 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Instance-Level Representation for Large-Scale Multi-Modal Pretraining in E-commerce
Apr 06, 2023



This paper aims to establish a generic multi-modal foundation model that has the scalable capability to massive downstream applications in E-commerce. Recently, large-scale vision-language pretraining approaches have achieved remarkable advances in the general domain. However, due to the significant differences between natural and product images, directly applying these frameworks for modeling image-level representations to E-commerce will be inevitably sub-optimal. To this end, we propose an instance-centric multi-modal pretraining paradigm called ECLIP in this work. In detail, we craft a decoder architecture that introduces a set of learnable instance queries to explicitly aggregate instance-level semantics. Moreover, to enable the model to focus on the desired product instance without reliance on expensive manual annotations, two specially configured pretext tasks are further proposed. Pretrained on the 100 million E-commerce-related data, ECLIP successfully extracts more generic, semantic-rich, and robust representations. Extensive experimental results show that, without further fine-tuning, ECLIP surpasses existing methods by a large margin on a broad range of downstream tasks, demonstrating the strong transferability to real-world E-commerce applications.
Multi-Level Contrastive Learning for Dense Prediction Task
Apr 04, 2023



In this work, we present Multi-Level Contrastive Learning for Dense Prediction Task (MCL), an efficient self-supervised method for learning region-level feature representation for dense prediction tasks. Our method is motivated by the three key factors in detection: localization, scale consistency and recognition. To explicitly encode absolute position and scale information, we propose a novel pretext task that assembles multi-scale images in a montage manner to mimic multi-object scenarios. Unlike the existing image-level self-supervised methods, our method constructs a multi-level contrastive loss that considers each sub-region of the montage image as a singleton. Our method enables the neural network to learn regional semantic representations for translation and scale consistency while reducing pre-training epochs to the same as supervised pre-training. Extensive experiments demonstrate that MCL consistently outperforms the recent state-of-the-art methods on various datasets with significant margins. In particular, MCL obtains 42.5 AP$^\mathrm{bb}$ and 38.3 AP$^\mathrm{mk}$ on COCO with the 1x schedule fintuning, when using Mask R-CNN with R50-FPN backbone pre-trained with 100 epochs. In comparison to MoCo, our method surpasses their performance by 4.0 AP$^\mathrm{bb}$ and 3.1 AP$^\mathrm{mk}$. Furthermore, we explore the alignment between pretext task and downstream tasks. We extend our pretext task to supervised pre-training, which achieves a similar performance to self-supervised learning. This result demonstrates the importance of the alignment between pretext task and downstream tasks, indicating the potential for wider applicability of our method beyond self-supervised settings.
Universal Instance Perception as Object Discovery and Retrieval
Mar 12, 2023



All instance perception tasks aim at finding certain objects specified by some queries such as category names, language expressions, and target annotations, but this complete field has been split into multiple independent subtasks. In this work, we present a universal instance perception model of the next generation, termed UNINEXT. UNINEXT reformulates diverse instance perception tasks into a unified object discovery and retrieval paradigm and can flexibly perceive different types of objects by simply changing the input prompts. This unified formulation brings the following benefits: (1) enormous data from different tasks and label vocabularies can be exploited for jointly training general instance-level representations, which is especially beneficial for tasks lacking in training data. (2) the unified model is parameter-efficient and can save redundant computation when handling multiple tasks simultaneously. UNINEXT shows superior performance on 20 challenging benchmarks from 10 instance-level tasks including classical image-level tasks (object detection and instance segmentation), vision-and-language tasks (referring expression comprehension and segmentation), and six video-level object tracking tasks. Code is available at https://github.com/MasterBin-IIAU/UNINEXT.
Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling
Jan 10, 2023



