 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCribriform pattern detection in prostate histopathological images using deep learning models
Oct 09, 2019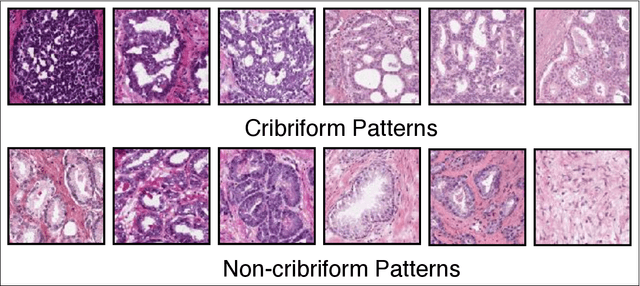
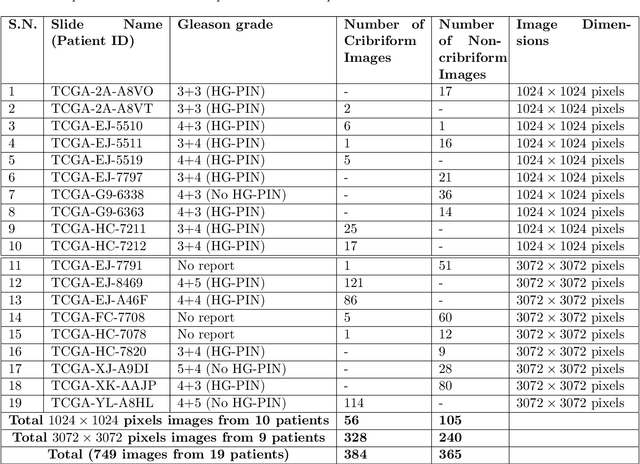
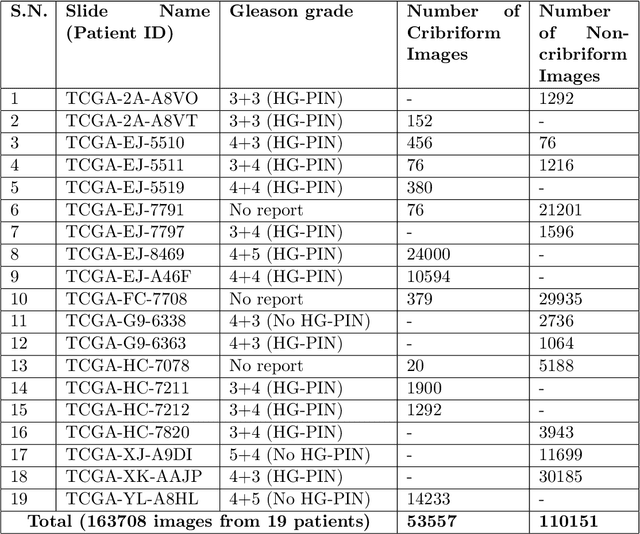
Architecture, size, and shape of glands are most important patterns used by pathologists for assessment of cancer malignancy in prostate histopathological tissue slides. Varying structures of glands along with cumbersome manual observations may result in subjective and inconsistent assessment. Cribriform gland with irregular border is an important feature in Gleason pattern 4. We propose using deep neural networks for cribriform pattern classification in prostate histopathological images. $163708$ Hematoxylin and Eosin (H\&E) stained images were extracted from histopathologic tissue slides of $19$ patients with prostate cancer and annotated for cribriform patterns. Our automated image classification system analyses the H\&E images to classify them as either `Cribriform' or `Non-cribriform'. Our system uses various deep learning approaches and hand-crafted image pixel intensity-based features. We present our results for cribriform pattern detection across various parameters and configuration allowed by our system. The combination of fine-tuned deep learning models outperformed the state-of-art nuclei feature based methods. Our image classification system achieved the testing accuracy of $85.93~\pm~7.54$ (cross-validated) and $88.04~\pm~5.63$ ( additional unseen test set) across three folds. In this paper, we present an annotated cribriform dataset along with analysis of deep learning models and hand-crafted features for cribriform pattern detection in prostate histopathological images.
