 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Language Models Can Perform Many Tasks with Scaling and Instruction-Finetuning
Aug 25, 2023



The recent surge of generative AI has been fueled by the generative power of diffusion probabilistic models and the scalable capabilities of large language models. Despite their potential, it remains elusive whether diffusion language models can solve general language tasks comparable to their autoregressive counterparts. This paper demonstrates that scaling diffusion models w.r.t. data, sizes, and tasks can effectively make them strong language learners. We build competent diffusion language models at scale by first acquiring knowledge from massive data via masked language modeling pretraining thanks to their intrinsic connections. We then reprogram pretrained masked language models into diffusion language models via diffusive adaptation, wherein task-specific finetuning and instruction finetuning are explored to unlock their versatility in solving general language tasks. Experiments show that scaling diffusion language models consistently improves performance across downstream language tasks. We further discover that instruction finetuning can elicit zero-shot and few-shot in-context learning abilities that help tackle many unseen tasks by following natural language instructions, and show promise in advanced and challenging abilities such as reasoning.
DINOISER: Diffused Conditional Sequence Learning by Manipulating Noises
Feb 20, 2023



While diffusion models have achieved great success in generating continuous signals such as images and audio, it remains elusive for diffusion models in learning discrete sequence data like natural languages. Although recent advances circumvent this challenge of discreteness by embedding discrete tokens as continuous surrogates, they still fall short of satisfactory generation quality. To understand this, we first dive deep into the denoised training protocol of diffusion-based sequence generative models and determine their three severe problems, i.e., 1) failing to learn, 2) lack of scalability, and 3) neglecting source conditions. We argue that these problems can be boiled down to the pitfall of the not completely eliminated discreteness in the embedding space, and the scale of noises is decisive herein. In this paper, we introduce DINOISER to facilitate diffusion models for sequence generation by manipulating noises. We propose to adaptively determine the range of sampled noise scales for counter-discreteness training; and encourage the proposed diffused sequence learner to leverage source conditions with amplified noise scales during inference. Experiments show that DINOISER enables consistent improvement over the baselines of previous diffusion-based sequence generative models on several conditional sequence modeling benchmarks thanks to both effective training and inference strategies. Analyses further verify that DINOISER can make better use of source conditions to govern its generative process.
Structure-informed Language Models Are Protein Designers
Feb 09, 2023This paper demonstrates that language models are strong structure-based protein designers. We present LM-Design, a generic approach to reprogramming sequence-based protein language models (pLMs), that have learned massive sequential evolutionary knowledge from the universe of natural protein sequences, to acquire an immediate capability to design preferable protein sequences for given folds. We conduct a structural surgery on pLMs, where a lightweight structural adapter is implanted into pLMs and endows it with structural awareness. During inference, iterative refinement is performed to effectively optimize the generated protein sequences. Experiments show that LM-Design improves the state-of-the-art results by a large margin, leading to up to 4% to 12% accuracy gains in sequence recovery (e.g., 55.65%/56.63% on CATH 4.2/4.3 single-chain benchmarks, and >60% when designing protein complexes). We provide extensive and in-depth analyses, which verify that LM-Design can (1) indeed leverage both structural and sequential knowledge to accurately handle structurally non-deterministic regions, (2) benefit from scaling data and model size, and (3) generalize to other proteins (e.g., antibodies and de novo proteins)
Helping the Weak Makes You Strong: Simple Multi-Task Learning Improves Non-Autoregressive Translators
Nov 11, 2022



Recently, non-autoregressive (NAR) neural machine translation models have received increasing attention due to their efficient parallel decoding. However, the probabilistic framework of NAR models necessitates conditional independence assumption on target sequences, falling short of characterizing human language data. This drawback results in less informative learning signals for NAR models under conventional MLE training, thereby yielding unsatisfactory accuracy compared to their autoregressive (AR) counterparts. In this paper, we propose a simple and model-agnostic multi-task learning framework to provide more informative learning signals. During training stage, we introduce a set of sufficiently weak AR decoders that solely rely on the information provided by NAR decoder to make prediction, forcing the NAR decoder to become stronger or else it will be unable to support its weak AR partners. Experiments on WMT and IWSLT datasets show that our approach can consistently improve accuracy of multiple NAR baselines without adding any additional decoding overhead.
