 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Generation by Differential Test Time Scaling
May 19, 2026Test-time scaling has emerged as a promising approach for improving code generation by exploring large solution spaces at inference time. However, existing methods often rely on public test cases that are unavailable in practice, or require extensive LLM inference for candidate selection, leading to significant token consumption and time overhead. We present DiffCodeGen, a novel test-time scaling method for code generation based on coverage-guided differential analysis. DiffCodeGen generates diverse code candidates using various sampling and prompting strategies, then applies coverage-guided fuzzing to synthesize inputs without requiring any existing tests or large language models. By executing all candidates on these inputs, DiffCodeGen captures their dynamic behavior and clusters candidates based on behavioral similarity. DiffCodeGen selects the medoid of the largest cluster as the final output. Unlike prior test-time scaling methods that invoke additional LLM inference for candidate selection, DiffCodeGen performs selection without any extra model calls, incurring little to no additional token consumption. DiffCodeGen is fully asynchronous, naturally suited to the current trend of agentic coding, and is thus efficient and highly scalable. We evaluate DiffCodeGen across 4 large language models, demonstrating consistent improvements over baselines. Compared to state-of-the-art test-time scaling methods, DiffCodeGen achieves competitive or superior performance while using only a fraction of time and tokens. DiffCodeGen is model-agnostic and can be combined with reasoning models to further boost performance.
Security of AI Agents
Jun 20, 2024



The study and development of AI agents have been boosted by large language models. AI agents can function as intelligent assistants and complete tasks on behalf of their users with access to tools and the ability to execute commands in their environments, Through studying and experiencing the workflow of typical AI agents, we have raised several concerns regarding their security. These potential vulnerabilities are not addressed by the frameworks used to build the agents, nor by research aimed at improving the agents. In this paper, we identify and describe these vulnerabilities in detail from a system security perspective, emphasizing their causes and severe effects. Furthermore, we introduce defense mechanisms corresponding to each vulnerability with meticulous design and experiments to evaluate their viability. Altogether, this paper contextualizes the security issues in the current development of AI agents and delineates methods to make AI agents safer and more reliable.
UniTSyn: A Large-Scale Dataset Capable of Enhancing the Prowess of Large Language Models for Program Testing
Feb 04, 2024



The remarkable capability of large language models (LLMs) in generating high-quality code has drawn increasing attention in the software testing community. However, existing code LLMs often demonstrate unsatisfactory capabilities in generating accurate and complete tests since they were trained on code snippets collected without differentiating between code for testing purposes and other code. In this paper, we present a large-scale dataset UniTSyn, which is capable of enhancing the prowess of LLMs for Unit Test Synthesis. Associating tests with the tested functions is crucial for LLMs to infer the expected behavior and the logic paths to be verified. By leveraging Language Server Protocol, UniTSyn achieves the challenging goal of collecting focal-test pairs without per-project execution setups or per-language heuristics that tend to be fragile and difficult to scale. It contains 2.7 million focal-test pairs across five mainstream programming languages, making it possible to be utilized for enhancing the test generation ability of LLMs. The details of UniTSyn can be found in Table 1. Our experiments demonstrate that, by building an autoregressive model based on UniTSyn, we can achieve significant benefits in learning and understanding unit test representations, resulting in improved generation accuracy and code coverage across all evaluated programming languages. Code and data will be publicly available.
Permutation Invariant Policy Optimization for Mean-Field Multi-Agent Reinforcement Learning: A Principled Approach
May 18, 2021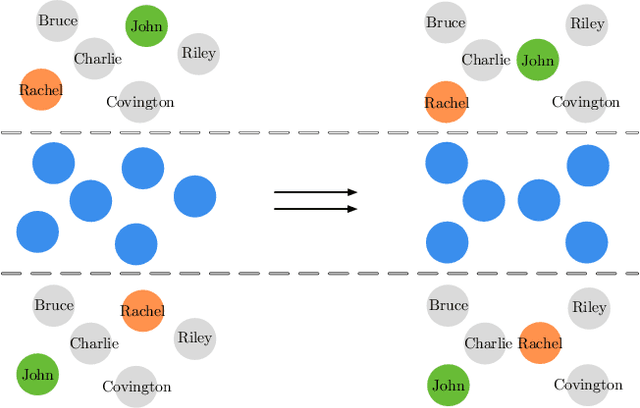
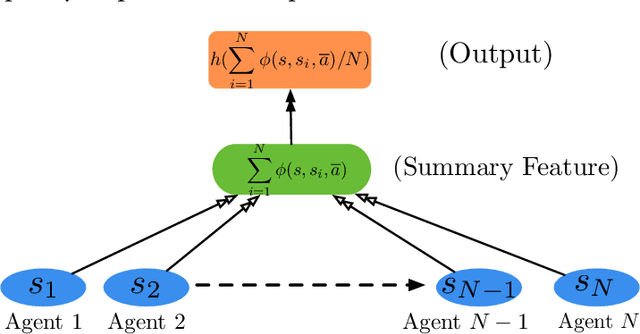
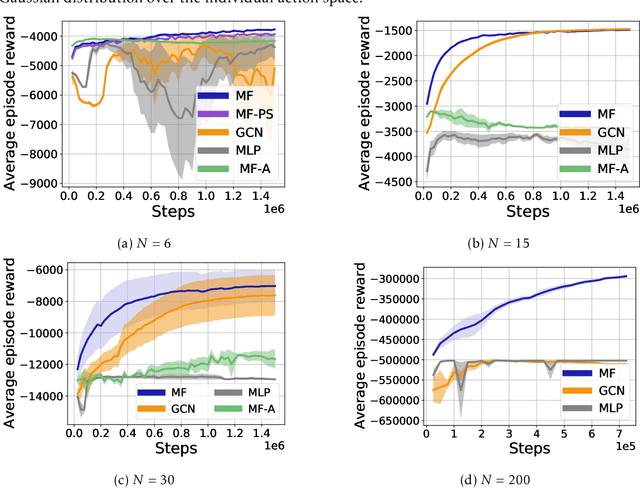
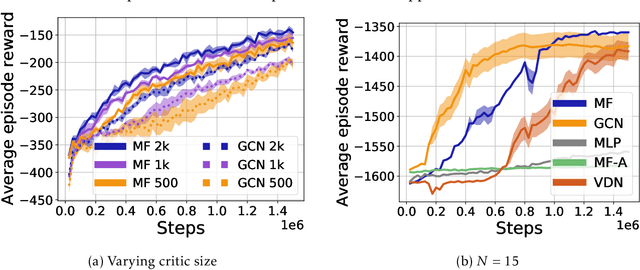
Multi-agent reinforcement learning (MARL) becomes more challenging in the presence of more agents, as the capacity of the joint state and action spaces grows exponentially in the number of agents. To address such a challenge of scale, we identify a class of cooperative MARL problems with permutation invariance, and formulate it as a mean-field Markov decision processes (MDP). To exploit the permutation invariance therein, we propose the mean-field proximal policy optimization (MF-PPO) algorithm, at the core of which is a permutation-invariant actor-critic neural architecture. We prove that MF-PPO attains the globally optimal policy at a sublinear rate of convergence. Moreover, its sample complexity is independent of the number of agents. We validate the theoretical advantages of MF-PPO with numerical experiments in the multi-agent particle environment (MPE). In particular, we show that the inductive bias introduced by the permutation-invariant neural architecture enables MF-PPO to outperform existing competitors with a smaller number of model parameters, which is the key to its generalization performance.