 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at the Robustness of Vision-and-Language Pre-trained Models
Dec 15, 2020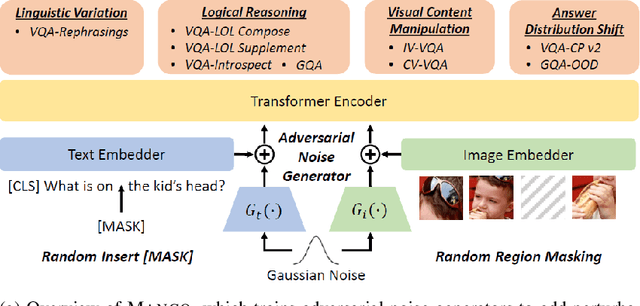
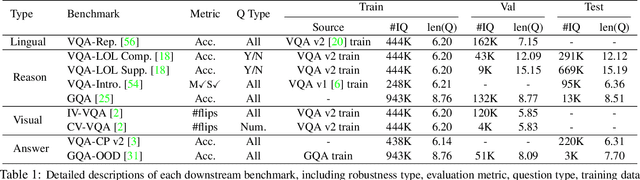
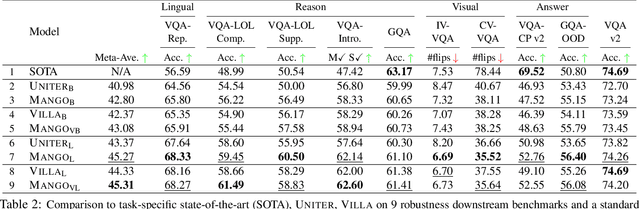

Large-scale pre-trained multimodal transformers, such as ViLBERT and UNITER, have propelled the state of the art in vision-and-language (V+L) research to a new level. Although achieving impressive performance on standard tasks, to date, it still remains unclear how robust these pre-trained models are. To investigate, we conduct a host of thorough evaluations on existing pre-trained models over 4 different types of V+L specific model robustness: (i) Linguistic Variation; (ii) Logical Reasoning; (iii) Visual Content Manipulation; and (iv) Answer Distribution Shift. Interestingly, by standard model finetuning, pre-trained V+L models already exhibit better robustness than many task-specific state-of-the-art methods. To further enhance model robustness, we propose Mango, a generic and efficient approach that learns a Multimodal Adversarial Noise GeneratOr in the embedding space to fool pre-trained V+L models. Differing from previous studies focused on one specific type of robustness, Mango is task-agnostic, and enables universal performance lift for pre-trained models over diverse tasks designed to evaluate broad aspects of robustness. Comprehensive experiments demonstrate that Mango achieves new state of the art on 7 out of 9 robustness benchmarks, surpassing existing methods by a significant margin. As the first comprehensive study on V+L robustness, this work puts robustness of pre-trained models into sharper focus, pointing new directions for future study.
InfoBERT: Improving Robustness of Language Models from An Information Theoretic Perspective
Oct 14, 2020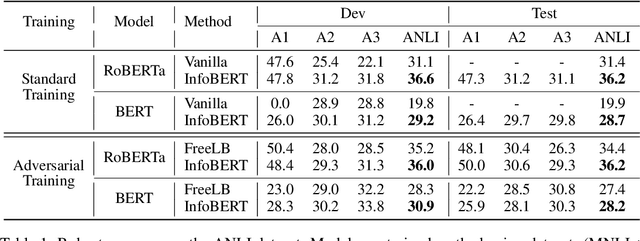
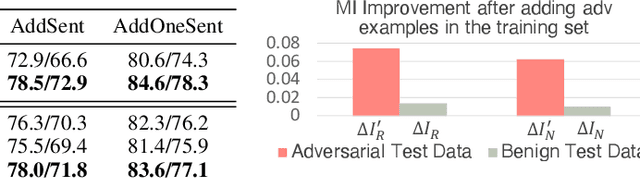
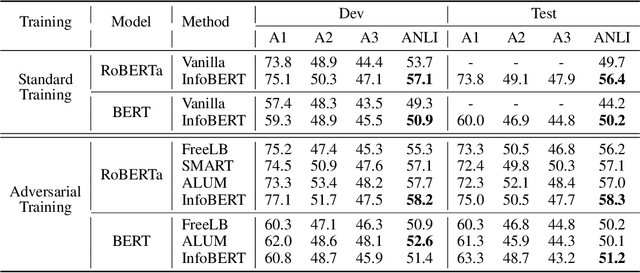
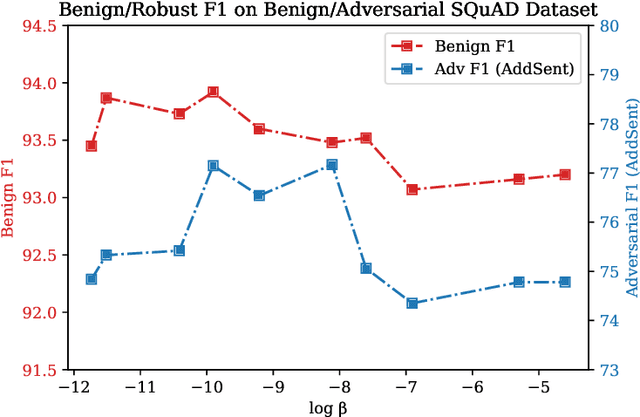
