 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Inference of Networked Dynamical Systems with Universal Differential Equations
Jul 11, 2022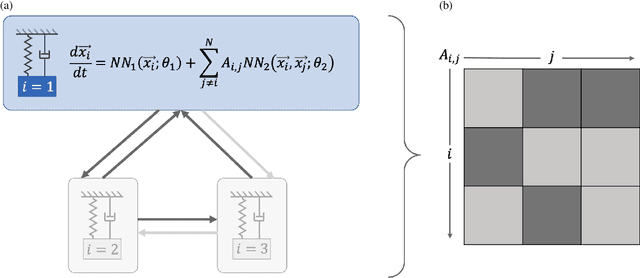
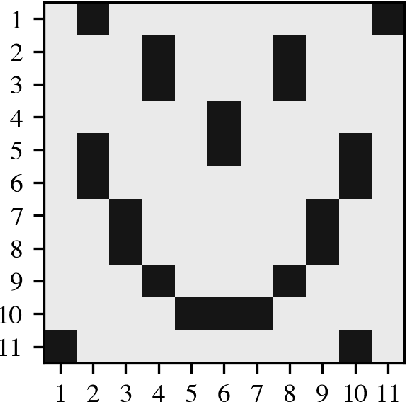
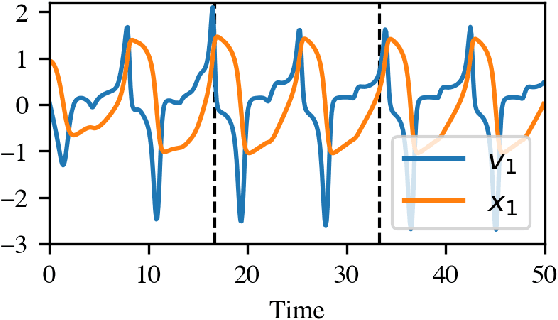
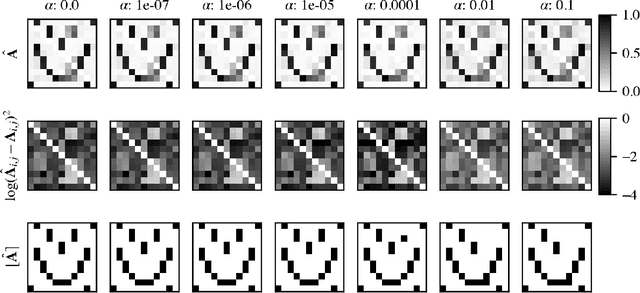
Networked dynamical systems are common throughout science in engineering; e.g., biological networks, reaction networks, power systems, and the like. For many such systems, nonlinearity drives populations of identical (or near-identical) units to exhibit a wide range of nontrivial behaviors, such as the emergence of coherent structures (e.g., waves and patterns) or otherwise notable dynamics (e.g., synchrony and chaos). In this work, we seek to infer (i) the intrinsic physics of a base unit of a population, (ii) the underlying graphical structure shared between units, and (iii) the coupling physics of a given networked dynamical system given observations of nodal states. These tasks are formulated around the notion of the Universal Differential Equation, whereby unknown dynamical systems can be approximated with neural networks, mathematical terms known a priori (albeit with unknown parameterizations), or combinations of the two. We demonstrate the value of these inference tasks by investigating not only future state predictions but also the inference of system behavior on varied network topologies. The effectiveness and utility of these methods is shown with their application to canonical networked nonlinear coupled oscillators.
