 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark and Baseline for Language-Driven Image Editing
Oct 05, 2020

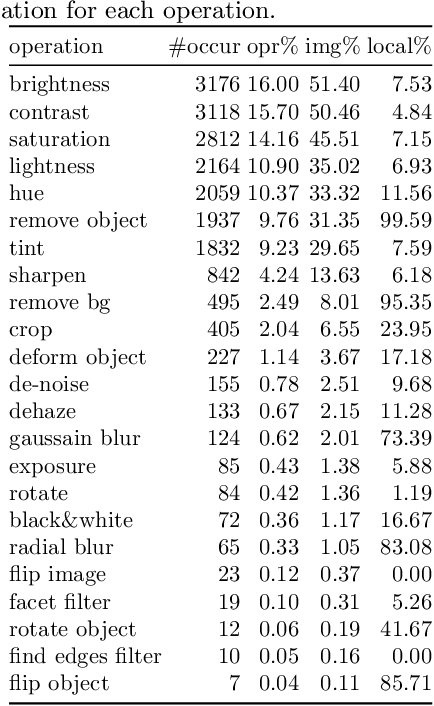
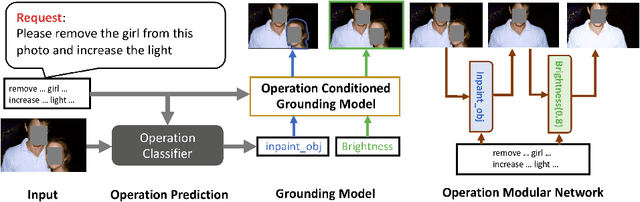
Language-driven image editing can significantly save the laborious image editing work and be friendly to the photography novice. However, most similar work can only deal with a specific image domain or can only do global retouching. To solve this new task, we first present a new language-driven image editing dataset that supports both local and global editing with editing operation and mask annotations. Besides, we also propose a baseline method that fully utilizes the annotation to solve this problem. Our new method treats each editing operation as a sub-module and can automatically predict operation parameters. Not only performing well on challenging user data, but such an approach is also highly interpretable. We believe our work, including both the benchmark and the baseline, will advance the image editing area towards a more general and free-form level.
On the Sample Complexity of Reinforcement Learning with Policy Space Generalization
Aug 17, 2020We study the optimal sample complexity in large-scale Reinforcement Learning (RL) problems with policy space generalization, i.e. the agent has a prior knowledge that the optimal policy lies in a known policy space. Existing results show that without a generalization model, the sample complexity of an RL algorithm will inevitably depend on the cardinalities of state space and action space, which are intractably large in many practical problems. To avoid such undesirable dependence on the state and action space sizes, this paper proposes a new notion of eluder dimension for the policy space, which characterizes the intrinsic complexity of policy learning in an arbitrary Markov Decision Process (MDP). Using a simulator oracle, we prove a near-optimal sample complexity upper bound that only depends linearly on the eluder dimension. We further prove a similar regret bound in deterministic systems without the simulator.
