 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWakeword Detection under Distribution Shifts
Jul 13, 2022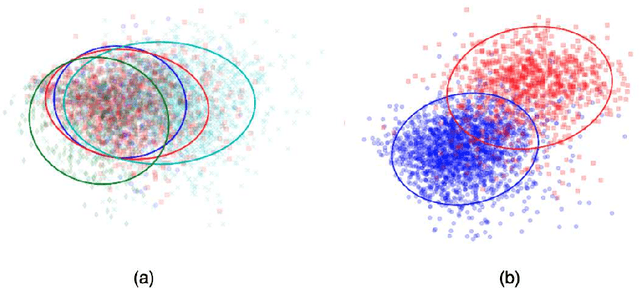
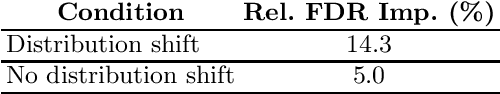
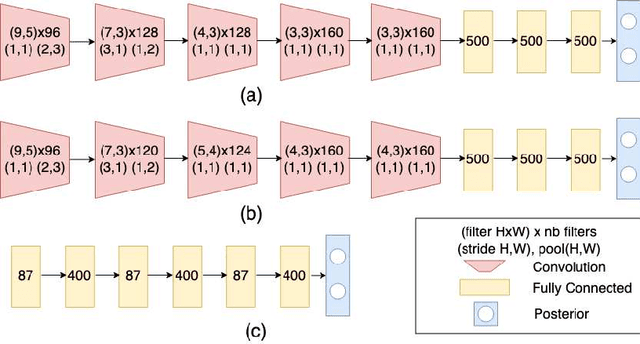
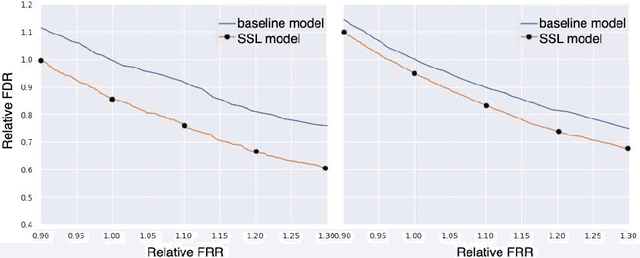
We propose a novel approach for semi-supervised learning (SSL) designed to overcome distribution shifts between training and real-world data arising in the keyword spotting (KWS) task. Shifts from training data distribution are a key challenge for real-world KWS tasks: when a new model is deployed on device, the gating of the accepted data undergoes a shift in distribution, making the problem of timely updates via subsequent deployments hard. Despite the shift, we assume that the marginal distributions on labels do not change. We utilize a modified teacher/student training framework, where labeled training data is augmented with unlabeled data. Note that the teacher does not have access to the new distribution as well. To train effectively with a mix of human and teacher labeled data, we develop a teacher labeling strategy based on confidence heuristics to reduce entropy on the label distribution from the teacher model; the data is then sampled to match the marginal distribution on the labels. Large scale experimental results show that a convolutional neural network (CNN) trained on far-field audio, and evaluated on far-field audio drawn from a different distribution, obtains a 14.3% relative improvement in false discovery rate (FDR) at equal false reject rate (FRR), while yielding a 5% improvement in FDR under no distribution shift. Under a more severe distribution shift from far-field to near-field audio with a smaller fully connected network (FCN) our approach achieves a 52% relative improvement in FDR at equal FRR, while yielding a 20% relative improvement in FDR on the original distribution.
