 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFGC 2022: The Second DeepFake Game Competition
Jun 30, 2022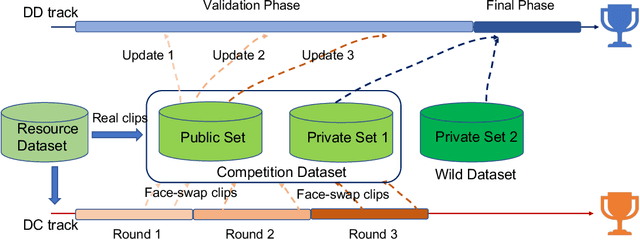
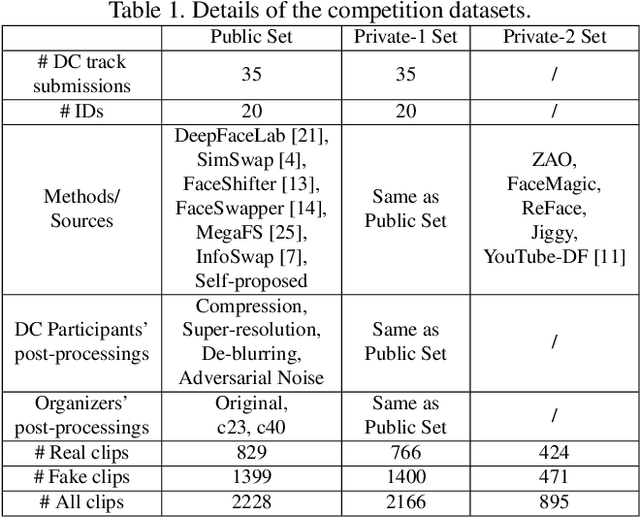
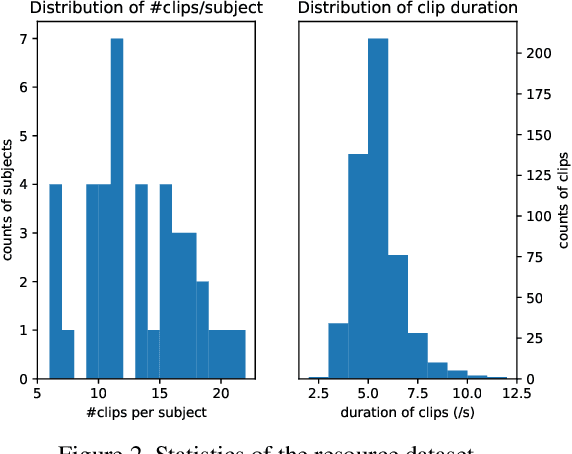
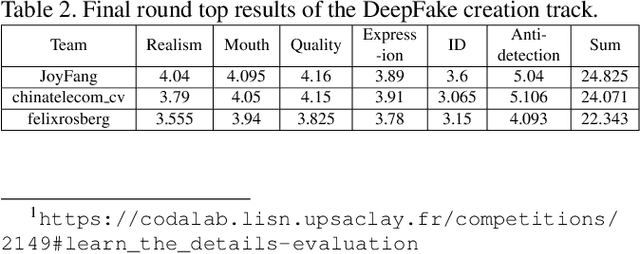
This paper presents the summary report on our DFGC 2022 competition. The DeepFake is rapidly evolving, and realistic face-swaps are becoming more deceptive and difficult to detect. On the contrary, methods for detecting DeepFakes are also improving. There is a two-party game between DeepFake creators and defenders. This competition provides a common platform for benchmarking the game between the current state-of-the-arts in DeepFake creation and detection methods. The main research question to be answered by this competition is the current state of the two adversaries when competed with each other. This is the second edition after the last year's DFGC 2021, with a new, more diverse video dataset, a more realistic game setting, and more reasonable evaluation metrics. With this competition, we aim to stimulate research ideas for building better defenses against the DeepFake threats. We also release our DFGC 2022 dataset contributed by both our participants and ourselves to enrich the DeepFake data resources for the research community (https://github.com/NiCE-X/DFGC-2022).