HyperPrompt: Prompt-based Task-Conditioning of Transformers
Mar 01, 2022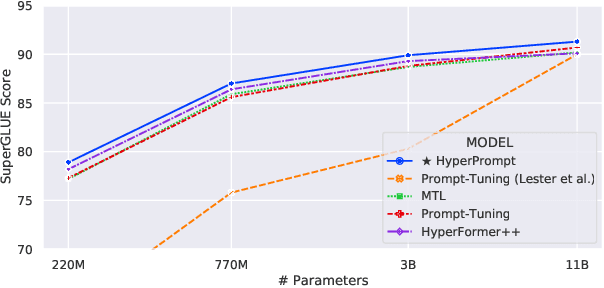

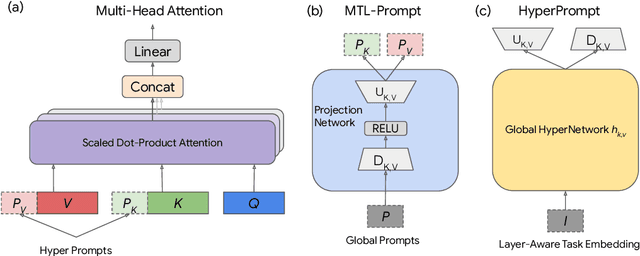
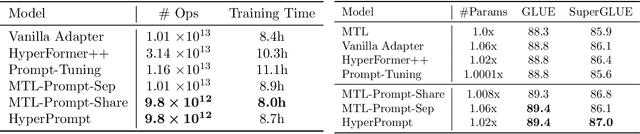
Prompt-Tuning is a new paradigm for finetuning pre-trained language models in a parameter-efficient way. Here, we explore the use of HyperNetworks to generate hyper-prompts: we propose HyperPrompt, a novel architecture for prompt-based task-conditioning of self-attention in Transformers. The hyper-prompts are end-to-end learnable via generation by a HyperNetwork. HyperPrompt allows the network to learn task-specific feature maps where the hyper-prompts serve as task global memories for the queries to attend to, at the same time enabling flexible information sharing among tasks. We show that HyperPrompt is competitive against strong multi-task learning baselines with as few as $0.14\%$ of additional task-conditioning parameters, achieving great parameter and computational efficiency. Through extensive empirical experiments, we demonstrate that HyperPrompt can achieve superior performances over strong T5 multi-task learning baselines and parameter-efficient adapter variants including Prompt-Tuning and HyperFormer++ on Natural Language Understanding benchmarks of GLUE and SuperGLUE across many model sizes.
GradTail: Learning Long-Tailed Data Using Gradient-based Sample Weighting
Jan 19, 2022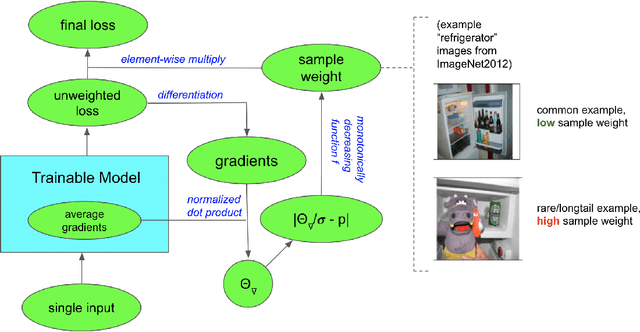
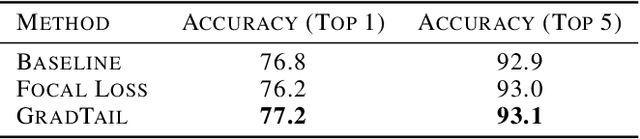
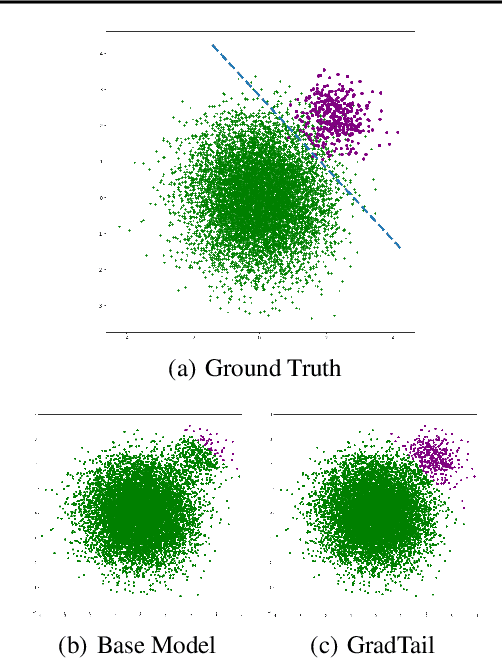

We propose GradTail, an algorithm that uses gradients to improve model performance on the fly in the face of long-tailed training data distributions. Unlike conventional long-tail classifiers which operate on converged - and possibly overfit - models, we demonstrate that an approach based on gradient dot product agreement can isolate long-tailed data early on during model training and improve performance by dynamically picking higher sample weights for that data. We show that such upweighting leads to model improvements for both classification and regression models, the latter of which are relatively unexplored in the long-tail literature, and that the long-tail examples found by gradient alignment are consistent with our semantic expectations.
