 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Is Not All You Need: Aligning Perception with Language Models
Mar 01, 2023



A big convergence of language, multimodal perception, action, and world modeling is a key step toward artificial general intelligence. In this work, we introduce Kosmos-1, a Multimodal Large Language Model (MLLM) that can perceive general modalities, learn in context (i.e., few-shot), and follow instructions (i.e., zero-shot). Specifically, we train Kosmos-1 from scratch on web-scale multimodal corpora, including arbitrarily interleaved text and images, image-caption pairs, and text data. We evaluate various settings, including zero-shot, few-shot, and multimodal chain-of-thought prompting, on a wide range of tasks without any gradient updates or finetuning. Experimental results show that Kosmos-1 achieves impressive performance on (i) language understanding, generation, and even OCR-free NLP (directly fed with document images), (ii) perception-language tasks, including multimodal dialogue, image captioning, visual question answering, and (iii) vision tasks, such as image recognition with descriptions (specifying classification via text instructions). We also show that MLLMs can benefit from cross-modal transfer, i.e., transfer knowledge from language to multimodal, and from multimodal to language. In addition, we introduce a dataset of Raven IQ test, which diagnoses the nonverbal reasoning capability of MLLMs.
Optimizing Prompts for Text-to-Image Generation
Dec 19, 2022



Well-designed prompts can guide text-to-image models to generate amazing images. However, the performant prompts are often model-specific and misaligned with user input. Instead of laborious human engineering, we propose prompt adaptation, a general framework that automatically adapts original user input to model-preferred prompts. Specifically, we first perform supervised fine-tuning with a pretrained language model on a small collection of manually engineered prompts. Then we use reinforcement learning to explore better prompts. We define a reward function that encourages the policy to generate more aesthetically pleasing images while preserving the original user intentions. Experimental results on Stable Diffusion show that our method outperforms manual prompt engineering in terms of both automatic metrics and human preference ratings. Moreover, reinforcement learning further boosts performance, especially on out-of-domain prompts. The pretrained checkpoints are available at https://aka.ms/promptist. The demo can be found at https://aka.ms/promptist-demo.
Bridging The Gap: Entailment Fused-T5 for Open-retrieval Conversational Machine Reading Comprehension
Dec 19, 2022Open-retrieval conversational machine reading comprehension (OCMRC) simulates real-life conversational interaction scenes. Machines are required to make a decision of "Yes/No/Inquire" or generate a follow-up question when the decision is "Inquire" based on retrieved rule texts, user scenario, user question, and dialogue history. Recent studies explored the methods to reduce the information gap between decision-making and question generation and thus improve the performance of generation. However, the information gap still exists because these pipeline structures are still limited in decision-making, span extraction, and question rephrasing three stages. Decision-making and generation are reasoning separately, and the entailment reasoning utilized in decision-making is hard to share through all stages. To tackle the above problem, we proposed a novel one-stage end-to-end framework, called Entailment Fused-T5 (EFT), to bridge the information gap between decision-making and generation in a global understanding manner. The extensive experimental results demonstrate that our proposed framework achieves new state-of-the-art performance on the OR-ShARC benchmark.
TorchScale: Transformers at Scale
Nov 23, 2022Large Transformers have achieved state-of-the-art performance across many tasks. Most open-source libraries on scaling Transformers focus on improving training or inference with better parallelization. In this work, we present TorchScale, an open-source toolkit that allows researchers and developers to scale up Transformers efficiently and effectively. TorchScale has the implementation of several modeling techniques, which can improve modeling generality and capability, as well as training stability and efficiency. Experimental results on language modeling and neural machine translation demonstrate that TorchScale can successfully scale Transformers to different sizes without tears. The library is available at https://aka.ms/torchscale.
