 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCriteria for Classifying Forecasting Methods
Dec 07, 2022


Classifying forecasting methods as being either of a "machine learning" or "statistical" nature has become commonplace in parts of the forecasting literature and community, as exemplified by the M4 competition and the conclusion drawn by the organizers. We argue that this distinction does not stem from fundamental differences in the methods assigned to either class. Instead, this distinction is probably of a tribal nature, which limits the insights into the appropriateness and effectiveness of different forecasting methods. We provide alternative characteristics of forecasting methods which, in our view, allow to draw meaningful conclusions. Further, we discuss areas of forecasting which could benefit most from cross-pollination between the ML and the statistics communities.
Deep Learning Based Audio-Visual Multi-Speaker DOA Estimation Using Permutation-Free Loss Function
Oct 26, 2022In this paper, we propose a deep learning based multi-speaker direction of arrival (DOA) estimation with audio and visual signals by using permutation-free loss function. We first collect a data set for multi-modal sound source localization (SSL) where both audio and visual signals are recorded in real-life home TV scenarios. Then we propose a novel spatial annotation method to produce the ground truth of DOA for each speaker with the video data by transformation between camera coordinate and pixel coordinate according to the pin-hole camera model. With spatial location information served as another input along with acoustic feature, multi-speaker DOA estimation could be solved as a classification task of active speaker detection. Label permutation problem in multi-speaker related tasks will be addressed since the locations of each speaker are used as input. Experiments conducted on both simulated data and real data show that the proposed audio-visual DOA estimation model outperforms audio-only DOA estimation model by a large margin.
MOFormer: Self-Supervised Transformer model for Metal-Organic Framework Property Prediction
Oct 25, 2022



Metal-Organic Frameworks (MOFs) are materials with a high degree of porosity that can be used for applications in energy storage, water desalination, gas storage, and gas separation. However, the chemical space of MOFs is close to an infinite size due to the large variety of possible combinations of building blocks and topology. Discovering the optimal MOFs for specific applications requires an efficient and accurate search over an enormous number of potential candidates. Previous high-throughput screening methods using computational simulations like DFT can be time-consuming. Such methods also require optimizing 3D atomic structure of MOFs, which adds one extra step when evaluating hypothetical MOFs. In this work, we propose a structure-agnostic deep learning method based on the Transformer model, named as MOFormer, for property predictions of MOFs. The MOFormer takes a text string representation of MOF (MOFid) as input, thus circumventing the need of obtaining the 3D structure of hypothetical MOF and accelerating the screening process. Furthermore, we introduce a self-supervised learning framework that pretrains the MOFormer via maximizing the cross-correlation between its structure-agnostic representations and structure-based representations of crystal graph convolutional neural network (CGCNN) on >400k publicly available MOF data. Using self-supervised learning allows the MOFormer to intrinsically learn 3D structural information though it is not included in the input. Experiments show that pretraining improved the prediction accuracy of both models on various downstream prediction tasks. Furthermore, we revealed that MOFormer can be more data-efficient on quantum-chemical property prediction than structure-based CGCNN when training data is limited. Overall, MOFormer provides a novel perspective on efficient MOF design using deep learning.
