 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Bottleneck for Robust Self-Supervised Exploration
Oct 25, 2021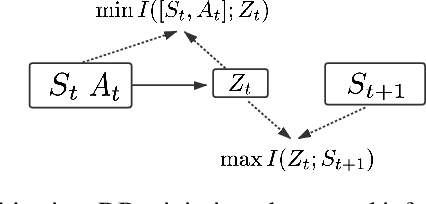
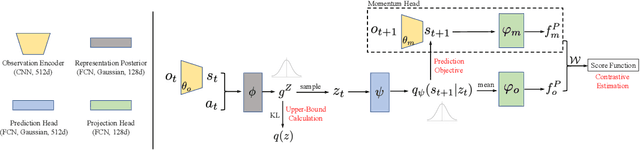

Exploration methods based on pseudo-count of transitions or curiosity of dynamics have achieved promising results in solving reinforcement learning with sparse rewards. However, such methods are usually sensitive to environmental dynamics-irrelevant information, e.g., white-noise. To handle such dynamics-irrelevant information, we propose a Dynamic Bottleneck (DB) model, which attains a dynamics-relevant representation based on the information-bottleneck principle. Based on the DB model, we further propose DB-bonus, which encourages the agent to explore state-action pairs with high information gain. We establish theoretical connections between the proposed DB-bonus, the upper confidence bound (UCB) for linear case, and the visiting count for tabular case. We evaluate the proposed method on Atari suits with dynamics-irrelevant noises. Our experiments show that exploration with DB bonus outperforms several state-of-the-art exploration methods in noisy environments.
SCORE: Spurious COrrelation REduction for Offline Reinforcement Learning
Oct 24, 2021
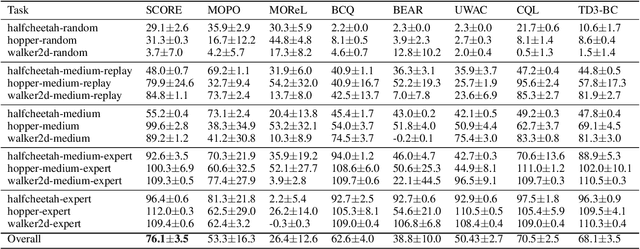
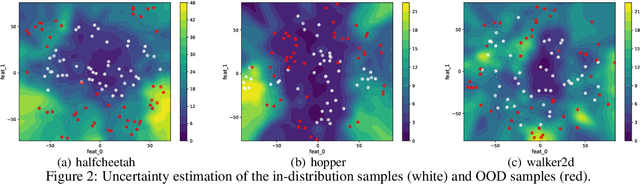

Offline reinforcement learning (RL) aims to learn the optimal policy from a pre-collected dataset without online interactions. Most of the existing studies focus on distributional shift caused by out-of-distribution actions. However, even in-distribution actions can raise serious problems. Since the dataset only contains limited information about the underlying model, offline RL is vulnerable to spurious correlations, i.e., the agent tends to prefer actions that by chance lead to high returns, resulting in a highly suboptimal policy. To address such a challenge, we propose a practical and theoretically guaranteed algorithm SCORE that reduces spurious correlations by combing an uncertainty penalty into policy evaluation. We show that this is consistent with the pessimism principle studied in theory, and the proposed algorithm converges to the optimal policy with a sublinear rate under mild assumptions. By conducting extensive experiments on existing benchmarks, we show that SCORE not only benefits from a solid theory but also obtains strong empirical results on a variety of tasks.
