 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePermutation Invariant Policy Optimization for Mean-Field Multi-Agent Reinforcement Learning: A Principled Approach
May 18, 2021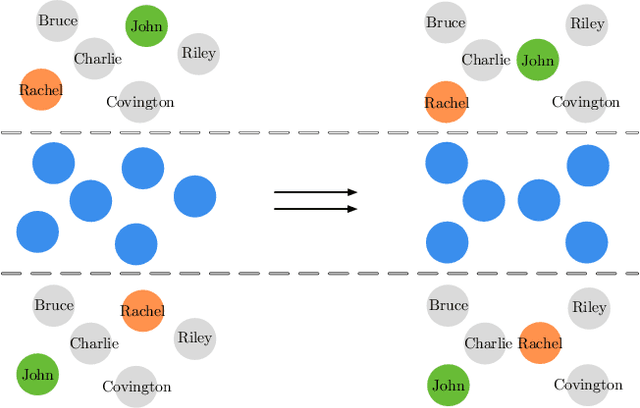
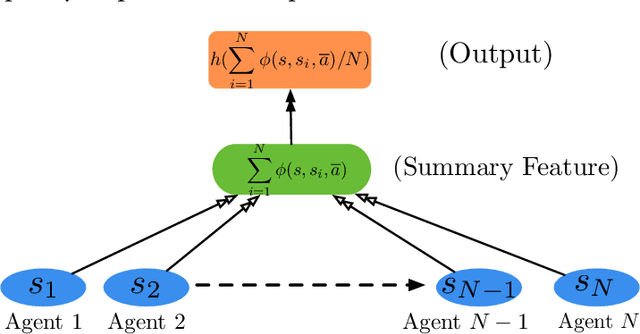
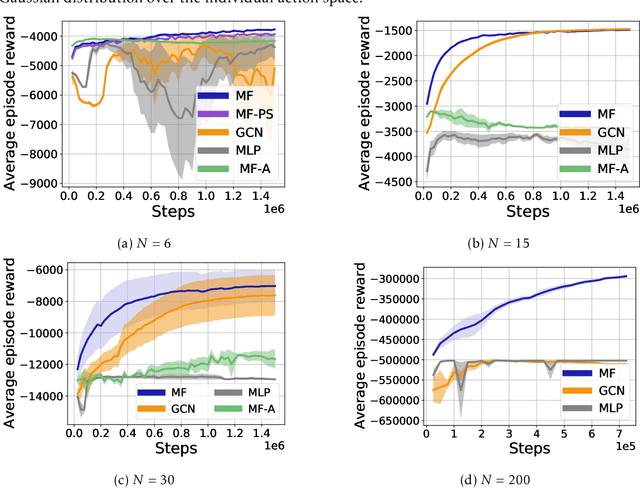
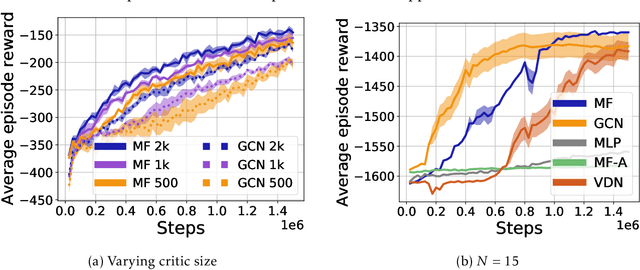
Multi-agent reinforcement learning (MARL) becomes more challenging in the presence of more agents, as the capacity of the joint state and action spaces grows exponentially in the number of agents. To address such a challenge of scale, we identify a class of cooperative MARL problems with permutation invariance, and formulate it as a mean-field Markov decision processes (MDP). To exploit the permutation invariance therein, we propose the mean-field proximal policy optimization (MF-PPO) algorithm, at the core of which is a permutation-invariant actor-critic neural architecture. We prove that MF-PPO attains the globally optimal policy at a sublinear rate of convergence. Moreover, its sample complexity is independent of the number of agents. We validate the theoretical advantages of MF-PPO with numerical experiments in the multi-agent particle environment (MPE). In particular, we show that the inductive bias introduced by the permutation-invariant neural architecture enables MF-PPO to outperform existing competitors with a smaller number of model parameters, which is the key to its generalization performance.