Latency Control for Keyword Spotting
Jun 15, 2022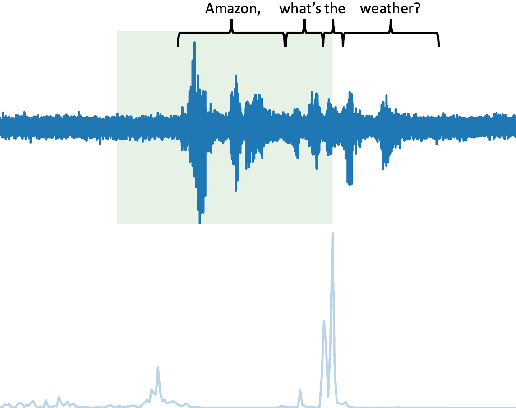

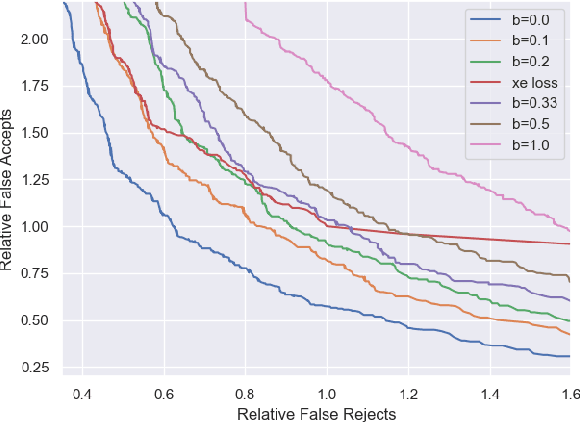
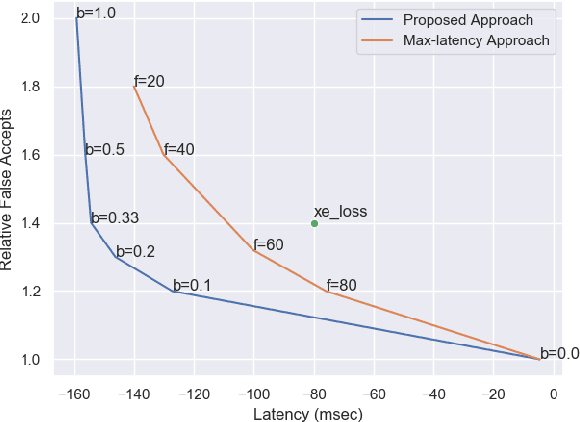
Conversational agents commonly utilize keyword spotting (KWS) to initiate voice interaction with the user. For user experience and privacy considerations, existing approaches to KWS largely focus on accuracy, which can often come at the expense of introduced latency. To address this tradeoff, we propose a novel approach to control KWS model latency and which generalizes to any loss function without explicit knowledge of the keyword endpoint. Through a single, tunable hyperparameter, our approach enables one to balance detection latency and accuracy for the targeted application. Empirically, we show that our approach gives superior performance under latency constraints when compared to existing methods. Namely, we make a substantial 25\% relative false accepts improvement for a fixed latency target when compared to the baseline state-of-the-art. We also show that when our approach is used in conjunction with a max-pooling loss, we are able to improve relative false accepts by 25 % at a fixed latency when compared to cross entropy loss.
Probabilistic Semantic Retrieval for Surveillance Videos with Activity Graphs
Aug 22, 2018
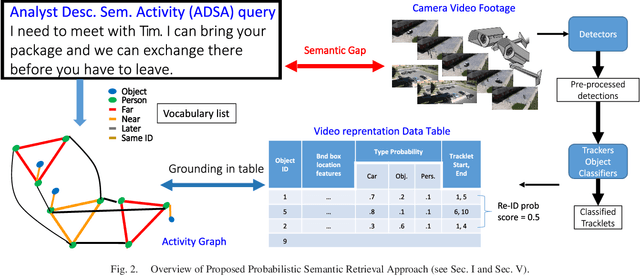
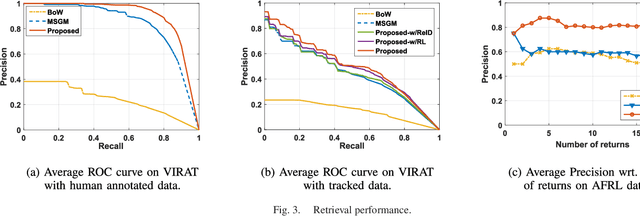
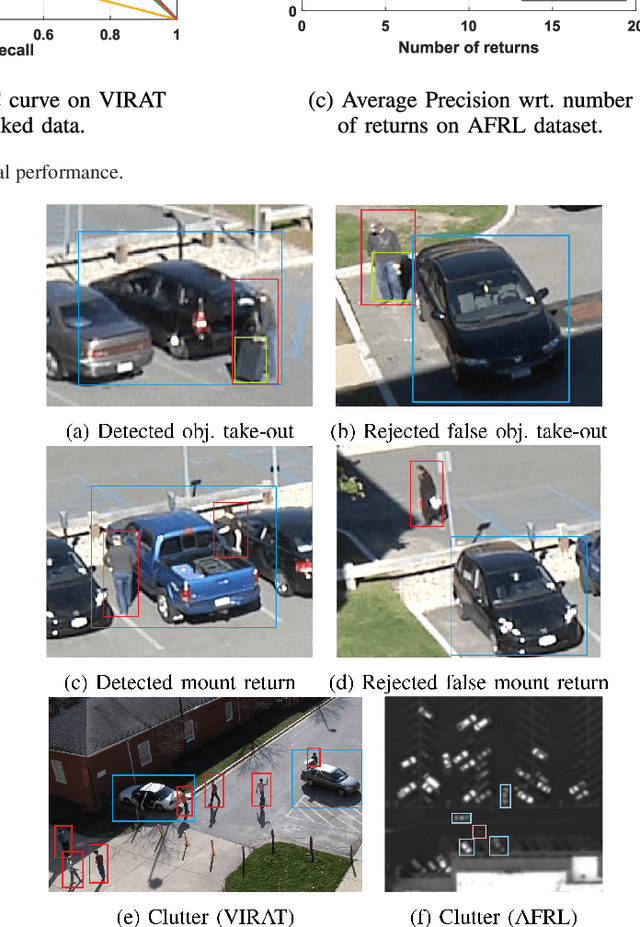
We present a novel framework for finding complex activities matching user-described queries in cluttered surveillance videos. The wide diversity of queries coupled with unavailability of annotated activity data limits our ability to train activity models. To bridge the semantic gap we propose to let users describe an activity as a semantic graph with object attributes and inter-object relationships associated with nodes and edges, respectively. We learn node/edge-level visual predictors during training and, at test-time, propose to retrieve activity by identifying likely locations that match the semantic graph. We formulate a novel CRF based probabilistic