We identify and overcome two key obstacles in extending the success of BERT-style pre-training, or the masked image modeling, to convolutional networks (convnets): (i) convolution operation cannot handle irregular, random-masked input images; (ii) the single-scale nature of BERT pre-training is inconsistent with convnet's hierarchical structure. For (i), we treat unmasked pixels as sparse voxels of 3D point clouds and use sparse convolution to encode. This is the first use of sparse convolution for 2D masked modeling. For (ii), we develop a hierarchical decoder to reconstruct images from multi-scale encoded features. Our method called Sparse masKed modeling (SparK) is general: it can be used directly on any convolutional model without backbone modifications. We validate it on both classical (ResNet) and modern (ConvNeXt) models: on three downstream tasks, it surpasses both state-of-the-art contrastive learning and transformer-based masked modeling by similarly large margins (around +1.0%). Improvements on object detection and instance segmentation are more substantial (up to +3.5%), verifying the strong transferability of features learned. We also find its favorable scaling behavior by observing more gains on larger models. All this evidence reveals a promising future of generative pre-training on convnets. Codes and models are released at https://github.com/keyu-tian/SparK.
QueryPose: Sparse Multi-Person Pose Regression via Spatial-Aware Part-Level Query
Dec 15, 2022



We propose a sparse end-to-end multi-person pose regression framework, termed QueryPose, which can directly predict multi-person keypoint sequences from the input image. The existing end-to-end methods rely on dense representations to preserve the spatial detail and structure for precise keypoint localization. However, the dense paradigm introduces complex and redundant post-processes during inference. In our framework, each human instance is encoded by several learnable spatial-aware part-level queries associated with an instance-level query. First, we propose the Spatial Part Embedding Generation Module (SPEGM) that considers the local spatial attention mechanism to generate several spatial-sensitive part embeddings, which contain spatial details and structural information for enhancing the part-level queries. Second, we introduce the Selective Iteration Module (SIM) to adaptively update the sparse part-level queries via the generated spatial-sensitive part embeddings stage-by-stage. Based on the two proposed modules, the part-level queries are able to fully encode the spatial details and structural information for precise keypoint regression. With the bipartite matching, QueryPose avoids the hand-designed post-processes and surpasses the existing dense end-to-end methods with 73.6 AP on MS COCO mini-val set and 72.7 AP on CrowdPose test set. Code is available at https://github.com/buptxyb666/QueryPose.
Learning Object-Language Alignments for Open-Vocabulary Object Detection
Nov 27, 2022Existing object detection methods are bounded in a fixed-set vocabulary by costly labeled data. When dealing with novel categories, the model has to be retrained with more bounding box annotations. Natural language supervision is an attractive alternative for its annotation-free attributes and broader object concepts. However, learning open-vocabulary object detection from language is challenging since image-text pairs do not contain fine-grained object-language alignments. Previous solutions rely on either expensive grounding annotations or distilling classification-oriented vision models. In this paper, we propose a novel open-vocabulary object detection framework directly learning from image-text pair data. We formulate object-language alignment as a set matching problem between a set of image region features and a set of word embeddings. It enables us to train an open-vocabulary object detector on image-text pairs in a much simple and effective way. Extensive experiments on two benchmark datasets, COCO and LVIS, demonstrate our superior performance over the competing approaches on novel categories, e.g. achieving 32.0% mAP on COCO and 21.7% mask mAP on LVIS. Code is available at: https://github.com/clin1223/VLDet.