Predicting CO$_2$ Absorption in Ionic Liquids with Molecular Descriptors and Explainable Graph Neural Networks
Sep 29, 2022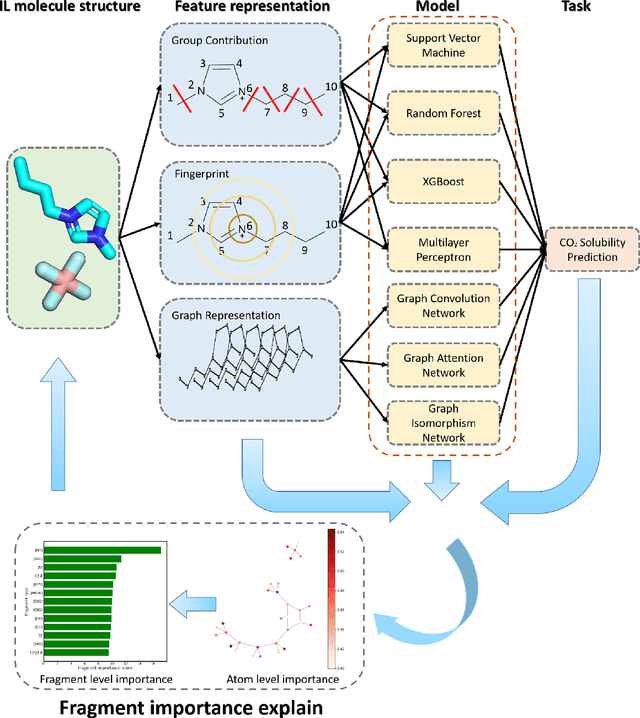
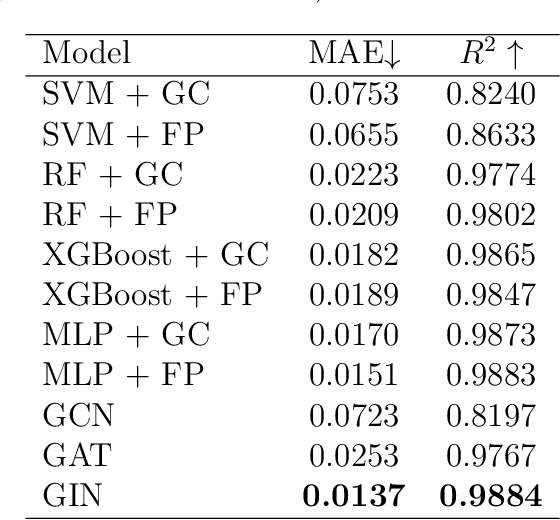
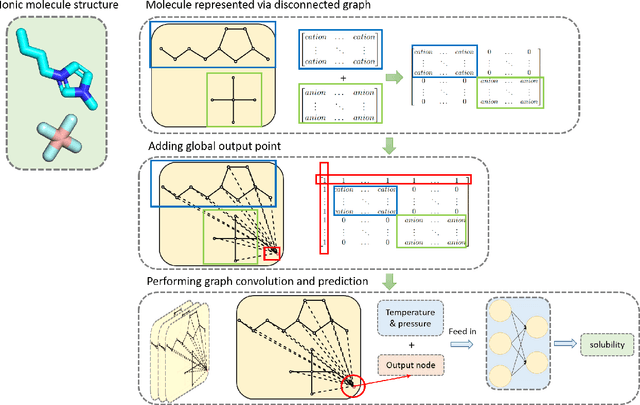
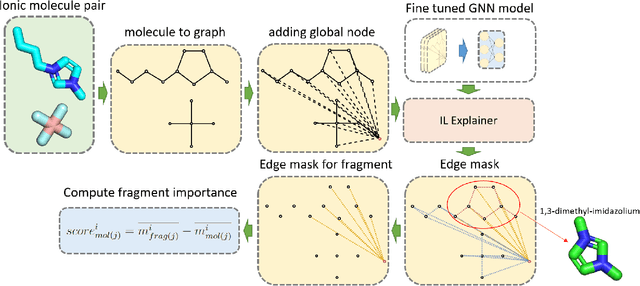
Ionic Liquids (ILs) provide a promising solution for CO$_2$ capture and storage to mitigate global warming. However, identifying and designing the high-capacity IL from the giant chemical space requires expensive, and exhaustive simulations and experiments. Machine learning (ML) can accelerate the process of searching for desirable ionic molecules through accurate and efficient property predictions in a data-driven manner. But existing descriptors and ML models for the ionic molecule suffer from the inefficient adaptation of molecular graph structure. Besides, few works have investigated the explainability of ML models to help understand the learned features that can guide the design of efficient ionic molecules. In this work, we develop both fingerprint-based ML models and Graph Neural Networks (GNNs) to predict the CO$_2$ absorption in ILs. Fingerprint works on graph structure at the feature extraction stage, while GNNs directly handle molecule structure in both the feature extraction and model prediction stage. We show that our method outperforms previous ML models by reaching a high accuracy (MAE of 0.0137, $R^2$ of 0.9884). Furthermore, we take the advantage of GNNs feature representation and develop a substructure-based explanation method that provides insight into how each chemical fragments within IL molecules contribute to the CO$_2$ absorption prediction of ML models. We also show that our explanation result agrees with some ground truth from the theoretical reaction mechanism of CO$_2$ absorption in ILs, which can advise on the design of novel and efficient functional ILs in the future.
