 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRObotic MAnipulation Network (ROMAN) $\unicode{x2013}$ Hybrid Hierarchical Learning for Solving Complex Sequential Tasks
Jul 07, 2023Solving long sequential tasks poses a significant challenge in embodied artificial intelligence. Enabling a robotic system to perform diverse sequential tasks with a broad range of manipulation skills is an active area of research. In this work, we present a Hybrid Hierarchical Learning framework, the Robotic Manipulation Network (ROMAN), to address the challenge of solving multiple complex tasks over long time horizons in robotic manipulation. ROMAN achieves task versatility and robust failure recovery by integrating behavioural cloning, imitation learning, and reinforcement learning. It consists of a central manipulation network that coordinates an ensemble of various neural networks, each specialising in distinct re-combinable sub-tasks to generate their correct in-sequence actions for solving complex long-horizon manipulation tasks. Experimental results show that by orchestrating and activating these specialised manipulation experts, ROMAN generates correct sequential activations for accomplishing long sequences of sophisticated manipulation tasks and achieving adaptive behaviours beyond demonstrations, while exhibiting robustness to various sensory noises. These results demonstrate the significance and versatility of ROMAN's dynamic adaptability featuring autonomous failure recovery capabilities, and highlight its potential for various autonomous manipulation tasks that demand adaptive motor skills.
Multi-Epoch Learning for Deep Click-Through Rate Prediction Models
May 31, 2023The one-epoch overfitting phenomenon has been widely observed in industrial Click-Through Rate (CTR) applications, where the model performance experiences a significant degradation at the beginning of the second epoch. Recent advances try to understand the underlying factors behind this phenomenon through extensive experiments. However, it is still unknown whether a multi-epoch training paradigm could achieve better results, as the best performance is usually achieved by one-epoch training. In this paper, we hypothesize that the emergence of this phenomenon may be attributed to the susceptibility of the embedding layer to overfitting, which can stem from the high-dimensional sparsity of data. To maintain feature sparsity while simultaneously avoiding overfitting of embeddings, we propose a novel Multi-Epoch learning with Data Augmentation (MEDA), which can be directly applied to most deep CTR models. MEDA achieves data augmentation by reinitializing the embedding layer in each epoch, thereby avoiding embedding overfitting and simultaneously improving convergence. To our best knowledge, MEDA is the first multi-epoch training paradigm designed for deep CTR prediction models. We conduct extensive experiments on several public datasets, and the effectiveness of our proposed MEDA is fully verified. Notably, the results show that MEDA can significantly outperform the conventional one-epoch training. Besides, MEDA has exhibited significant benefits in a real-world scene on Kuaishou.
Deep Stable Multi-Interest Learning for Out-of-distribution Sequential Recommendation
Apr 12, 2023Recently, multi-interest models, which extract interests of a user as multiple representation vectors, have shown promising performances for sequential recommendation. However, none of existing multi-interest recommendation models consider the Out-Of-Distribution (OOD) generalization problem, in which interest distribution may change. Considering multiple interests of a user are usually highly correlated, the model has chance to learn spurious correlations between noisy interests and target items. Once the data distribution changes, the correlations among interests may also change, and the spurious correlations will mislead the model to make wrong predictions. To tackle with above OOD generalization problem, we propose a novel multi-interest network, named DEep Stable Multi-Interest Learning (DESMIL), which attempts to de-correlate the extracted interests in the model, and thus spurious correlations can be eliminated. DESMIL applies an attentive module to extract multiple interests, and then selects the most important one for making final predictions. Meanwhile, DESMIL incorporates a weighted correlation estimation loss based on Hilbert-Schmidt Independence Criterion (HSIC), with which training samples are weighted, to minimize the correlations among extracted interests. Extensive experiments have been conducted under both OOD and random settings, and up to 36.8% and 21.7% relative improvements are achieved respectively.