Just Pick a Sign: Optimizing Deep Multitask Models with Gradient Sign Dropout
Oct 14, 2020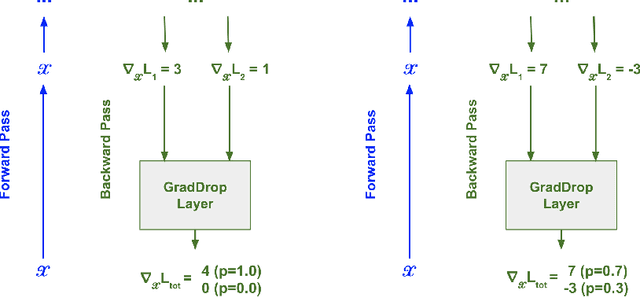
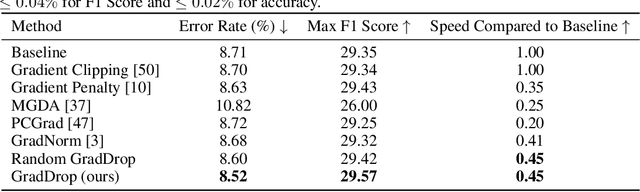
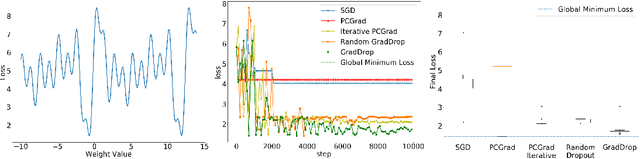
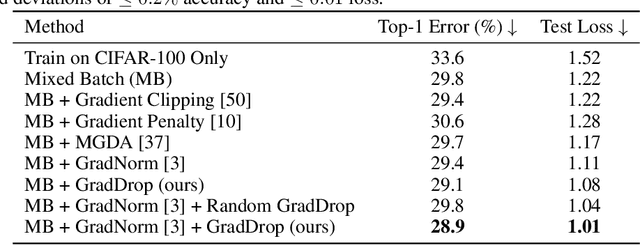
The vast majority of deep models use multiple gradient signals, typically corresponding to a sum of multiple loss terms, to update a shared set of trainable weights. However, these multiple updates can impede optimal training by pulling the model in conflicting directions. We present Gradient Sign Dropout (GradDrop), a probabilistic masking procedure which samples gradients at an activation layer based on their level of consistency. GradDrop is implemented as a simple deep layer that can be used in any deep net and synergizes with other gradient balancing approaches. We show that GradDrop outperforms the state-of-the-art multiloss methods within traditional multitask and transfer learning settings, and we discuss how GradDrop reveals links between optimal multiloss training and gradient stochasticity.