Robust Regression via Deep Negative Correlation Learning
Aug 24, 2019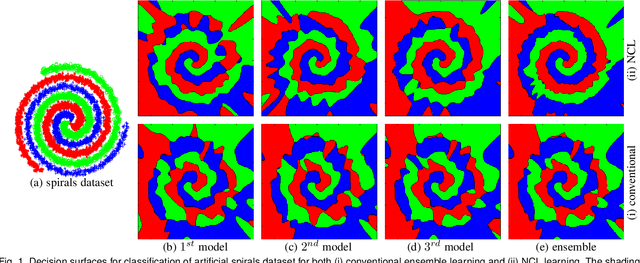
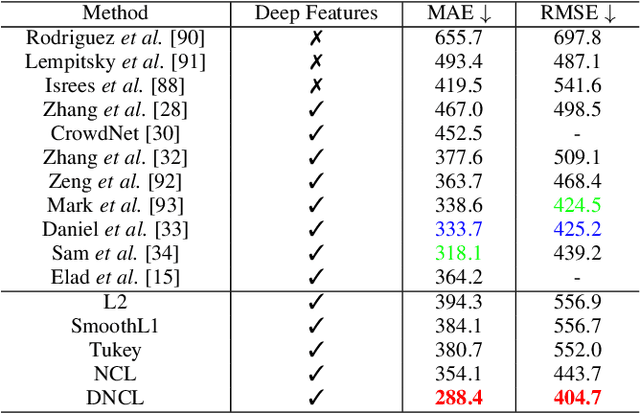
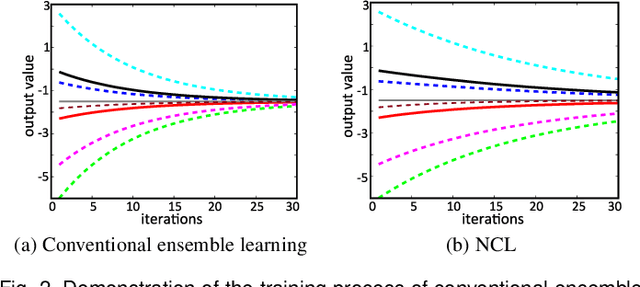
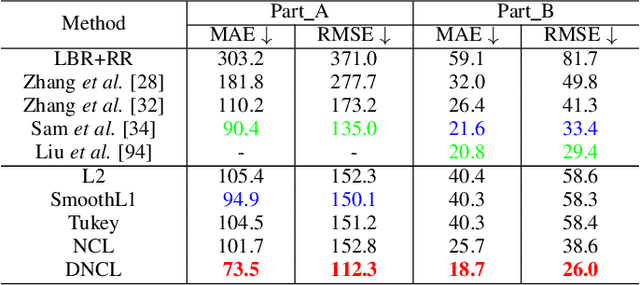
Nonlinear regression has been extensively employed in many computer vision problems (e.g., crowd counting, age estimation, affective computing). Under the umbrella of deep learning, two common solutions exist i) transforming nonlinear regression to a robust loss function which is jointly optimizable with the deep convolutional network, and ii) utilizing ensemble of deep networks. Although some improved performance is achieved, the former may be lacking due to the intrinsic limitation of choosing a single hypothesis and the latter usually suffers from much larger computational complexity. To cope with those issues, we propose to regress via an efficient "divide and conquer" manner. The core of our approach is the generalization of negative correlation learning that has been shown, both theoretically and empirically, to work well for non-deep regression problems. Without extra parameters, the proposed method controls the bias-variance-covariance trade-off systematically and usually yields a deep regression ensemble where each base model is both "accurate" and "diversified". Moreover, we show that each sub-problem in the proposed method has less Rademacher Complexity and thus is easier to optimize. Extensive experiments on several diverse and challenging tasks including crowd counting, personality analysis, age estimation, and image super-resolution demonstrate the superiority over challenging baselines as well as the versatility of the proposed method.