Disentangled Federated Learning for Tackling Attributes Skew via Invariant Aggregation and Diversity Transferring
Jun 14, 2022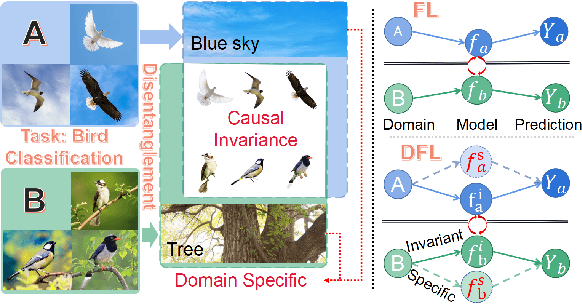

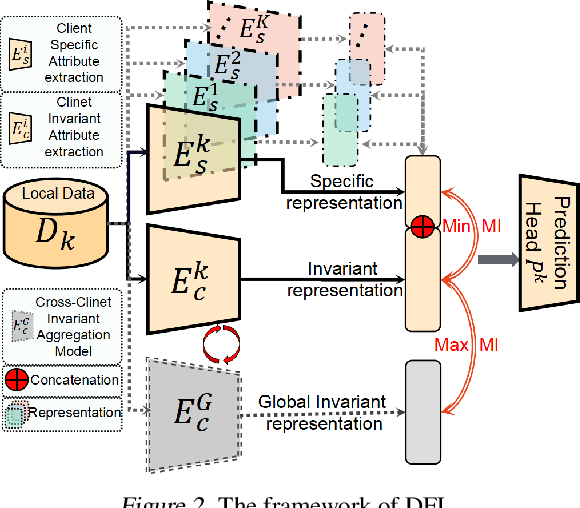
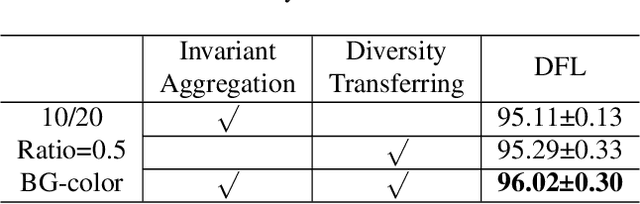
Attributes skew hinders the current federated learning (FL) frameworks from consistent optimization directions among the clients, which inevitably leads to performance reduction and unstable convergence. The core problems lie in that: 1) Domain-specific attributes, which are non-causal and only locally valid, are indeliberately mixed into global aggregation. 2) The one-stage optimizations of entangled attributes cannot simultaneously satisfy two conflicting objectives, i.e., generalization and personalization. To cope with these, we proposed disentangled federated learning (DFL) to disentangle the domain-specific and cross-invariant attributes into two complementary branches, which are trained by the proposed alternating local-global optimization independently. Importantly, convergence analysis proves that the FL system can be stably converged even if incomplete client models participate in the global aggregation, which greatly expands the application scope of FL. Extensive experiments verify that DFL facilitates FL with higher performance, better interpretability, and faster convergence rate, compared with SOTA FL methods on both manually synthesized and realistic attributes skew datasets.
ShowFace: Coordinated Face Inpainting with Memory-Disentangled Refinement Networks
Apr 16, 2022
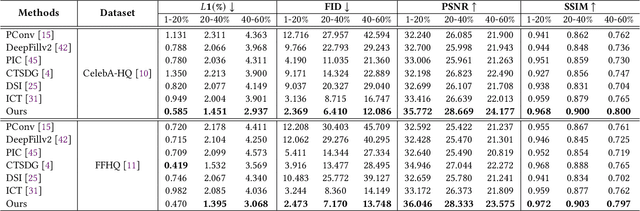
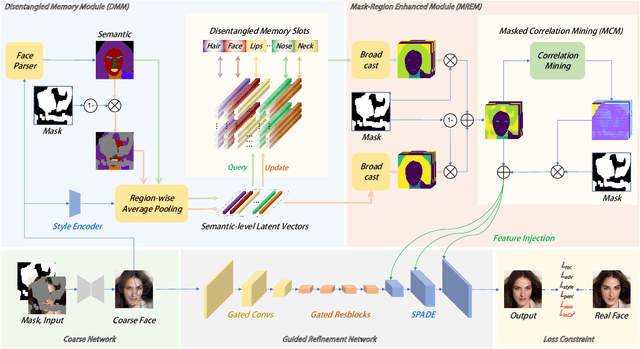
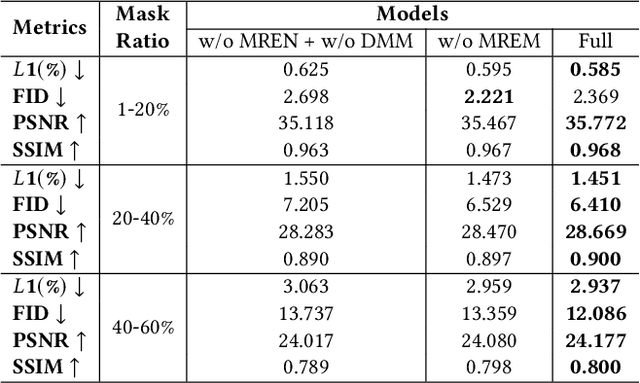
Face inpainting aims to complete the corrupted regions of the face images, which requires coordination between the completed areas and the non-corrupted areas. Recently, memory-oriented methods illustrate great prospects in the generation related tasks by introducing an external memory module to improve image coordination. However, such methods still have limitations in restoring the consistency and continuity for specificfacial semantic parts. In this paper, we propose the coarse-to-fine Memory-Disentangled Refinement Networks (MDRNets) for coordinated face inpainting, in which two collaborative modules are integrated, Disentangled Memory Module (DMM) and Mask-Region