Sparse representation for damage identification of structural systems
Jun 06, 2020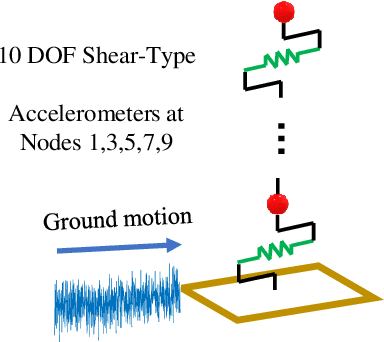
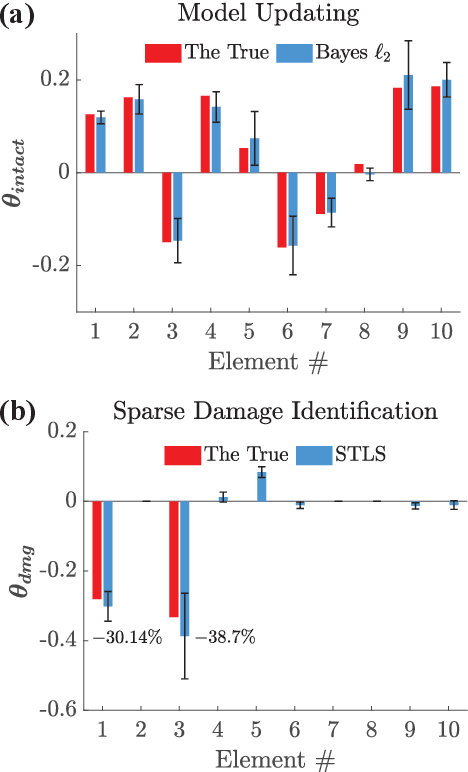
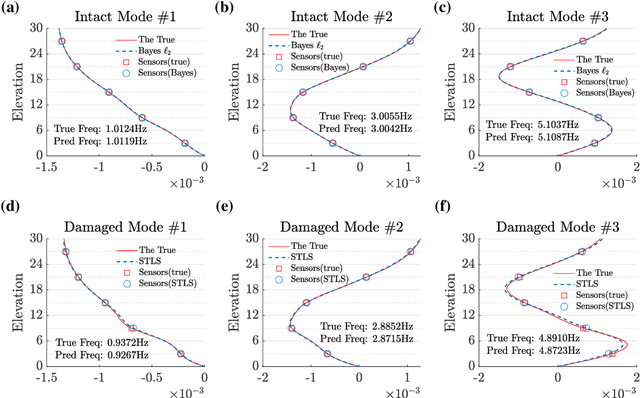
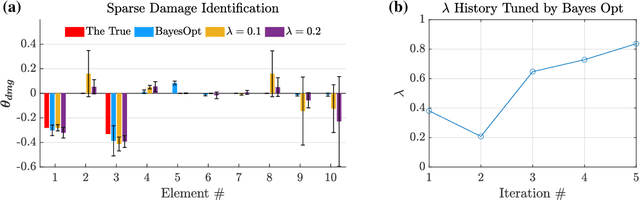
Identifying damage of structural systems is typically characterized as an inverse problem which might be ill-conditioned due to aleatory and epistemic uncertainties induced by measurement noise and modeling error. Sparse representation can be used to perform inverse analysis for the case of sparse damage. In this paper, we propose a novel two-stage sensitivity analysis-based framework for both model updating and sparse damage identification. Specifically, an $\ell_2$ Bayesian learning method is firstly developed for updating the intact model and uncertainty quantification so as to set forward a baseline for damage detection. A sparse representation pipeline built on a quasi-$\ell_0$ method, e.g., Sequential Threshold Least Squares (STLS) regression, is then presented for damage localization and quantification. Additionally, Bayesian optimization together with cross validation is developed to heuristically learn hyperparameters from data, which saves the computational cost of hyperparameter tuning and produces more reliable identification result. The proposed framework is verified by three examples, including a 10-story shear-type building, a complex truss structure, and a shake table test of an eight-story steel frame. Results show that the proposed approach is capable of both localizing and quantifying structural damage with high accuracy.
