 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDC-BERT: Decoupling Question and Document for Efficient Contextual Encoding
Feb 28, 2020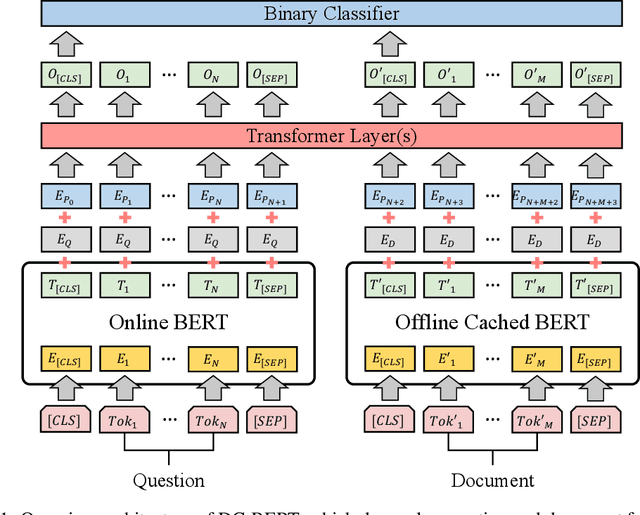
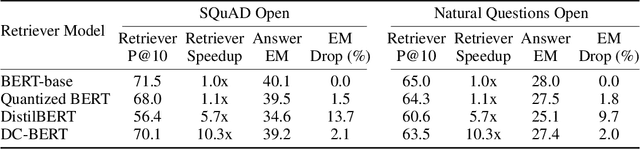
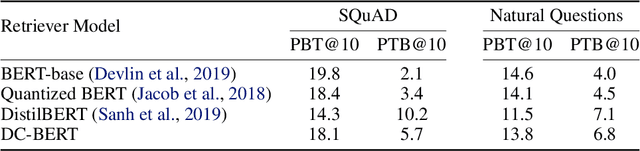
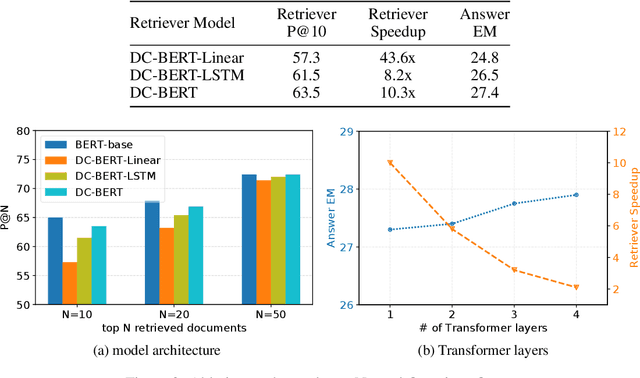
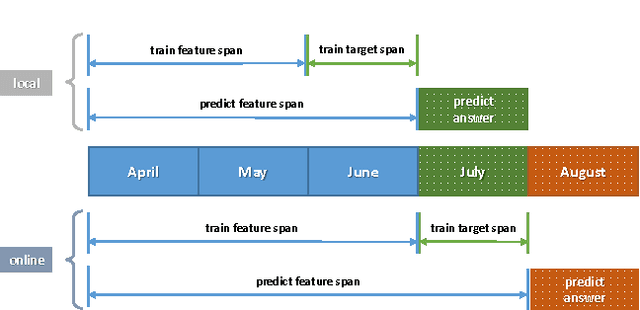
Recent studies on open-domain question answering have achieved prominent performance improvement using pre-trained language models such as BERT. State-of-the-art approaches typically follow the "retrieve and read" pipeline and employ BERT-based reranker to filter retrieved documents before feeding them into the reader module. The BERT retriever takes as input the concatenation of question and each retrieved document. Despite the success of these approaches in terms of QA accuracy, due to the concatenation, they can barely handle high-throughput of incoming questions each with a large collection of retrieved documents. To address the efficiency problem, we propose DC-BERT, a decoupled contextual encoding framework that has dual BERT models: an online BERT which encodes the question only once, and an offline BERT which pre-encodes all the documents and caches their encodings. On SQuAD Open and Natural Questions Open datasets, DC-BERT achieves 10x speedup on document retrieval, while retaining most (about 98%) of the QA performance compared to state-of-the-art approaches for open-domain question answering.
