 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFNet: Faster, Accurate, and Domain Agnostic Semantic Segmentation via Semantic Flow
Jul 10, 2022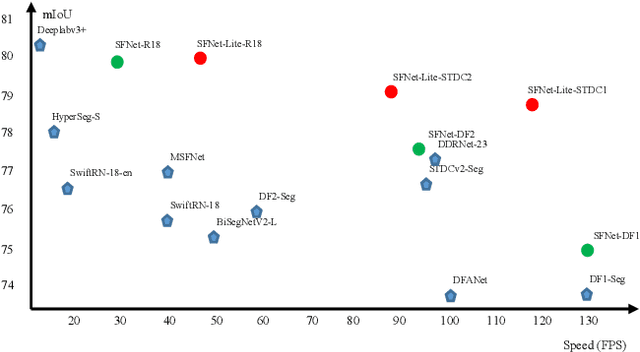

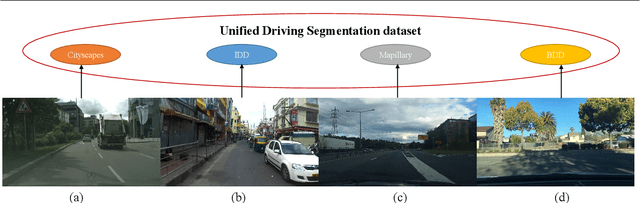
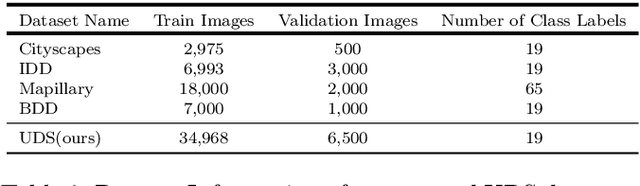
In this paper, we focus on exploring effective methods for faster, accurate, and domain agnostic semantic segmentation. Inspired by the Optical Flow for motion alignment between adjacent video frames, we propose a Flow Alignment Module (FAM) to learn \textit{Semantic Flow} between feature maps of adjacent levels, and broadcast high-level features to high resolution features effectively and efficiently. Furthermore, integrating our FAM to a common feature pyramid structure exhibits superior performance over other real-time methods even on light-weight backbone networks, such as ResNet-18 and DFNet. Then to further speed up the inference procedure, we also present a novel Gated Dual Flow Alignment Module to directly align high resolution feature maps and low resolution feature maps where we term improved version network as SFNet-Lite. Extensive experiments are conducted on several challenging datasets, where results show the effectiveness of both SFNet and SFNet-Lite. In particular, the proposed SFNet-Lite series achieve 80.1 mIoU while running at 60 FPS using ResNet-18 backbone and 78.8 mIoU while running at 120 FPS using STDC backbone on RTX-3090. Moreover, we unify four challenging driving datasets (i.e., Cityscapes, Mapillary, IDD and BDD) into one large dataset, which we named Unified Driving Segmentation (UDS) dataset. It contains diverse domain and style information. We benchmark several representative works on UDS. Both SFNet and SFNet-Lite still achieve the best speed and accuracy trade-off on UDS which serves as a strong baseline in such a new challenging setting. All the code and models are publicly available at https://github.com/lxtGH/SFSegNets.