Taskology: Utilizing Task Relations at Scale
May 14, 2020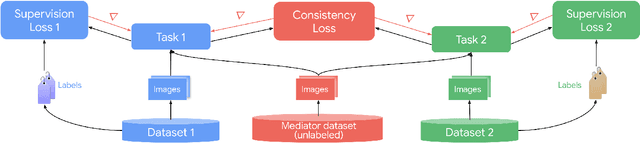
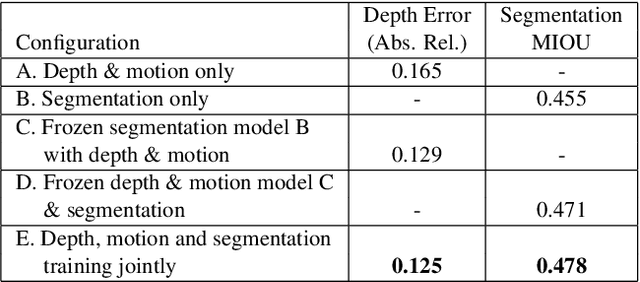
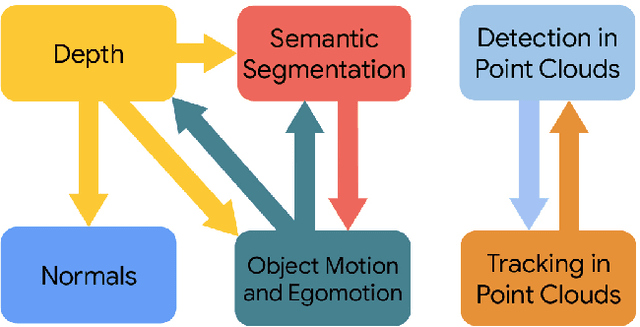
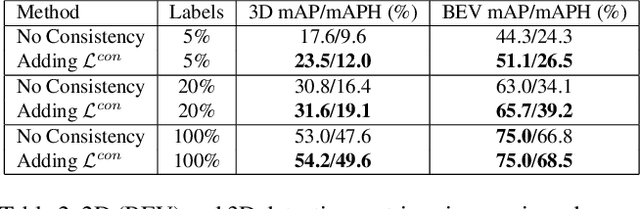
It has been recognized that the joint training of computer vision tasks with shared network components enables higher performance for each individual task. Training tasks together allows learning the inherent relationships among them; however, this requires large sets of labeled data. Instead, we argue that utilizing the known relationships between tasks explicitly allows improving their performance with less labeled data. To this end, we aim to establish and explore a novel approach for the collective training of computer vision tasks. In particular, we focus on utilizing the inherent relations of tasks by employing consistency constraints derived from physics, geometry, and logic. We show that collections of models can be trained without shared components, interacting only through the consistency constraints as supervision (peer-supervision). The consistency constraints enforce the structural priors between tasks, which enables their mutually consistent training, and -- in turn -- leads to overall higher performance. Treating individual tasks as modules, agnostic to their implementation, reduces the engineering overhead to collectively train many tasks to a minimum. Furthermore, the collective training can be distributed among multiple compute nodes, which further facilitates training at scale. We demonstrate our framework on subsets of the following collection of tasks: depth and normal prediction, semantic segmentation, 3D motion estimation, and object tracking and detection in point clouds.
Deep learning of physical laws from scarce data
May 05, 2020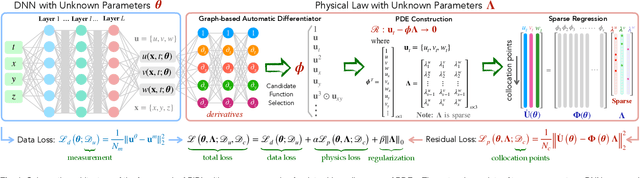

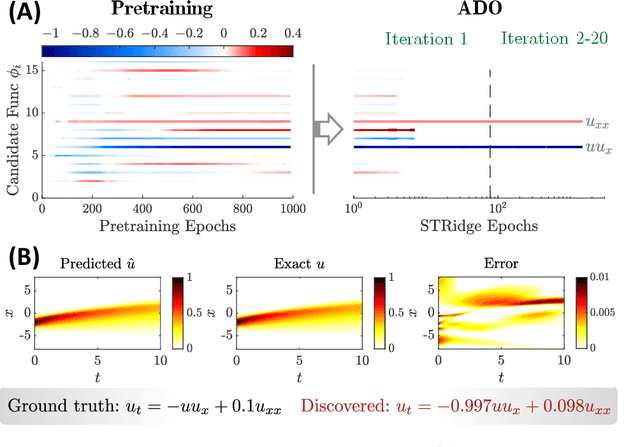
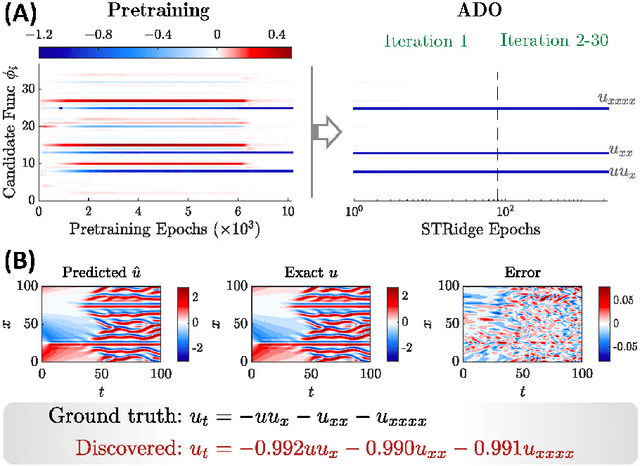