A Deep Framework for Bone Age Assessment based on Finger Joint Localization
May 07, 2019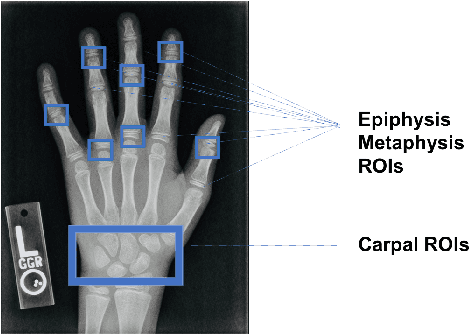
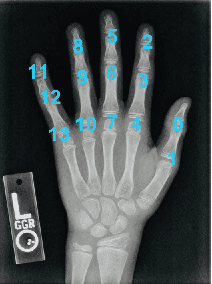
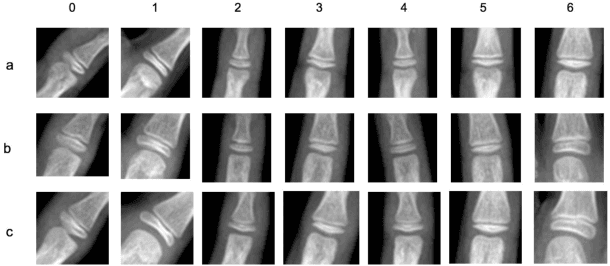
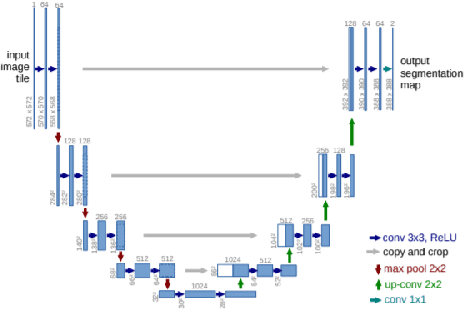
Bone age assessment is an important clinical trial to measure skeletal child maturity and diagnose of growth disorders. Conventional approaches such as the Tanner-Whitehouse (TW) and Greulich and Pyle (GP) may not perform well due to their large inter-observer and intra-observer variations. In this paper, we propose a finger joint localization strategy to filter out most non-informative parts of images. When combining with the conventional full image-based deep network, we observe a much-improved performance. % Our approach utilizes full hand and specific joints images for skeletal maturity prediction. In this study, we applied powerful deep neural network and explored a process in the forecast of skeletal bone age with the specifically combine joints images to increase the performance accuracy compared with the whole hand images.
Semi-Supervised Self-Taught Deep Learning for Finger Bones Segmentation
Mar 12, 2019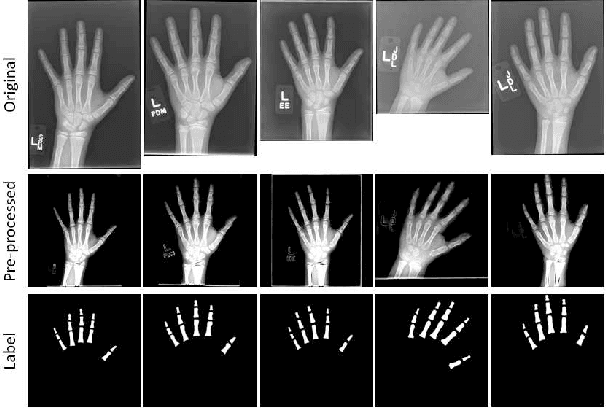
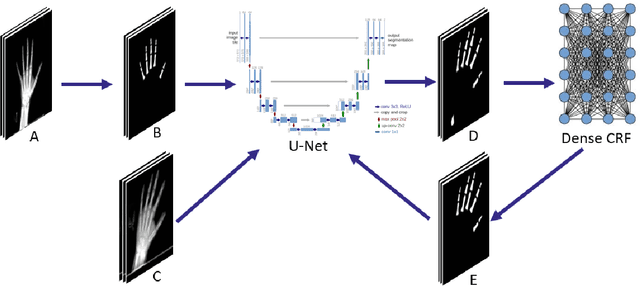
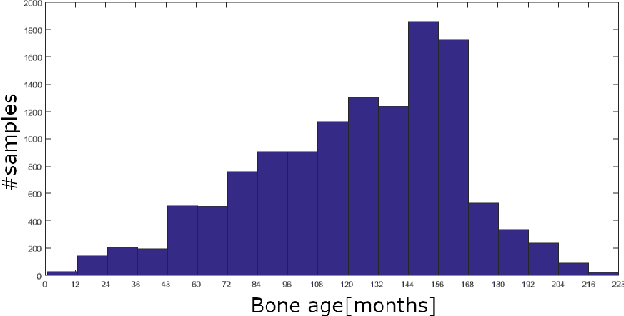
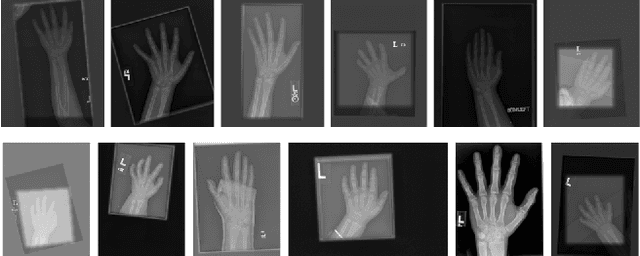
Segmentation stands at the forefront of many high-level vision tasks. In this study, we focus on segmenting finger bones within a newly introduced semi-supervised self-taught deep learning framework which consists of a student network and a stand-alone teacher module. The whole system is boosted in a life-long learning manner wherein each step the teacher module provides a refinement for the student network to learn with newly unlabeled data. Experimental results demonstrate the superiority of the proposed method over conventional supervised deep learning methods.