On the detrimental effect of invariances in the likelihood for variational inference
Sep 15, 2022


Variational Bayesian posterior inference often requires simplifying approximations such as mean-field parametrisation to ensure tractability. However, prior work has associated the variational mean-field approximation for Bayesian neural networks with underfitting in the case of small datasets or large model sizes. In this work, we show that invariances in the likelihood function of over-parametrised models contribute to this phenomenon because these invariances complicate the structure of the posterior by introducing discrete and/or continuous modes which cannot be well approximated by Gaussian mean-field distributions. In particular, we show that the mean-field approximation has an additional gap in the evidence lower bound compared to a purpose-built posterior that takes into account the known invariances. Importantly, this invariance gap is not constant; it vanishes as the approximation reverts to the prior. We proceed by first considering translation invariances in a linear model with a single data point in detail. We show that, while the true posterior can be constructed from a mean-field parametrisation, this is achieved only if the objective function takes into account the invariance gap. Then, we transfer our analysis of the linear model to neural networks. Our analysis provides a framework for future work to explore solutions to the invariance problem.
Graph Neural Networks for Molecules
Sep 12, 2022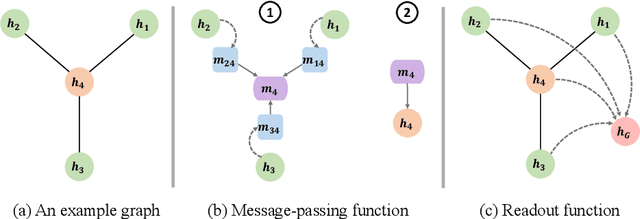
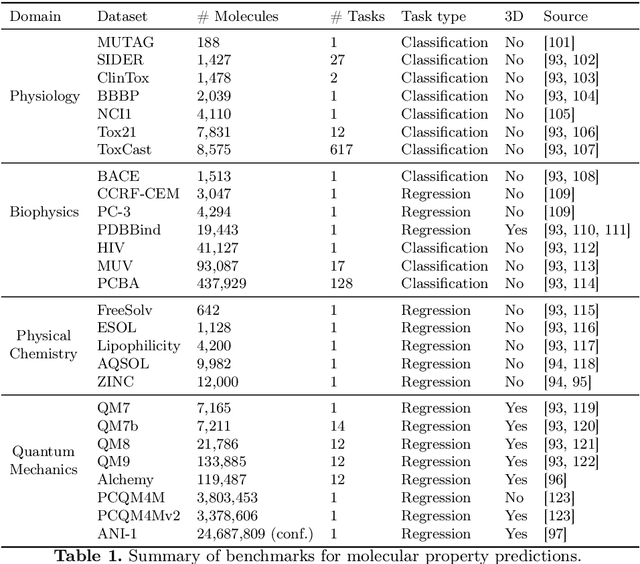
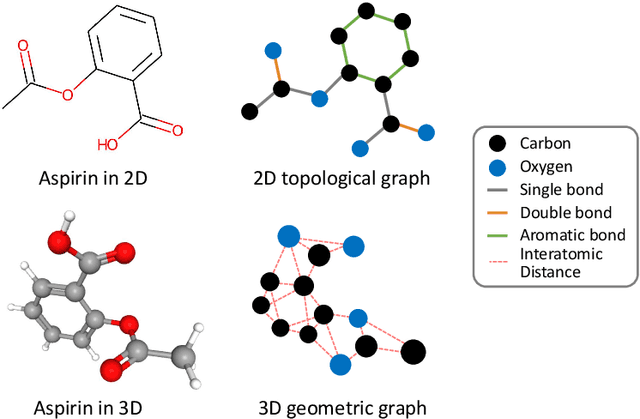
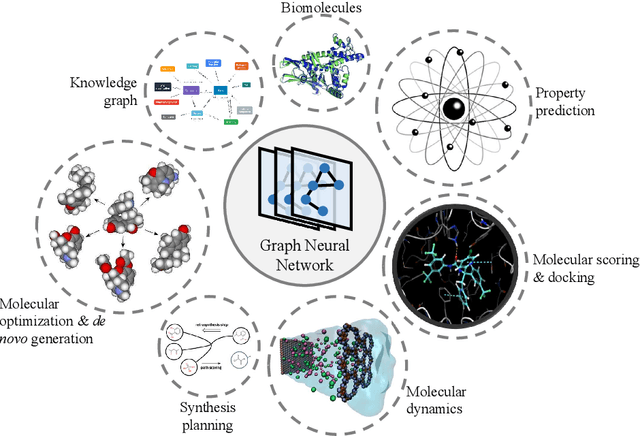
Graph neural networks (GNNs), which are capable of learning representations from graphical data, are naturally suitable for modeling molecular systems. This review introduces GNNs and their various applications for small organic molecules. GNNs rely on message-passing operations, a generic yet powerful framework, to update node features iteratively. Many researches design GNN architectures to effectively learn topological information of 2D molecule graphs as well as geometric information of 3D molecular systems. GNNs have been implemented in a wide variety of molecular applications, including molecular property prediction, molecular scoring and docking, molecular optimization and de novo generation, molecular dynamics simulation, etc. Besides, the review also summarizes the recent development of self-supervised learning for molecules with GNNs.