Agile and Versatile Robot Locomotion via Kernel-based Residual Learning
Feb 14, 2023



This work developed a kernel-based residual learning framework for quadrupedal robotic locomotion. Initially, a kernel neural network is trained with data collected from an MPC controller. Alongside a frozen kernel network, a residual controller network is trained via reinforcement learning to acquire generalized locomotion skills and resilience against external perturbations. With this proposed framework, a robust quadrupedal locomotion controller is learned with high sample efficiency and controllability, providing omnidirectional locomotion at continuous velocities. Its versatility and robustness are validated on unseen terrains that the expert MPC controller fails to traverse. Furthermore, the learned kernel can produce a range of functional locomotion behaviors and can generalize to unseen gaits.
Deep Stable Representation Learning on Electronic Health Records
Sep 03, 2022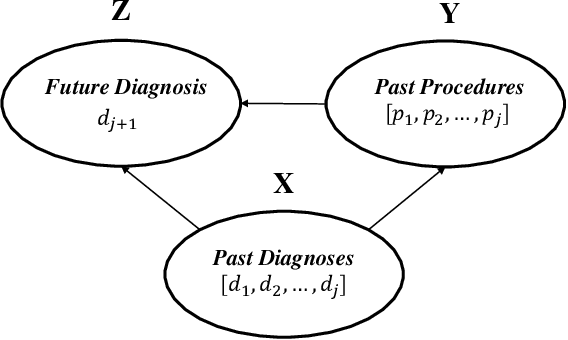
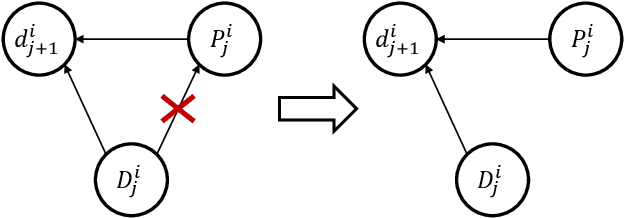
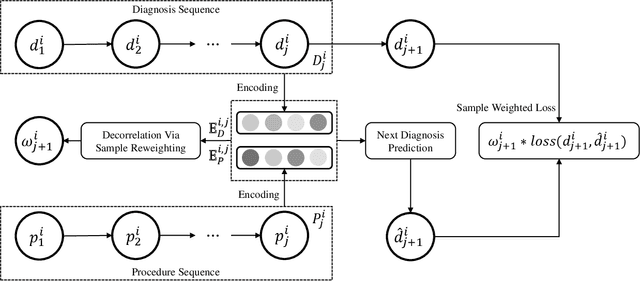
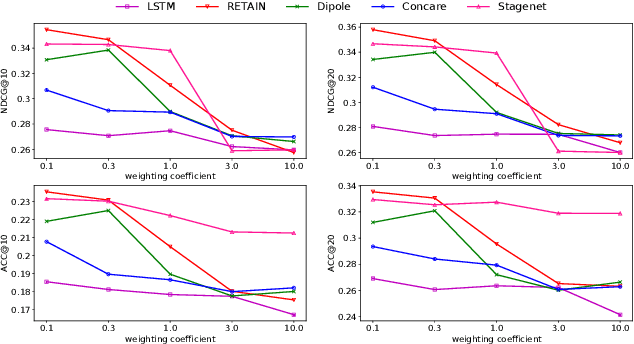
Deep learning models have achieved promising disease prediction performance of the Electronic Health Records (EHR) of patients. However, most models developed under the I.I.D. hypothesis fail to consider the agnostic distribution shifts, diminishing the generalization ability of deep learning models to Out-Of-Distribution (OOD) data. In this setting, spurious statistical correlations that may change in different environments will be exploited, which can cause sub-optimal performances of deep learning models. The unstable correlation between procedures and diagnoses existed in the training distribution can cause spurious correlation between historical EHR and future diagnosis. To address this problem, we propose to use a causal representation learning method called Causal Healthcare Embedding (CHE). CHE aims at eliminating the spurious statistical relationship by removing the dependencies between diagnoses and procedures. We introduce the Hilbert-Schmidt Independence Criterion (HSIC) to measure the degree of independence between the embedded diagnosis and procedure features. Based on causal view analyses, we perform the sample weighting technique to get rid of such spurious relationship for the stable learning of EHR across different environments. Moreover, our proposed CHE method can be used as a flexible plug-and-play module that can enhance existing deep learning models on EHR. Extensive experiments on two public datasets and five state-of-the-art baselines unequivocally show that CHE can improve the prediction accuracy of deep learning models on out-of-distribution data by a large margin. In addition, the interpretability study shows that CHE could successfully leverage causal structures to reflect a more reasonable contribution of historical records for predictions.
