 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Model Averaging under Predictor Redundancy via Density-Ratio Posterior Compression
Jun 19, 2026Bayesian model averaging in support-indexed regression induces a posterior distribution over active predictor supports. Under predictor redundancy, posterior mass can spread across many nearly interchangeable supports, making exact-support summaries unstable or hard to interpret even when prediction is stable. We study how to report an already fitted Bayesian model averaging posterior without changing the Bayesian target. A report uses hard or soft regions of support space, and its compressed reporting law is compared with the reference posterior through an explicit density ratio. This ratio gives computable total-variation and Kullback--Leibler distortion, bounds for bounded predictive summaries, retained-mass diagnostics, and fallback-weight diagnostics. The framework covers fixed hard regions, metric-ball regions, posterior-cluster regions, and pooled-pruned region dictionaries. We prove exact error formulas and validation bounds for these region reports, and give conditions under which a few regions can replace a long list of individual supports. In simulations, our region reports often give shorter and clearer summaries while preserving the main posterior information, and the density-ratio diagnostics show when too much information has been lost.
ReasonAudio: A Benchmark for Evaluating Reasoning Beyond Matching in Text-Audio Retrieval
May 05, 2026As multimodal content continues to expand at a rapid pace, audio retrieval has emerged as a key enabling technology for media search, content organization, and intelligent assistants. However, most existing benchmarks concentrate on semantic matching and fail to capture the fact that real-world queries often demand advanced reasoning abilities, including negation understanding, temporal ordering, concurrent event recognition, and duration discrimination. To address this gap, we introduce ReasonAudio, the first reasoning-intensive benchmark for Text-Audio Retrieval, comprising 1,000 queries and 10,000 composite audio clips across five fundamental reasoning tasks: Negation, Order, Overlap, Duration, and Mix. Despite their intuitive nature for humans and straightforward construction, these tasks pose significant challenges to current models. Our evaluation of ten state-of-the-art models reveals the following findings: All models struggle with reasoning-intensive audio retrieval, performing particularly poorly on Negation and Duration while showing relatively better results on Overlap and Order. Moreover, Multimodal Large Language Model-based embedding models fail to inherit the reasoning capabilities of their backbones through contrastive fine-tuning, suggesting that current training paradigms are insufficient to preserve reasoning capacity in retrieval settings
SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents
Jan 23, 2026LLM agents have demonstrated remarkable capabilities in software development, but their performance is hampered by long interaction contexts, which incur high API costs and latency. While various context compression approaches such as LongLLMLingua have emerged to tackle this challenge, they typically rely on fixed metrics such as PPL, ignoring the task-specific nature of code understanding. As a result, they frequently disrupt syntactic and logical structure and fail to retain critical implementation details. In this paper, we propose SWE-Pruner, a self-adaptive context pruning framework tailored for coding agents. Drawing inspiration from how human programmers "selectively skim" source code during development and debugging, SWE-Pruner performs task-aware adaptive pruning for long contexts. Given the current task, the agent formulates an explicit goal (e.g., "focus on error handling") as a hint to guide the pruning targets. A lightweight neural skimmer (0.6B parameters) is trained to dynamically select relevant lines from the surrounding context given the goal. Evaluations across four benchmarks and multiple models validate SWE-Pruner's effectiveness in various scenarios, achieving 23-54% token reduction on agent tasks like SWE-Bench Verified and up to 14.84x compression on single-turn tasks like LongCodeQA with minimal performance impact.
GlimpRouter: Efficient Collaborative Inference by Glimpsing One Token of Thoughts
Jan 08, 2026Large Reasoning Models (LRMs) achieve remarkable performance by explicitly generating multi-step chains of thought, but this capability incurs substantial inference latency and computational cost. Collaborative inference offers a promising solution by selectively allocating work between lightweight and large models, yet a fundamental challenge remains: determining when a reasoning step requires the capacity of a large model or the efficiency of a small model. Existing routing strategies either rely on local token probabilities or post-hoc verification, introducing significant inference overhead. In this work, we propose a novel perspective on step-wise collaboration: the difficulty of a reasoning step can be inferred from its very first token. Inspired by the "Aha Moment" phenomenon in LRMs, we show that the entropy of the initial token serves as a strong predictor of step difficulty. Building on this insight, we introduce GlimpRouter, a training-free step-wise collaboration framework. GlimpRouter employs a lightweight model to generate only the first token of each reasoning step and routes the step to a larger model only when the initial token entropy exceeds a threshold. Experiments on multiple benchmarks demonstrate that our approach significantly reduces inference latency while preserving accuracy. For instance, GlimpRouter attains a substantial 10.7% improvement in accuracy while reducing inference latency by 25.9% compared to a standalone large model on AIME25. These results suggest a simple yet effective mechanism for reasoning: allocating computation based on a glimpse of thought rather than full-step evaluation.
LGAN: An Efficient High-Order Graph Neural Network via the Line Graph Aggregation
Dec 11, 2025