Self-supervised Video Representation Learning with Motion-Aware Masked Autoencoders
Oct 09, 2022
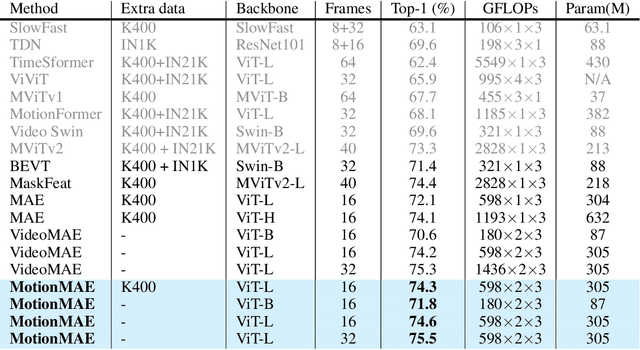
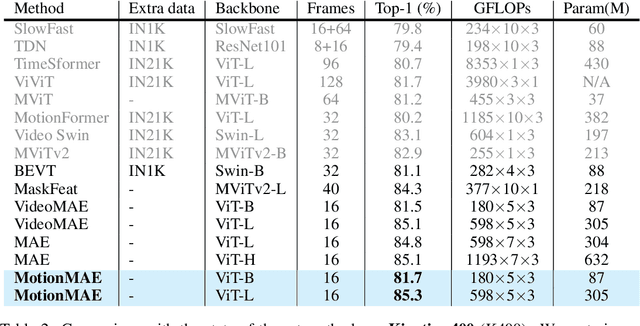
Masked autoencoders (MAEs) have emerged recently as art self-supervised spatiotemporal representation learners. Inheriting from the image counterparts, however, existing video MAEs still focus largely on static appearance learning whilst are limited in learning dynamic temporal information hence less effective for video downstream tasks. To resolve this drawback, in this work we present a motion-aware variant -- MotionMAE. Apart from learning to reconstruct individual masked patches of video frames, our model is designed to additionally predict the corresponding motion structure information over time. This motion information is available at the temporal difference of nearby frames. As a result, our model can extract effectively both static appearance and dynamic motion spontaneously, leading to superior spatiotemporal representation learning capability. Extensive experiments show that our MotionMAE outperforms significantly both supervised learning baseline and state-of-the-art MAE alternatives, under both domain-specific and domain-generic pretraining-then-finetuning settings. In particular, when using ViT-B as the backbone our MotionMAE surpasses the prior art model by a margin of 1.2% on Something-Something V2 and 3.2% on UCF101 in domain-specific pretraining setting. Encouragingly, it also surpasses the competing MAEs by a large margin of over 3% on the challenging video object segmentation task. The code is available at https://github.com/happy-hsy/MotionMAE.
MAMO: Masked Multimodal Modeling for Fine-Grained Vision-Language Representation Learning
Oct 09, 2022
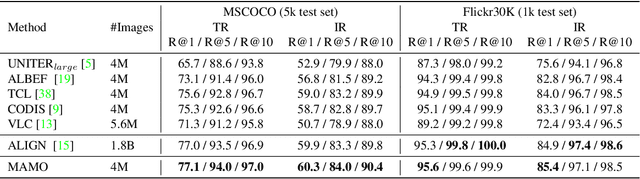
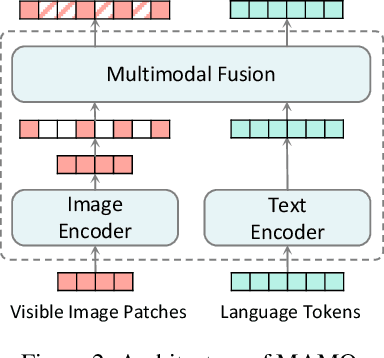
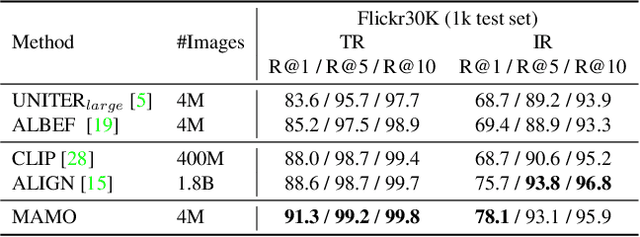
Multimodal representation learning has shown promising improvements on various vision-language tasks. Most existing methods excel at building global-level alignment between vision and language while lacking effective fine-grained image-text interaction. In this paper, we propose a jointly masked multimodal modeling method to learn fine-grained multimodal representations. Our method performs joint masking on image-text input and integrates both implicit and explicit targets for the masked signals to recover. The implicit target provides a unified and debiased objective for vision and language, where the model predicts latent multimodal representations of the unmasked input. The explicit target further enriches the multimodal representations by recovering high-level and semantically meaningful information: momentum visual features of image patches and concepts of word tokens. Through such a masked modeling process, our model not only learns fine-grained multimodal interaction, but also avoids the semantic gap between high-level representations and low- or mid-level prediction targets (e.g. image pixels), thus producing semantically rich multimodal representations that perform well on both zero-shot and fine-tuned settings. Our pre-trained model (named MAMO) achieves state-of-the-art performance on various downstream vision-language tasks, including image-text retrieval, visual question answering, visual reasoning, and weakly-supervised visual grounding.
ManiCLIP: Multi-Attribute Face Manipulation from Text
Oct 02, 2022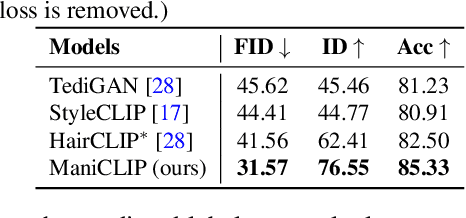