Harnessing data to discover the underlying governing laws or equations that describe the behavior of complex physical systems can significantly advance our modeling, simulation and understanding of such systems in various science and engineering disciplines. Recent advances in sparse identification show encouraging success in distilling closed-form governing equations from data for a wide range of nonlinear dynamical systems. However, the fundamental bottleneck of this approach lies in the robustness and scalability with respect to data scarcity and noise. This work introduces a novel physics-informed deep learning framework to discover governing partial differential equations (PDEs) from scarce and noisy data for nonlinear spatiotemporal systems. In particular, this approach seamlessly integrates the strengths of deep neural networks for rich representation learning, automatic differentiation and sparse regression to approximate the solution of system variables, compute essential derivatives, as well as identify the key derivative terms and parameters that form the structure and explicit expression of the PDEs. The efficacy and robustness of this method are demonstrated on discovering a variety of PDE systems with different levels of data scarcity and noise. The resulting computational framework shows the potential for closed-form model discovery in practical applications where large and accurate datasets are intractable to capture.
DeepPerimeter: Indoor Boundary Estimation from Posed Monocular Sequences
Apr 25, 2019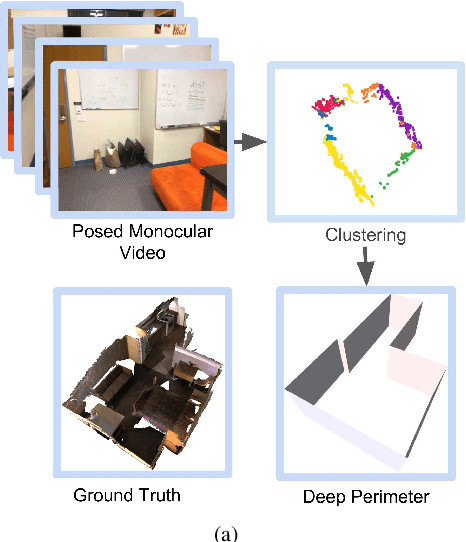
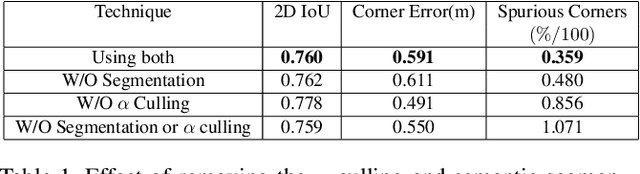
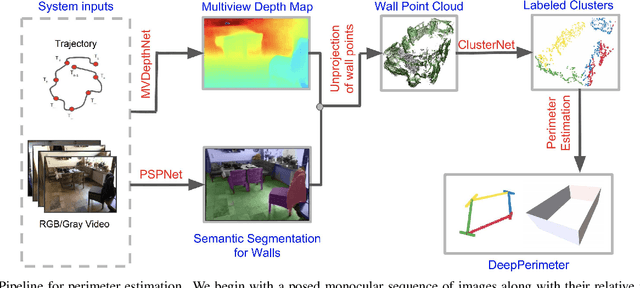
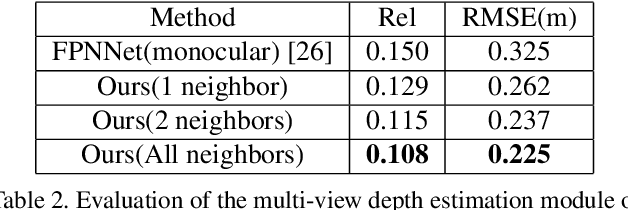
We present DeepPerimeter, a deep learning based pipeline for inferring a full indoor perimeter (i.e. exterior boundary map) from a sequence of posed RGB images. Our method relies on robust deep methods for depth estimation and wall segmentation to generate an exterior boundary point cloud, and then uses deep unsupervised clustering to fit wall planes to obtain a final boundary map of the room. We demonstrate that DeepPerimeter results in excellent visual and quantitative performance on the popular ScanNet and FloorNet datasets and works for room shapes of various complexities as well as in multiroom scenarios. We also establish important baselines for future work on indoor perimeter estimation, topics which will become increasingly prevalent as application areas like augmented reality and robotics become more significant.