Enhanced Module (MREM). Specifically, the DMM establishes a group of disentangled memory blocks to store the semantic-decoupled face representations, which could provide the most relevant information to refine the semantic-level coordination. The MREM involves a masked correlation mining mechanism to enhance the feature relationships into the corrupted regions, which could also make up for the correlation loss caused by memory disentanglement. Furthermore, to better improve the inter-coordination between the corrupted and non-corrupted regions and enhance the intra-coordination in corrupted regions, we design InCo2 Loss, a pair of similarity based losses to constrain the feature consistency. Eventually, extensive experiments conducted on CelebA-HQ and FFHQ datasets demonstrate the superiority of our MDRNets compared with previous State-Of-The-Art methods.
AnyFace: Free-style Text-to-Face Synthesis and Manipulation
Mar 29, 2022
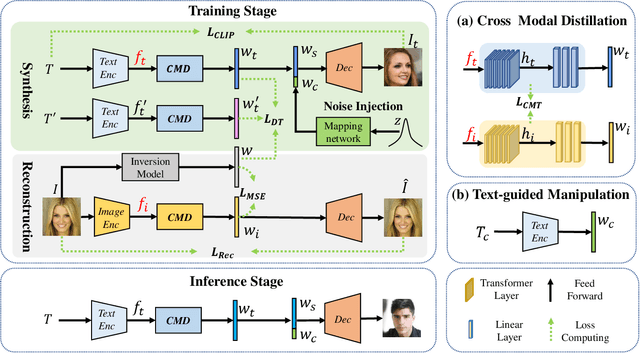
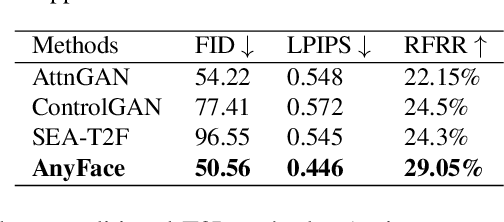
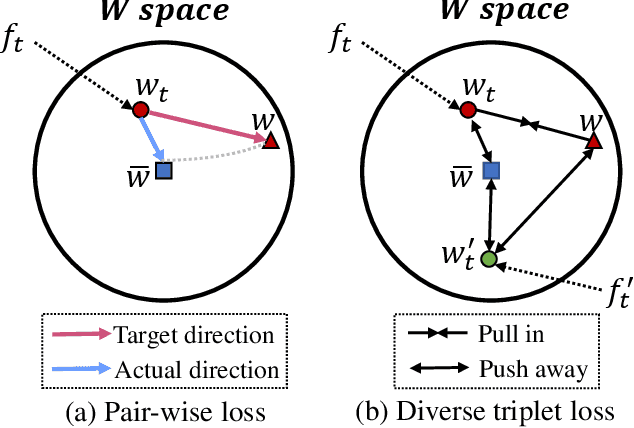
Existing text-to-image synthesis methods generally are only applicable to words in the training dataset. However, human faces are so variable to be described with limited words. So this paper proposes the first free-style text-to-face method namely AnyFace enabling much wider open world applications such as metaverse, social media, cosmetics, forensics, etc. AnyFace has a novel two-stream framework for face image synthesis and manipulation given arbitrary descriptions of the human face. Specifically, one stream performs text-to-face generation and the other conducts face image reconstruction. Facial text and image features are extracted using the CLIP (Contrastive Language-Image Pre-training) encoders. And a collaborative Cross Modal Distillation (CMD) module is designed to align the linguistic and visual features across these two streams. Furthermore, a Diverse Triplet Loss (DT loss) is developed to model fine-grained features and improve facial diversity. Extensive experiments on Multi-modal CelebA-HQ and CelebAText-HQ demonstrate significant advantages of AnyFace over state-of-the-art methods. AnyFace can achieve high-quality, high-resolution, and high-diversity face synthesis and manipulation results without any constraints on the number and content of input captions.