Low-rank Tensor Bandits
Jul 31, 2020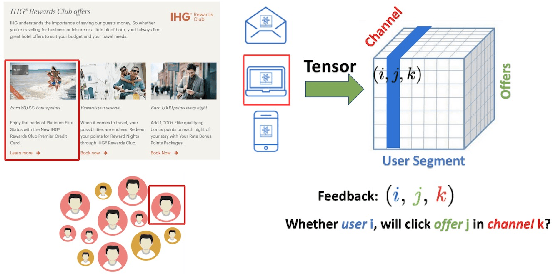
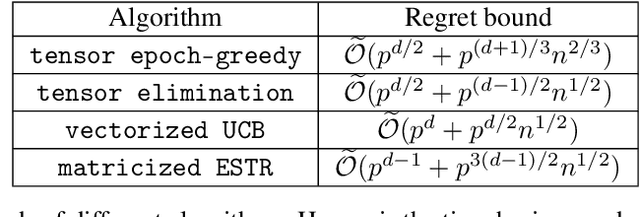
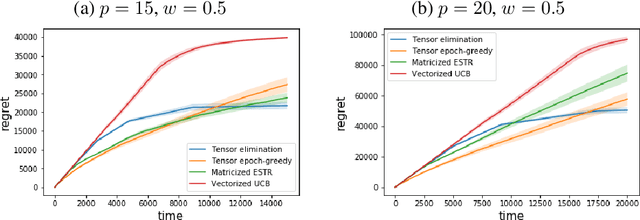
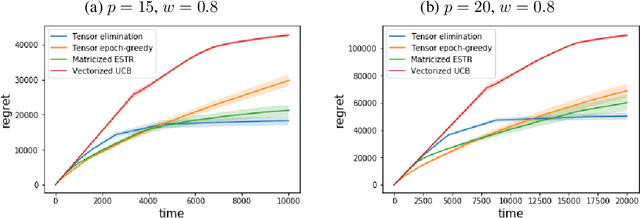
In recent years, multi-dimensional online decision making has been playing a crucial role in many practical applications such as online recommendation and digital marketing. To solve it, we introduce stochastic low-rank tensor bandits, a class of bandits whose mean rewards can be represented as a low-rank tensor. We propose two learning algorithms, tensor epoch-greedy and tensor elimination, and develop finite-time regret bounds for them. We observe that tensor elimination has an optimal dependency on the time horizon, while tensor epoch-greedy has a sharper dependency on tensor dimensions. Numerical experiments further back up these theoretical findings and show that our algorithms outperform various state-of-the-art approaches that ignore the tensor low-rank structure.
Structured Policy Iteration for Linear Quadratic Regulator
Jul 13, 2020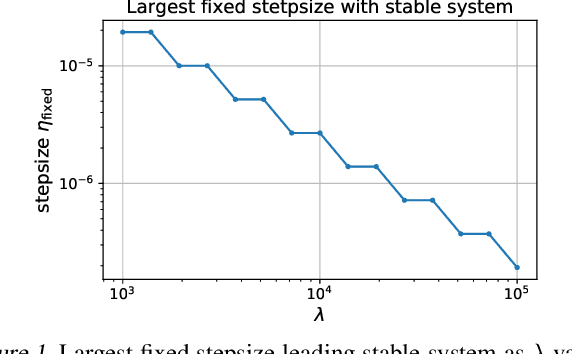
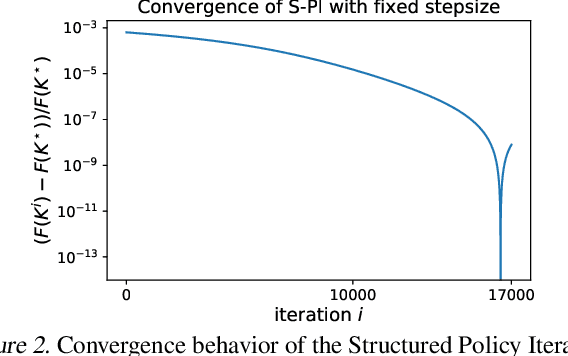
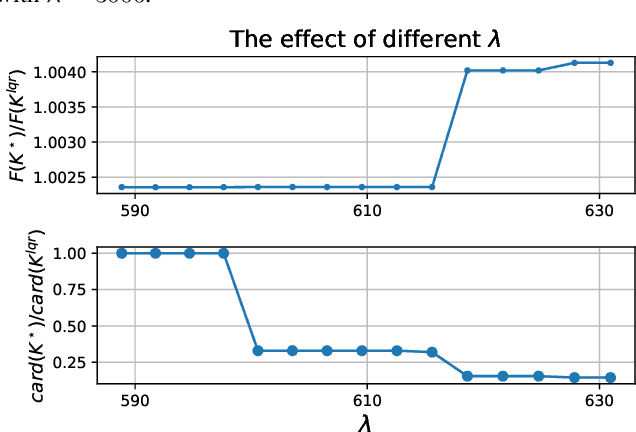
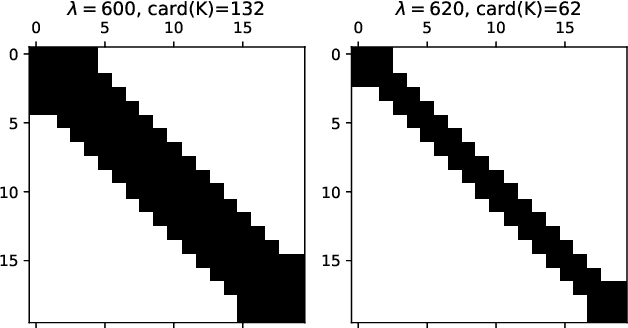
Linear quadratic regulator (LQR) is one of the most popular frameworks to tackle continuous Markov decision process tasks. With its fundamental theory and tractable optimal policy, LQR has been revisited and analyzed in recent years, in terms of reinforcement learning scenarios such as the model-free or model-based setting. In this paper, we introduce the \textit{Structured Policy Iteration} (S-PI) for LQR, a method capable of deriving a structured linear policy. Such a structured policy with (block) sparsity or low-rank can have significant advantages over the standard LQR policy: more interpretable, memory-efficient, and well-suited for