Multi-Task Learning with Multi-query Transformer for Dense Prediction
May 31, 2022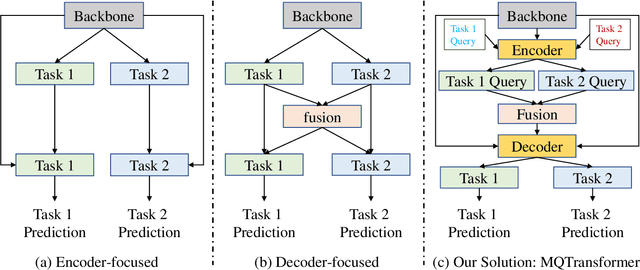
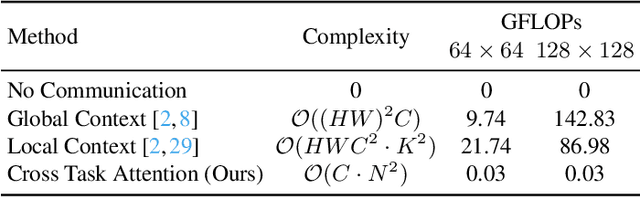
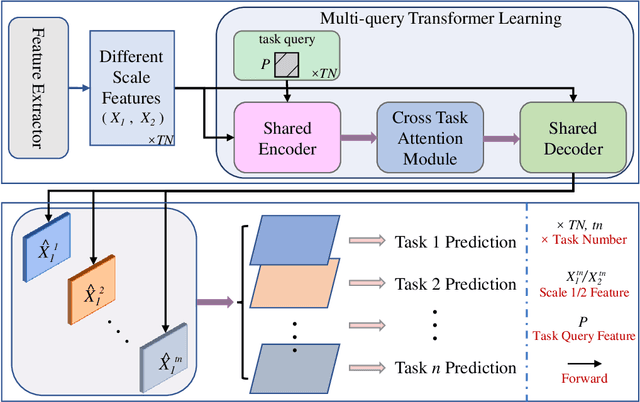
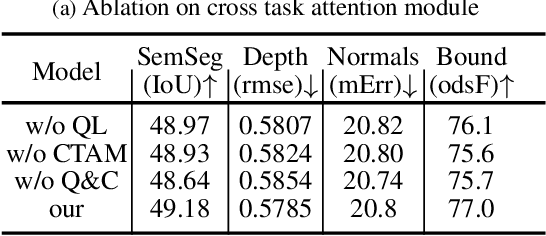
Previous multi-task dense prediction studies developed complex pipelines such as multi-modal distillations in multiple stages or searching for task relational contexts for each task. The core insight beyond these methods is to maximize the mutual effects between each task. Inspired by the recent query-based Transformers, we propose a simpler pipeline named Multi-Query Transformer (MQTransformer) that is equipped with multiple queries from different tasks to facilitate the reasoning among multiple tasks and simplify the cross task pipeline. Instead of modeling the dense per-pixel context among different tasks, we seek a task-specific proxy to perform cross-task reasoning via multiple queries where each query encodes the task-related context. The MQTransformer is composed of three key components: shared encoder, cross task attention and shared decoder. We first model each task with a task-relevant and scale-aware query, and then both the image feature output by the feature extractor and the task-relevant query feature are fed into the shared encoder, thus encoding the query feature from the image feature. Secondly, we design a cross task attention module to reason the dependencies among multiple tasks and feature scales from two perspectives including different tasks of the same scale and different scales of the same task. Then we use a shared decoder to gradually refine the image features with the reasoned query features from different tasks. Extensive experiment results on two dense prediction datasets (NYUD-v2 and PASCAL-Context) show that the proposed method is an effective approach and achieves the state-of-the-art result. Code will be available.