The Volctrans GLAT System: Non-autoregressive Translation Meets WMT21
Sep 24, 2021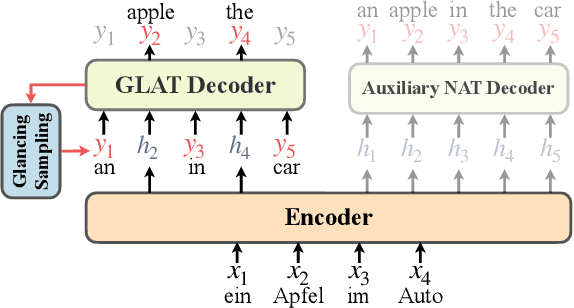
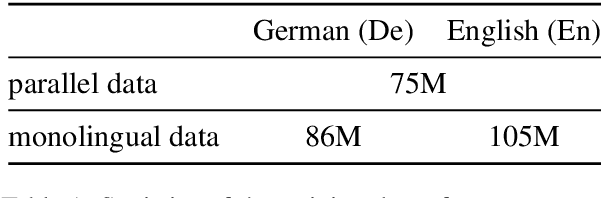
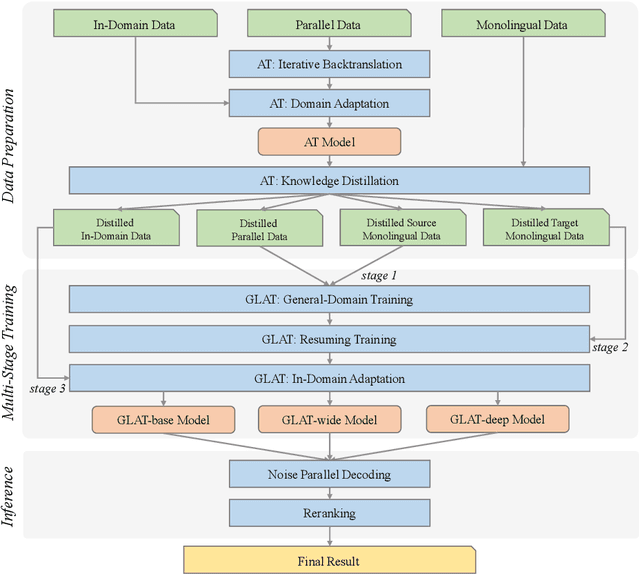
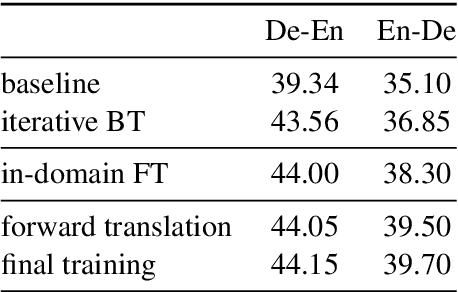
This paper describes the Volctrans' submission to the WMT21 news translation shared task for German->English translation. We build a parallel (i.e., non-autoregressive) translation system using the Glancing Transformer, which enables fast and accurate parallel decoding in contrast to the currently prevailing autoregressive models. To the best of our knowledge, this is the first parallel translation system that can be scaled to such a practical scenario like WMT competition. More importantly, our parallel translation system achieves the best BLEU score (35.0) on German->English translation task, outperforming all strong autoregressive counterparts.