the distributed setting. In order to derive such a policy, we first cast a regularized LQR problem when the model is known. Then, our Structured Policy Iteration (S-PI) algorithm, which takes a policy evaluation step and a policy improvement step in an iterative manner, can solve this regularized LQR efficiently. We further extend the S-PI algorithm to the model-free setting where a smoothing procedure is adopted to estimate the gradient. In both the known-model and model-free setting, we prove convergence analysis under the proper choice of parameters. Finally, the experiments demonstrate the advantages of S-PI in terms of balancing the LQR performance and level of structure by varying the weight parameter.
Influence Diagram Bandits: Variational Thompson Sampling for Structured Bandit Problems
Jul 09, 2020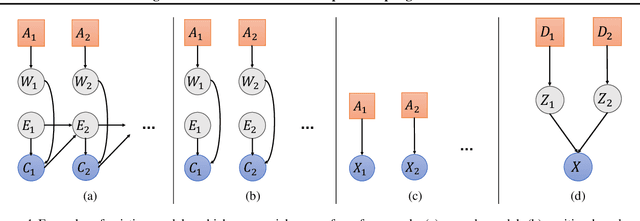
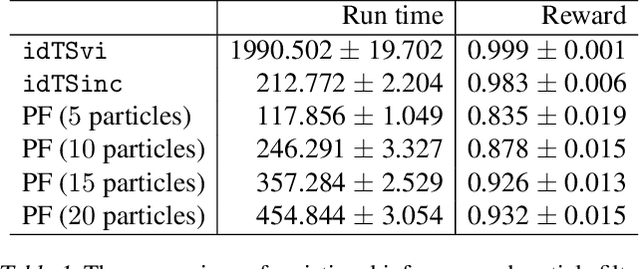
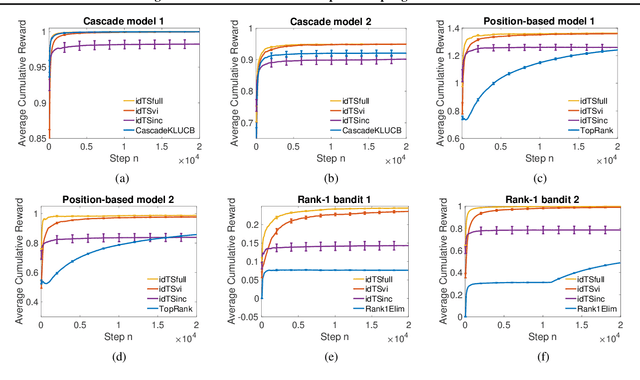
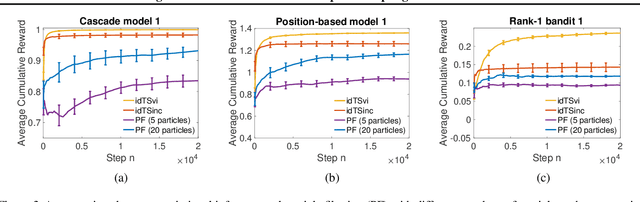
We propose a novel framework for structured bandits, which we call an influence diagram bandit. Our framework captures complex statistical dependencies between actions, latent variables, and observations; and thus unifies and extends many existing models, such as combinatorial semi-bandits, cascading bandits, and low-rank bandits. We develop novel online learning algorithms that learn to act efficiently in our models. The key idea is to track a structured posterior distribution of model parameters, either exactly or approximately. To act, we sample model parameters from their posterior and then use the structure of the influence diagram to find the most optimistic action under the sampled parameters. We empirically evaluate our algorithms in three structured bandit problems, and show that they perform as well as or better than problem-specific state-of-the-art baselines.