Beyond English-Centric Bitexts for Better Multilingual Language Representation Learning
Oct 26, 2022



In this paper, we elaborate upon recipes for building multilingual representation models that are not only competitive with existing state-of-the-art models but are also more parameter efficient, thereby promoting better adoption in resource-constrained scenarios and practical applications. We show that going beyond English-centric bitexts, coupled with a novel sampling strategy aimed at reducing under-utilization of training data, substantially boosts performance across model sizes for both Electra and MLM pre-training objectives. We introduce XY-LENT: X-Y bitext enhanced Language ENcodings using Transformers which not only achieves state-of-the-art performance over 5 cross-lingual tasks within all model size bands, is also competitive across bands. Our XY-LENT XL variant outperforms XLM-RXXL and exhibits competitive performance with mT5 XXL while being 5x and 6x smaller respectively. We then show that our proposed method helps ameliorate the curse of multilinguality, with the XY-LENT XL achieving 99.3% GLUE performance and 98.5% SQuAD 2.0 performance compared to a SoTA English only model in the same size band. We then analyze our models performance on extremely low resource languages and posit that scaling alone may not be sufficient for improving the performance in this scenario
ET5: A Novel End-to-end Framework for Conversational Machine Reading Comprehension
Sep 23, 2022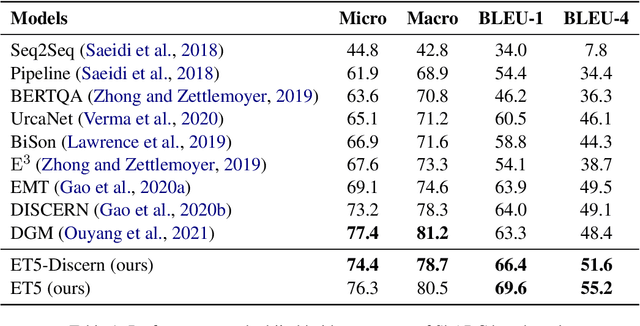
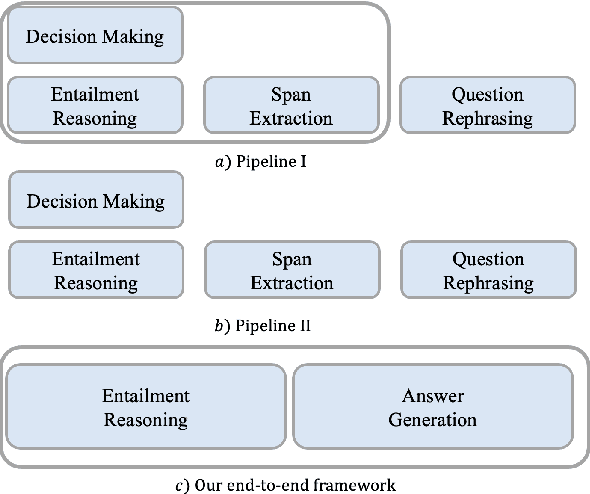
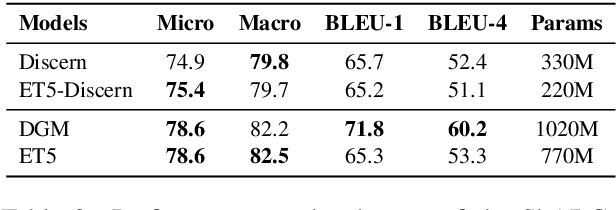
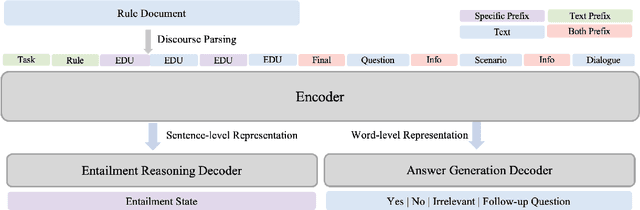
Conversational machine reading comprehension (CMRC) aims to assist computers to understand an natural language text and thereafter engage in a multi-turn conversation to answer questions related to the text. Existing methods typically require three steps: (1) decision making based on entailment reasoning; (2) span extraction if required by the above decision; (3) question rephrasing based on the extracted span. However, for nearly all these methods, the span extraction and question rephrasing steps cannot fully exploit the fine-grained entailment reasoning information in decision making step because of their relative independence, which will further enlarge the information gap between decision making and question phrasing. Thus, to tackle this problem, we propose a novel end-to-end framework for conversational machine reading comprehension based on shared parameter mechanism, called entailment reasoning T5 (ET5). Despite the lightweight of our proposed framework, experimental results show that the proposed ET5 achieves new state-of-the-art results on the ShARC leaderboard with the BLEU-4 score of 55.2. Our model and code are publicly available at https://github.com/Yottaxx/ET5.