Learning Disentangled Representation for One-shot Progressive Face Swapping
Mar 24, 2022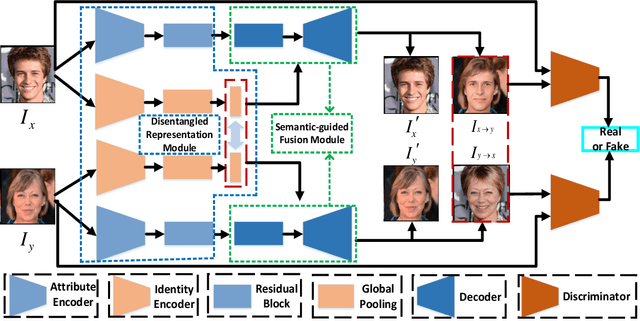
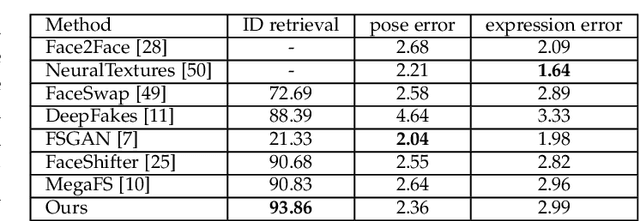
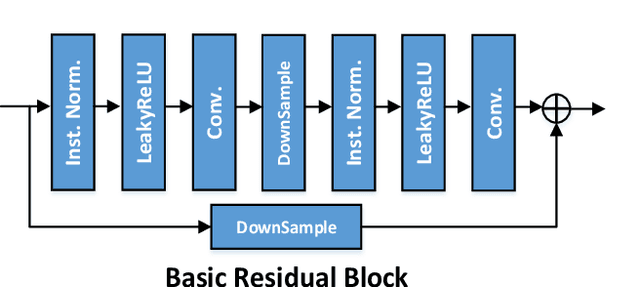
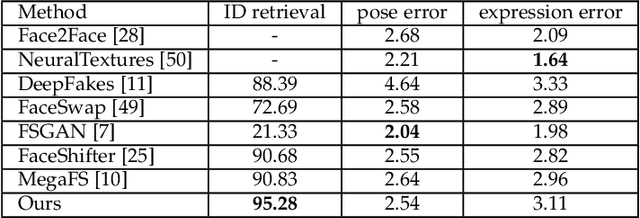
Although face swapping has attracted much attention in recent years, it remains a challenging problem. The existing methods leverage a large number of data samples to explore the intrinsic properties of face swapping without taking into account the semantic information of face images. Moreover, the representation of the identity information tends to be fixed, leading to suboptimal face swapping. In this paper, we present a simple yet efficient method named FaceSwapper, for one-shot face swapping based on Generative Adversarial Networks. Our method consists of a disentangled representation module and a semantic-guided fusion module. The disentangled representation module is composed of an attribute encoder and an identity encoder, which aims to achieve the disentanglement of the identity and the attribute information. The identity encoder is more flexible and the attribute encoder contains more details of the attributes than its competitors. Benefiting from the disentangled representation, FaceSwapper can swap face images progressively. In addition, semantic information is introduced into the semantic-guided fusion module to control the swapped area and model the pose and expression more accurately. The experimental results show that our method achieves state-of-the-art results on benchmark datasets with fewer training samples. Our code is publicly available at https://github.com/liqi-casia/FaceSwapper.