Graph Neural Networks (GNNs) have emerged as a dominant paradigm for graph classification. Specifically, most existing GNNs mainly rely on the message passing strategy between neighbor nodes, where the expressivity is limited by the 1-dimensional Weisfeiler-Lehman (1-WL) test. Although a number of k-WL-based GNNs have been proposed to overcome this limitation, their computational cost increases rapidly with k, significantly restricting the practical applicability. Moreover, since the k-WL models mainly operate on node tuples, these k-WL-based GNNs cannot retain fine-grained node- or edge-level semantics required by attribution methods (e.g., Integrated Gradients), leading to the less interpretable problem. To overcome the above shortcomings, in this paper, we propose a novel Line Graph Aggregation Network (LGAN), that constructs a line graph from the induced subgraph centered at each node to perform the higher-order aggregation. We theoretically prove that the LGAN not only possesses the greater expressive power than the 2-WL under injective aggregation assumptions, but also has lower time complexity. Empirical evaluations on benchmarks demonstrate that the LGAN outperforms state-of-the-art k-WL-based GNNs, while offering better interpretability.
MIMOSA: Multi-parametric Imaging using Multiple-echoes with Optimized Simultaneous Acquisition for highly-efficient quantitative MRI
Aug 13, 2025



Purpose: To develop a new sequence, MIMOSA, for highly-efficient T1, T2, T2*, proton density (PD), and source separation quantitative susceptibility mapping (QSM). Methods: MIMOSA was developed based on 3D-quantification using an interleaved Look-Locker acquisition sequence with T2 preparation pulse (3D-QALAS) by combining 3D turbo Fast Low Angle Shot (FLASH) and multi-echo gradient echo acquisition modules with a spiral-like Cartesian trajectory to facilitate highly-efficient acquisition. Simulations were performed to optimize the sequence. Multi-contrast/-slice zero-shot self-supervised learning algorithm was employed for reconstruction. The accuracy of quantitative mapping was assessed by comparing MIMOSA with 3D-QALAS and reference techniques in both ISMRM/NIST phantom and in-vivo experiments. MIMOSA's acceleration capability was assessed at R = 3.3, 6.5, and 11.8 in in-vivo experiments, with repeatability assessed through scan-rescan studies. Beyond the 3T experiments, mesoscale quantitative mapping was performed at 750 um isotropic resolution at 7T. Results: Simulations demonstrated that MIMOSA achieved improved parameter estimation accuracy compared to 3D-QALAS. Phantom experiments indicated that MIMOSA exhibited better agreement with the reference techniques than 3D-QALAS. In-vivo experiments demonstrated that an acceleration factor of up to R = 11.8-fold can be achieved while preserving parameter estimation accuracy, with intra-class correlation coefficients of 0.998 (T1), 0.973 (T2), 0.947 (T2*), 0.992 (QSM), 0.987 (paramagnetic susceptibility), and 0.977 (diamagnetic susceptibility) in scan-rescan studies. Whole-brain T1, T2, T2*, PD, source separation QSM were obtained with 1 mm isotropic resolution in 3 min at 3T and 750 um isotropic resolution in 13 min at 7T. Conclusion: MIMOSA demonstrated potential for highly-efficient multi-parametric mapping.
Synergizing Human-AI Agency: A Guide of 23 Heuristics for Service Co-Creation with LLM-Based Agents
Oct 23, 2023



This empirical study serves as a primer for interested service providers to determine if and how Large Language Models (LLMs) technology will be integrated for their practitioners and the broader community. We investigate the mutual learning journey of non-AI experts and AI through CoAGent, a service co-creation tool with LLM-based agents. Engaging in a three-stage participatory design processes, we work with with 23 domain experts from public libraries across the U.S., uncovering their fundamental challenges of integrating AI into human workflows. Our findings provide 23 actionable "heuristics for service co-creation with AI", highlighting the nuanced shared responsibilities between humans and AI. We further exemplar 9 foundational agency aspects for AI, emphasizing essentials like ownership, fair treatment, and freedom of expression. Our innovative approach enriches the participatory design model by incorporating AI as crucial stakeholders and utilizing AI-AI interaction to identify blind spots. Collectively, these insights pave the way for synergistic and ethical human-AI co-creation in service contexts, preparing for workforce ecosystems where AI coexists.
Channel-robust Automatic Modulation Classification Using Spectral Quotient Cumulants
Oct 12, 2023