TransPolymer: a Transformer-based Language Model for Polymer Property Predictions
Sep 11, 2022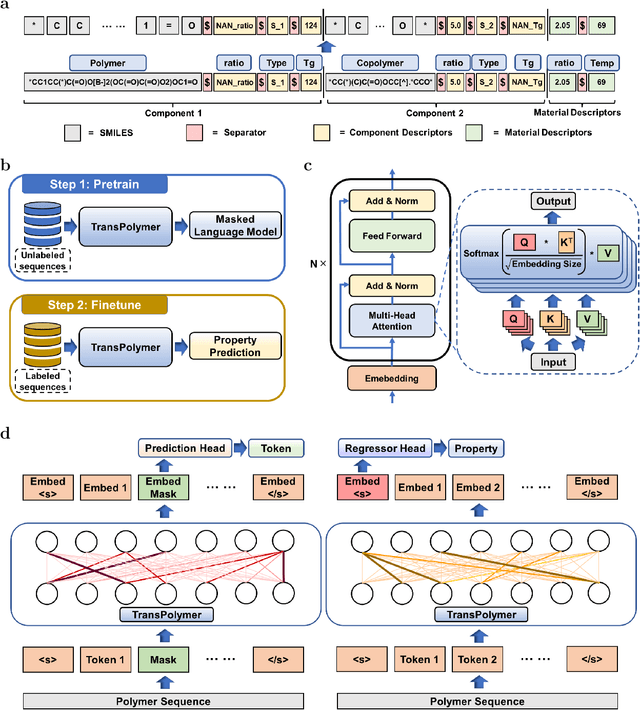
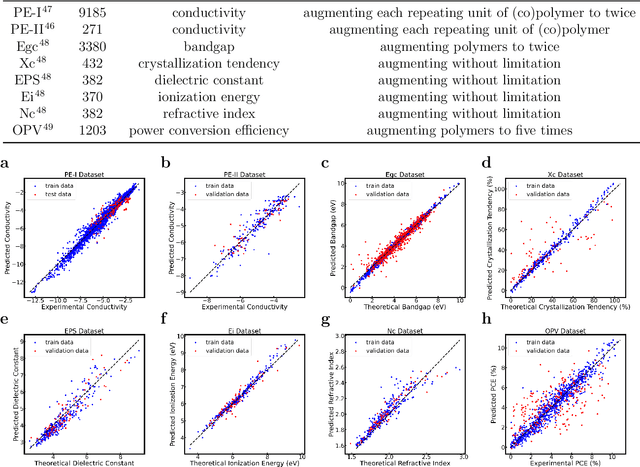
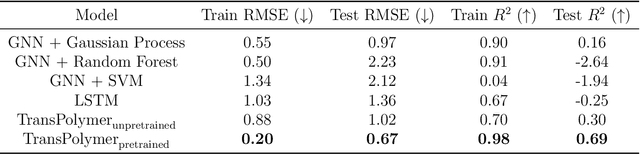
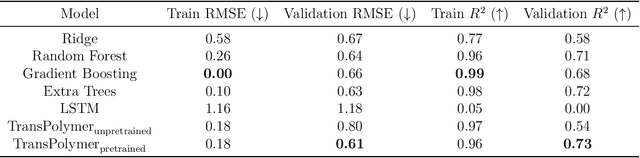
Accurate and efficient prediction of polymer properties is of great significance in polymer development and design. Conventionally, expensive and time-consuming experiments or simulations are required to evaluate the function of polymers. Recently, Transformer models, equipped with attention mechanisms, have exhibited superior performance in various natural language processing tasks. However, such methods have not been investigated in polymer sciences. Herein, we report TransPolymer, a Transformer-based language model for polymer property prediction. Owing to our proposed polymer tokenizer with chemical awareness, TransPolymer can learn representations directly from polymer sequences. The model learns expressive representations by pretraining on a large unlabeled dataset, followed by finetuning the model on downstream datasets concerning various polymer properties. TransPolymer achieves superior performance in all eight datasets and surpasses other baselines significantly on most downstream tasks. Moreover, the improvement by the pretrained TransPolymer over supervised TransPolymer and other language models strengthens the significant benefits of pretraining on large unlabeled data in representation learning. Experiment results further demonstrate the important role of the attention mechanism in understanding polymer sequences. We highlight this model as a promising computational tool for promoting rational polymer design and understanding structure-property relationships in a data science view.
