 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Dental Landmarks from Intraoral 3D Scans: the 3DTeethLand challenge
Dec 09, 2025Teeth landmark detection is a critical task in modern clinical orthodontics. Their precise identification enables advanced diagnostics, facilitates personalized treatment strategies, and supports more effective monitoring of treatment progress in clinical dentistry. However, several significant challenges may arise due to the intricate geometry of individual teeth and the substantial variations observed across different individuals. To address these complexities, the development of advanced techniques, especially through the application of deep learning, is essential for the precise and reliable detection of 3D tooth landmarks. In this context, the 3DTeethLand challenge was held in collaboration with the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) in 2024, calling for algorithms focused on teeth landmark detection from intraoral 3D scans. This challenge introduced the first publicly available dataset for 3D teeth landmark detection, offering a valuable resource to assess the state-of-the-art methods in this task and encourage the community to provide methodological contributions towards the resolution of their problem with significant clinical implications.
AutoGMap: Learning to Map Large-scale Sparse Graphs on Memristive Crossbars
Nov 15, 2021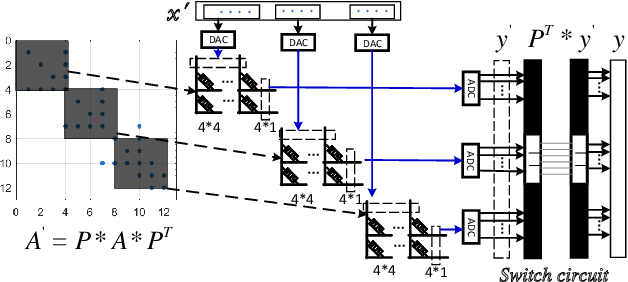
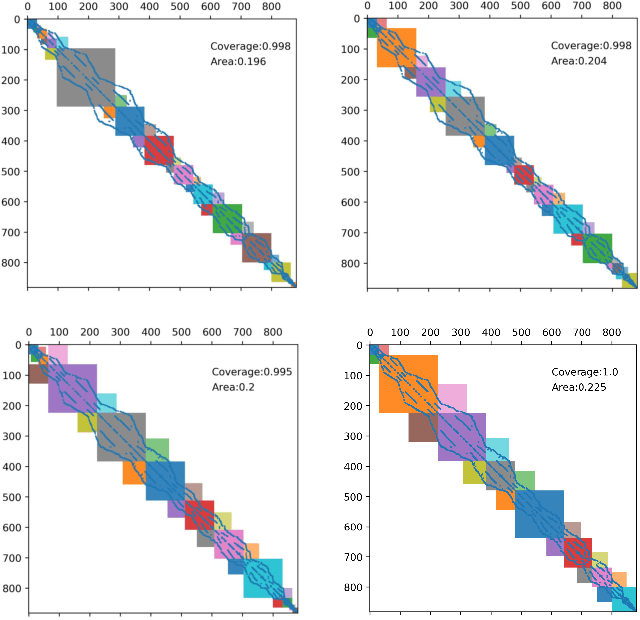
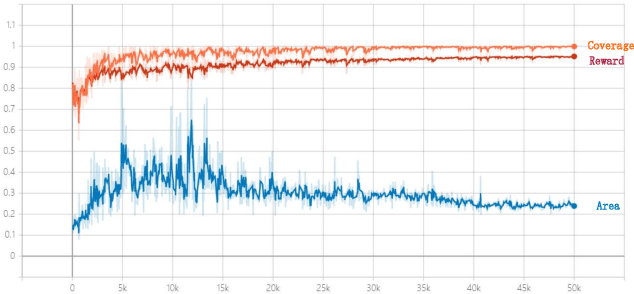
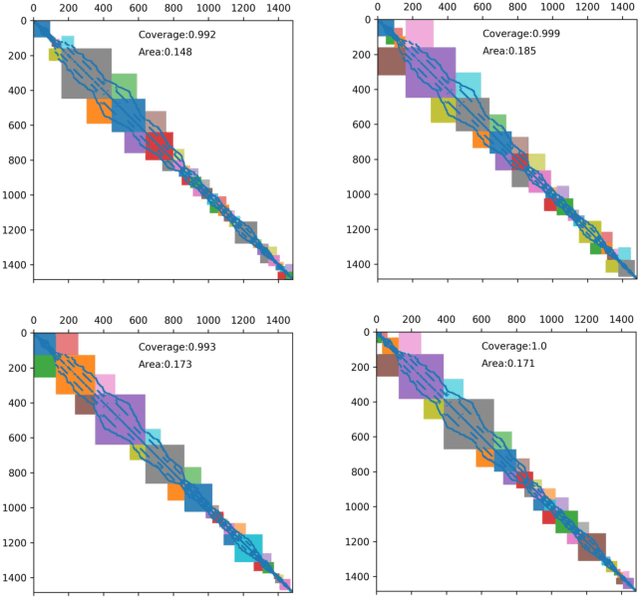
The sparse representation of graphs has shown its great potential for accelerating the computation of the graph applications (e.g. Social Networks, Knowledge Graphs) on traditional computing architectures (CPU, GPU, or TPU). But the exploration of the large-scale sparse graph computing on processing-in-memory (PIM) platforms (typically with memristive crossbars) is still in its infancy. As we look to implement the computation or storage of large-scale or batch graphs on memristive crossbars, a natural assumption would be that we need a large-scale crossbar, but with low utilization. Some recent works have questioned this assumption to avoid the waste of the storage and computational resource by "block partition", which is fixed-size, progressively scheduled, or coarse-grained, thus is not effectively sparsity-aware in our view. This work proposes the dynamic sparsity-aware mapping scheme generating method that models the problem as a sequential decision-making problem which is solved by reinforcement learning (RL) algorithm (REINFORCE). Our generating model (LSTM, combined with our dynamic-fill mechanism) generates remarkable mapping performance on a small-scale typical graph/matrix data (43% area of the original matrix with fully mapping), and two large-scale matrix data (22.5% area on qh882, and 17.1% area on qh1484). Moreover, our coding framework of the scheme is intuitive and has promising adaptability with the deployment or compilation system.