On Reward-Free RL with Kernel and Neural Function Approximations: Single-Agent MDP and Markov Game
Oct 19, 2021To achieve sample efficiency in reinforcement learning (RL), it necessitates efficiently exploring the underlying environment. Under the offline setting, addressing the exploration challenge lies in collecting an offline dataset with sufficient coverage. Motivated by such a challenge, we study the reward-free RL problem, where an agent aims to thoroughly explore the environment without any pre-specified reward function. Then, given any extrinsic reward, the agent computes the policy via a planning algorithm with offline data collected in the exploration phase. Moreover, we tackle this problem under the context of function approximation, leveraging powerful function approximators. Specifically, we propose to explore via an optimistic variant of the value-iteration algorithm incorporating kernel and neural function approximations, where we adopt the associated exploration bonus as the exploration reward. Moreover, we design exploration and planning algorithms for both single-agent MDPs and zero-sum Markov games and prove that our methods can achieve $\widetilde{\mathcal{O}}(1 /\varepsilon^2)$ sample complexity for generating a $\varepsilon$-suboptimal policy or $\varepsilon$-approximate Nash equilibrium when given an arbitrary extrinsic reward. To the best of our knowledge, we establish the first provably efficient reward-free RL algorithm with kernel and neural function approximators.
Inducing Equilibria via Incentives: Simultaneous Design-and-Play Finds Global Optima
Oct 12, 2021
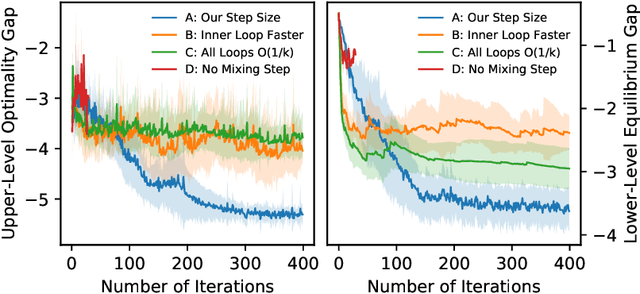
To regulate a social system comprised of self-interested agents, economic incentives (e.g., taxes, tolls, and subsidies) are often required to induce a desirable outcome. This incentive design problem naturally possesses a bi-level structure, in which an upper-level "designer" modifies the payoffs of the agents with incentives while anticipating the response of the agents at the lower level, who play a non-cooperative game that converges to an equilibrium. The existing bi-level optimization algorithms developed in machine learning raise a dilemma when applied to this problem: anticipating how incentives affect the agents at equilibrium requires solving the equilibrium problem repeatedly, which is computationally inefficient; bypassing the time-consuming step of equilibrium-finding can reduce the computational cost, but may lead the designer to a sub-optimal solution. To address such a dilemma, we propose a method that tackles the designer's and agents' problems simultaneously in a single loop. In particular, at each iteration, both the designer and the agents only move one step based on the first-order information. In the proposed scheme, although the designer does not solve the equilibrium problem repeatedly, it can anticipate the overall influence of the incentives on the agents, which guarantees optimality. We prove that the algorithm converges to the global optima at a sublinear rate for a broad class of games.
Provably Efficient Generative Adversarial Imitation Learning for Online and Offline Setting with Linear Function Approximation
Aug 19, 2021In generative adversarial imitation learning (GAIL), the agent aims to learn a policy from an expert demonstration so that its performance cannot be discriminated from the expert policy on a certain predefined reward set. In this paper, we study GAIL in both online and offline settings with linear function approximation, where both the transition and reward function are linear in the feature maps. Besides the expert demonstration, in the online setting the agent can interact with the environment, while in the offline setting the agent only accesses an additional dataset collected by a prior. For online GAIL, we propose an optimistic generative adversarial policy optimization algorithm (OGAP) and prove that OGAP achieves $\widetilde{\mathcal{O}}(H^2 d^{3/2}K^{1/2}+KH^{3/2}dN_1^{-1/2})$ regret. Here $N_1$ represents the number of trajectories of the expert demonstration, $d$ is the feature dimension, and $K$ is the number of episodes. For offline GAIL, we propose a pessimistic generative adversarial policy optimization algorithm (PGAP). For an arbitrary additional dataset, we obtain the optimality gap of PGAP, achieving the minimax lower bound in the utilization of the additional dataset. Assuming sufficient coverage on the additional dataset, we show that PGAP achieves $\widetilde{\mathcal{O}}(H^{2}dK^{-1/2} +H^2d^{3/2}N_2^{-1/2}+H^{3/2}dN_1^{-1/2} \ )$ optimality gap. Here $N_2$ represents the number of trajectories of the additional dataset with sufficient coverage.