Large-scale language models such as BERT have achieved state-of-the-art performance across a wide range of NLP tasks. Recent studies, however, show that such BERT-based models are vulnerable facing the threats of textual adversarial attacks. We aim to address this problem from an information-theoretic perspective, and propose InfoBERT, a novel learning framework for robust fine-tuning of pre-trained language models. InfoBERT contains two mutual-information-based regularizers for model training: (i) an Information Bottleneck regularizer, which suppresses noisy mutual information between the input and the feature representation; and (ii) a Robust Feature regularizer, which increases the mutual information between local robust features and global features. We provide a principled way to theoretically analyze and improve the robustness of representation learning for language models in both standard and adversarial training. Extensive experiments demonstrate that InfoBERT achieves state-of-the-art robust accuracy over several adversarial datasets on Natural Language Inference (NLI) and Question Answering (QA) tasks.
Cross-Thought for Sentence Encoder Pre-training
Oct 07, 2020
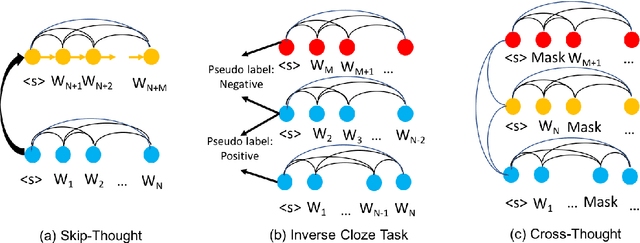
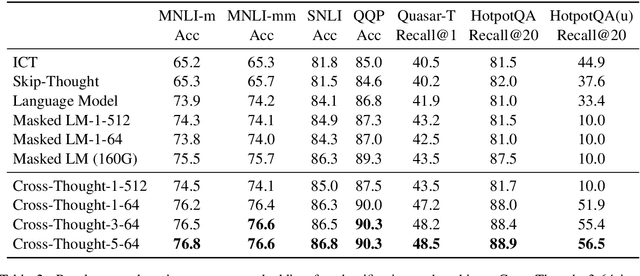
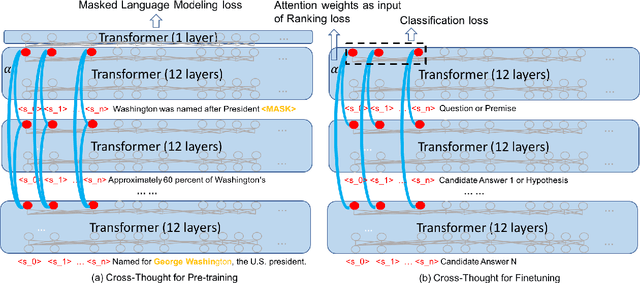
In this paper, we propose Cross-Thought, a novel approach to pre-training sequence encoder, which is instrumental in building reusable sequence embeddings for large-scale NLP tasks such as question answering. Instead of using the original signals of full sentences, we train a Transformer-based sequence encoder over a large set of short sequences, which allows the model to automatically select the most useful information for predicting masked words. Experiments on question answering and textual entailment tasks demonstrate that our pre-trained encoder can outperform state-of-the-art encoders trained with continuous sentence signals as well as traditional masked language modeling baselines. Our proposed approach also achieves new state of the art on HotpotQA (full-wiki setting) by improving intermediate information retrieval performance.