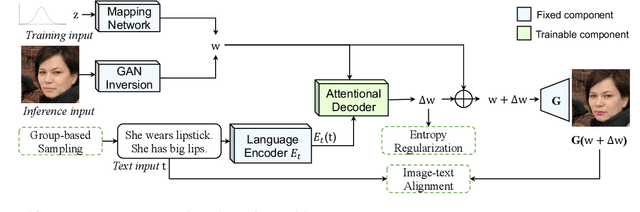
In this paper we present a novel multi-attribute face manipulation method based on textual descriptions. Previous text-based image editing methods either require test-time optimization for each individual image or are restricted to single attribute editing. Extending these methods to multi-attribute face image editing scenarios will introduce undesired excessive attribute change, e.g., text-relevant attributes are overly manipulated and text-irrelevant attributes are also changed. In order to address these challenges and achieve natural editing over multiple face attributes, we propose a new decoupling training scheme where we use group sampling to get text segments from same attribute categories, instead of whole complex sentences. Further, to preserve other existing face attributes, we encourage the model to edit the latent code of each attribute separately via a entropy constraint. During the inference phase, our model is able to edit new face images without any test-time optimization, even from complex textual prompts. We show extensive experiments and analysis to demonstrate the efficacy of our method, which generates natural manipulated faces with minimal text-irrelevant attribute editing. Code and pre-trained model will be released.
Embracing Consistency: A One-Stage Approach for Spatio-Temporal Video Grounding
Sep 27, 2022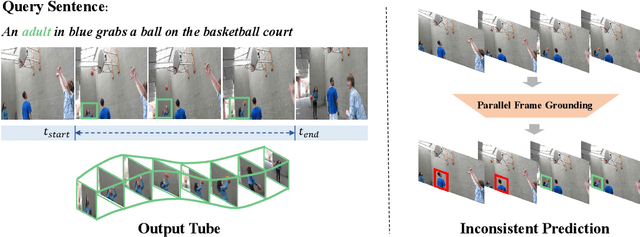
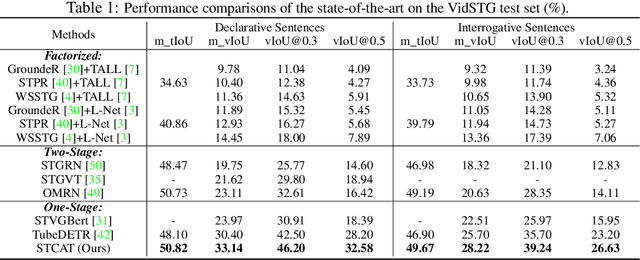
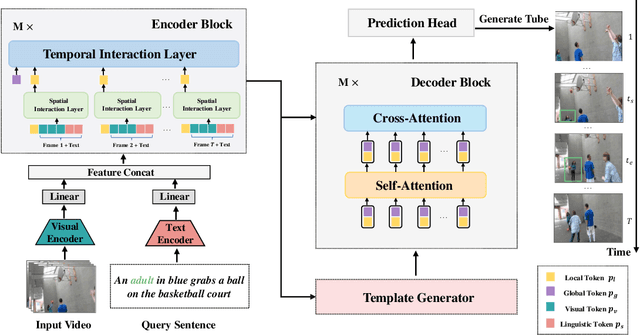

Spatio-Temporal video grounding (STVG) focuses on retrieving the spatio-temporal tube of a specific object depicted by a free-form textual expression. Existing approaches mainly treat this complicated task as a parallel frame-grounding problem and thus suffer from two types of inconsistency drawbacks: feature alignment inconsistency and prediction inconsistency. In this paper, we present an end-to-end one-stage framework, termed Spatio-Temporal Consistency-Aware Transformer (STCAT), to alleviate these issues. Specially, we introduce a novel multi-modal template as the global objective to address this task, which explicitly constricts the grounding region and associates the predictions among all video frames. Moreover, to generate the above template under sufficient video-textual perception, an encoder-decoder architecture is proposed for effective global context modeling. Thanks to these critical designs, STCAT enjoys more consistent cross-modal feature alignment and tube prediction without reliance on any pre-trained object detectors. Extensive experiments show that our method outperforms previous state-of-the-arts with clear margins on two challenging video benchmarks (VidSTG and HC-STVG), illustrating the superiority of the proposed framework to better understanding the association between vision and natural language. Code is publicly available at \url{https://github.com/jy0205/STCAT}.