Video K-Net: A Simple, Strong, and Unified Baseline for Video Segmentation
Apr 10, 2022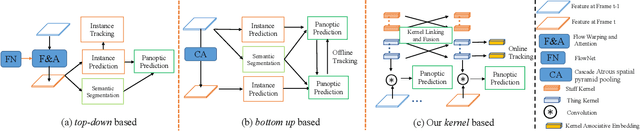

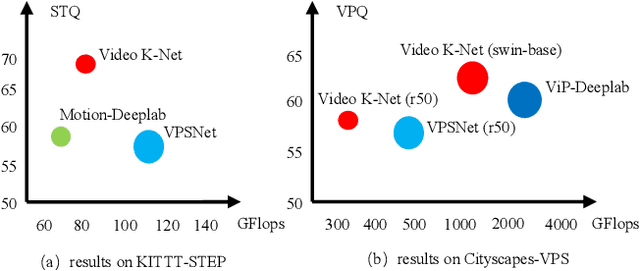
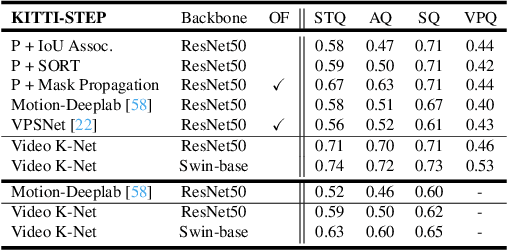
This paper presents Video K-Net, a simple, strong, and unified framework for fully end-to-end video panoptic segmentation. The method is built upon K-Net, a method that unifies image segmentation via a group of learnable kernels. We observe that these learnable kernels from K-Net, which encode object appearances and contexts, can naturally associate identical instances across video frames. Motivated by this observation, Video K-Net learns to simultaneously segment and track "things" and "stuff" in a video with simple kernel-based appearance modeling and cross-temporal kernel interaction. Despite the simplicity, it achieves state-of-the-art video panoptic segmentation results on Citscapes-VPS and KITTI-STEP without bells and whistles. In particular on KITTI-STEP, the simple method can boost almost 12\% relative improvements over previous methods. We also validate its generalization on video semantic segmentation, where we boost various baselines by 2\% on the VSPW dataset. Moreover, we extend K-Net into clip-level video framework for video instance segmentation where we obtain 40.5\% for ResNet50 backbone and 51.5\% mAP for Swin-base on YouTube-2019 validation set. We hope this simple yet effective method can serve as a new flexible baseline in video segmentation. Both code and models are released at https://github.com/lxtGH/Video-K-Net
Panoptic-PartFormer: Learning a Unified Model for Panoptic Part Segmentation
Apr 10, 2022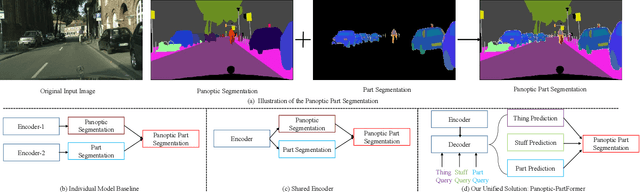

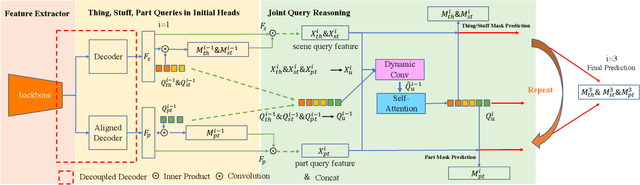
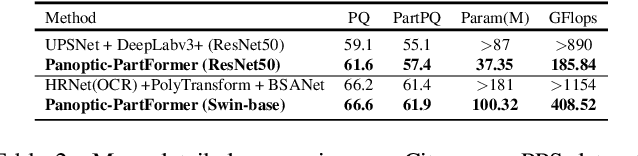
Panoptic Part Segmentation (PPS) aims to unify panoptic segmentation and part segmentation into one task. Previous work mainly utilizes separated approaches to handle thing, stuff, and part predictions individually without performing any shared computation and task association. In this work, we aim to unify these tasks at the architectural level, designing the first end-to-end unified method named Panoptic-PartFormer. In particular, motivated by the recent progress in Vision Transformer, we model things, stuff, and part as object queries and directly learn to optimize the all three predictions as unified mask prediction and classification problem. We design a decoupled decoder to generate part feature and thing/stuff feature respectively. Then we propose to utilize all the queries and corresponding features to perform reasoning jointly and iteratively. The final mask can be obtained via inner product between queries and the corresponding features. The extensive ablation studies and analysis prove the effectiveness of our framework. Our Panoptic-PartFormer achieves the new state-of-the-art results on both Cityscapes PPS and Pascal Context PPS datasets with at least 70% GFlops and 50% parameters decrease. In particular, we get 3.4% relative improvements with ResNet50 backbone and 10% improvements after adopting Swin Transformer on Pascal Context PPS dataset. To the best of our knowledge, we are the first to solve the PPS problem via \textit{a unified and end-to-end transformer model. Given its effectiveness and conceptual simplicity, we hope our Panoptic-PartFormer can serve as a good baseline and aid future unified research for PPS. Our code and models will be available at https://github.com/lxtGH/Panoptic-PartFormer.