Efficient Probabilistic Logic Reasoning with Graph Neural Networks
Feb 04, 2020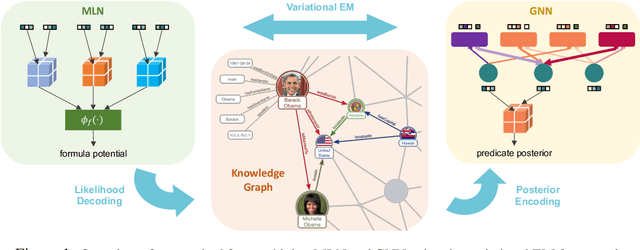
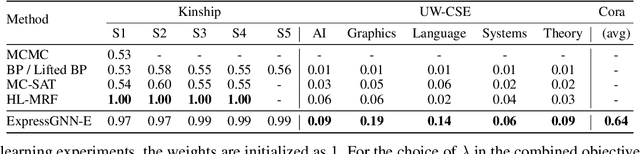
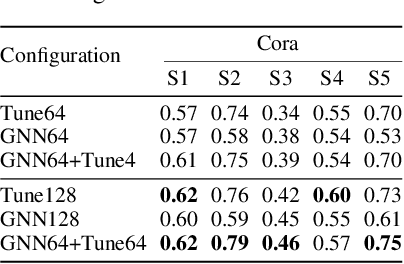
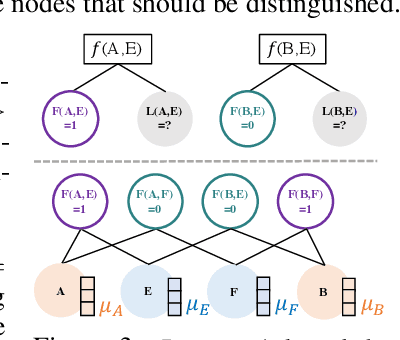
Markov Logic Networks (MLNs), which elegantly combine logic rules and probabilistic graphical models, can be used to address many knowledge graph problems. However, inference in MLN is computationally intensive, making the industrial-scale application of MLN very difficult. In recent years, graph neural networks (GNNs) have emerged as efficient and effective tools for large-scale graph problems. Nevertheless, GNNs do not explicitly incorporate prior logic rules into the models, and may require many labeled examples for a target task. In this paper, we explore the combination of MLNs and GNNs, and use graph neural networks for variational inference in MLN. We propose a GNN variant, named ExpressGNN, which strikes a nice balance between the representation power and the simplicity of the model. Our extensive experiments on several benchmark datasets demonstrate that ExpressGNN leads to effective and efficient probabilistic logic reasoning.
Can Graph Neural Networks Help Logic Reasoning?