Online Bootstrap Inference For Policy Evaluation in Reinforcement Learning
Aug 08, 2021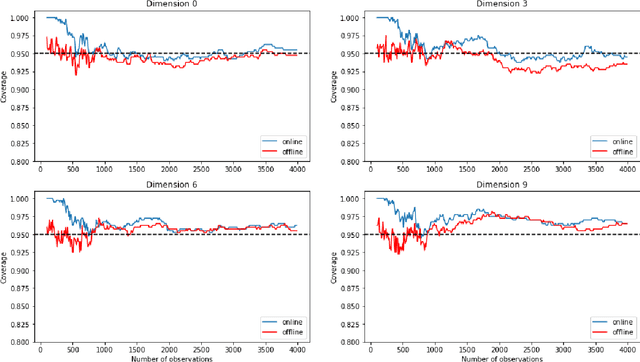
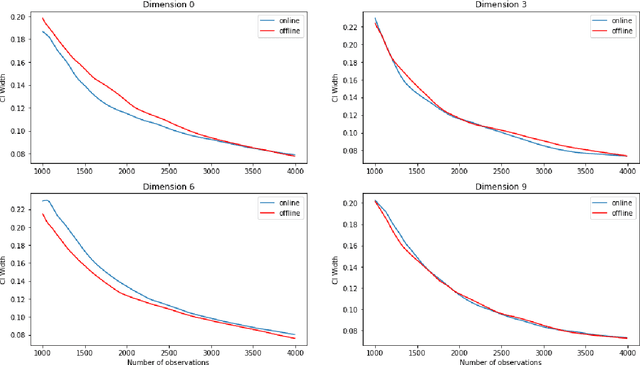
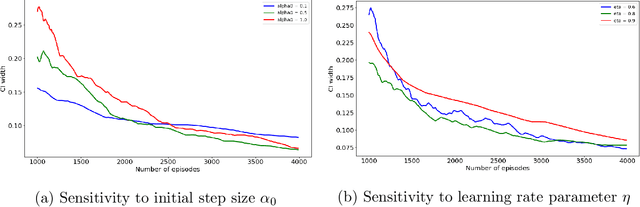
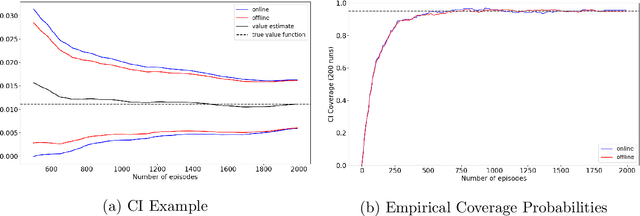
The recent emergence of reinforcement learning has created a demand for robust statistical inference methods for the parameter estimates computed using these algorithms. Existing methods for statistical inference in online learning are restricted to settings involving independently sampled observations, while existing statistical inference methods in reinforcement learning (RL) are limited to the batch setting. The online bootstrap is a flexible and efficient approach for statistical inference in linear stochastic approximation algorithms, but its efficacy in settings involving Markov noise, such as RL, has yet to be explored. In this paper, we study the use of the online bootstrap method for statistical inference in RL. In particular, we focus on the temporal difference (TD) learning and Gradient TD (GTD) learning algorithms, which are themselves special instances of linear stochastic approximation under Markov noise. The method is shown to be distributionally consistent for statistical inference in policy evaluation, and numerical experiments are included to demonstrate the effectiveness of this algorithm at statistical inference tasks across a range of real RL environments.