Graph Convolutional Neural Networks for Polymers Property Prediction
Nov 15, 2018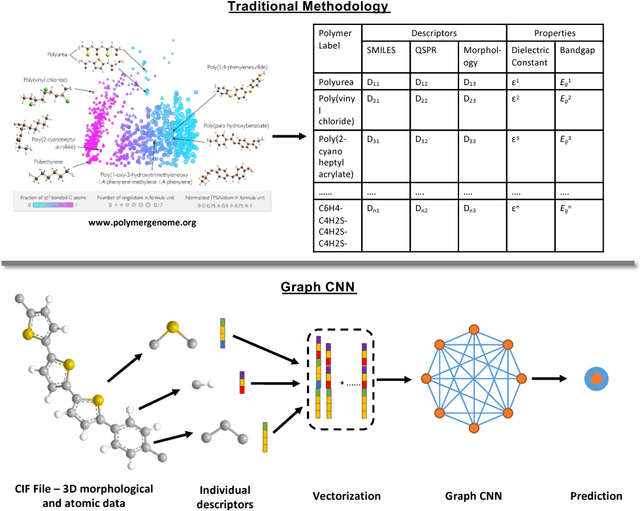
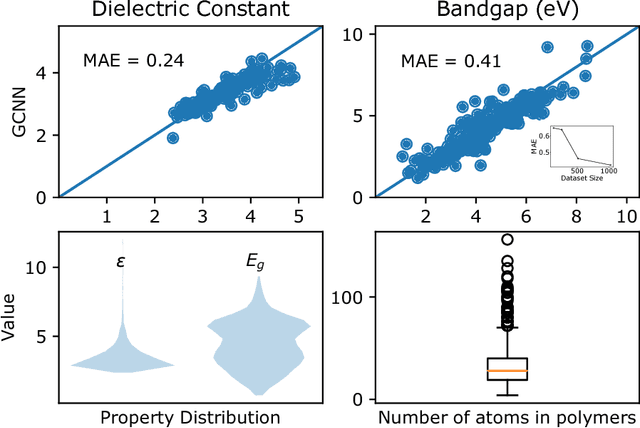

A fast and accurate predictive tool for polymer properties is demanding and will pave the way to iterative inverse design. In this work, we apply graph convolutional neural networks (GCNN) to predict the dielectric constant and energy bandgap of polymers. Using density functional theory (DFT) calculated properties as the ground truth, GCNN can achieve remarkable agreement with DFT results. Moreover, we show that GCNN outperforms other machine learning algorithms. Our work proves that GCNN relies only on morphological data of polymers and removes the requirement for complicated hand-crafted descriptors, while still offering accuracy in fast predictions.
End-to-End Video Classification with Knowledge Graphs
Nov 06, 2017


Video understanding has attracted much research attention especially since the recent availability of large-scale video benchmarks. In this paper, we address the problem of multi-label video classification. We first observe that there exists a significant knowledge gap between how machines and humans learn. That is, while current machine learning approaches including deep neural networks largely focus on the representations of the given data, humans often look beyond the data at hand and leverage external knowledge to make better decisions. Towards narrowing the gap, we propose to incorporate external knowledge graphs into video classification. In particular, we unify traditional "knowledgeless" machine learning models and knowledge graphs in a novel end-to-end framework. The framework is flexible to work with most existing video classification algorithms including state-of-the-art deep models. Finally, we conduct extensive experiments on the largest public video dataset YouTube-8M. The results are promising across the board, improving mean average precision by up to 2.9%.