Principled Exploration via Optimistic Bootstrapping and Backward Induction
May 17, 2021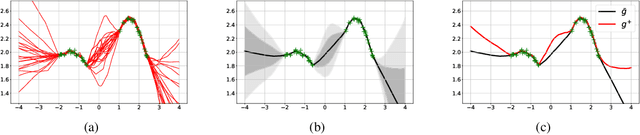

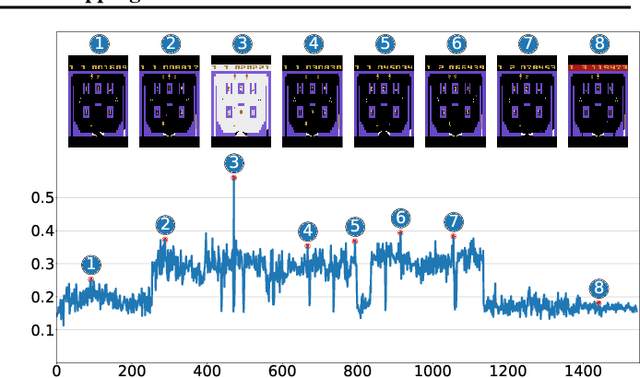
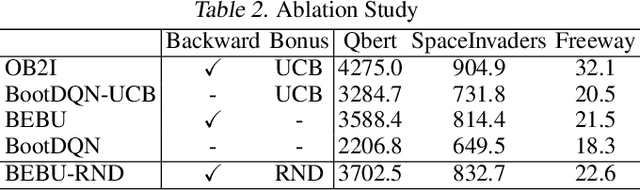
One principled approach for provably efficient exploration is incorporating the upper confidence bound (UCB) into the value function as a bonus. However, UCB is specified to deal with linear and tabular settings and is incompatible with Deep Reinforcement Learning (DRL). In this paper, we propose a principled exploration method for DRL through Optimistic Bootstrapping and Backward Induction (OB2I). OB2I constructs a general-purpose UCB-bonus through non-parametric bootstrap in DRL. The UCB-bonus estimates the epistemic uncertainty of state-action pairs for optimistic exploration. We build theoretical connections between the proposed UCB-bonus and the LSVI-UCB in a linear setting. We propagate future uncertainty in a time-consistent manner through episodic backward update, which exploits the theoretical advantage and empirically improves the sample-efficiency. Our experiments in the MNIST maze and Atari suite suggest that OB2I outperforms several state-of-the-art exploration approaches.
Doubly Robust Off-Policy Actor-Critic: Convergence and Optimality
Feb 27, 2021
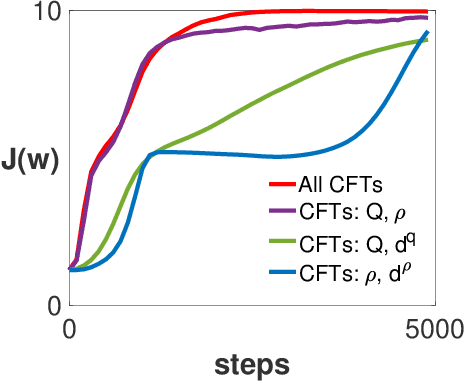
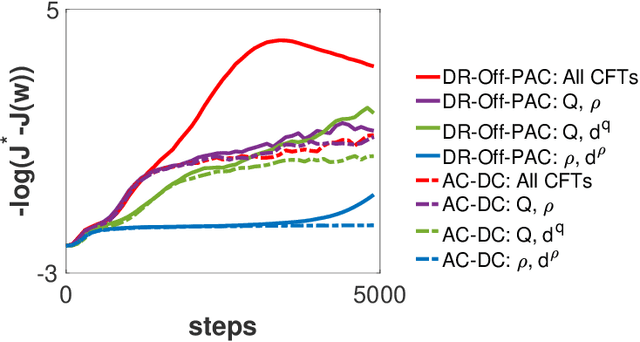
Designing off-policy reinforcement learning algorithms is typically a very challenging task, because a desirable iteration update often involves an expectation over an on-policy distribution. Prior off-policy actor-critic (AC) algorithms have introduced a new critic that uses the density ratio for adjusting the distribution mismatch in order to stabilize the convergence, but at the cost of potentially introducing high biases due to the estimation errors of both the density ratio and value function. In this paper, we develop a doubly robust off-policy AC (DR-Off-PAC) for discounted MDP, which can take advantage of learned nuisance functions to reduce estimation errors. Moreover, DR-Off-PAC adopts a single timescale structure, in which both actor and critics are updated simultaneously with constant stepsize, and is thus more sample efficient than prior algorithms that adopt either two timescale or nested-loop structure. We study the finite-time convergence rate and characterize the sample complexity for DR-Off-PAC to attain an $\epsilon$-accurate optimal policy. We also show that the overall convergence of DR-Off-PAC is doubly robust to the approximation errors that depend only on the expressive power of approximation functions. To the best of our knowledge, our study establishes the first overall sample complexity analysis for a single time-scale off-policy AC algorithm.