MOST-Net: A Memory Oriented Style Transfer Network for Face Sketch Synthesis
Feb 08, 2022
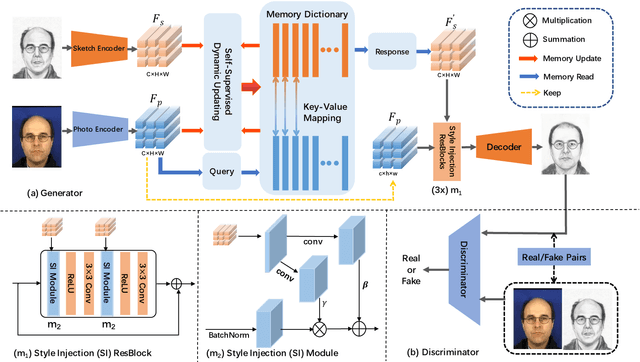
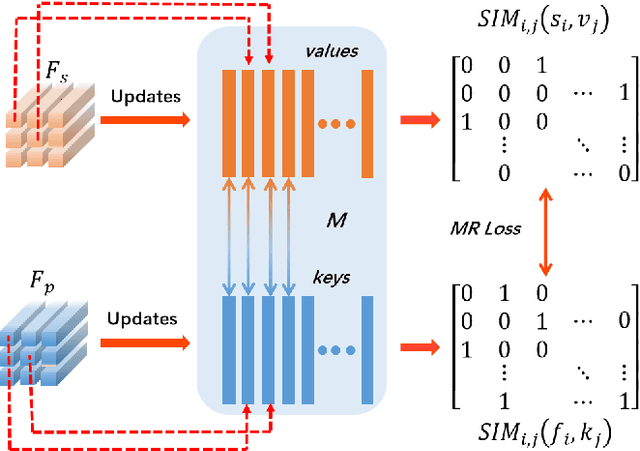
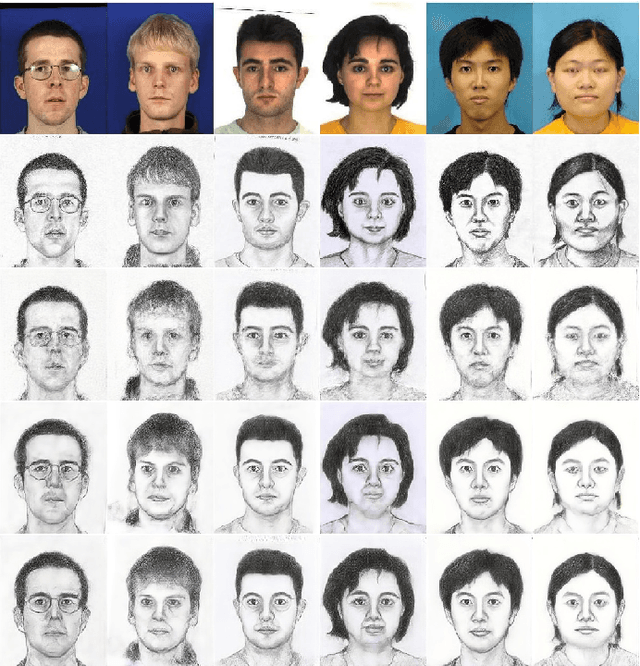
Face sketch synthesis has been widely used in multi-media entertainment and law enforcement. Despite the recent developments in deep neural networks, accurate and realistic face sketch synthesis is still a challenging task due to the diversity and complexity of human faces. Current image-to-image translation-based face sketch synthesis frequently encounters over-fitting problems when it comes to small-scale datasets. To tackle this problem, we present an end-to-end Memory Oriented Style Transfer Network (MOST-Net) for face sketch synthesis which can produce high-fidelity sketches with limited data. Specifically, an external self-supervised dynamic memory module is introduced to capture the domain alignment knowledge in the long term. In this way, our proposed model could obtain the domain-transfer ability by establishing the durable relationship between faces and corresponding sketches on the feature level. Furthermore, we design a novel Memory Refinement Loss (MR Loss) for feature alignment in the memory module, which enhances the accuracy of memory slots in an unsupervised manner. Extensive experiments on the CUFS and the CUFSF datasets show that our MOST-Net achieves state-of-the-art performance, especially in terms of the Structural Similarity Index(SSIM).