Unsupervised Question Answering via Answer Diversifying
Aug 23, 2022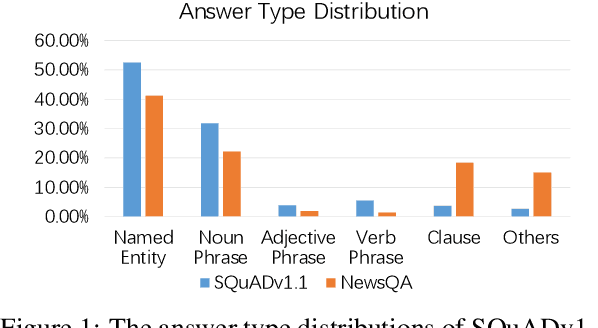
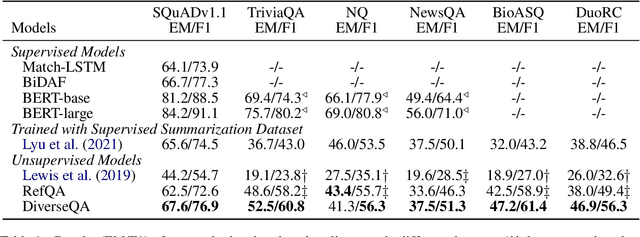
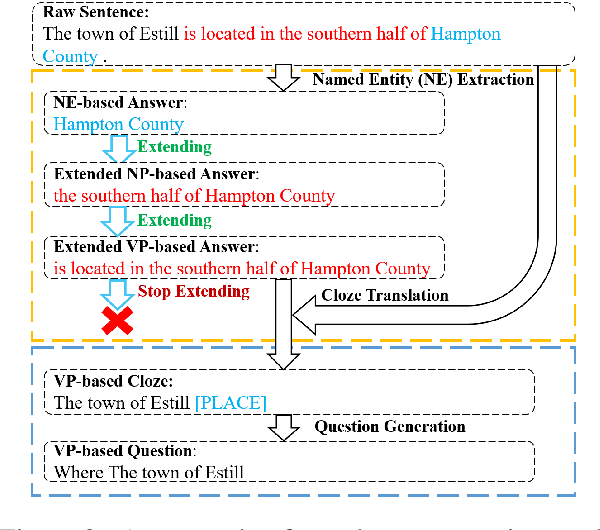
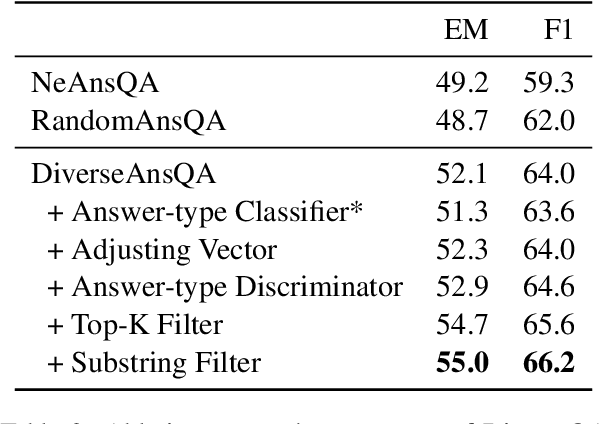
Unsupervised question answering is an attractive task due to its independence on labeled data. Previous works usually make use of heuristic rules as well as pre-trained models to construct data and train QA models. However, most of these works regard named entity (NE) as the only answer type, which ignores the high diversity of answers in the real world. To tackle this problem, we propose a novel unsupervised method by diversifying answers, named DiverseQA. Specifically, the proposed method is composed of three modules: data construction, data augmentation and denoising filter. Firstly, the data construction module extends the extracted named entity into a longer sentence constituent as the new answer span to construct a QA dataset with diverse answers. Secondly, the data augmentation module adopts an answer-type dependent data augmentation process via adversarial training in the embedding level. Thirdly, the denoising filter module is designed to alleviate the noise in the constructed data. Extensive experiments show that the proposed method outperforms previous unsupervised models on five benchmark datasets, including SQuADv1.1, NewsQA, TriviaQA, BioASQ, and DuoRC. Besides, the proposed method shows strong performance in the few-shot learning setting.