Hypermodels for Exploration
Jun 12, 2020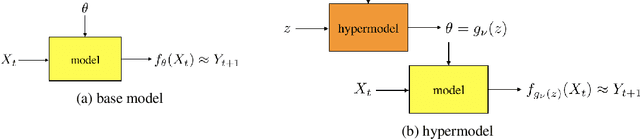
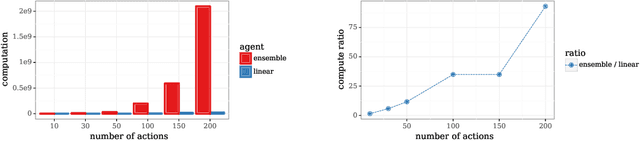
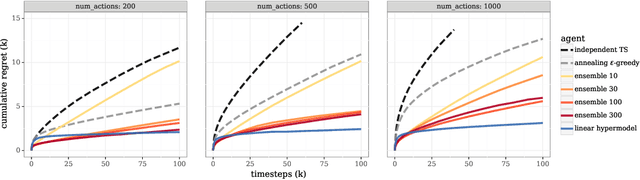
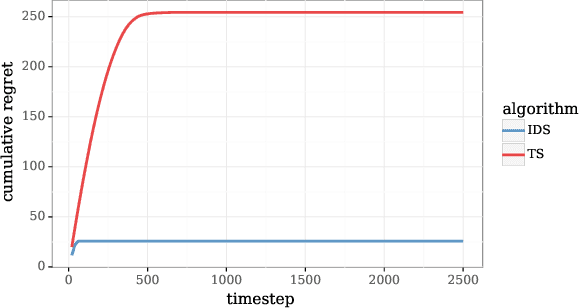
We study the use of hypermodels to represent epistemic uncertainty and guide exploration. This generalizes and extends the use of ensembles to approximate Thompson sampling. The computational cost of training an ensemble grows with its size, and as such, prior work has typically been limited to ensembles with tens of elements. We show that alternative hypermodels can enjoy dramatic efficiency gains, enabling behavior that would otherwise require hundreds or thousands of elements, and even succeed in situations where ensemble methods fail to learn regardless of size. This allows more accurate approximation of Thompson sampling as well as use of more sophisticated exploration schemes. In particular, we consider an approximate form of information-directed sampling and demonstrate performance gains relative to Thompson sampling. As alternatives to ensembles, we consider linear and neural network hypermodels, also known as hypernetworks. We prove that, with neural network base models, a linear hypermodel can represent essentially any distribution over functions, and as such, hypernetworks are no more expressive.