Earthformer: Exploring Space-Time Transformers for Earth System Forecasting
Jul 12, 2022
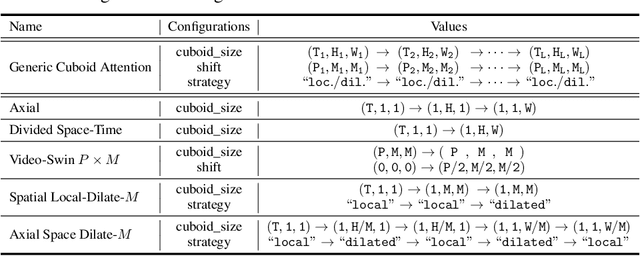
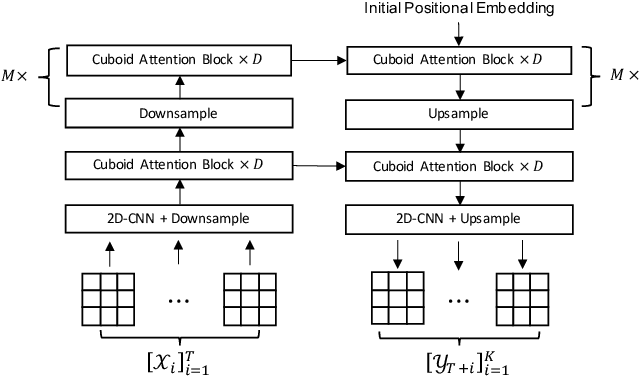
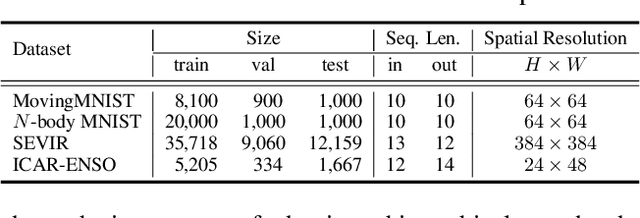
Conventionally, Earth system (e.g., weather and climate) forecasting relies on numerical simulation with complex physical models and are hence both expensive in computation and demanding on domain expertise. With the explosive growth of the spatiotemporal Earth observation data in the past decade, data-driven models that apply Deep Learning (DL) are demonstrating impressive potential for various Earth system forecasting tasks. The Transformer as an emerging DL architecture, despite its broad success in other domains, has limited adoption in this area. In this paper, we propose Earthformer, a space-time Transformer for Earth system forecasting. Earthformer is based on a generic, flexible and efficient space-time attention block, named Cuboid Attention. The idea is to decompose the data into cuboids and apply cuboid-level self-attention in parallel. These cuboids are further connected with a collection of global vectors. We conduct experiments on the MovingMNIST dataset and a newly proposed chaotic N-body MNIST dataset to verify the effectiveness of cuboid attention and figure out the best design of Earthformer. Experiments on two real-world benchmarks about precipitation nowcasting and El Nino/Southern Oscillation (ENSO) forecasting show Earthformer achieves state-of-the-art performance.