Language Models are General-Purpose Interfaces
Jun 13, 2022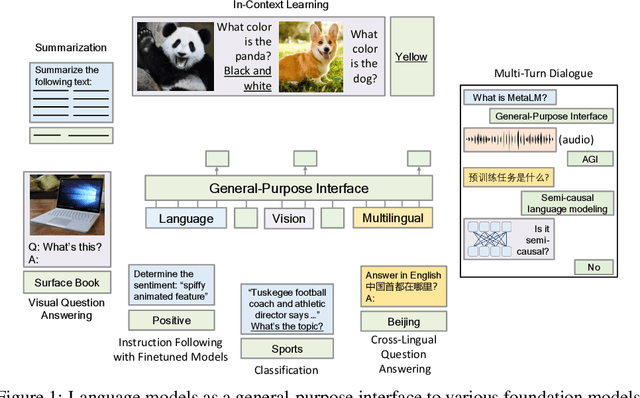

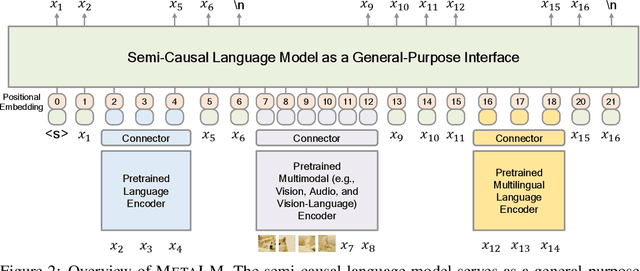
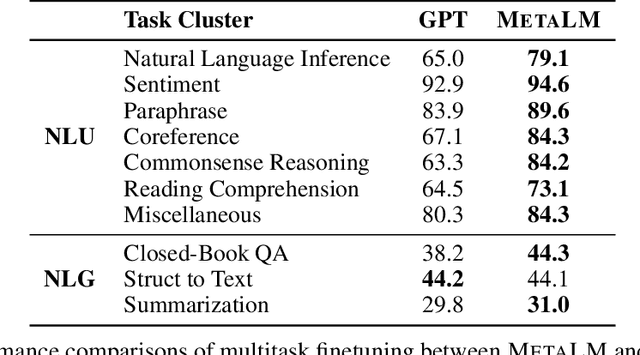
Foundation models have received much attention due to their effectiveness across a broad range of downstream applications. Though there is a big convergence in terms of architecture, most pretrained models are typically still developed for specific tasks or modalities. In this work, we propose to use language models as a general-purpose interface to various foundation models. A collection of pretrained encoders perceive diverse modalities (such as vision, and language), and they dock with a language model that plays the role of a universal task layer. We propose a semi-causal language modeling objective to jointly pretrain the interface and the modular encoders. We subsume the advantages and capabilities from both causal and non-causal modeling, thereby combining the best of two worlds. Specifically, the proposed method not only inherits the capabilities of in-context learning and open-ended generation from causal language modeling, but also is conducive to finetuning because of the bidirectional encoders. More importantly, our approach seamlessly unlocks the combinations of the above capabilities, e.g., enabling in-context learning or instruction following with finetuned encoders. Experimental results across various language-only and vision-language benchmarks show that our model outperforms or is competitive with specialized models on finetuning, zero-shot generalization, and few-shot learning.
On the Representation Collapse of Sparse Mixture of Experts
Apr 20, 2022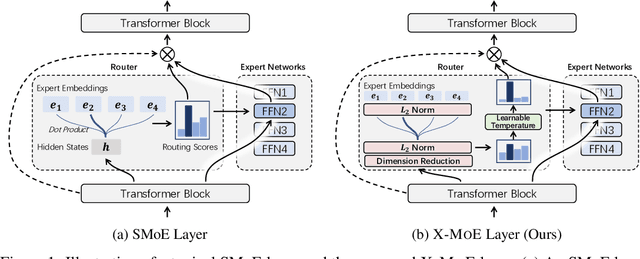
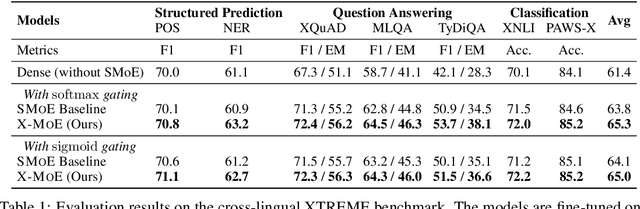
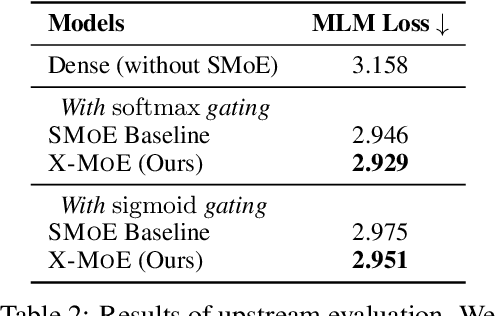
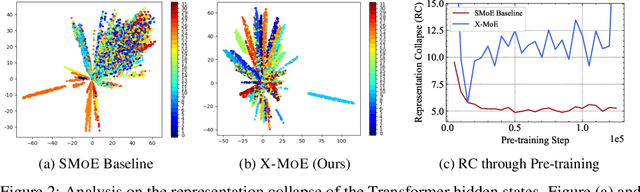
Sparse mixture of experts provides larger model capacity while requiring a constant computational overhead. It employs the routing mechanism to distribute input tokens to the best-matched experts according to their hidden representations. However, learning such a routing mechanism encourages token clustering around expert centroids, implying a trend toward representation collapse. In this work, we propose to estimate the routing scores between tokens and experts on a low-dimensional hypersphere. We conduct extensive experiments on cross-lingual language model pre-training and fine-tuning on downstream tasks. Experimental results across seven multilingual benchmarks show that our method achieves consistent gains. We also present a comprehensive analysis on the representation and routing behaviors of our models. Our method alleviates the representation collapse issue and achieves more consistent routing than the baseline mixture-of-experts methods.