Instrumental Variable Value Iteration for Causal Offline Reinforcement Learning
Feb 19, 2021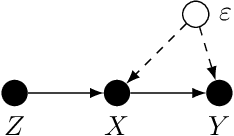
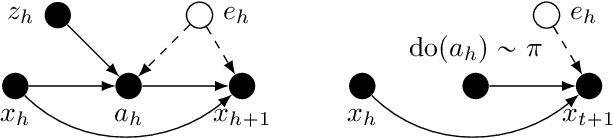
In offline reinforcement learning (RL) an optimal policy is learnt solely from a priori collected observational data. However, in observational data, actions are often confounded by unobserved variables. Instrumental variables (IVs), in the context of RL, are the variables whose influence on the state variables are all mediated through the action. When a valid instrument is present, we can recover the confounded transition dynamics through observational data. We study a confounded Markov decision process where the transition dynamics admit an additive nonlinear functional form. Using IVs, we derive a conditional moment restriction (CMR) through which we can identify transition dynamics based on observational data. We propose a provably efficient IV-aided Value Iteration (IVVI) algorithm based on a primal-dual reformulation of CMR. To the best of our knowledge, this is the first provably efficient algorithm for instrument-aided offline RL.
A Momentum-Assisted Single-Timescale Stochastic Approximation Algorithm for Bilevel Optimization
Feb 15, 2021
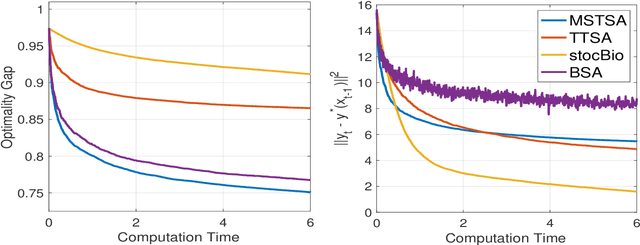
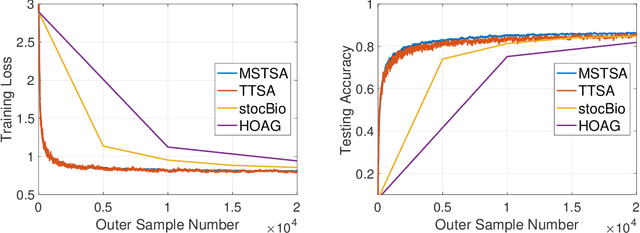

This paper proposes a new algorithm -- the Momentum-assisted Single-timescale Stochastic Approximation (MSTSA) -- for tackling unconstrained bilevel optimization problems. We focus on bilevel problems where the lower level subproblem is strongly-convex. Unlike prior works which rely on two timescale or double loop techniques that track the optimal solution to the lower level subproblem, we design a stochastic momentum assisted gradient estimator for the upper level subproblem's updates. The latter allows us to gradually control the error in stochastic gradient updates due to inaccurate solution to the lower level subproblem. We show that if the upper objective function is smooth but possibly non-convex (resp. strongly-convex), MSTSA requires $\mathcal{O}(\epsilon^{-2})$ (resp. $\mathcal{O}(\epsilon^{-1})$) iterations (each using constant samples) to find an $\epsilon$-stationary (resp. $\epsilon$-optimal) solution. This achieves the best-known guarantees for stochastic bilevel problems. We validate our theoretical results by showing the efficiency of the MSTSA algorithm on hyperparameter optimization and data hyper-cleaning problems.