activity localization objective that accounts for mis-detections, mis-classifications and track-losses, and outputs a likelihood score for a candidate grounded location of the query in the video. We seek groundings that maximize overall precision and recall. To handle the combinatorial search over all high-probability groundings, we propose a highest precision subgraph matching algorithm. Our method outperforms existing retrieval methods on benchmarked datasets.
Adaptive Neural Networks for Efficient Inference
Sep 18, 2017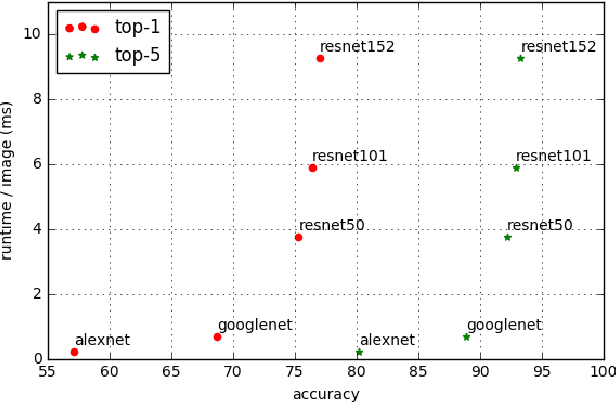
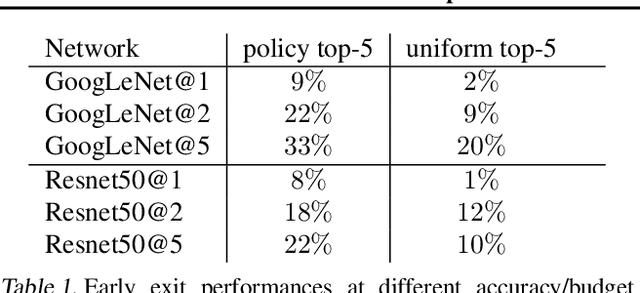
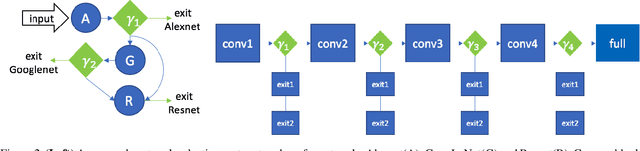
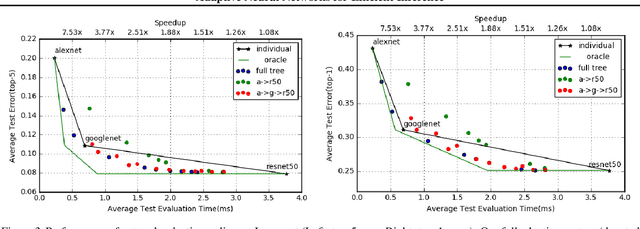
We present an approach to adaptively utilize deep neural networks in order to reduce the evaluation time on new examples without loss of accuracy. Rather than attempting to redesign or approximate existing networks, we propose two schemes that adaptively utilize networks. We first pose an adaptive network evaluation scheme, where we learn a system to adaptively choose the components of a deep network to be evaluated for each example. By allowing examples correctly classified using early layers of the system to exit, we avoid the computational time associated with full evaluation of the network. We extend this to learn a network selection system that adaptively selects the network to be evaluated for each example. We show that computational time can be dramatically reduced by exploiting the fact that many examples can be correctly classified using relatively efficient networks and that complex, computationally costly networks are only necessary for a small fraction of examples. We pose a global objective for learning an adaptive early exit or network selection policy and solve it by reducing the policy learning problem to a layer-by-layer weighted binary classification problem. Empirically, these approaches yield dramatic reductions in computational cost, with up to a 2.8x speedup on state-of-the-art networks from the ImageNet image recognition challenge with minimal (<1%) loss of top5 accuracy.