Jun 27, 2019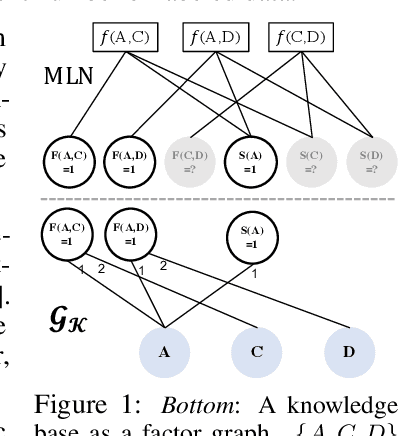

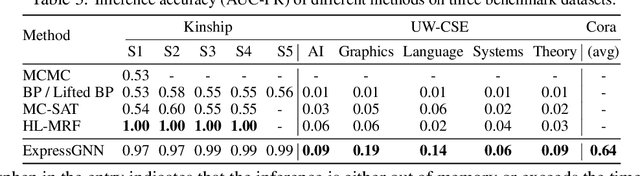
Effectively combining logic reasoning and probabilistic inference has been a long-standing goal of machine learning: the former has the ability to generalize with small training data, while the latter provides a principled framework for dealing with noisy data. However, existing methods for combining the best of both worlds are typically computationally intensive. In this paper, we focus on Markov Logic Networks and explore the use of graph neural networks (GNNs) for representing probabilistic logic inference. It is revealed from our analysis that the representation power of GNN alone is not enough for such a task. We instead propose a more expressive variant, called ExpressGNN, which can perform effective probabilistic logic inference while being able to scale to a large number of entities. We demonstrate by several benchmark datasets that ExpressGNN has the potential to advance probabilistic logic reasoning to the next stage.
KG^2: Learning to Reason Science Exam Questions with Contextual Knowledge Graph Embeddings
May 31, 2018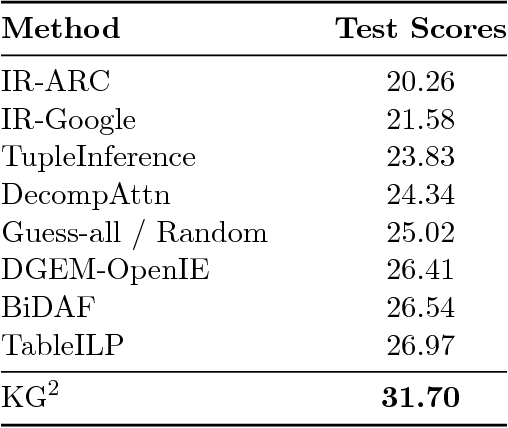
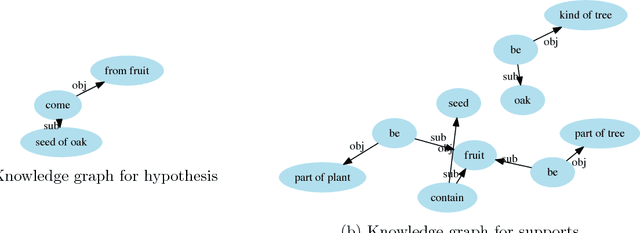
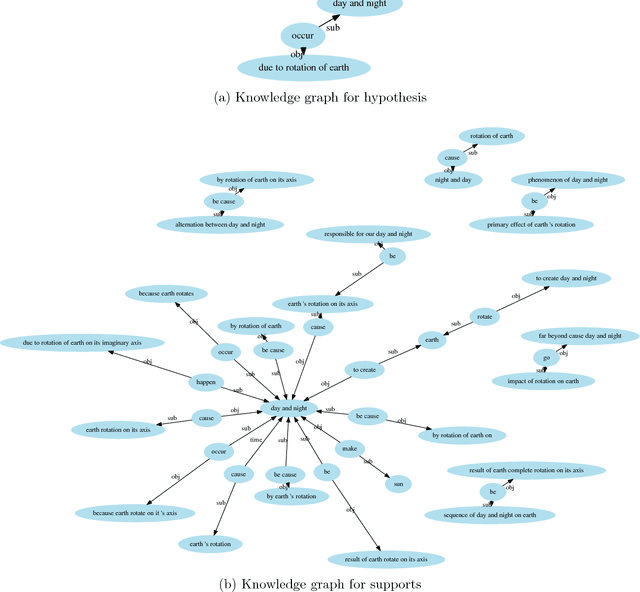
The AI2 Reasoning Challenge (ARC), a new benchmark dataset for question answering (QA) has been recently released. ARC only contains natural science questions authored for human exams, which are hard to answer and require advanced logic reasoning. On the ARC Challenge Set, existing state-of-the-art QA systems fail to significantly outperform random baseline, reflecting the difficult nature of this task. In this paper, we propose a novel framework for answering science exam questions, which mimics human solving process in an open-book exam. To address the reasoning challenge, we construct contextual knowledge graphs respectively for the question itself and supporting sentences. Our model learns to reason with neural embeddings of both knowledge graphs. Experiments on the ARC Challenge Set show that our model outperforms the previous state-of-the-art QA systems.