DirectQE: Direct Pretraining for Machine Translation Quality Estimation
May 15, 2021
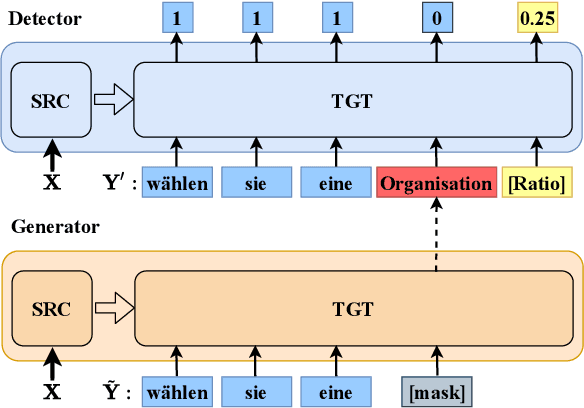
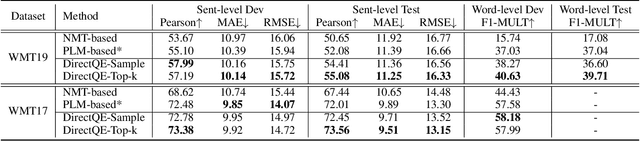
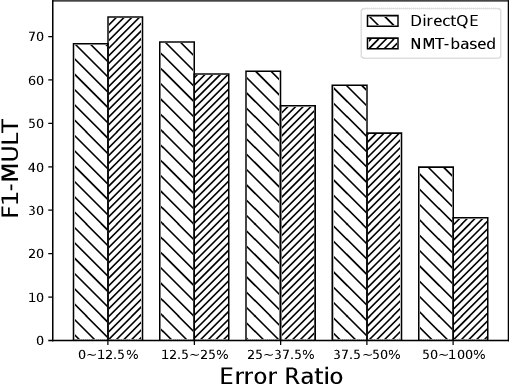
Machine Translation Quality Estimation (QE) is a task of predicting the quality of machine translations without relying on any reference. Recently, the predictor-estimator framework trains the predictor as a feature extractor, which leverages the extra parallel corpora without QE labels, achieving promising QE performance. However, we argue that there are gaps between the predictor and the estimator in both data quality and training objectives, which preclude QE models from benefiting from a large number of parallel corpora more directly. We propose a novel framework called DirectQE that provides a direct pretraining for QE tasks. In DirectQE, a generator is trained to produce pseudo data that is closer to the real QE data, and a detector is pretrained on these data with novel objectives that are akin to the QE task. Experiments on widely used benchmarks show that DirectQE outperforms existing methods, without using any pretraining models such as BERT. We also give extensive analyses showing how fixing the two gaps contributes to our improvements.
Duplex Sequence-to-Sequence Learning for Reversible Machine Translation
May 07, 2021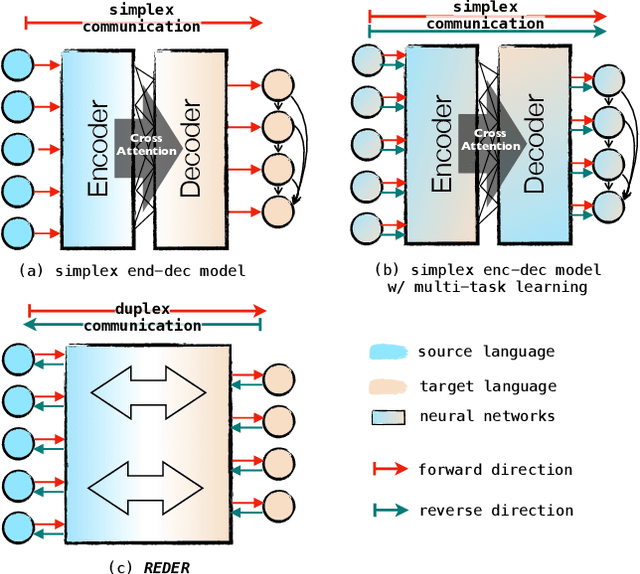
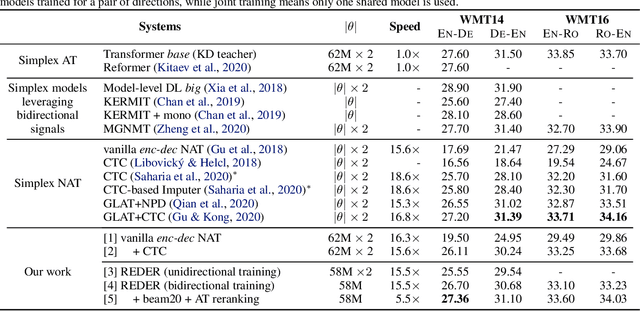
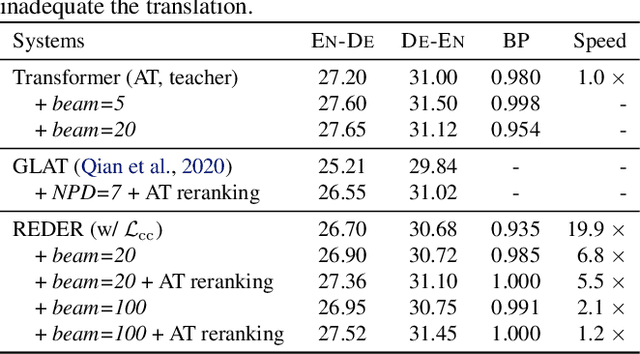
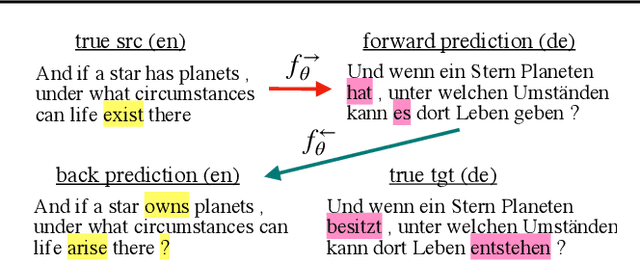
Sequence-to-sequence (seq2seq) problems such as machine translation are bidirectional, which naturally derive a pair of directional tasks and two directional learning signals. However, typical seq2seq neural networks are {\em simplex} that only model one unidirectional task, which cannot fully exploit the potential of bidirectional learning signals from parallel data. To address this issue, we propose a {\em duplex} seq2seq neural network, REDER (Reversible