META: Mimicking Embedding via oThers' Aggregation for Generalizable Person Re-identification
Dec 16, 2021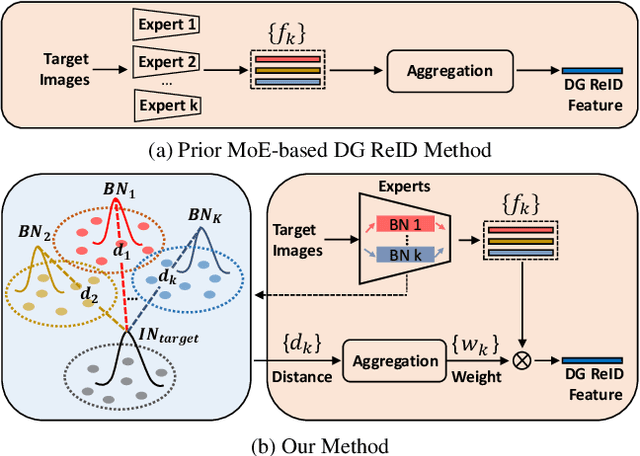
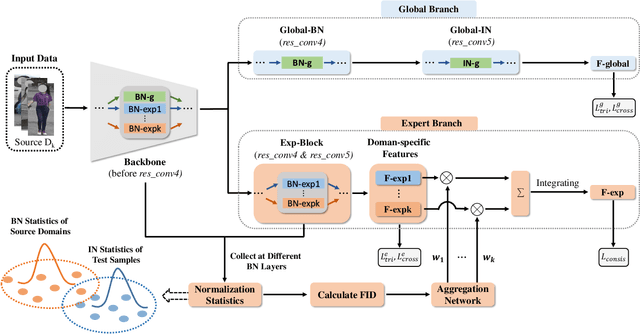
Domain generalizable (DG) person re-identification (ReID) aims to test across unseen domains without access to the target domain data at training time, which is a realistic but challenging problem. In contrast to methods assuming an identical model for different domains, Mixture of Experts (MoE) exploits multiple domain-specific networks for leveraging complementary information between domains, obtaining impressive results. However, prior MoE-based DG ReID methods suffer from a large model size with the increase of the number of source domains, and most of them overlook the exploitation of domain-invariant characteristics. To handle the two issues above, this paper presents a new approach called Mimicking Embedding via oThers' Aggregation (META) for DG ReID. To avoid the large model size, experts in META do not add a branch network for each source domain but share all the parameters except for the batch normalization layers. Besides multiple experts, META leverages Instance Normalization (IN) and introduces it into a global branch to pursue invariant features across domains. Meanwhile, META considers the relevance of an unseen target sample and source domains via normalization statistics and develops an aggregation network to adaptively integrate multiple experts for mimicking unseen target domain. Benefiting from a proposed consistency loss and an episodic training algorithm, we can expect META to mimic embedding for a truly unseen target domain. Extensive experiments verify that META surpasses state-of-the-art DG ReID methods by a large margin.
Toward Accurate and Reliable Iris Segmentation Using Uncertainty Learning
Oct 20, 2021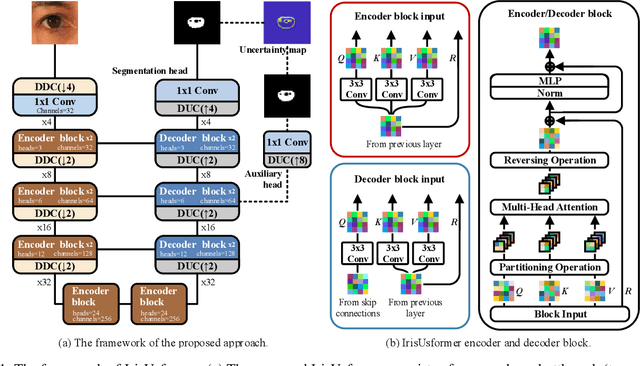
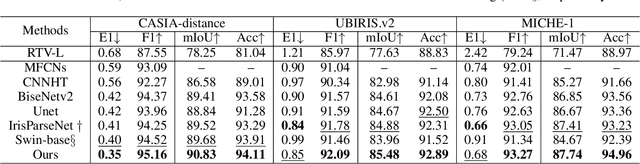
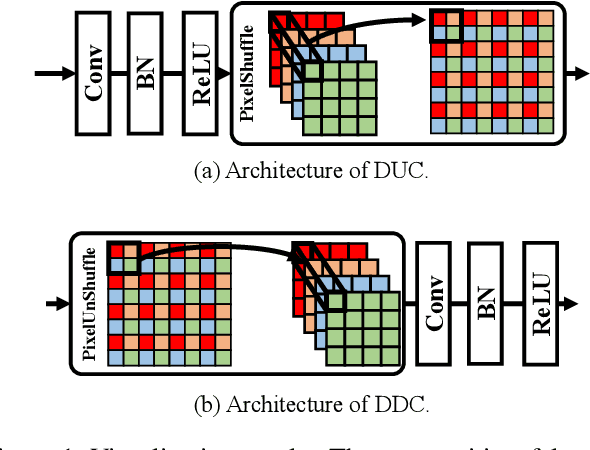
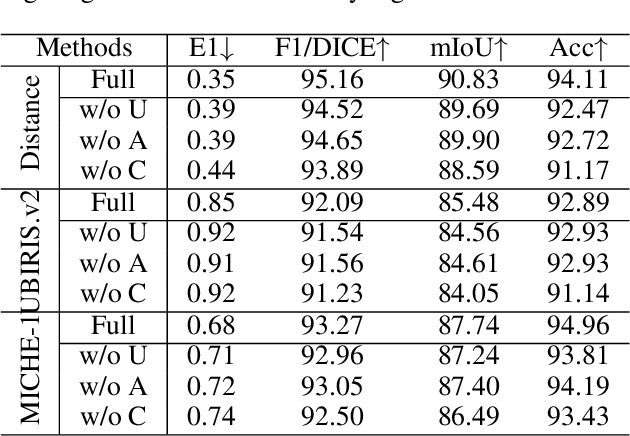
As an upstream task of iris recognition, iris segmentation plays a vital role in multiple subsequent tasks, including localization and matching. A slight bias in iris segmentation often results in obvious performance degradation of the iris recognition system. In the paper, we propose an Iris U-transformer (IrisUsformer) for accurate and reliable iris segmentation. For better accuracy, we elaborately design IrisUsformer by adopting position-sensitive operation and re-packaging transformer block