Improving Multi-Interest Network with Stable Learning
Jul 14, 2022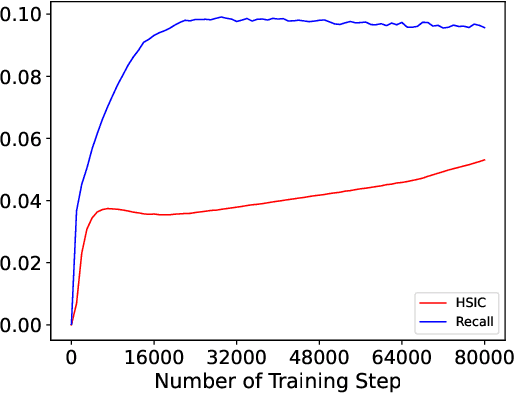
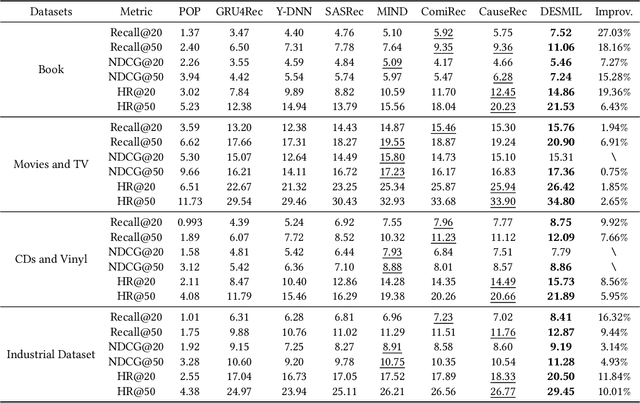
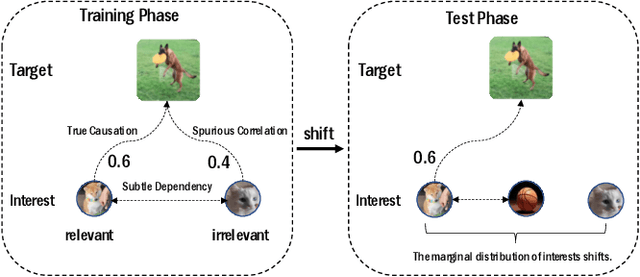
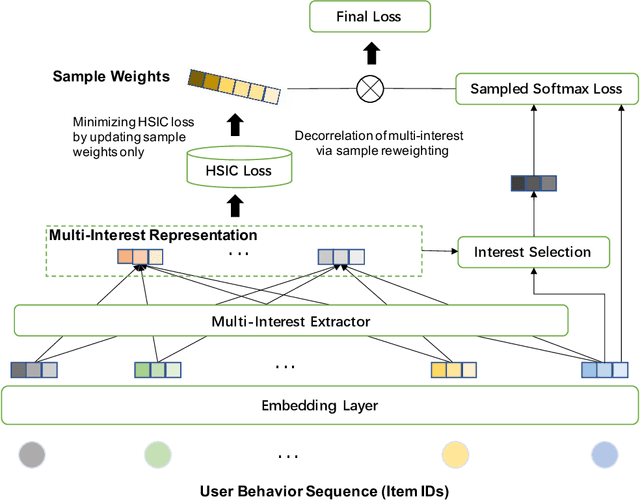
Modeling users' dynamic preferences from historical behaviors lies at the core of modern recommender systems. Due to the diverse nature of user interests, recent advances propose the multi-interest networks to encode historical behaviors into multiple interest vectors. In real scenarios, the corresponding items of captured interests are usually retrieved together to get exposure and collected into training data, which produces dependencies among interests. Unfortunately, multi-interest networks may incorrectly concentrate on subtle dependencies among captured interests. Misled by these dependencies, the spurious correlations between irrelevant interests and targets are captured, resulting in the instability of prediction results when training and test distributions do not match. In this paper, we introduce the widely used Hilbert-Schmidt Independence Criterion (HSIC) to measure the degree of independence among captured interests and empirically show that the continuous increase of HSIC may harm model performance. Based on this, we propose a novel multi-interest network, named DEep Stable Multi-Interest Learning (DESMIL), which tries to eliminate the influence of subtle dependencies among captured interests via learning weights for training samples and make model concentrate more on underlying true causation. We conduct extensive experiments on public recommendation datasets, a large-scale industrial dataset and the synthetic datasets which simulate the out-of-distribution data. Experimental results demonstrate that our proposed DESMIL outperforms state-of-the-art models by a significant margin. Besides, we also conduct comprehensive model analysis to reveal the reason why DESMIL works to a certain extent.