Improving Adversarial Text Generation by Modeling the Distant Future
May 04, 2020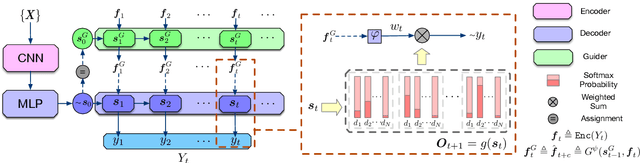
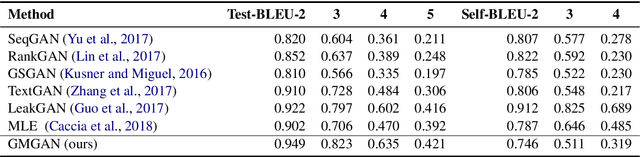
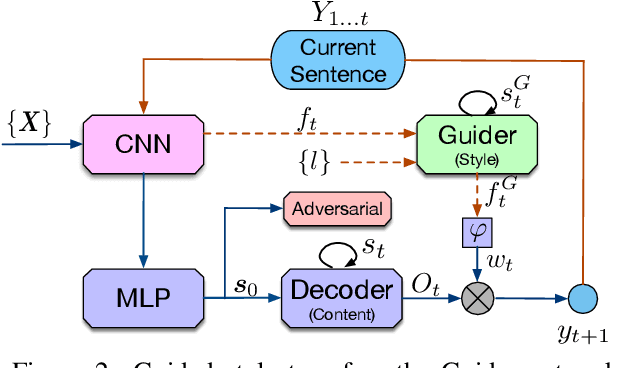
Auto-regressive text generation models usually focus on local fluency, and may cause inconsistent semantic meaning in long text generation. Further, automatically generating words with similar semantics is challenging, and hand-crafted linguistic rules are difficult to apply. We consider a text planning scheme and present a model-based imitation-learning approach to alleviate the aforementioned issues. Specifically, we propose a novel guider network to focus on the generative process over a longer horizon, which can assist next-word prediction and provide intermediate rewards for generator optimization. Extensive experiments demonstrate that the proposed method leads to improved performance.
Nested-Wasserstein Self-Imitation Learning for Sequence Generation
Jan 20, 2020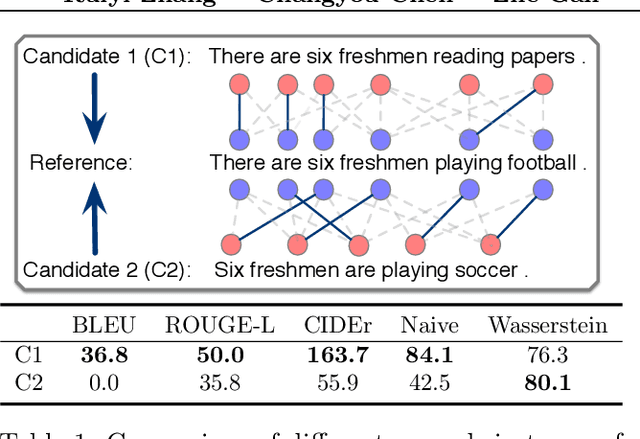
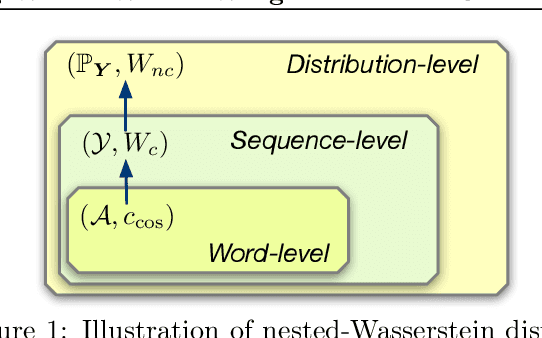
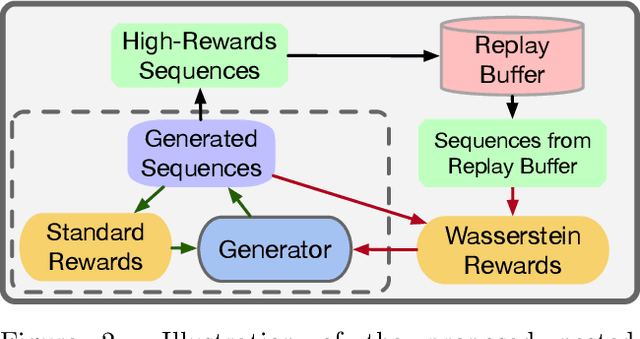
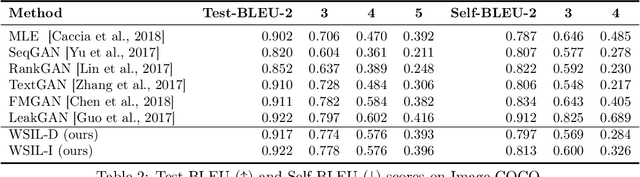
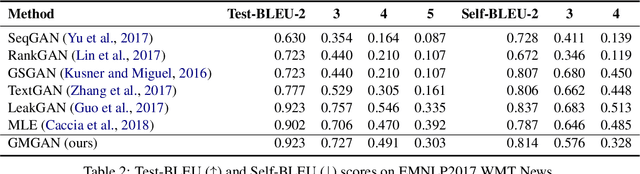
Reinforcement learning (RL) has been widely studied for improving sequence-generation models. However, the conventional rewards used for RL training typically cannot capture sufficient semantic information and therefore render model bias. Further, the sparse and delayed rewards make RL exploration inefficient. To alleviate these issues, we propose the concept of nested-Wasserstein distance for distributional