Crystal Twins: Self-supervised Learning for Crystalline Material Property Prediction
May 04, 2022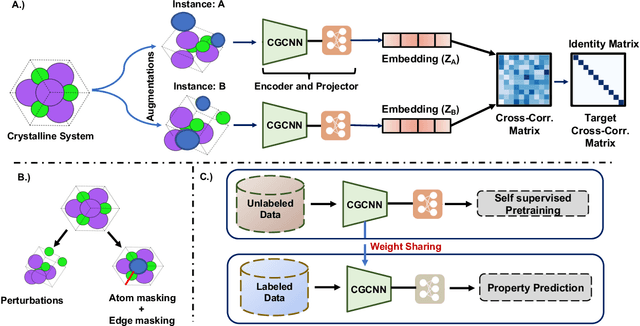
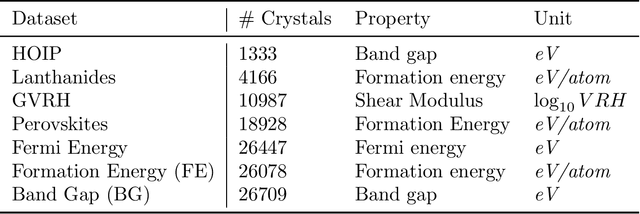

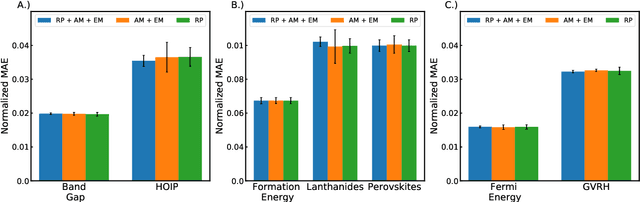
Machine learning (ML) models have been widely successful in the prediction of material properties. However, large labeled datasets required for training accurate ML models are elusive and computationally expensive to generate. Recent advances in Self-Supervised Learning (SSL) frameworks capable of training ML models on unlabeled data have mitigated this problem and demonstrated superior performance in computer vision and natural language processing tasks. Drawing inspiration from the developments in SSL, we introduce Crystal Twins (CT): an SSL method for crystalline materials property prediction. Using a large unlabeled dataset, we pre-train a Graph Neural Network (GNN) by applying the redundancy reduction principle to the graph latent embeddings of augmented instances obtained from the same crystalline system. By sharing the pre-trained weights when fine-tuning the GNN for regression tasks, we significantly improve the performance for 7 challenging material property prediction benchmarks
Robust Probabilistic Time Series Forecasting
Feb 24, 2022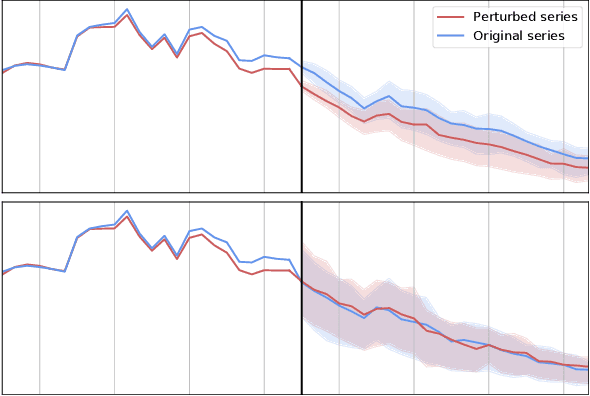

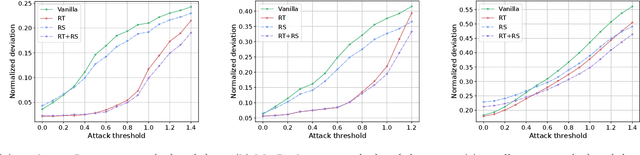
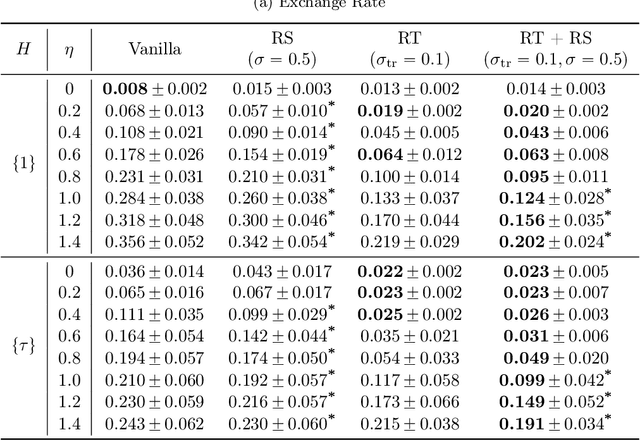
Probabilistic time series forecasting has played critical role in decision-making processes due to its capability to quantify uncertainties. Deep forecasting models, however, could be prone to input perturbations, and the notion of such perturbations, together with that of robustness, has not even been completely established in the regime of probabilistic forecasting. In this work, we propose a framework for robust probabilistic time series forecasting. First, we generalize the concept of adversarial input perturbations, based on which we formulate the concept of robustness in terms of bounded Wasserstein deviation. Then we extend the randomized smoothing technique to attain robust probabilistic forecasters with theoretical robustness certificates against certain classes of adversarial perturbations. Lastly, extensive experiments demonstrate that our methods are empirically effective in enhancing the forecast quality under additive adversarial attacks and forecast consistency under supplement of noisy observations.