LPFS: Learnable Polarizing Feature Selection for Click-Through Rate Prediction
Jun 01, 2022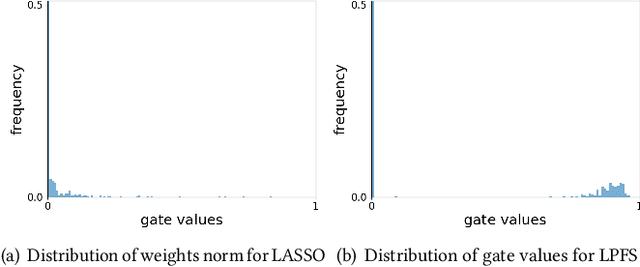
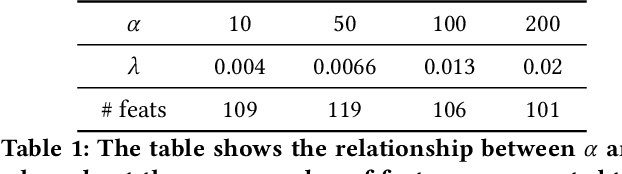
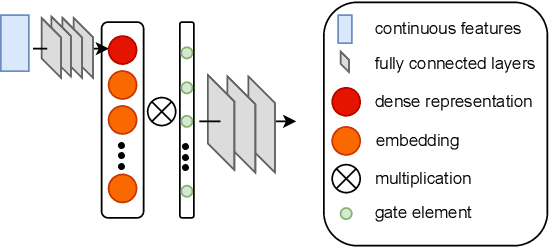

In industry, feature selection is a standard but necessary step to search for an optimal set of informative feature fields for efficient and effective training of deep Click-Through Rate (CTR) models. Most previous works measure the importance of feature fields by using their corresponding continuous weights from the model, then remove the feature fields with small weight values. However, removing many features that correspond to small but not exact zero weights will inevitably hurt model performance and not be friendly to hot-start model training. There is also no theoretical guarantee that the magnitude of weights can represent the importance, thus possibly leading to sub-optimal results if using these methods. To tackle this problem, we propose a novel Learnable Polarizing Feature Selection (LPFS) method using a smoothed-$\ell^0$ function in literature. Furthermore, we extend LPFS to LPFS++ by our newly designed smoothed-$\ell^0$-liked function to select a more informative subset of features. LPFS and LPFS++ can be used as gates inserted at the input of the deep network to control the active and inactive state of each feature. When training is finished, some gates are exact zero, while others are around one, which is particularly favored by the practical hot-start training in the industry, due to no damage to the model performance before and after removing the features corresponding to exact-zero gates. Experiments show that our methods outperform others by a clear margin, and have achieved great A/B test results in KuaiShou Technology.