Decentralized Computation Offloading for Multi-User Mobile Edge Computing: A Deep Reinforcement Learning Approach
Dec 16, 2018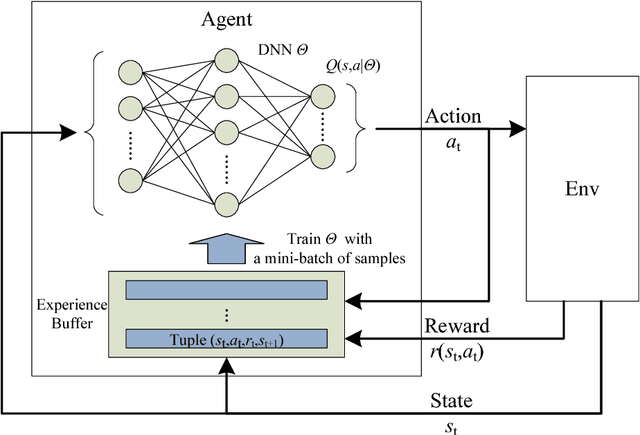
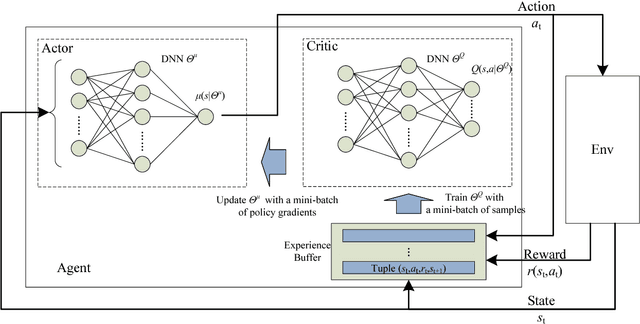
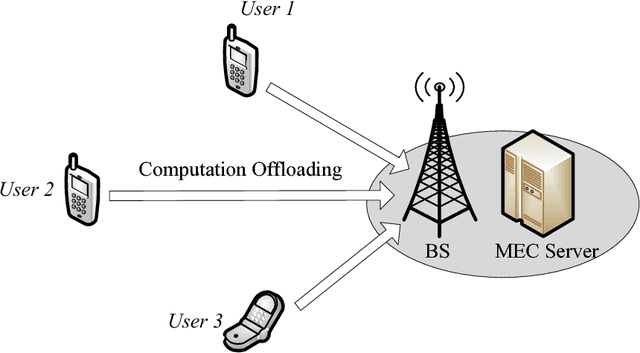
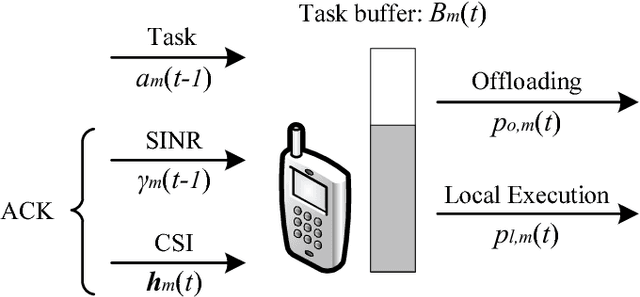
Mobile edge computing (MEC) emerges recently as a promising solution to relieve resource-limited mobile devices from computation-intensive tasks, which enables devices to offload workloads to nearby MEC servers and improve the quality of computation experience. Nevertheless, by considering a MEC system consisting of multiple mobile users with stochastic task arrivals and wireless channels in this paper, the design of computation offloading policies is challenging to minimize the long-term average computation cost in terms of power consumption and buffering delay. A deep reinforcement learning (DRL) based decentralized dynamic computation offloading strategy is investigated to build a scalable MEC system with limited feedback. Specifically, a continuous action space-based DRL approach named deep deterministic policy gradient (DDPG) is adopted to learn efficient computation offloading policies independently at each mobile user. Thus, powers of both local execution and task offloading can be adaptively allocated by the learned policies from each user's local observation of the MEC system. Numerical results are illustrated to demonstrate that efficient policies can be learned at each user, and performance of the proposed DDPG based decentralized strategy outperforms the conventional deep Q-network (DQN) based discrete power control strategy and some other greedy strategies with reduced computation cost. Besides, the power-delay tradeoff is also analyzed for both the DDPG based and DQN based strategies.