semantic matching. To further exploit it, a novel nested-Wasserstein self-imitation learning framework is developed, encouraging the model to exploit historical high-rewarded sequences for enhanced exploration and better semantic matching. Our solution can be understood as approximately executing proximal policy optimization with Wasserstein trust-regions. Experiments on a variety of unconditional and conditional sequence-generation tasks demonstrate the proposed approach consistently leads to improved performance.
Bootstrapping Upper Confidence Bound
Jul 23, 2019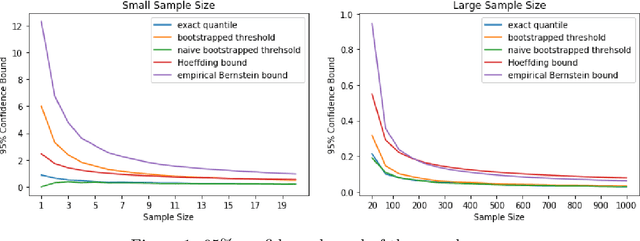
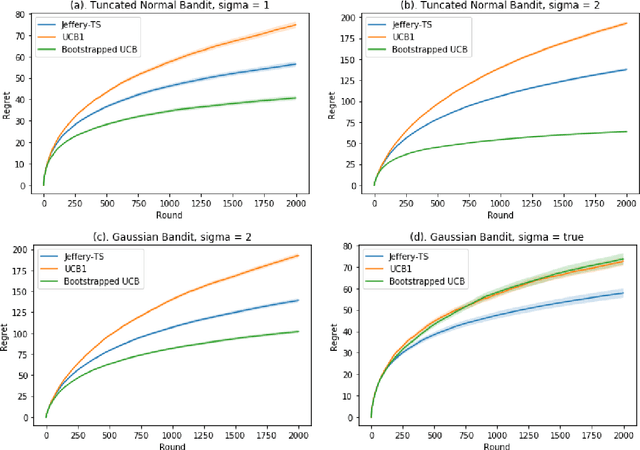
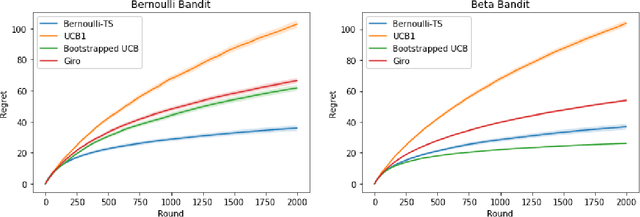
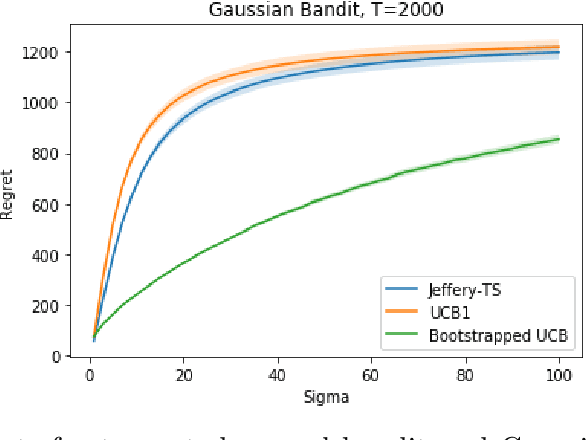
Upper Confidence Bound (UCB) method is arguably the most celebrated one used in online decision making with partial information feedback. Existing techniques for constructing confidence bounds are typically built upon various concentration inequalities, which thus lead to over-exploration. In this paper, we propose a non-parametric and data-dependent UCB algorithm based on the multiplier bootstrap. To improve its finite sample performance, we further incorporate second-order correction into the above construction. In theory, we derive both problem-dependent and problem-independent regret bounds for multi-armed bandits under a much weaker tail assumption than the standard sub-Gaussianity. Numerical results demonstrate significant regret reductions by our method, in comparison with several baselines in a range of multi-armed and linear bandit problems.
