 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPOT-E: Test-Time Entropy Shaping with Visual Spotlights for Frozen VLMs
Jun 18, 2026Vision-language models (VLMs) often underperform on evidence intensive tasks because decisive visual evidence are small, localized, and easy to overlook, leading to failures in evidence readout even when high-level reasoning is intact. Prior inference-time visual interventions can improve grounding without retraining, but they are largely open-loop and lack a mechanism to verify whether highlighted evidence is actually used. We study answer-span prediction entropy as a model-internal feedback signal and show that naive entropy minimization is ambiguous, since low entropy may arise from evidence-grounded confidence or shortcut collapse. To resolve this ambiguity, we introduce low-entropy anchors and an entropy-shaping objective that reduces answer uncertainty while preserving baseline high-confidence tokens. We instantiate this principle in SPOT-E, a plug-and-play test-time method that produces question-conditioned spotlights, optimized per instance via light-weight tuning based on Group Relative Policy Optimization (GRPO). Across all benchmarks and different VLM families, SPOT-E yields consistent gains and improved robustness under visual corruptions. Code is publicly available at: \url{https://github.com/YinBo0927/SPOT-E}
From Trajectories to Phenotypes: Disease Progression as Structural Priors for Multi-organ Imaging Representation Learning
May 12, 2026Imaging-derived phenotypes (IDPs) summarize multi-organ physiology but provide only static snapshots of diseases that evolve over time. In contrast, longitudinal electronic health records encode disease trajectories through temporal dependencies among past diagnosis events and comorbidity structure. We hypothesize that IDPs and disease trajectories contain partially shared disease-relevant structure. We propose a trajectory-aware distillation framework that transfers structural knowledge from a generative disease trajectory Transformer into an organ-wise IDP encoder. A population-scale trajectory model trained on longitudinal diagnosis sequences produces subject-level embeddings that supervise IDP representation learning via geometry-preserving alignment. During downstream prediction, trajectory and imaging representations can also be fused via cross-attention. Across 159 diseases in the UK Biobank cohort, trajectory-aware pretraining consistently improves both discrimination (AUC) and time-to-onset prediction (MAE), with the largest gains for low-prevalence diseases. Similarity relationships in IDP embedding space also align with those in trajectory space, providing supportive evidence for partially aligned representation geometry. These results suggest that population-scale generative disease models can serve as structural priors for data-limited imaging modalities, improving robustness under realistic cohort constraints.
AD-CARE: A Guideline-grounded, Modality-agnostic LLM Agent for Real-world Alzheimer's Disease Diagnosis with Multi-cohort Assessment, Fairness Analysis, and Reader Study
Mar 26, 2026Alzheimer's disease (AD) is a growing global health challenge as populations age, and timely, accurate diagnosis is essential to reduce individual and societal burden. However, real-world AD assessment is hampered by incomplete, heterogeneous multimodal data and variability across sites and patient demographics. Although large language models (LLMs) have shown promise in biomedicine, their use in AD has largely been confined to answering narrow, disease-specific questions rather than generating comprehensive diagnostic reports that support clinical decision-making. Here we expand LLM capabilities for clinical decision support by introducing AD-CARE, a modality-agnostic agent that performs guideline-grounded diagnostic assessment from incomplete, heterogeneous inputs without imputing missing modalities. By dynamically orchestrating specialized diagnostic tools and embedding clinical guidelines into LLM-driven reasoning, AD-CARE generates transparent, report-style outputs aligned with real-world clinical workflows. Across six cohorts comprising 10,303 cases, AD-CARE achieved 84.9% diagnostic accuracy, delivering 4.2%-13.7% relative improvements over baseline methods. Despite cohort-level differences, dataset-specific accuracies remain robust (80.4%-98.8%), and the agent consistently outperforms all baselines. AD-CARE reduced performance disparities across racial and age subgroups, decreasing the average dispersion of four metrics by 21%-68% and 28%-51%, respectively. In a controlled reader study, the agent improved neurologist and radiologist accuracy by 6%-11% and more than halved decision time. The framework yielded 2.29%-10.66% absolute gains over eight backbone LLMs and converges their performance. These results show that AD-CARE is a scalable, practically deployable framework that can be integrated into routine clinical workflows for multimodal decision support in AD.
SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents
Jan 23, 2026LLM agents have demonstrated remarkable capabilities in software development, but their performance is hampered by long interaction contexts, which incur high API costs and latency. While various context compression approaches such as LongLLMLingua have emerged to tackle this challenge, they typically rely on fixed metrics such as PPL, ignoring the task-specific nature of code understanding. As a result, they frequently disrupt syntactic and logical structure and fail to retain critical implementation details. In this paper, we propose SWE-Pruner, a self-adaptive context pruning framework tailored for coding agents. Drawing inspiration from how human programmers "selectively skim" source code during development and debugging, SWE-Pruner performs task-aware adaptive pruning for long contexts. Given the current task, the agent formulates an explicit goal (e.g., "focus on error handling") as a hint to guide the pruning targets. A lightweight neural skimmer (0.6B parameters) is trained to dynamically select relevant lines from the surrounding context given the goal. Evaluations across four benchmarks and multiple models validate SWE-Pruner's effectiveness in various scenarios, achieving 23-54% token reduction on agent tasks like SWE-Bench Verified and up to 14.84x compression on single-turn tasks like LongCodeQA with minimal performance impact.