Truly Multi-modal YouTube-8M Video Classification with Video, Audio, and Text
Jul 10, 2017
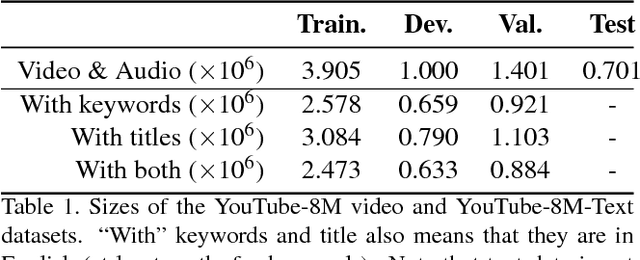
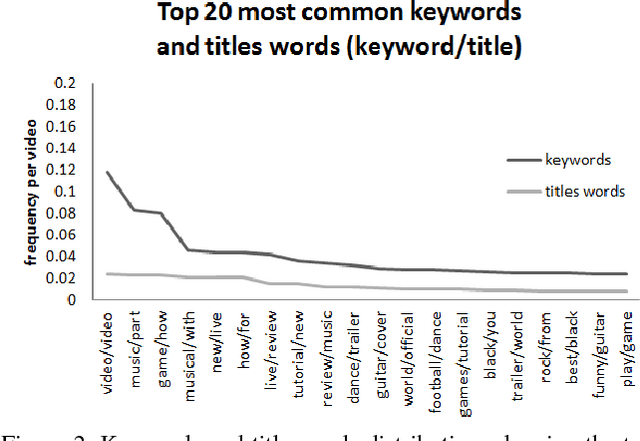

The YouTube-8M video classification challenge requires teams to classify 0.7 million videos into one or more of 4,716 classes. In this Kaggle competition, we placed in the top 3% out of 650 participants using released video and audio features. Beyond that, we extend the original competition by including text information in the classification, making this a truly multi-modal approach with vision, audio and text. The newly introduced text data is termed as YouTube-8M-Text. We present a classification framework for the joint use of text, visual and audio features, and conduct an extensive set of experiments to quantify the benefit that this additional mode brings. The inclusion of text yields state-of-the-art results, e.g. 86.7% GAP on the YouTube-8M-Text validation dataset.
Deep Learning for Lung Cancer Detection: Tackling the Kaggle Data Science Bowl 2017 Challenge
May 26, 2017
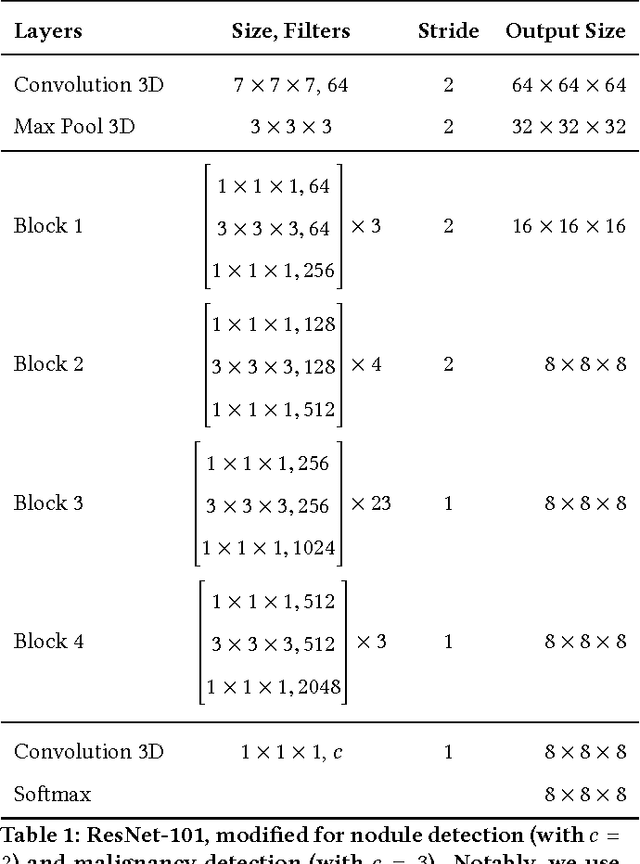
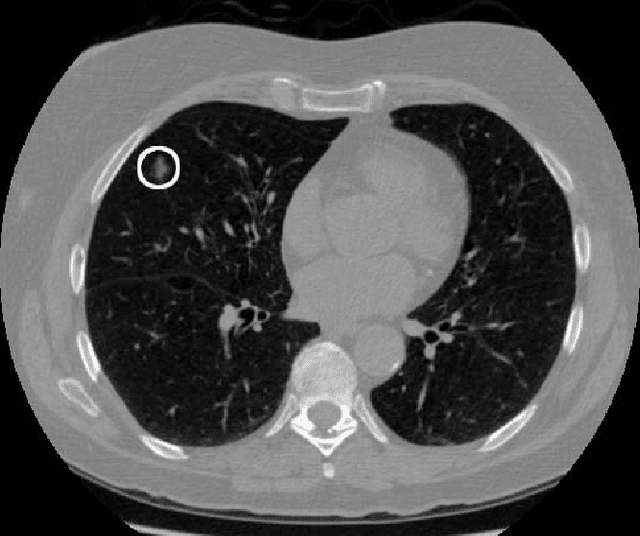
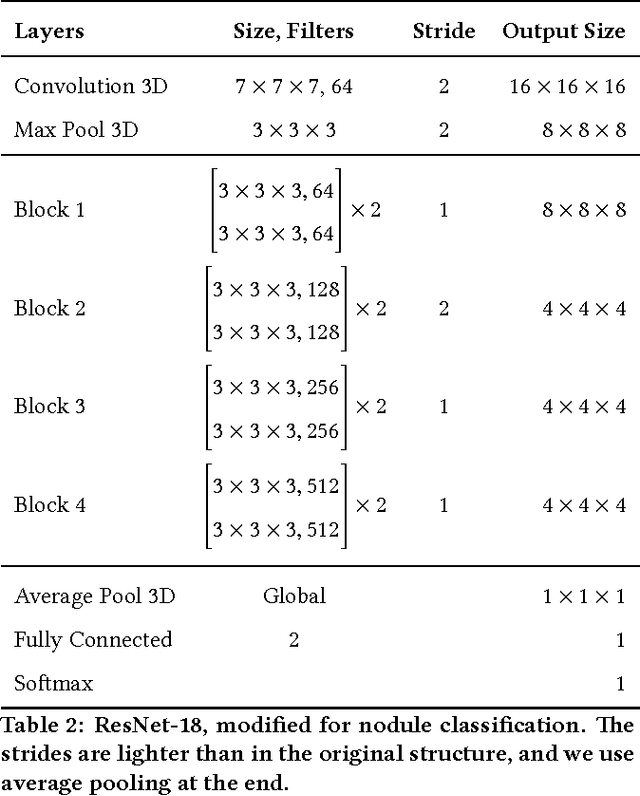
We present a deep learning framework for computer-aided lung cancer diagnosis. Our multi-stage framework detects nodules in 3D lung CAT scans, determines if each nodule is malignant, and finally assigns a cancer probability based on these results. We discuss the challenges and advantages of our framework. In the Kaggle Data Science Bowl 2017, our framework ranked 41st out of 1972 teams.