Provably Training Neural Network Classifiers under Fairness Constraints
Dec 30, 2020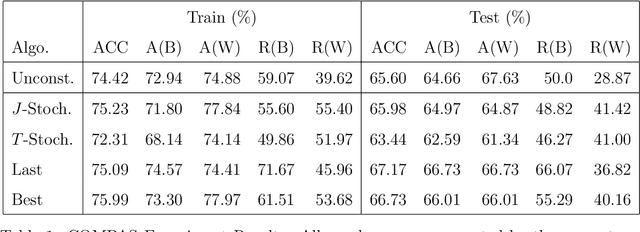
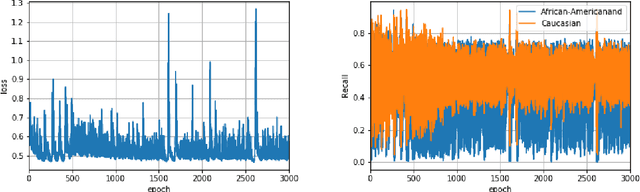
Training a classifier under fairness constraints has gotten increasing attention in the machine learning community thanks to moral, legal, and business reasons. However, several recent works addressing algorithmic fairness have only focused on simple models such as logistic regression or support vector machines due to non-convex and non-differentiable fairness criteria across protected groups, such as race or gender. Neural networks, the most widely used models for classification nowadays, are precluded and lack theoretical guarantees. This paper aims to fill this missing but crucial part of the literature of algorithmic fairness for neural networks. In particular, we show that overparametrized neural networks could meet the fairness constraints. The key ingredient of building a fair neural network classifier is establishing no-regret analysis for neural networks in the overparameterization regime, which may be of independent interest in the online learning of neural networks and related applications.
Is Pessimism Provably Efficient for Offline RL?
Dec 30, 2020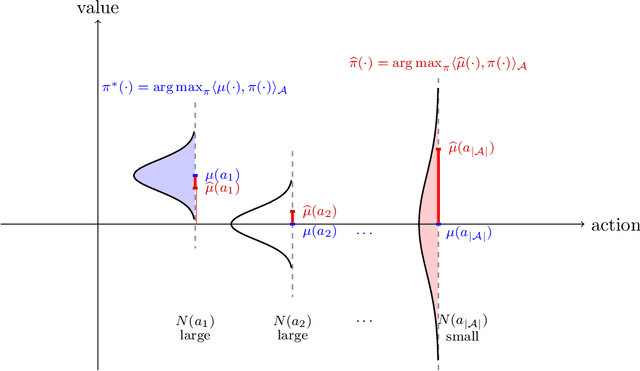
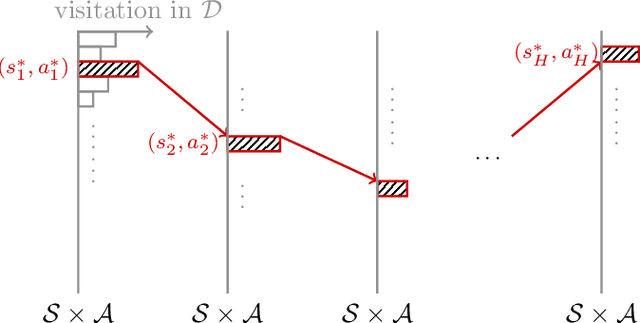
We study offline reinforcement learning (RL), which aims to learn an optimal policy based on a dataset collected a priori. Due to the lack of further interactions with the environment, offline RL suffers from the insufficient coverage of the dataset, which eludes most existing theoretical analysis. In this paper, we propose a pessimistic variant of the value iteration algorithm (PEVI), which incorporates an uncertainty quantifier as the penalty function. Such a penalty function simply flips the sign of the bonus function for promoting exploration in online RL, which makes it easily implementable and compatible with general function approximators. Without assuming the sufficient coverage of the dataset, we establish a data-dependent upper bound on the suboptimality of PEVI for general Markov decision processes (MDPs). When specialized to linear MDPs, it matches the information-theoretic lower bound up to multiplicative factors of the dimension and horizon. In other words, pessimism is not only provably efficient but also minimax optimal. In particular, given the dataset, the learned policy serves as the ``best effort'' among all policies, as no other policies can do better. Our theoretical analysis identifies the critical role of pessimism in eliminating a notion of spurious correlation, which emerges from the ``irrelevant'' trajectories that are less covered by the dataset and not informative for the optimal policy.