Reasoning in Trees: Improving Retrieval-Augmented Generation for Multi-Hop Question Answering
Jan 16, 2026Retrieval-Augmented Generation (RAG) has demonstrated significant effectiveness in enhancing large language models (LLMs) for complex multi-hop question answering (QA). For multi-hop QA tasks, current iterative approaches predominantly rely on LLMs to self-guide and plan multi-step exploration paths during retrieval, leading to substantial challenges in maintaining reasoning coherence across steps from inaccurate query decomposition and error propagation. To address these issues, we introduce Reasoning Tree Guided RAG (RT-RAG), a novel hierarchical framework for complex multi-hop QA. RT-RAG systematically decomposes multi-hop questions into explicit reasoning trees, minimizing inaccurate decomposition through structured entity analysis and consensus-based tree selection that clearly separates core queries, known entities, and unknown entities. Subsequently, a bottom-up traversal strategy employs iterative query rewriting and refinement to collect high-quality evidence, thereby mitigating error propagation. Comprehensive experiments show that RT-RAG substantially outperforms state-of-the-art methods by 7.0% F1 and 6.0% EM, demonstrating the effectiveness of RT-RAG in complex multi-hop QA.
Tropical Cyclone Track Forecasting using Fused Deep Learning from Aligned Reanalysis Data
Oct 23, 2019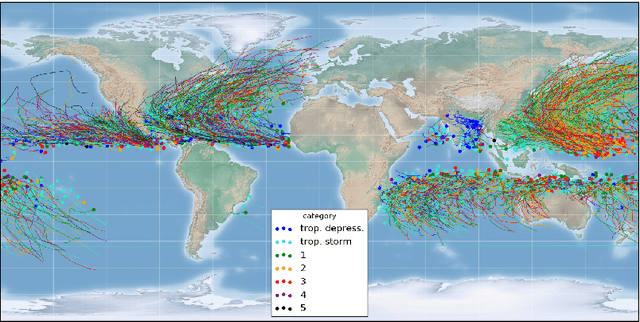
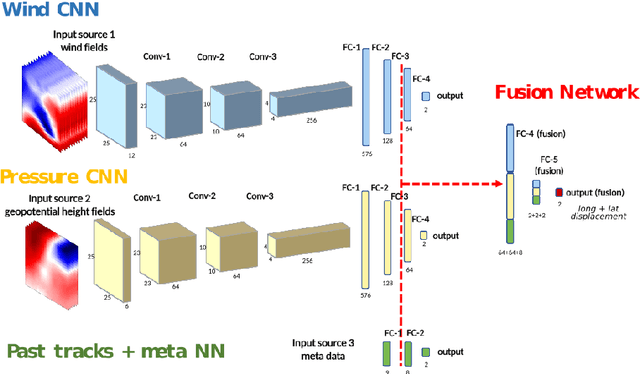

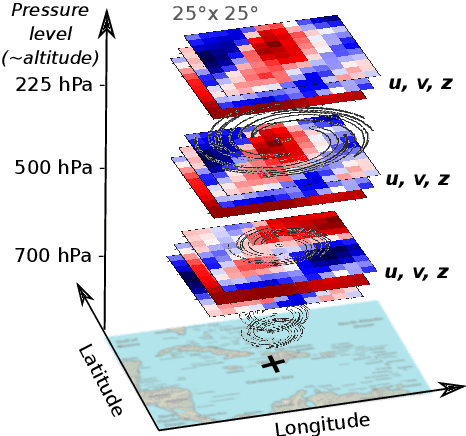
The forecast of tropical cyclone trajectories is crucial for the protection of people and property. Although forecast dynamical models can provide high-precision short-term forecasts, they are computationally demanding, and current statistical forecasting models have much room for improvement given that the database of past hurricanes is constantly growing. Machine learning methods, that can capture non-linearities and complex relations, have only been scarcely tested for this application. We propose a neural network model fusing past trajectory data and reanalysis atmospheric images (wind and pressure 3D fields). We use a moving frame of reference that follows the storm center for the 24h tracking forecast. The network is trained to estimate the longitude and latitude displacement of tropical cyclones and depressions from a large database from both hemispheres (more than 3000 storms since 1979, sampled at a 6 hour frequency). The advantage of the fused network is demonstrated and a comparison with current forecast models shows that deep learning methods could provide a valuable and complementary prediction. Moreover, our method can give a forecast for a new storm in a few seconds, which is an important asset for real-time forecasts compared to traditional forecasts.