Towards General Function Approximation in Zero-Sum Markov Games
Jul 30, 2021This paper considers two-player zero-sum finite-horizon Markov games with simultaneous moves. The study focuses on the challenging settings where the value function or the model is parameterized by general function classes. Provably efficient algorithms for both decoupled and {coordinated} settings are developed. In the {decoupled} setting where the agent controls a single player and plays against an arbitrary opponent, we propose a new model-free algorithm. The sample complexity is governed by the Minimax Eluder dimension -- a new dimension of the function class in Markov games. As a special case, this method improves the state-of-the-art algorithm by a $\sqrt{d}$ factor in the regret when the reward function and transition kernel are parameterized with $d$-dimensional linear features. In the {coordinated} setting where both players are controlled by the agent, we propose a model-based algorithm and a model-free algorithm. In the model-based algorithm, we prove that sample complexity can be bounded by a generalization of Witness rank to Markov games. The model-free algorithm enjoys a $\sqrt{K}$-regret upper bound where $K$ is the number of episodes. Our algorithms are based on new techniques of alternate optimism.
A Unified Off-Policy Evaluation Approach for General Value Function
Jul 06, 2021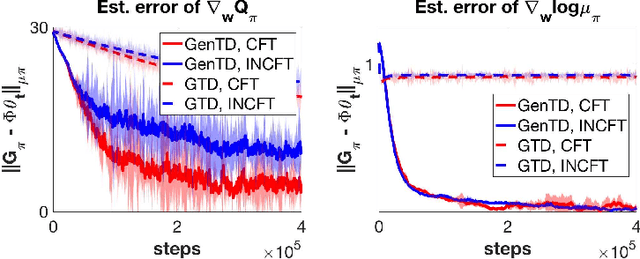
General Value Function (GVF) is a powerful tool to represent both the {\em predictive} and {\em retrospective} knowledge in reinforcement learning (RL). In practice, often multiple interrelated GVFs need to be evaluated jointly with pre-collected off-policy samples. In the literature, the gradient temporal difference (GTD) learning method has been adopted to evaluate GVFs in the off-policy setting, but such an approach may suffer from a large estimation error even if the function approximation class is sufficiently expressive. Moreover, none of the previous work have formally established the convergence guarantee to the ground truth GVFs under the function approximation settings. In this paper, we address both issues through the lens of a class of GVFs with causal filtering, which cover a wide range of RL applications such as reward variance, value gradient, cost in anomaly detection, stationary distribution gradient, etc. We propose a new algorithm called GenTD for off-policy GVFs evaluation and show that GenTD learns multiple interrelated multi-dimensional GVFs as efficiently as a single canonical scalar value function. We further show that unlike GTD, the learned GVFs by GenTD are guaranteed to converge to the ground truth GVFs as long as the function approximation power is sufficiently large. To our best knowledge, GenTD is the first off-policy GVF evaluation algorithm that has global optimality guarantee.
Gap-Dependent Bounds for Two-Player Markov Games
Jul 01, 2021As one of the most popular methods in the field of reinforcement learning, Q-learning has received increasing attention. Recently, there have been more theoretical works on the regret bound of algorithms that belong to the Q-learning class in different settings. In this paper, we analyze the cumulative regret when conducting Nash Q-learning algorithm on 2-player turn-based stochastic Markov games (2-TBSG), and propose the very first gap dependent logarithmic upper bounds in the episodic tabular setting. This bound matches the theoretical lower bound only up to a logarithmic term. Furthermore, we extend the conclusion to the discounted game setting with infinite horizon and propose a similar gap dependent logarithmic regret bound. Also, under the linear MDP assumption, we obtain another logarithmic regret for 2-TBSG, in both centralized and independent settings.