A Novel Multi-task Deep Learning Model for Skin Lesion Segmentation and Classification
Mar 03, 2017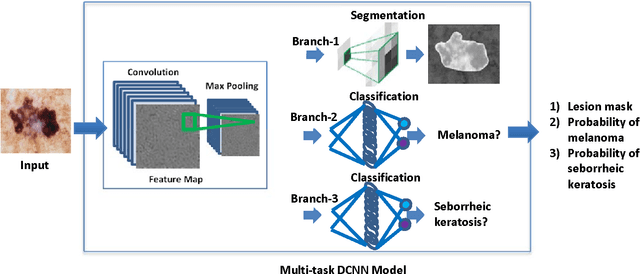

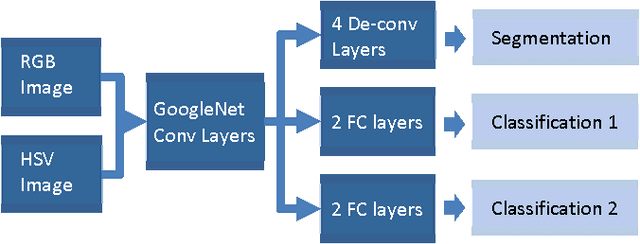

In this study, a multi-task deep neural network is proposed for skin lesion analysis. The proposed multi-task learning model solves different tasks (e.g., lesion segmentation and two independent binary lesion classifications) at the same time by exploiting commonalities and differences across tasks. This results in improved learning efficiency and potential prediction accuracy for the task-specific models, when compared to training the individual models separately. The proposed multi-task deep learning model is trained and evaluated on the dermoscopic image sets from the International Skin Imaging Collaboration (ISIC) 2017 Challenge - Skin Lesion Analysis towards Melanoma Detection, which consists of 2000 training samples and 150 evaluation samples. The experimental results show that the proposed multi-task deep learning model achieves promising performances on skin lesion segmentation and classification. The average value of Jaccard index for lesion segmentation is 0.724, while the average values of area under the receiver operating characteristic curve (AUC) on two individual lesion classifications are 0.880 and 0.972, respectively.