Duplex Transformer), and apply it to machine translation. The architecture of REDER has two ends, each of which specializes in a language so as to read and yield sequences in that language. As a result, REDER can simultaneously learn from the bidirectional signals, and enables {\em reversible machine translation} by simply flipping the input and output ends, Experiments on widely-used machine translation benchmarks verify that REDER achieves the first success of reversible machine translation, which helps obtain considerable gains over several strong baselines.
VOLT: Improving Vocabularization via Optimal Transport for Machine Translation
Dec 31, 2020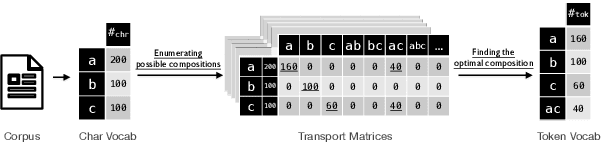
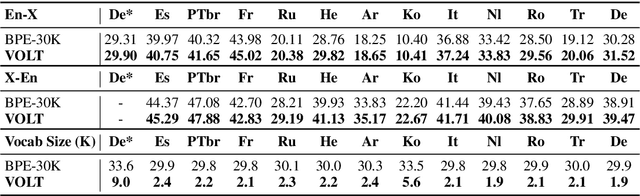
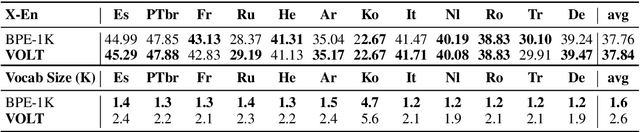
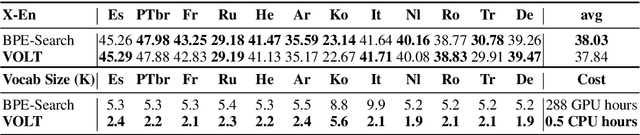
It is well accepted that the choice of token vocabulary largely affects the performance of machine translation. However, due to expensive trial costs, most studies only conduct simple trials with dominant approaches (e.g BPE) and commonly used vocabulary sizes. In this paper, we find an exciting relation between an information-theoretic feature and BLEU scores. With this observation, we formulate the quest of vocabularization -- finding the best token dictionary with a proper size -- as an optimal transport problem. We then propose VOLT, a simple and efficient vocabularization solution without the full and costly trial training. We evaluate our approach on multiple machine translation tasks, including WMT-14 English-German translation, TED bilingual translation, and TED multilingual translation. Empirical results show that VOLT beats widely-used vocabularies on diverse scenarios. For example, VOLT achieves 70% vocabulary size reduction and 0.6 BLEU gain on English-German translation. Also, one advantage of VOLT lies in its low resource consumption. Compared to naive BPE-search, VOLT reduces the search time from 288 GPU hours to 0.5 CPU hours.