TND-NAS: Towards Non-differentiable Objectives in Progressive Differentiable NAS Framework
Nov 06, 2021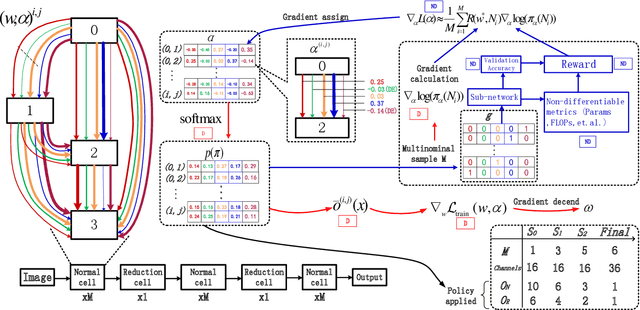
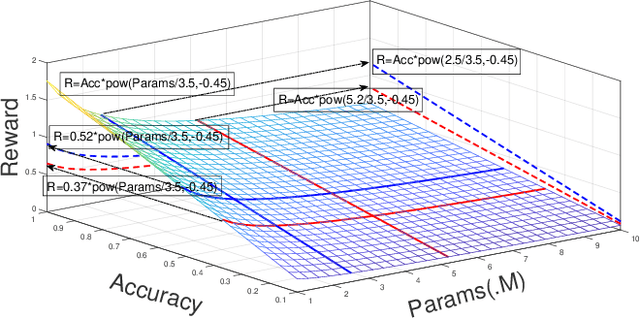
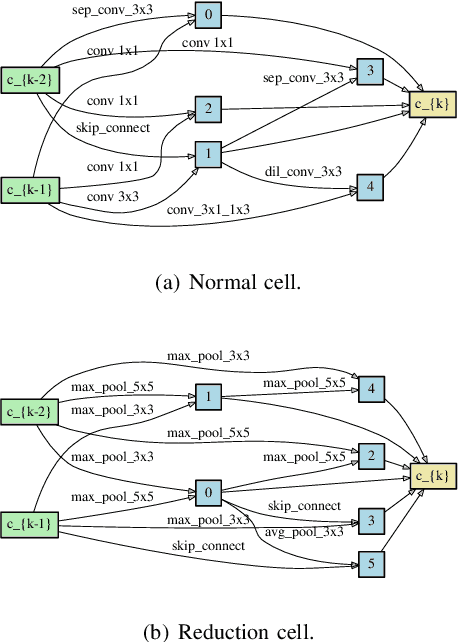
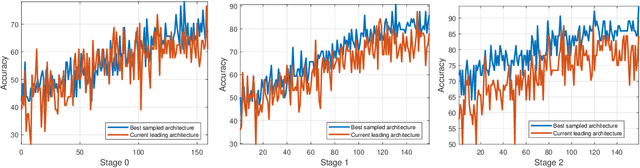
Differentiable architecture search has gradually become the mainstream research topic in the field of Neural Architecture Search (NAS) for its capability to improve efficiency compared with the early NAS (EA-based, RL-based) methods. Recent differentiable NAS also aims at further improving search efficiency, reducing the GPU-memory consumption, and addressing the "depth gap" issue. However, these methods are no longer capable of tackling the non-differentiable objectives, let alone multi-objectives, e.g., performance, robustness, efficiency, and other metrics. We propose an end-to-end architecture search framework towards non-differentiable objectives, TND-NAS, with the merits of the high efficiency in differentiable NAS framework and the compatibility among non-differentiable metrics in Multi-objective NAS (MNAS). Under differentiable NAS framework, with the continuous relaxation of the search space, TND-NAS has the architecture parameters ($\alpha$) been optimized in discrete space, while resorting to the search policy of progressively shrinking the supernetwork by $\alpha$. Our representative experiment takes two objectives (Parameters, Accuracy) as an example, we achieve a series of high-performance compact architectures on CIFAR10 (1.09M/3.3%, 2.4M/2.95%, 9.57M/2.54%) and CIFAR100 (2.46M/18.3%, 5.46/16.73%, 12.88/15.20%) datasets. Favorably, under real-world scenarios (resource-constrained, platform-specialized), the Pareto-optimal solutions can be conveniently reached by TND-NAS.