Field of Groves: An Energy-Efficient Random Forest
Apr 10, 2017



Machine Learning (ML) algorithms, like Convolutional Neural Networks (CNN), Support Vector Machines (SVM), etc. have become widespread and can achieve high statistical performance. However their accuracy decreases significantly in energy-constrained mobile and embedded systems space, where all computations need to be completed under a tight energy budget. In this work, we present a field of groves (FoG) implementation of random forests (RF) that achieves an accuracy comparable to CNNs and SVMs under tight energy budgets. Evaluation of the FoG shows that at comparable accuracy it consumes ~1.48x, ~24x, ~2.5x, and ~34.7x lower energy per classification compared to conventional RF, SVM_RBF , MLP, and CNN, respectively. FoG is ~6.5x less energy efficient than SVM_LR, but achieves 18% higher accuracy on average across all considered datasets.
Pruning Random Forests for Prediction on a Budget
Jun 16, 2016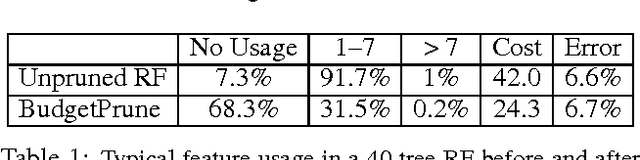

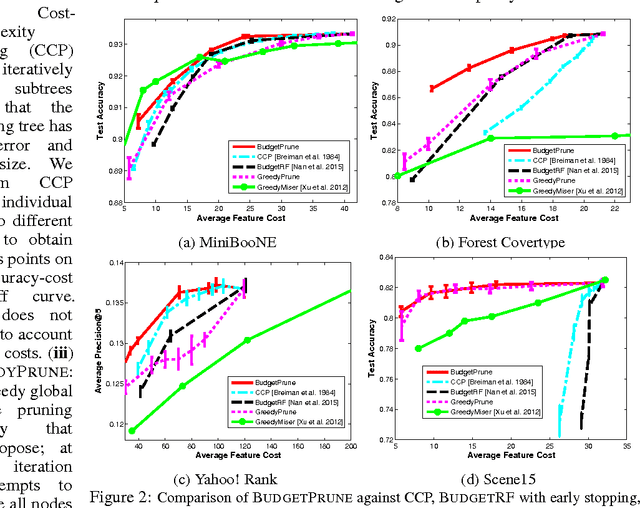
We propose to prune a random forest (RF) for resource-constrained prediction. We first construct a RF and then prune it to optimize expected feature cost & accuracy. We pose pruning RFs as a novel 0-1 integer program with linear constraints that encourages feature re-use. We establish total unimodularity of the constraint set to prove that the corresponding LP relaxation solves the original integer program. We then exploit connections to combinatorial optimization and develop an efficient primal-dual algorithm, scalable to large datasets. In contrast to our bottom-up approach, which benefits from good RF initialization, conventional methods are top-down acquiring features based on their utility value and is generally intractable, requiring heuristics. Empirically, our pruning algorithm outperforms existing state-of-the-art resource-constrained algorithms.