Slimmable Video Codec
May 13, 2022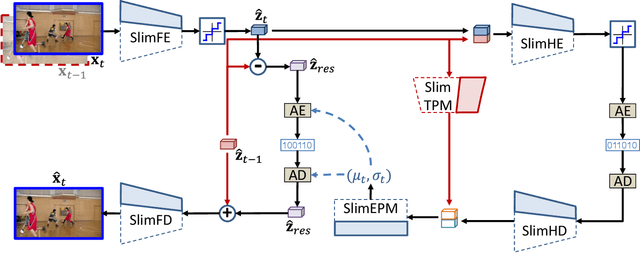

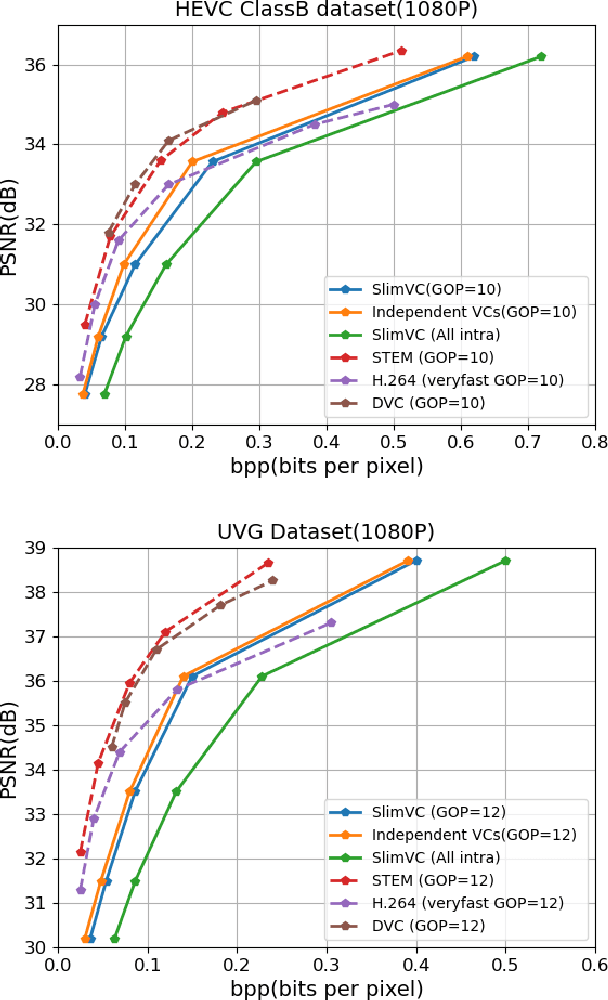
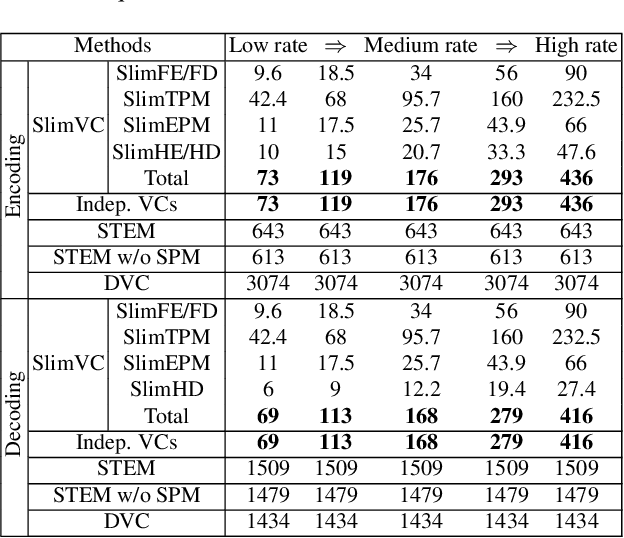
Neural video compression has emerged as a novel paradigm combining trainable multilayer neural networks and machine learning, achieving competitive rate-distortion (RD) performances, but still remaining impractical due to heavy neural architectures, with large memory and computational demands. In addition, models are usually optimized for a single RD tradeoff. Recent slimmable image codecs can dynamically adjust their model capacity to gracefully reduce the memory and computation requirements, without harming RD performance. In this paper we propose a slimmable video codec (SlimVC), by integrating a slimmable temporal entropy model in a slimmable autoencoder. Despite a significantly more complex architecture, we show that slimming remains a powerful mechanism to control rate, memory footprint, computational cost and latency, all being important requirements for practical video compression.