Risk-Sensitive Deep RL: Variance-Constrained Actor-Critic Provably Finds Globally Optimal Policy
Dec 28, 2020


While deep reinforcement learning has achieved tremendous successes in various applications, most existing works only focus on maximizing the expected value of total return and thus ignore its inherent stochasticity. Such stochasticity is also known as the aleatoric uncertainty and is closely related to the notion of risk. In this work, we make the first attempt to study risk-sensitive deep reinforcement learning under the average reward setting with the variance risk criteria. In particular, we focus on a variance-constrained policy optimization problem where the goal is to find a policy that maximizes the expected value of the long-run average reward, subject to a constraint that the long-run variance of the average reward is upper bounded by a threshold. Utilizing Lagrangian and Fenchel dualities, we transform the original problem into an unconstrained saddle-point policy optimization problem, and propose an actor-critic algorithm that iteratively and efficiently updates the policy, the Lagrange multiplier, and the Fenchel dual variable. When both the value and policy functions are represented by multi-layer overparameterized neural networks, we prove that our actor-critic algorithm generates a sequence of policies that finds a globally optimal policy at a sublinear rate.
Variational Transport: A Convergent Particle-BasedAlgorithm for Distributional Optimization
Dec 21, 2020We consider the optimization problem of minimizing a functional defined over a family of probability distributions, where the objective functional is assumed to possess a variational form. Such a distributional optimization problem arises widely in machine learning and statistics, with Monte-Carlo sampling, variational inference, policy optimization, and generative adversarial network as examples. For this problem, we propose a novel particle-based algorithm, dubbed as variational transport, which approximately performs Wasserstein gradient descent over the manifold of probability distributions via iteratively pushing a set of particles. Specifically, we prove that moving along the geodesic in the direction of functional gradient with respect to the second-order Wasserstein distance is equivalent to applying a pushforward mapping to a probability distribution, which can be approximated accurately by pushing a set of particles. Specifically, in each iteration of variational transport, we first solve the variational problem associated with the objective functional using the particles, whose solution yields the Wasserstein gradient direction. Then we update the current distribution by pushing each particle along the direction specified by such a solution. By characterizing both the statistical error incurred in estimating the Wasserstein gradient and the progress of the optimization algorithm, we prove that when the objective function satisfies a functional version of the Polyak-\L{}ojasiewicz (PL) (Polyak, 1963) and smoothness conditions, variational transport converges linearly to the global minimum of the objective functional up to a certain statistical error, which decays to zero sublinearly as the number of particles goes to infinity.
Bridging Exploration and General Function Approximation in Reinforcement Learning: Provably Efficient Kernel and Neural Value Iterations
Nov 09, 2020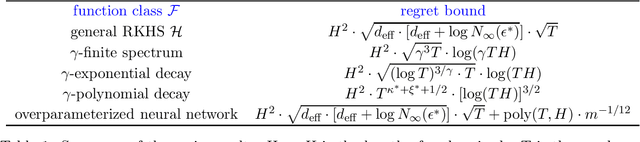
Reinforcement learning (RL) algorithms combined with modern function approximators such as kernel functions and deep neural networks have achieved significant empirical successes in large-scale application problems with a massive number of states. From a theoretical perspective, however, RL with functional approximation poses a fundamental challenge to developing algorithms with provable computational and statistical efficiency, due to the need to take into consideration both the exploration-exploitation tradeoff that is inherent in RL and the bias-variance tradeoff that is innate in statistical estimation. To address such a challenge, focusing on the episodic setting where the action-value functions are represented by a kernel function or over-parametrized neural network, we propose the first provable RL algorithm with both polynomial runtime and sample complexity, without additional assumptions on the data-generating model. In particular, for both the kernel and neural settings, we prove that an optimistic modification of the least-squares value iteration algorithm incurs an $\tilde{\mathcal{O}}(\delta_{\mathcal{F}} H^2 \sqrt{T})$ regret, where $\delta_{\mathcal{F}}$ characterizes the intrinsic complexity of the function class $\mathcal{F}$, $H$ is the length of each episode, and $T$ is the total number of episodes. Our regret bounds are independent of the number of states and therefore even allows it to diverge, which exhibits the benefit of function approximation.