Multi-Fact Correction in Abstractive Text Summarization
Oct 06, 2020

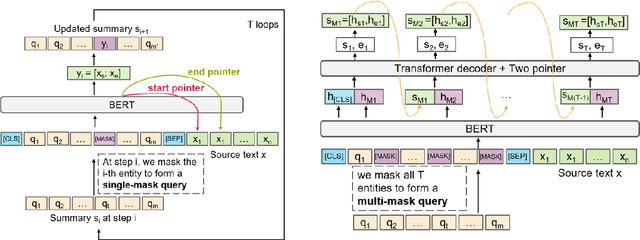
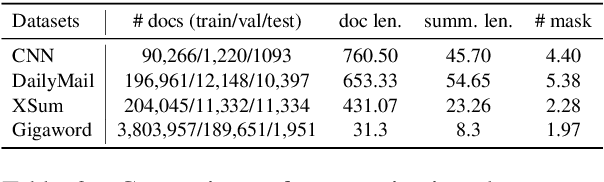
Pre-trained neural abstractive summarization systems have dominated extractive strategies on news summarization performance, at least in terms of ROUGE. However, system-generated abstractive summaries often face the pitfall of factual inconsistency: generating incorrect facts with respect to the source text. To address this challenge, we propose Span-Fact, a suite of two factual correction models that leverages knowledge learned from question answering models to make corrections in system-generated summaries via span selection. Our models employ single or multi-masking strategies to either iteratively or auto-regressively replace entities in order to ensure semantic consistency w.r.t. the source text, while retaining the syntactic structure of summaries generated by abstractive summarization models. Experiments show that our models significantly boost the factual consistency of system-generated summaries without sacrificing summary quality in terms of both automatic metrics and human evaluation.
MagGAN: High-Resolution Face Attribute Editing with Mask-Guided Generative Adversarial Network
Oct 03, 2020
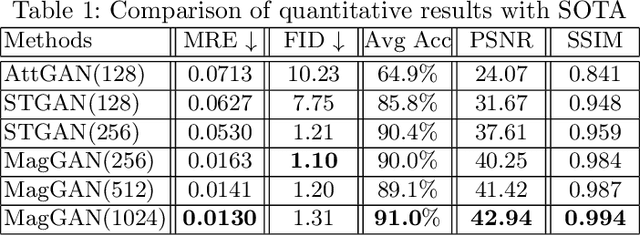

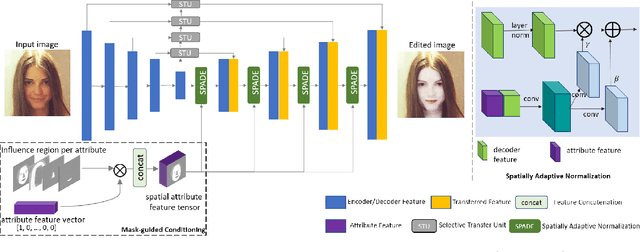
We present Mask-guided Generative Adversarial Network (MagGAN) for high-resolution face attribute editing, in which semantic facial masks from a pre-trained face parser are used to guide the fine-grained image editing process. With the introduction of a mask-guided reconstruction loss, MagGAN learns to only edit the facial parts that are relevant to the desired attribute changes, while preserving the attribute-irrelevant regions (e.g., hat, scarf for modification `To Bald'). Further, a novel mask-guided conditioning strategy is introduced to incorporate the influence region of each attribute change into the generator. In addition, a multi-level patch-wise discriminator structure is proposed to scale our model for high-resolution ($1024 \times 1024$) face editing. Experiments on the CelebA benchmark show that the proposed method significantly outperforms prior state-of-the-art approaches in terms of both image quality and editing performance.