Resource Constrained Structured Prediction
Jun 08, 2016
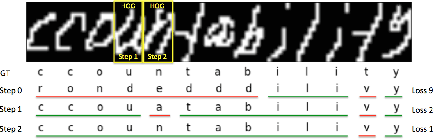
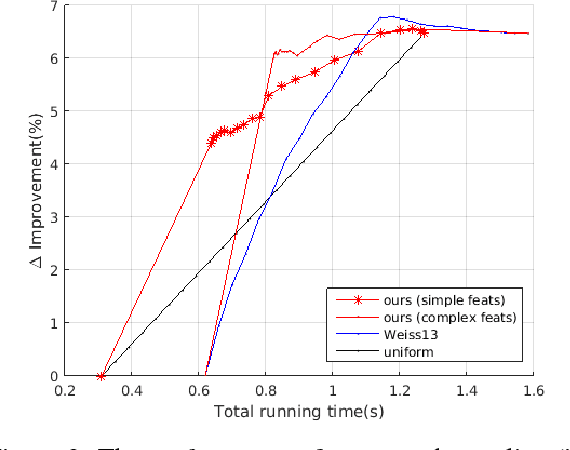
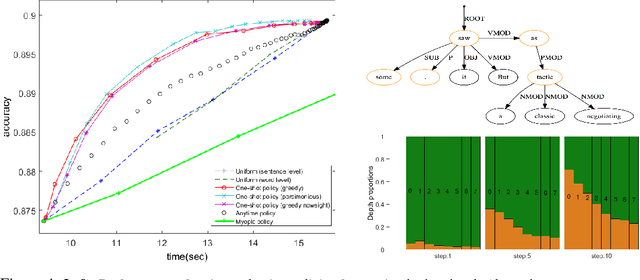
We study the problem of structured prediction under test-time budget constraints. We propose a novel approach applicable to a wide range of structured prediction problems in computer vision and natural language processing. Our approach seeks to adaptively generate computationally costly features during test-time in order to reduce the computational cost of prediction while maintaining prediction performance. We show that training the adaptive feature generation system can be reduced to a series of structured learning problems, resulting in efficient training using existing structured learning algorithms. This framework provides theoretical justification for several existing heuristic approaches found in literature. We evaluate our proposed adaptive system on two structured prediction tasks, optical character recognition (OCR) and dependency parsing and show strong performance in reduction of the feature costs without degrading accuracy.
Optimally Pruning Decision Tree Ensembles With Feature Cost
Jan 05, 2016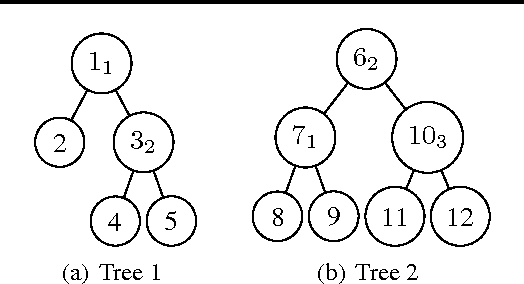
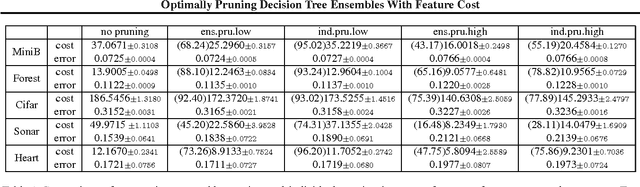
We consider the problem of learning decision rules for prediction with feature budget constraint. In particular, we are interested in pruning an ensemble of decision trees to reduce expected feature cost while maintaining high prediction accuracy for any test example. We propose a novel 0-1 integer program formulation for ensemble pruning. Our pruning formulation is general - it takes any ensemble of decision trees as input. By explicitly accounting for feature-sharing across trees together with accuracy/cost trade-off, our method is able to significantly reduce feature cost by pruning subtrees that introduce more loss in terms of feature cost than benefit in terms of prediction accuracy gain. Theoretically, we prove that a linear programming relaxation produces the exact solution of the original integer program. This allows us to use efficient convex optimization tools to obtain an optimally pruned ensemble for any given budget. Empirically, we see that our pruning algorithm significantly improves the performance of the state of the art ensemble method BudgetRF.