Cross-Lingual Phrase Retrieval
Apr 19, 2022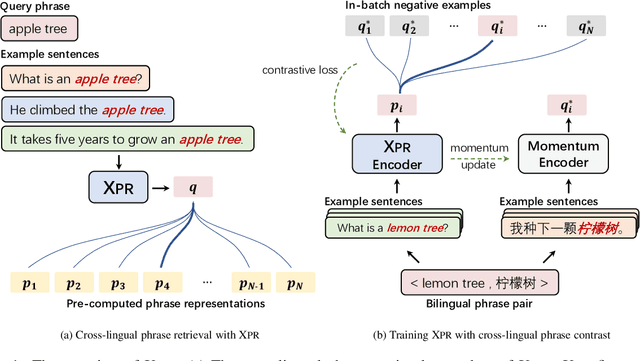

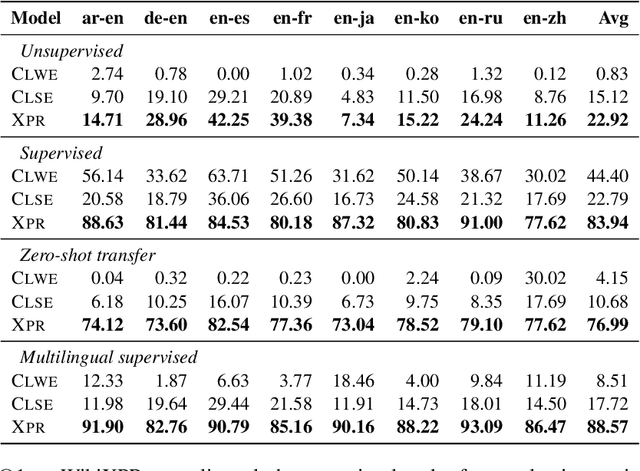
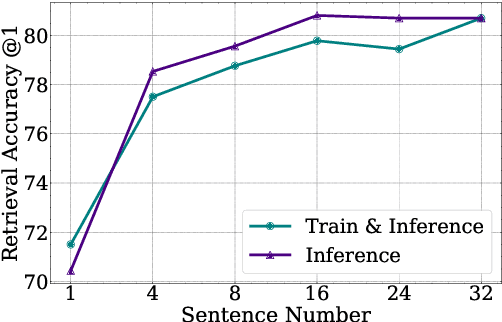
Cross-lingual retrieval aims to retrieve relevant text across languages. Current methods typically achieve cross-lingual retrieval by learning language-agnostic text representations in word or sentence level. However, how to learn phrase representations for cross-lingual phrase retrieval is still an open problem. In this paper, we propose XPR, a cross-lingual phrase retriever that extracts phrase representations from unlabeled example sentences. Moreover, we create a large-scale cross-lingual phrase retrieval dataset, which contains 65K bilingual phrase pairs and 4.2M example sentences in 8 English-centric language pairs. Experimental results show that XPR outperforms state-of-the-art baselines which utilize word-level or sentence-level representations. XPR also shows impressive zero-shot transferability that enables the model to perform retrieval in an unseen language pair during training. Our dataset, code, and trained models are publicly available at www.github.com/cwszz/XPR/.