Waterfall Bandits: Learning to Sell Ads Online
Apr 20, 2019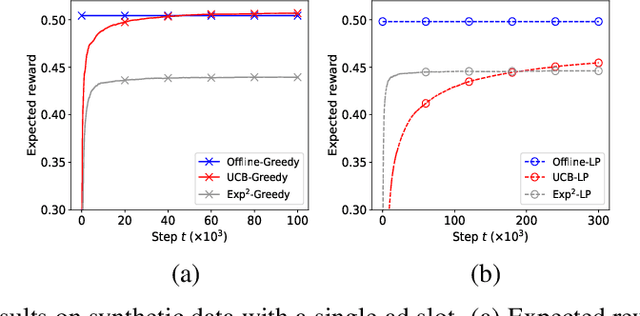
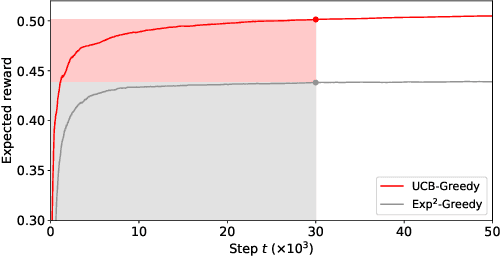
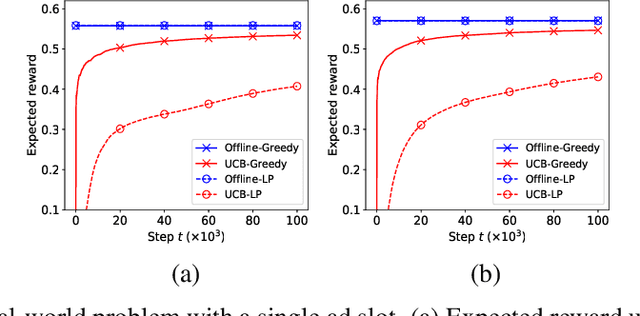
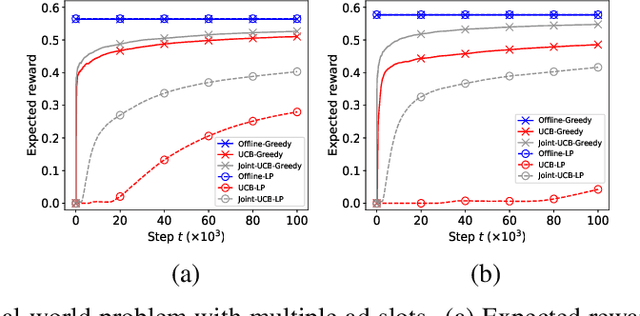
A popular approach to selling online advertising is by a waterfall, where a publisher makes sequential price offers to ad networks for an inventory, and chooses the winner in that order. The publisher picks the order and prices to maximize her revenue. A traditional solution is to learn the demand model and then subsequently solve the optimization problem for the given demand model. This will incur a linear regret. We design an online learning algorithm for solving this problem, which interleaves learning and optimization, and prove that this algorithm has sublinear regret. We evaluate the algorithm on both synthetic and real-world data, and show that it quickly learns high quality pricing strategies. This is the first principled study of learning a waterfall design online by sequential experimentation.