Efficient Learning by Directed Acyclic Graph For Resource Constrained Prediction
Oct 26, 2015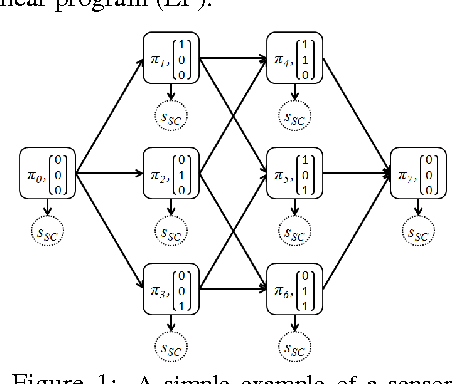
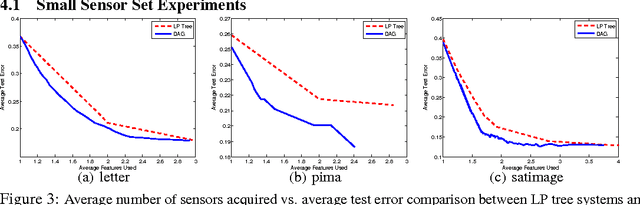
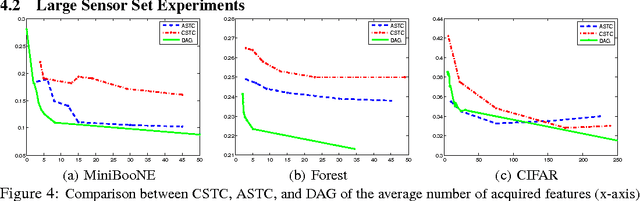
We study the problem of reducing test-time acquisition costs in classification systems. Our goal is to learn decision rules that adaptively select sensors for each example as necessary to make a confident prediction. We model our system as a directed acyclic graph (DAG) where internal nodes correspond to sensor subsets and decision functions at each node choose whether to acquire a new sensor or classify using the available measurements. This problem can be naturally posed as an empirical risk minimization over training data. Rather than jointly optimizing such a highly coupled and non-convex problem over all decision nodes, we propose an efficient algorithm motivated by dynamic programming. We learn node policies in the DAG by reducing the global objective to a series of cost sensitive learning problems. Our approach is computationally efficient and has proven guarantees of convergence to the optimal system for a fixed architecture. In addition, we present an extension to map other budgeted learning problems with large number of sensors to our DAG architecture and demonstrate empirical performance exceeding state-of-the-art algorithms for data composed of both few and many sensors.
Sensor Selection by Linear Programming
Sep 09, 2015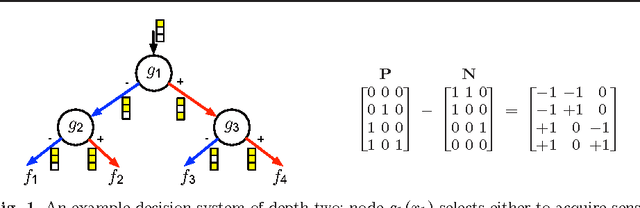

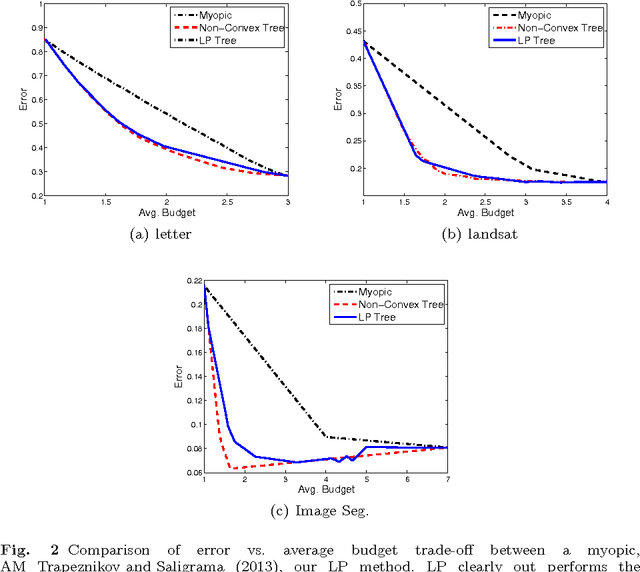
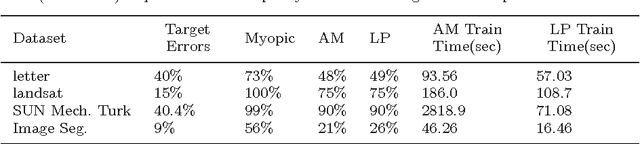
We learn sensor trees from training data to minimize sensor acquisition costs during test time. Our system adaptively selects sensors at each stage if necessary to make a confident classification. We pose the problem as empirical risk minimization over the choice of trees and node decision rules. We decompose the problem, which is known to be intractable, into combinatorial (tree structures) and continuous parts (node decision rules) and propose to solve them separately. Using training data we greedily solve for the combinatorial tree structures and for the continuous part, which is a non-convex multilinear objective function, we derive convex surrogate loss functions that are piecewise linear. The resulting problem can be cast as a linear program and has the advantage of guaranteed convergence, global optimality, repeatability and computational efficiency. We show that our proposed approach outperforms the state-of-art on a number of benchmark datasets.