Efficient Robust Training via Backward Smoothing
Oct 03, 2020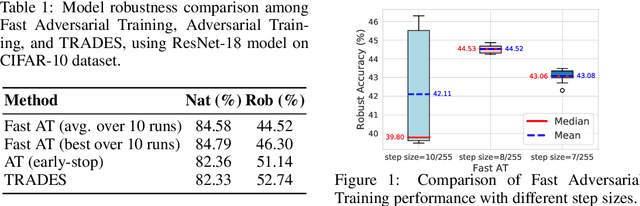
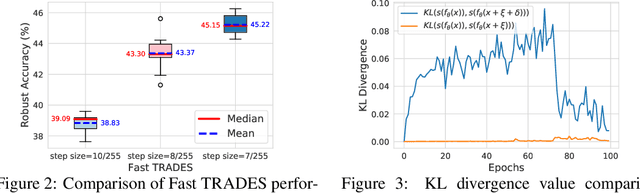

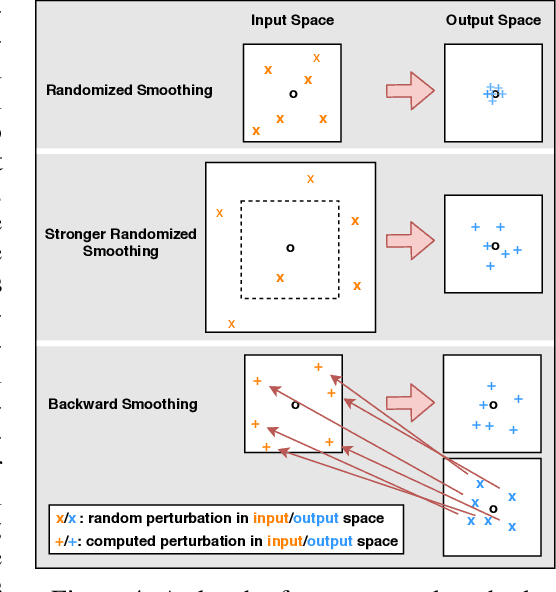
Adversarial training is so far the most effective strategy in defending against adversarial examples. However, it suffers from high computational cost due to the iterative adversarial attacks in each training step. Recent studies show that it is possible to achieve Fast Adversarial Training by performing a single-step attack with random initialization. Yet, it remains a mystery why random initialization helps. Besides, such an approach still lags behind state-of-the-art adversarial training algorithms on both stability and model robustness. In this work, we develop a new understanding towards Fast Adversarial Training, by viewing random initialization as performing randomized smoothing for better optimization of the inner maximization problem. From this perspective, we show that the smoothing effect by random initialization is not sufficient under the adversarial perturbation constraint. A new initialization strategy, backward smoothing, is proposed to address this issue and significantly improves both stability and model robustness over single-step robust training methods.Experiments on multiple benchmarks demonstrate that our method achieves similar model robustness as the original TRADES method, while using much less training time ($\sim$3x improvement with the same training schedule).
Contrastive Distillation on Intermediate Representations for Language Model Compression
Sep 29, 2020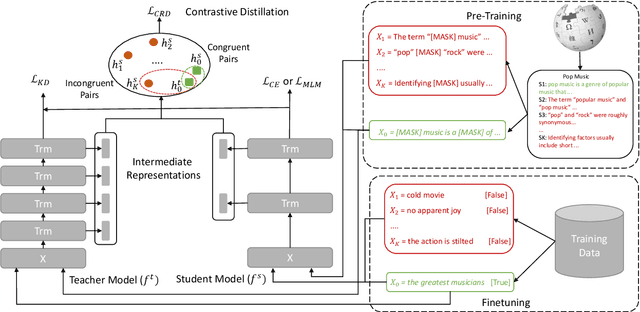
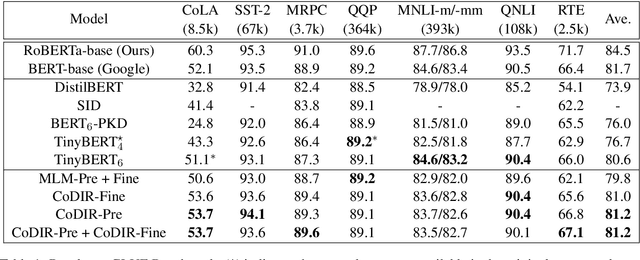
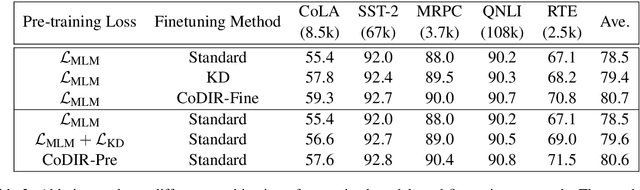

Existing language model compression methods mostly use a simple L2 loss to distill knowledge in the intermediate representations of a large BERT model to a smaller one. Although widely used, this objective by design assumes that all the dimensions of hidden representations are independent, failing to capture important structural knowledge in the intermediate layers of the teacher network. To achieve better distillation efficacy, we propose Contrastive Distillation on Intermediate Representations (CoDIR), a principled knowledge distillation framework where the student is trained to distill knowledge through intermediate layers of the teacher via a contrastive objective. By learning to distinguish positive sample from a large set of negative samples, CoDIR facilitates the student's exploitation of rich information in teacher's hidden layers. CoDIR can be readily applied to compress large-scale language models in both pre-training and finetuning stages, and achieves superb performance on the GLUE benchmark, outperforming state-of-the-art compression methods.