Learning Vision-Guided Dynamic Locomotion Over Challenging Terrains
Sep 09, 2021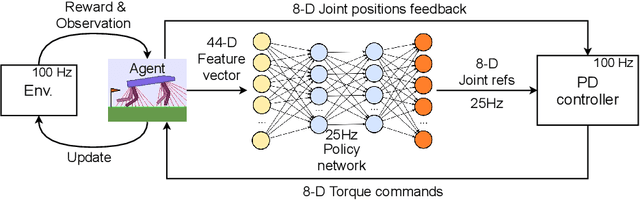
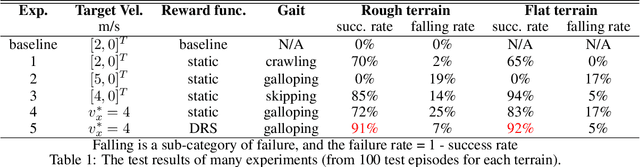
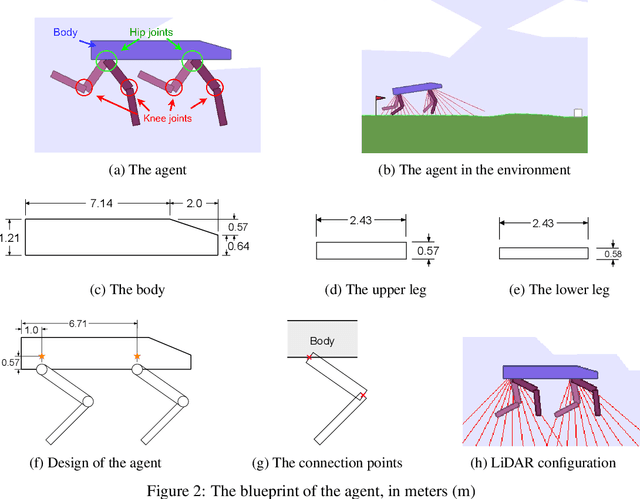

Legged robots are becoming increasingly powerful and popular in recent years for their potential to bring the mobility of autonomous agents to the next level. This work presents a deep reinforcement learning approach that learns a robust Lidar-based perceptual locomotion policy in a partially observable environment using Proximal Policy Optimisation. Visual perception is critical to actively overcome challenging terrains, and to do so, we propose a novel learning strategy: Dynamic Reward Strategy (DRS), which serves as effective heuristics to learn a versatile gait using a neural network architecture without the need to access the history data. Moreover, in a modified version of the OpenAI gym environment, the proposed work is evaluated with scores over 90% success rate in all tested challenging terrains.
Deep Active Learning for Text Classification with Diverse Interpretations
Aug 15, 2021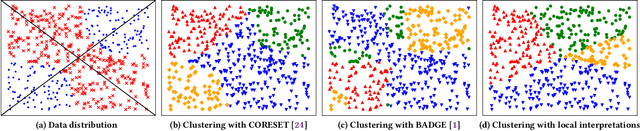
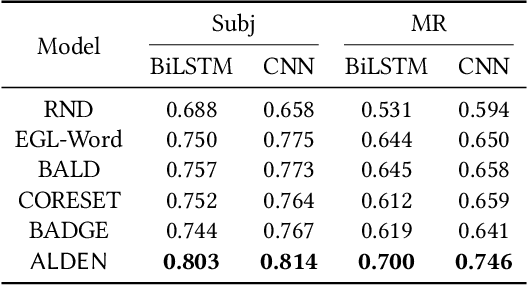
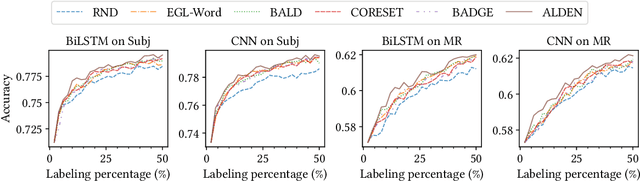
Recently, Deep Neural Networks (DNNs) have made remarkable progress for text classification, which, however, still require a large number of labeled data. To train high-performing models with the minimal annotation cost, active learning is proposed to select and label the most informative samples, yet it is still challenging to measure informativeness of samples used in DNNs. In this paper, inspired by piece-wise linear interpretability of DNNs, we propose a novel Active Learning with DivErse iNterpretations (ALDEN) approach. With local interpretations in DNNs, ALDEN identifies linearly separable regions of samples. Then, it selects samples according to their diversity of local interpretations and queries their labels. To tackle the text classification problem, we choose the word with the most diverse interpretations to represent the whole sentence. Extensive experiments demonstrate that ALDEN consistently outperforms several state-of-the-art deep active learning methods.