Learning Combinatorial Optimization Algorithms over Graphs
Feb 21, 2018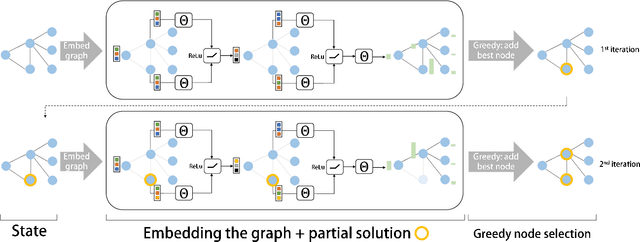

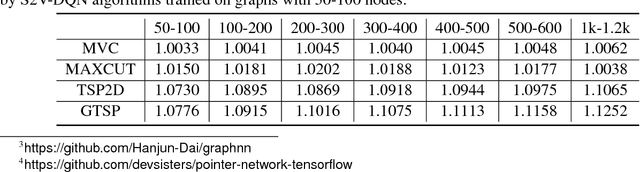
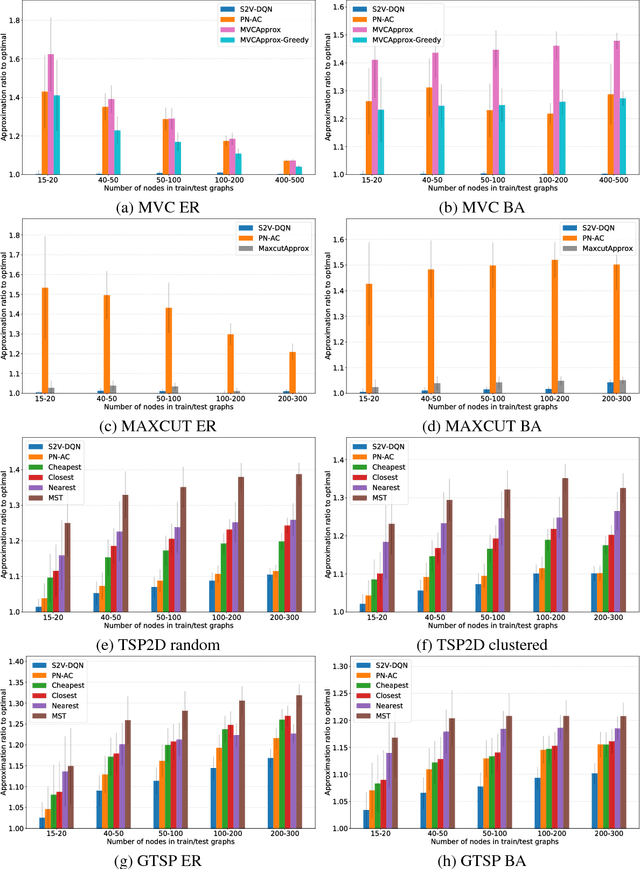
The design of good heuristics or approximation algorithms for NP-hard combinatorial optimization problems often requires significant specialized knowledge and trial-and-error. Can we automate this challenging, tedious process, and learn the algorithms instead? In many real-world applications, it is typically the case that the same optimization problem is solved again and again on a regular basis, maintaining the same problem structure but differing in the data. This provides an opportunity for learning heuristic algorithms that exploit the structure of such recurring problems. In this paper, we propose a unique combination of reinforcement learning and graph embedding to address this challenge. The learned greedy policy behaves like a meta-algorithm that incrementally constructs a solution, and the action is determined by the output of a graph embedding network capturing the current state of the solution. We show that our framework can be applied to a diverse range of optimization problems over graphs, and learns effective algorithms for the Minimum Vertex Cover, Maximum Cut and Traveling Salesman problems.
