when modeling a physical system. In this paper, we introduce a novel neural network structure, Kolmogorov-Arnold Network (KAN), to achieve "white-box" modeling for electrical energy systems to enhance the interpretability. The most distinct feature of KAN lies in the learnable activation function together with the sparse training and symbolification process. Consequently, KAN can express the physical process with concise and explicit mathematical formulas while remaining the nonlinear-fitting capability of deep neural networks. Simulation results based on three electrical energy systems demonstrate the effectiveness of KAN in the aspects of interpretability, accuracy, robustness and generalization ability.
RIS-Aided Backscattering Tag-to-Tag Networks: Performance Analysis
Aug 29, 2024



Backscattering tag-to-tag networks (BTTNs) represent a passive radio frequency identification (RFID) system that enables direct communication between tags within an external radio frequency (RF) field. However, low spectral efficiency and short-range communication capabilities, along with the ultra-low power nature of the tags, create significant challenges for reliable and practical applications of BTTNs. To address these challenges, this paper introduces integrating an indoor reconfigurable intelligent surface (RIS) into BTTN and studying RIS's impact on the system's performance. To that end, we first derive compact analytical expressions of the probability density function (PDF) and cumulative distribution function (CDF) for the received signal-to-noise ratio (SNR) at the receiver tag by exploiting the moment matching technique. Then, based on the derived PDF and CDF, we further derive analytical expressions of outage probability (OP), bit error rate (BER), and average capacity (AC) rate. Eventually, the Monte Carlo simulation is used to validate the accuracy of the analytical results, revealing that utilizing RIS can greatly improve the performance of BTTNs in terms of AC, BER, OP, and coverage region relative to traditional BTTNs setups that do not incorporate RIS.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
A Neural-Network-Embedded Equivalent Circuit Model for Lithium-ion Battery State Estimation
Jul 24, 2024Equivalent Circuit Model(ECM)has been widelyused in battery modeling and state estimation because of itssimplicity, stability and interpretability.However, ECM maygenerate large estimation errors in extreme working conditionssuch as freezing environmenttemperature andcomplexcharging/discharging behaviors,in whichscenariostheelectrochemical characteristics of the battery become extremelycomplex and nonlinear.In this paper,we propose a hybridbattery model by embeddingneural networks as 'virtualelectronic components' into the classical ECM to enhance themodel nonlinear-fitting ability and adaptability. First, thestructure of the proposed hybrid model is introduced, where theembedded neural networks are targeted to fit the residuals of theclassical ECM,Second, an iterative offline training strategy isdesigned to train the hybrid model by merging the battery statespace equation into the neural network loss function. Last, thebattery online state of charge (SOC)estimation is achieved basedon the proposed hybrid model to demonstrate its applicationvalue,Simulation results based on a real-world battery datasetshow that the proposed hybrid model can achieve 29%-64%error reduction for $OC estimation under different operatingconditions at varying environment temperatures.
Unsupervised and Interpretable Synthesizing for Electrical Time Series Based on Information Maximizing Generative Adversarial Nets
Jul 18, 2024



Generating synthetic data has become a popular alternative solution to deal with the difficulties in accessing and sharing field measurement data in power systems. However, to make the generation results controllable, existing methods (e.g. Conditional Generative Adversarial Nets, cGAN) require labeled dataset to train the model, which is demanding in practice because many field measurement data lacks descriptive labels. In this paper, we introduce the Information Maximizing Generative Adversarial Nets (infoGAN) to achieve interpretable feature extraction and controllable synthetic data generation based on the unlabeled electrical time series dataset. Features with clear physical meanings can be automatically extracted by maximizing the mutual information between the input latent code and the classifier output of infoGAN. Then the extracted features are used to control the generation results similar to a vanilla cGAN framework. Case study is based on the time series datasets of power load and renewable energy output. Results demonstrate that infoGAN can extract both discrete and continuous features with clear physical meanings, as well as generating realistic synthetic time series that satisfy given features.
On Performance of FAS-aided Wireless Powered NOMA Communication Systems
May 19, 2024


This paper studies the performance of a wireless powered communication network (WPCN) under the non-orthogonal multiple access (NOMA) scheme, where users take advantage of an emerging fluid antenna system (FAS). More precisely, we consider a scenario where a transmitter is powered by a remote power beacon (PB) to send information to the planar NOMA FAS-equipped users through Rayleigh fading channels. After introducing the distribution of the equivalent channel coefficients to the users, we derive compact analytical expressions for the outage probability (OP) in order to evaluate the system performance. Additionally, we present asymptotic OP in the high signal-to-noise ratio (SNR) regime. Eventually, results reveal that deploying the FAS with only one activated port in NOMA users can significantly enhance the WPCN performance compared with using traditional antenna systems (TAS).
FlowMur: A Stealthy and Practical Audio Backdoor Attack with Limited Knowledge
Dec 15, 2023

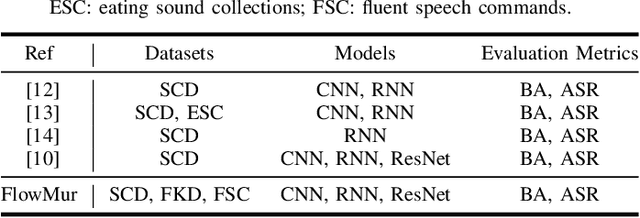
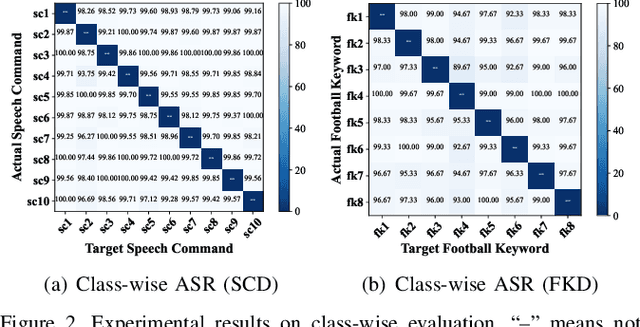
Speech recognition systems driven by DNNs have revolutionized human-computer interaction through voice interfaces, which significantly facilitate our daily lives. However, the growing popularity of these systems also raises special concerns on their security, particularly regarding backdoor attacks. A backdoor attack inserts one or more hidden backdoors into a DNN model during its training process, such that it does not affect the model's performance on benign inputs, but forces the model to produce an adversary-desired output if a specific trigger is present in the model input. Despite the initial success of current audio backdoor attacks, they suffer from the following limitations: (i) Most of them require sufficient knowledge, which limits their widespread adoption. (ii) They are not stealthy enough, thus easy to be detected by humans. (iii) Most of them cannot attack live speech, reducing their practicality. To address these problems, in this paper, we propose FlowMur, a stealthy and practical audio backdoor attack that can be launched with limited knowledge. FlowMur constructs an auxiliary dataset and a surrogate model to augment adversary knowledge. To achieve dynamicity, it formulates trigger generation as an optimization problem and optimizes the trigger over different attachment positions. To enhance stealthiness, we propose an adaptive data poisoning method according to Signal-to-Noise Ratio (SNR). Furthermore, ambient noise is incorporated into the process of trigger generation and data poisoning to make FlowMur robust to ambient noise and improve its practicality. Extensive experiments conducted on two datasets demonstrate that FlowMur achieves high attack performance in both digital and physical settings while remaining resilient to state-of-the-art defenses. In particular, a human study confirms that triggers generated by FlowMur are not easily detected by participants.