RPD: A Distance Function Between Word Embeddings
May 16, 2020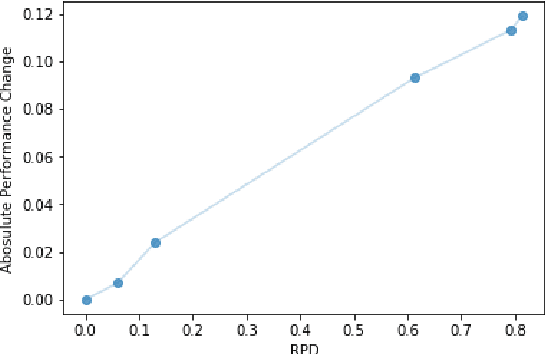
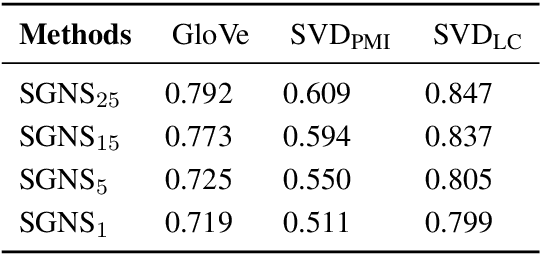
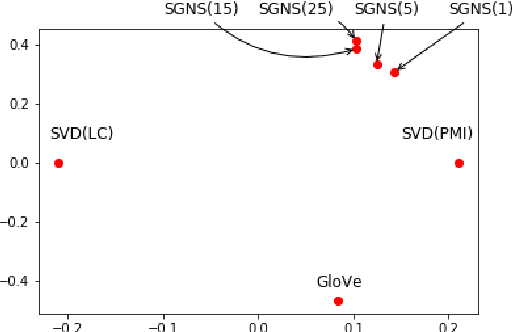
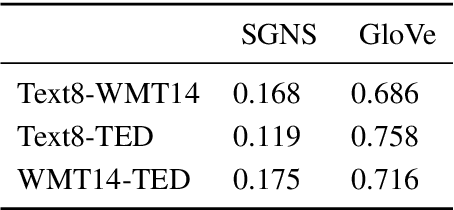
It is well-understood that different algorithms, training processes, and corpora produce different word embeddings. However, less is known about the relation between different embedding spaces, i.e. how far different sets of embeddings deviate from each other. In this paper, we propose a novel metric called Relative pairwise inner Product Distance (RPD) to quantify the distance between different sets of word embeddings. This metric has a unified scale for comparing different sets of word embeddings. Based on the properties of RPD, we study the relations of word embeddings of different algorithms systematically and investigate the influence of different training processes and corpora. The results shed light on the poorly understood word embeddings and justify RPD as a measure of the distance of embedding spaces.
Toward Making the Most of Context in Neural Machine Translation
Feb 19, 2020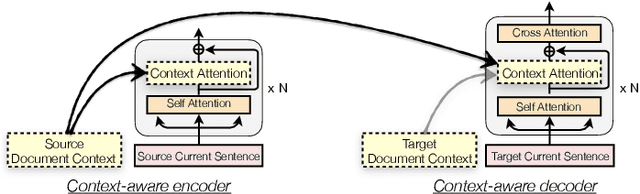
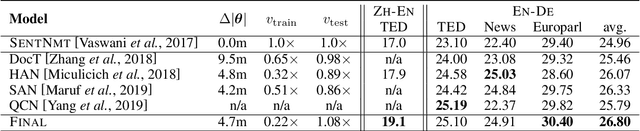
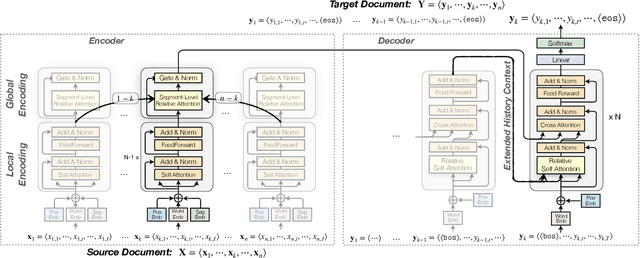

Document-level machine translation manages to outperform sentence level models by a small margin, but have failed to be widely adopted. We argue that previous research did not make a clear use of the global context, and propose a new document-level NMT framework that deliberately models the local context of each sentence with the awareness of the global context of the document in both source and target languages. We specifically design the model to be able to deal with documents containing any number of sentences, including single sentences. This unified approach allows our model to be trained elegantly on standard datasets without needing to train on sentence and document level data separately. Experimental results demonstrate that our model outperforms Transformer baselines and previous document-level NMT models with substantial margins of up to 2.1 BLEU on state-of-the-art baselines. We also provide analyses which show the benefit of context far beyond the neighboring two or three sentences, which previous studies have typically incorporated.