Variational Reasoning for Question Answering with Knowledge Graph
Nov 27, 2017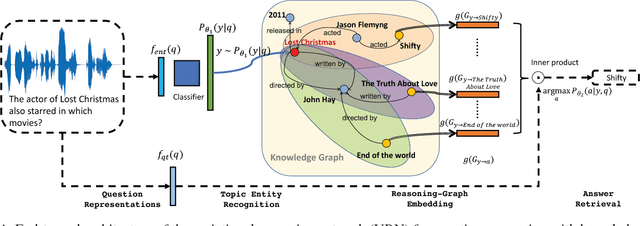

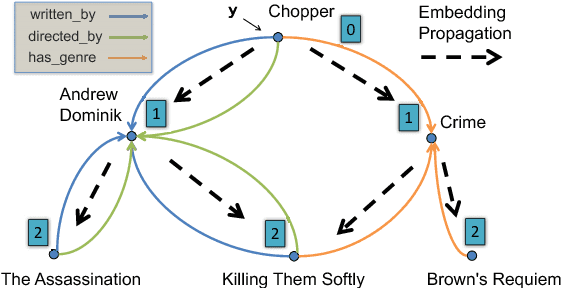

Knowledge graph (KG) is known to be helpful for the task of question answering (QA), since it provides well-structured relational information between entities, and allows one to further infer indirect facts. However, it is challenging to build QA systems which can learn to reason over knowledge graphs based on question-answer pairs alone. First, when people ask questions, their expressions are noisy (for example, typos in texts, or variations in pronunciations), which is non-trivial for the QA system to match those mentioned entities to the knowledge graph. Second, many questions require multi-hop logic reasoning over the knowledge graph to retrieve the answers. To address these challenges, we propose a novel and unified deep learning architecture, and an end-to-end variational learning algorithm which can handle noise in questions, and learn multi-hop reasoning simultaneously. Our method achieves state-of-the-art performance on a recent benchmark dataset in the literature. We also derive a series of new benchmark datasets, including questions for multi-hop reasoning, questions paraphrased by neural translation model, and questions in human voice. Our method yields very promising results on all these challenging datasets.
FLASH: Fast Bayesian Optimization for Data Analytic Pipelines
Jun 24, 2016

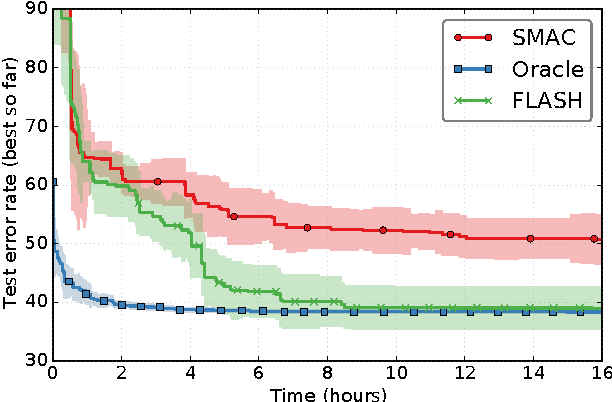
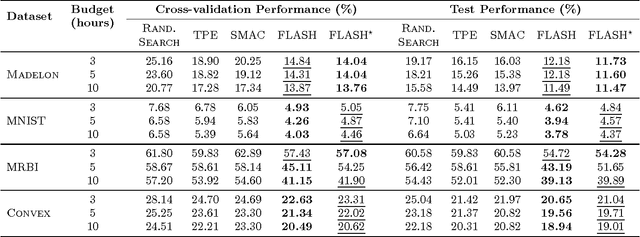
Modern data science relies on data analytic pipelines to organize interdependent computational steps. Such analytic pipelines often involve different algorithms across multiple steps, each with its own hyperparameters. To achieve the best performance, it is often critical to select optimal algorithms and to set appropriate hyperparameters, which requires large computational efforts. Bayesian optimization provides a principled way for searching optimal hyperparameters for a single algorithm. However, many challenges remain in solving pipeline optimization problems with high-dimensional and highly conditional search space. In this work, we propose Fast LineAr SearcH (FLASH), an efficient method for tuning analytic pipelines. FLASH is a two-layer Bayesian optimization framework, which firstly uses a parametric model to select promising algorithms, then computes a nonparametric model to fine-tune hyperparameters of the promising algorithms. FLASH also includes an effective caching algorithm which can further accelerate the search process. Extensive experiments on a number of benchmark datasets have demonstrated that FLASH significantly outperforms previous state-of-the-art methods in both search speed and accuracy. Using 50% of the time budget, FLASH achieves up to 20% improvement on test error rate compared to the baselines. FLASH also yields state-of-the-art performance on a real-world application for healthcare predictive modeling.