to raise the spatial perception ability of the model. For better reliability, IrisUsformer utilizes an auxiliary head to distinguishes the high- and low-uncertainty regions of segmentation predictions and then adopts a weighting scheme to guide model optimization. Experimental results on three publicly available databases demonstrate that IrisUsformer achieves better segmentation accuracy using 35% MACs of the SOTA IrisParseNet. More importantly, our method estimates the uncertainty map corresponding to the segmentation prediction for subsequent processing in iris recognition systems.
A Unified Framework for Biphasic Facial Age Translation with Noisy-Semantic Guided Generative Adversarial Networks
Sep 15, 2021
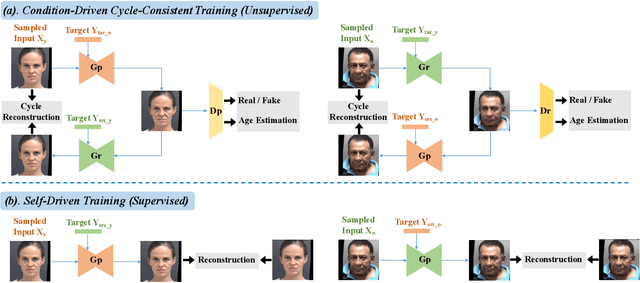
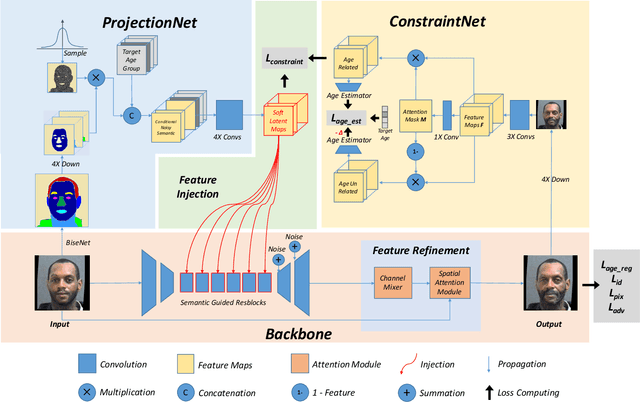

Biphasic facial age translation aims at predicting the appearance of the input face at any age. Facial age translation has received considerable research attention in the last decade due to its practical value in cross-age face recognition and various entertainment applications. However, most existing methods model age changes between holistic images, regardless of the human face structure and the age-changing patterns of individual facial components. Consequently, the lack of semantic supervision will cause infidelity of generated faces in detail. To this end, we propose a unified framework for biphasic facial age translation with noisy-semantic guided generative adversarial networks. Structurally, we project the class-aware noisy semantic layouts to soft latent maps for the following injection operation on the individual facial parts. In particular, we introduce two sub-networks, ProjectionNet and ConstraintNet. ProjectionNet introduces the low-level structural semantic information with noise map and produces soft latent maps. ConstraintNet disentangles the high-level spatial features to constrain the soft latent maps, which endows more age-related context into the soft latent maps. Specifically, attention mechanism is employed in ConstraintNet for feature disentanglement. Meanwhile, in order to mine the strongest mapping ability of the network, we embed two types of learning strategies in the training procedure, supervised self-driven generation and unsupervised condition-driven cycle-consistent generation. As a result, extensive experiments conducted on MORPH and CACD datasets demonstrate the prominent ability of our proposed method which achieves state-of-the-art performance.