FILTER: An Enhanced Fusion Method for Cross-lingual Language Understanding
Sep 17, 2020
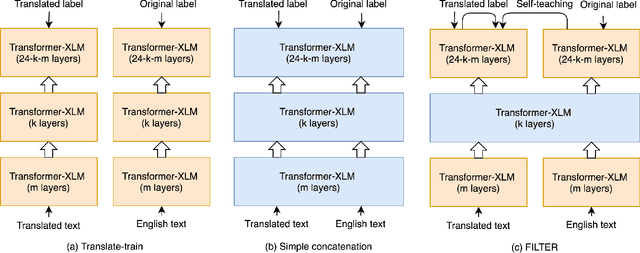
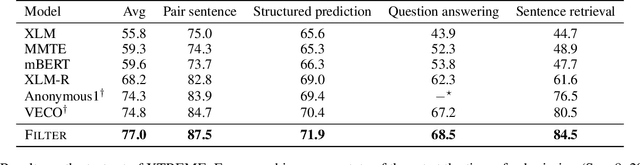
Large-scale cross-lingual language models (LM), such as mBERT, Unicoder and XLM, have achieved great success in cross-lingual representation learning. However, when applied to zero-shot cross-lingual transfer tasks, most existing methods use only single-language input for LM finetuning, without leveraging the intrinsic cross-lingual alignment between different languages that is essential for multilingual tasks. In this paper, we propose FILTER, an enhanced fusion method that takes cross-lingual data as input for XLM finetuning. Specifically, FILTER first encodes text input in the source language and its translation in the target language independently in the shallow layers, then performs cross-lingual fusion to extract multilingual knowledge in the intermediate layers, and finally performs further language-specific encoding. During inference, the model makes predictions based on the text input in the target language and its translation in the source language. For simple tasks such as classification, translated text in the target language shares the same label as the source language. However, this shared label becomes less accurate or even unavailable for more complex tasks such as question answering, NER and POS tagging. For better model scalability, we further propose an additional KL-divergence self-teaching loss for model training, based on auto-generated soft pseudo-labels for translated text in the target language. Extensive experiments demonstrate that FILTER achieves new state of the art on two challenging multilingual multi-task benchmarks, XTREME and XGLUE.
Cluster-Former: Clustering-based Sparse Transformer for Long-Range Dependency Encoding
Sep 13, 2020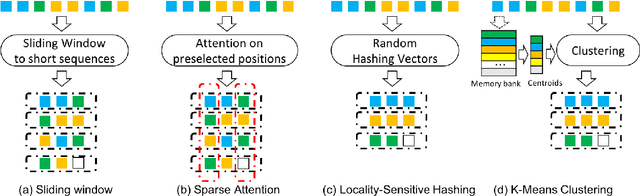
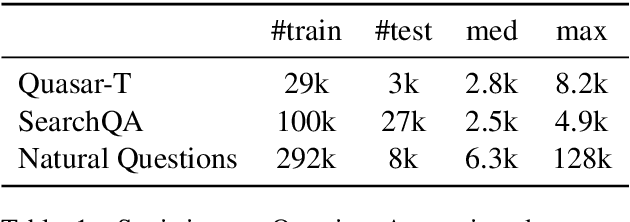
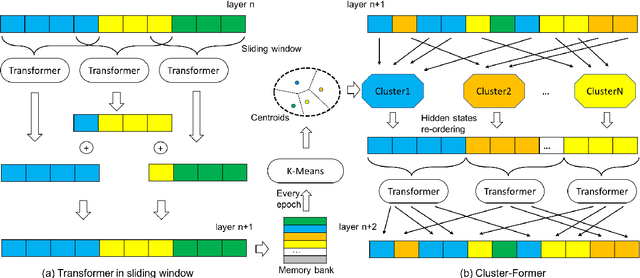
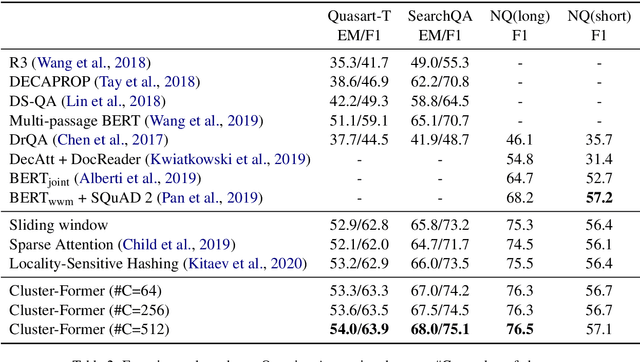
Transformer has become ubiquitous in the deep learning field. One of the key ingredients that destined its success is the self-attention mechanism, which allows fully-connected contextual encoding over input tokens. However, despite its effectiveness in modeling short sequences, self-attention suffers when handling inputs with extreme long-range dependencies, as its complexity grows quadratically with respect to the sequence length. Therefore, long sequences are often encoded by Transformer in chunks using a sliding window. In this paper, we propose Cluster-Former, a novel clustering-based sparse Transformer to perform attention across chunked sequences. Our proposed method allows information integration beyond local windows, which is especially beneficial for question answering (QA) and language modeling tasks that rely on long-range dependencies. Experiments show that Cluster-Former achieves state-of-the-art performance on several major QA benchmarks.