Large Scale Purchase Prediction with Historical User Actions on B2C Online Retail Platform
Mar 04, 2015
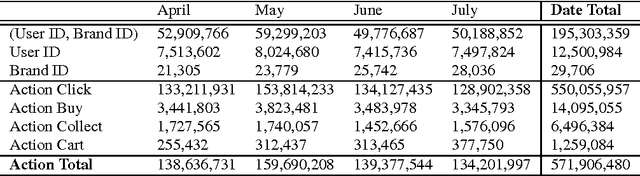
This paper describes the solution of Bazinga Team for Tmall Recommendation Prize 2014. With real-world user action data provided by Tmall, one of the largest B2C online retail platforms in China, this competition requires to predict future user purchases on Tmall website. Predictions are judged on F1Score, which considers both precision and recall for fair evaluation. The data set provided by Tmall contains more than half billion action records from over ten million distinct users. Such massive data volume poses a big challenge, and drives competitors to write every single program in MapReduce fashion and run it on distributed cluster. We model the purchase prediction problem as standard machine learning problem, and mainly employ regression and classification methods as single models. Individual models are then aggregated in a two-stage approach, using linear regression for blending, and finally a linear ensemble of blended models. The competition is approaching the end but still in running during writing this paper. In the end, our team achieves F1Score 6.11 and ranks 7th (out of 7,276 teams in total).
Sequential Click Prediction for Sponsored Search with Recurrent Neural Networks
Jul 28, 2014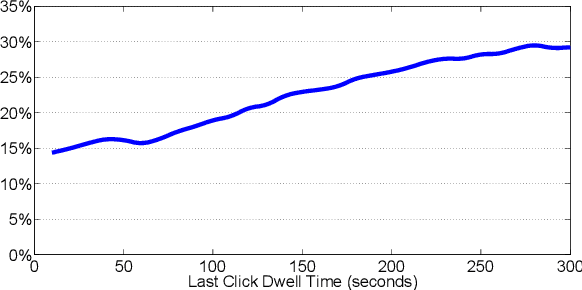
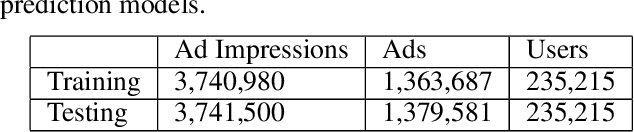
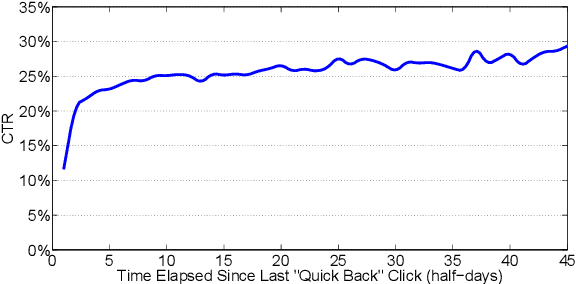
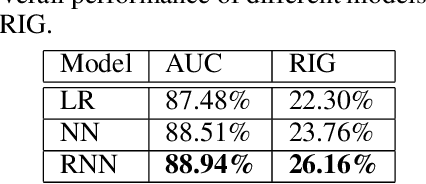