Automatic modulation classification (AMC) is to identify the modulation format of the received signal corrupted by the channel effects and noise. Most existing works focus on the impact of noise while relatively little attention has been paid to the impact of channel effects. However, the instability posed by multipath fading channels leads to significant performance degradation. To mitigate the adverse effects of the multipath channel, we propose a channel-robust modulation classification framework named spectral quotient cumulant classification (SQCC) for orthogonal frequency division multiplexing (OFDM) systems. Specifically, we first transform the received signal to the spectral quotient (SQ) sequence by spectral circular shift division operations. Secondly, an outlier detector is proposed to filter the outliers in the SQ sequence. At last, we extract spectral quotient cumulants (SQCs) from the filtered SQ sequence as the inputs to train the artificial neural network (ANN) classifier and use the trained ANN to make the final decisions. Simulation results show that our proposed SQCC method exhibits classification robustness and superiority under various unknown Rician multipath fading channels compared with other existing methods. Specifically, the SQCC method achieves nearly 90% classification accuracy at the signal to noise ratio (SNR) of 4dB when testing under multiple channels but training under AWGN channel.
InfeRE: Step-by-Step Regex Generation via Chain of Inference
Aug 08, 2023Automatically generating regular expressions (abbrev. regexes) from natural language description (NL2RE) has been an emerging research area. Prior studies treat regex as a linear sequence of tokens and generate the final expressions autoregressively in a single pass. They did not take into account the step-by-step internal text-matching processes behind the final results. This significantly hinders the efficacy and interpretability of regex generation by neural language models. In this paper, we propose a new paradigm called InfeRE, which decomposes the generation of regexes into chains of step-by-step inference. To enhance the robustness, we introduce a self-consistency decoding mechanism that ensembles multiple outputs sampled from different models. We evaluate InfeRE on two publicly available datasets, NL-RX-Turk and KB13, and compare the results with state-of-the-art approaches and the popular tree-based generation approach TRANX. Experimental results show that InfeRE substantially outperforms previous baselines, yielding 16.3% and 14.7% improvement in DFA@5 accuracy on two datasets, respectively. Particularly, InfeRE outperforms the popular tree-based generation approach by 18.1% and 11.3% on both datasets, respectively, in terms of DFA@5 accuracy.
Scenario-aware and Mutual-based approach for Multi-scenario Recommendation in E-Commerce
Dec 16, 2020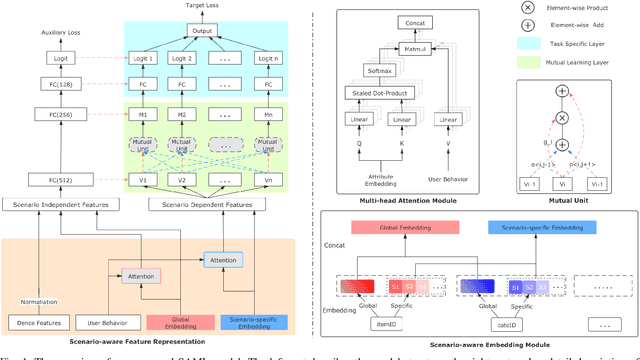

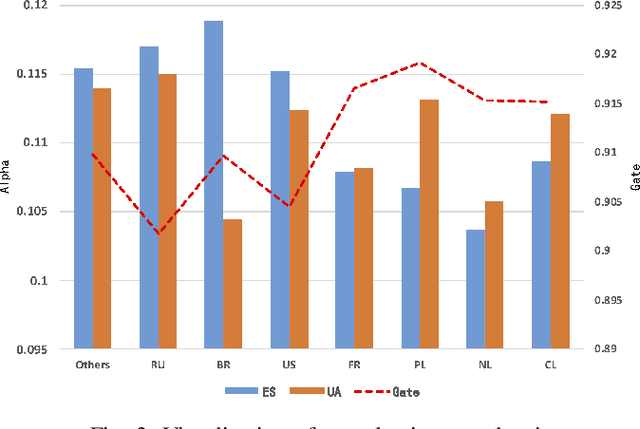
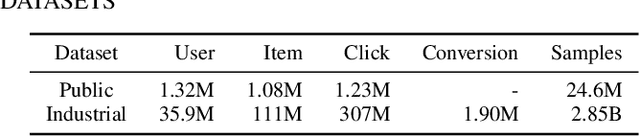
Recommender systems (RSs) are essential for e-commerce platforms to help meet the enormous needs of users. How to capture user interests and make accurate recommendations for users in heterogeneous e-commerce scenarios is still a continuous research topic. However, most existing studies overlook the intrinsic association of the scenarios: the log data collected from platforms can be naturally divided into different scenarios (e.g., country, city, culture). We observed that the scenarios are heterogeneous because of the huge differences among them. Therefore, a unified model is difficult to effectively capture complex correlations (e.g., differences and similarities) between multiple scenarios thus seriously reducing the accuracy of recommendation results. In this paper, we target the problem of multi-scenario recommendation in e-commerce, and propose a novel recommendation model named Scenario-aware Mutual Learning (SAML) that leverages the differences and similarities between multiple scenarios. We first introduce scenario-aware feature representation, which transforms the embedding and attention modules to map the features into both global and scenario-specific subspace in parallel. Then we introduce an auxiliary network to model the shared knowledge across all scenarios, and use a multi-branch network to model differences among specific scenarios. Finally, we employ a novel mutual unit to adaptively learn the similarity between various scenarios and incorporate it into multi-branch network. We conduct extensive experiments on both public and industrial datasets, empirical results show that SAML consistently and significantly outperforms state-of-the-art methods.