Accelerating Real-Time Question Answering via Question Generation
Sep 10, 2020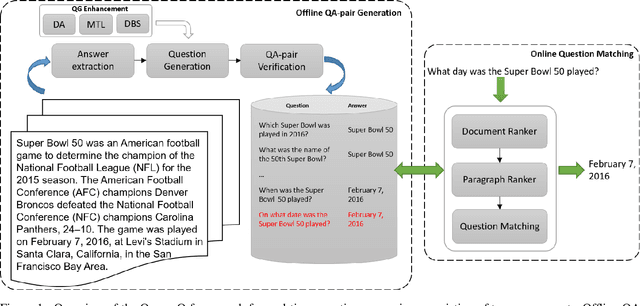
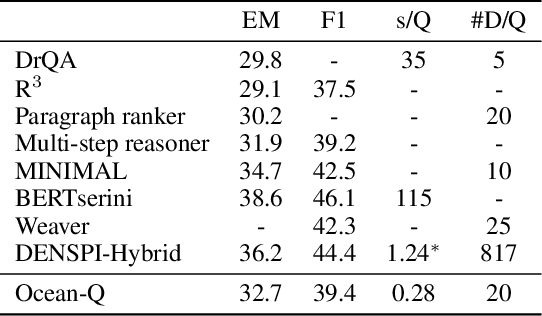
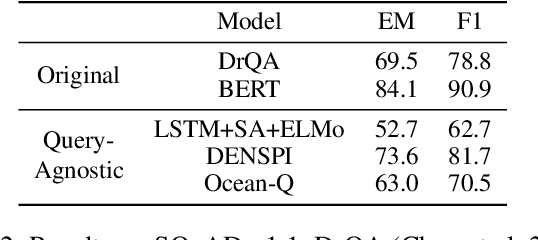
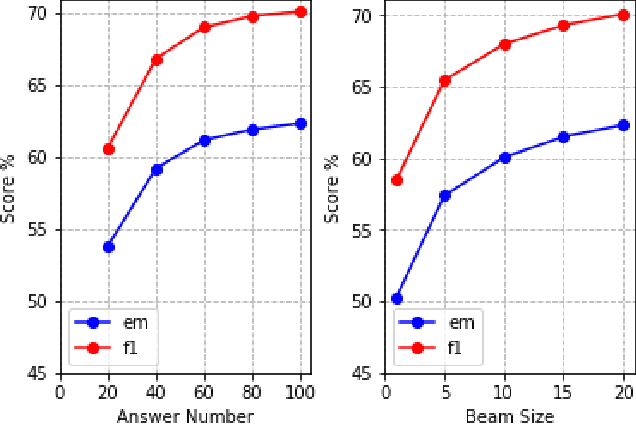
Existing approaches to real-time question answering (RTQA) rely on learning the representations of only key phrases in the documents, then matching them with the question representation to derive answer. However, such approach is bottlenecked by the encoding time of real-time questions, thus suffering from detectable latency in deployment for large-volume traffic. To accelerate RTQA for practical use, we present Ocean-Q (an Ocean of Questions), a novel approach that leverages question generation (QG) for RTQA. Ocean-Q introduces a QG model to generate a large pool of question-answer (QA) pairs offline, then in real time matches an input question with the candidate QA pool to predict the answer without question encoding. To further improve QG quality, we propose a new data augmentation method and leverage multi-task learning and diverse beam search to boost RTQA performance. Experiments on SQuAD(-open) and HotpotQA benchmarks demonstrate that Ocean-Q is able to accelerate the fastest state-of-the-art RTQA system by 4X times, with only a 3+% accuracy drop.