Click prediction is one of the fundamental problems in sponsored search. Most of existing studies took advantage of machine learning approaches to predict ad click for each event of ad view independently. However, as observed in the real-world sponsored search system, user's behaviors on ads yield high dependency on how the user behaved along with the past time, especially in terms of what queries she submitted, what ads she clicked or ignored, and how long she spent on the landing pages of clicked ads, etc. Inspired by these observations, we introduce a novel framework based on Recurrent Neural Networks (RNN). Compared to traditional methods, this framework directly models the dependency on user's sequential behaviors into the click prediction process through the recurrent structure in RNN. Large scale evaluations on the click-through logs from a commercial search engine demonstrate that our approach can significantly improve the click prediction accuracy, compared to sequence-independent approaches.
Combination of Diverse Ranking Models for Personalized Expedia Hotel Searches
Nov 29, 2013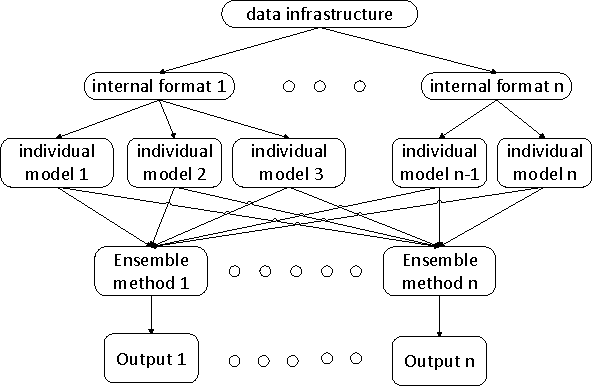
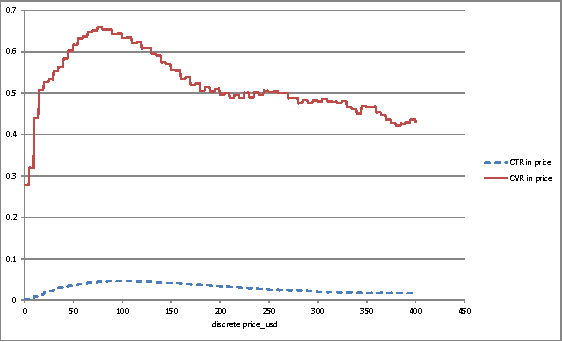
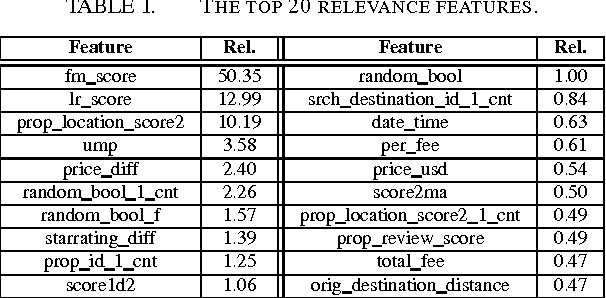

The ICDM Challenge 2013 is to apply machine learning to the problem of hotel ranking, aiming to maximize purchases according to given hotel characteristics, location attractiveness of hotels, user's aggregated purchase history and competitive online travel agency information for each potential hotel choice. This paper describes the solution of team "binghsu & MLRush & BrickMover". We conduct simple feature engineering work and train different models by each individual team member. Afterwards, we use listwise ensemble method to combine each model's output. Besides describing effective model and features, we will discuss about the lessons we learned while using deep learning in this competition.