An End-to-End Autofocus Camera for Iris on the Move
Jun 29, 2021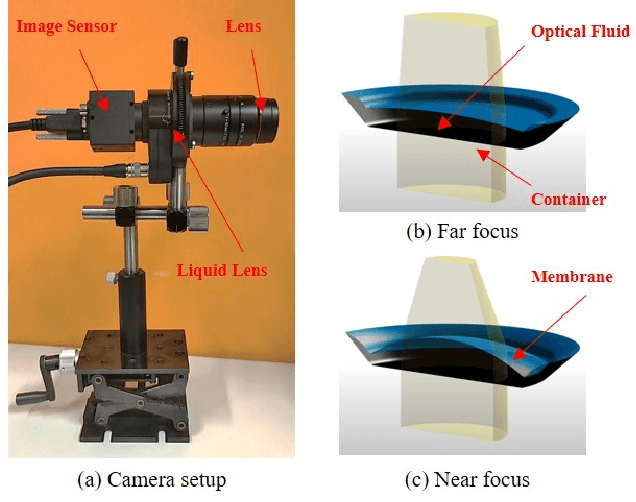

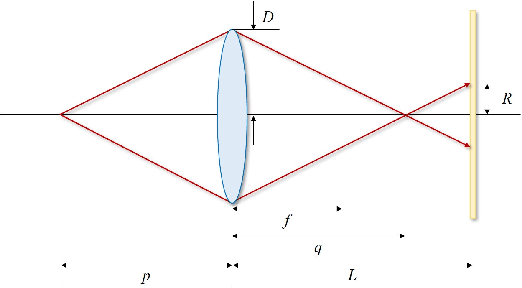
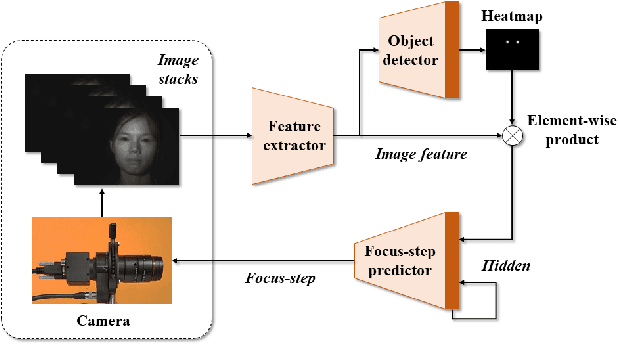
For distant iris recognition, a long focal length lens is generally used to ensure the resolution ofiris images, which reduces the depth of field and leads to potential defocus blur. To accommodate users at different distances, it is necessary to control focus quickly and accurately. While for users in motion, it is expected to maintain the correct focus on the iris area continuously. In this paper, we introduced a novel rapid autofocus camera for active refocusing ofthe iris area ofthe moving objects using a focus-tunable lens. Our end-to-end computational algorithm can predict the best focus position from one single blurred image and generate a lens diopter control signal automatically. This scene-based active manipulation method enables real-time focus tracking of the iris area ofa moving object. We built a testing bench to collect real-world focal stacks for evaluation of the autofocus methods. Our camera has reached an autofocus speed ofover 50 fps. The results demonstrate the advantages of our proposed camera for biometric perception in static and dynamic scenes. The code is available at https://github.com/Debatrix/AquulaCam.