Gradient Adversarial Training of Neural Networks
Jun 21, 2018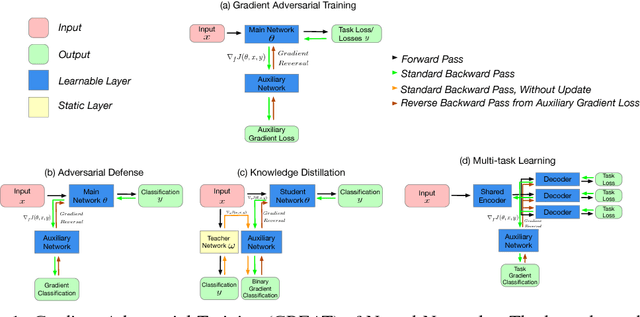
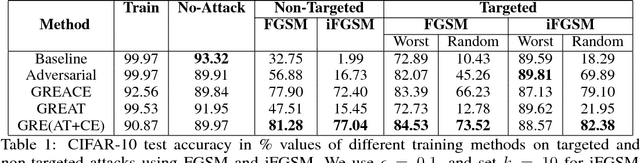
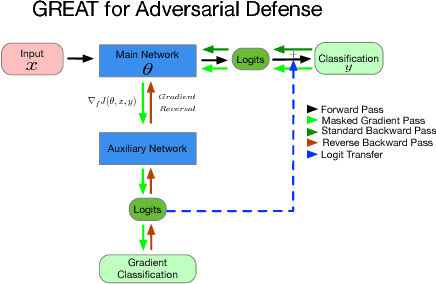
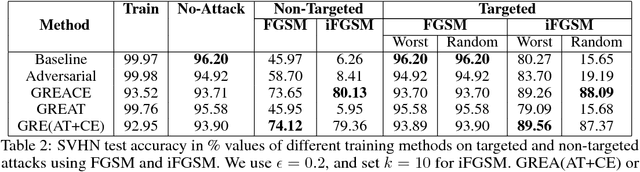
We propose gradient adversarial training, an auxiliary deep learning framework applicable to different machine learning problems. In gradient adversarial training, we leverage a prior belief that in many contexts, simultaneous gradient updates should be statistically indistinguishable from each other. We enforce this consistency using an auxiliary network that classifies the origin of the gradient tensor, and the main network serves as an adversary to the auxiliary network in addition to performing standard task-based training. We demonstrate gradient adversarial training for three different scenarios: (1) as a defense to adversarial examples we classify gradient tensors and tune them to be agnostic to the class of their corresponding example, (2) for knowledge distillation, we do binary classification of gradient tensors derived from the student or teacher network and tune the student gradient tensor to mimic the teacher's gradient tensor; and (3) for multi-task learning we classify the gradient tensors derived from different task loss functions and tune them to be statistically indistinguishable. For each of the three scenarios we show the potential of gradient adversarial training procedure. Specifically, gradient adversarial training increases the robustness of a network to adversarial attacks, is able to better distill the knowledge from a teacher network to a student network compared to soft targets, and boosts multi-task learning by aligning the gradient tensors derived from the task specific loss functions. Overall, our experiments demonstrate that gradient tensors contain latent information about whatever tasks are being trained, and can support diverse machine learning problems when intelligently guided through adversarialization using a auxiliary network.