Randomized Exploration for Reinforcement Learning with General Value Function Approximation
Jun 15, 2021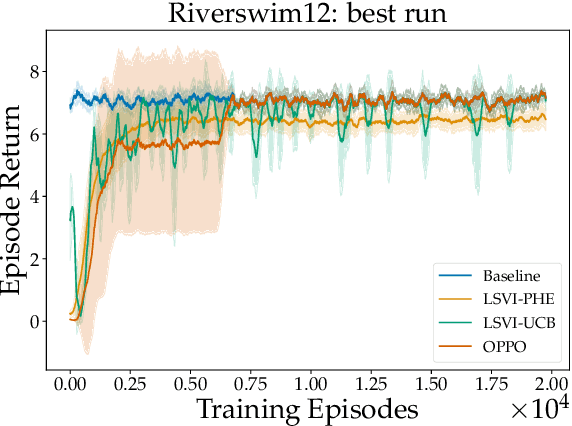
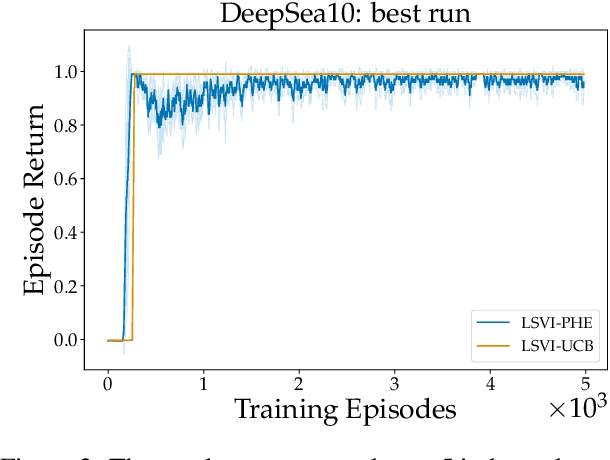
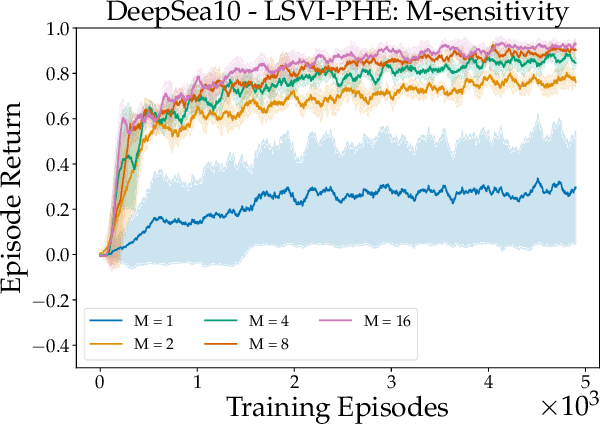
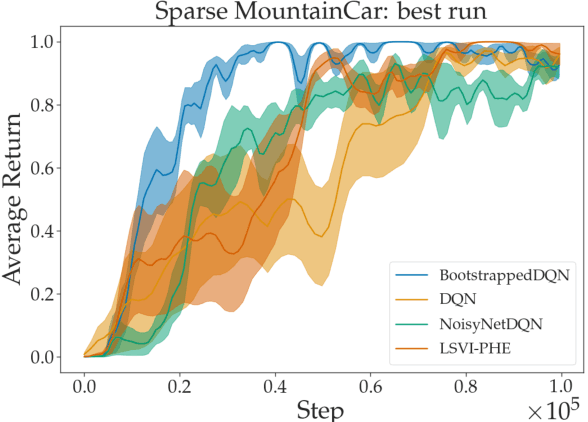
We propose a model-free reinforcement learning algorithm inspired by the popular randomized least squares value iteration (RLSVI) algorithm as well as the optimism principle. Unlike existing upper-confidence-bound (UCB) based approaches, which are often computationally intractable, our algorithm drives exploration by simply perturbing the training data with judiciously chosen i.i.d. scalar noises. To attain optimistic value function estimation without resorting to a UCB-style bonus, we introduce an optimistic reward sampling procedure. When the value functions can be represented by a function class $\mathcal{F}$, our algorithm achieves a worst-case regret bound of $\widetilde{O}(\mathrm{poly}(d_EH)\sqrt{T})$ where $T$ is the time elapsed, $H$ is the planning horizon and $d_E$ is the $\textit{eluder dimension}$ of $\mathcal{F}$. In the linear setting, our algorithm reduces to LSVI-PHE, a variant of RLSVI, that enjoys an $\widetilde{\mathcal{O}}(\sqrt{d^3H^3T})$ regret. We complement the theory with an empirical evaluation across known difficult exploration tasks.