Fashionformer: A simple, Effective and Unified Baseline for Human Fashion Segmentation and Recognition
Apr 10, 2022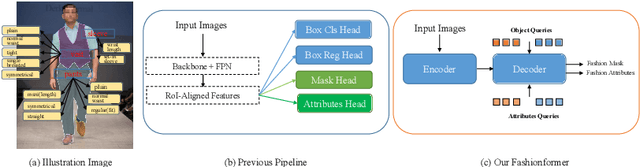
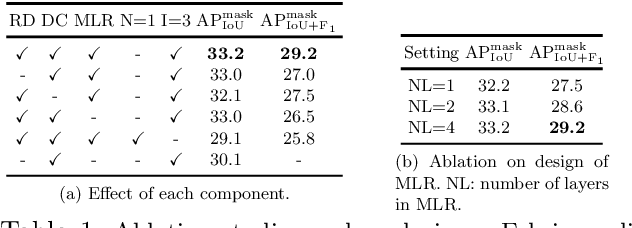
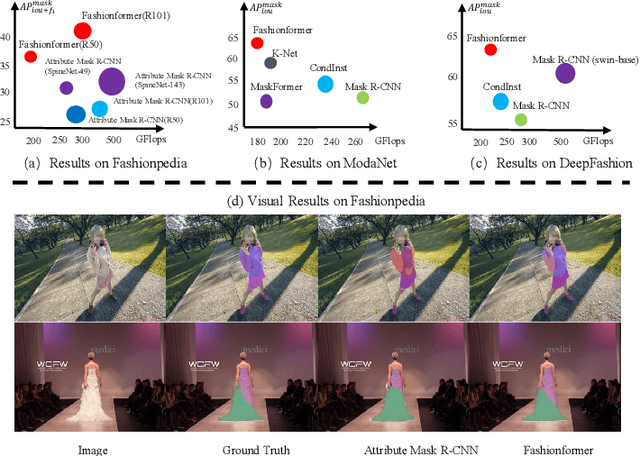
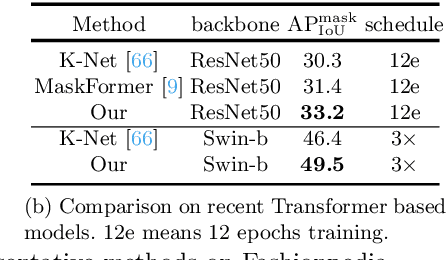
Human fashion understanding is one important computer vision task since it has the comprehensive information that can be used for real-world applications. In this work, we focus on joint human fashion segmentation and attribute recognition. Contrary to the previous works that separately model each task as a multi-head prediction problem, our insight is to bridge these two tasks with one unified model via vision transformer modeling to benefit each task. In particular, we introduce the object query for segmentation and the attribute query for attribute prediction. Both queries and their corresponding features can be linked via mask prediction. Then we adopt a two-stream query learning framework to learn the decoupled query representations. For attribute stream, we design a novel Multi-Layer Rendering module to explore more fine-grained features. The decoder design shares the same spirits with DETR, thus we name the proposed method Fahsionformer. Extensive experiments on three human fashion datasets including Fashionpedia, ModaNet and Deepfashion illustrate the effectiveness of our approach. In particular, our method with the same backbone achieve relative 10% improvements than previous works in case of \textit{a joint metric ( AP$^{\text{mask}}_{\text{IoU+F}_1}$) for both segmentation and attribute recognition}. To the best of our knowledge, we are the first unified end-to-end vision transformer framework for human fashion analysis. We hope this simple yet effective method can serve as a new flexible baseline for fashion analysis. Code will be available at https://github.com/xushilin1/FashionFormer.
TransVOD: End-to-end Video Object Detection with Spatial-Temporal Transformers
Jan 17, 2022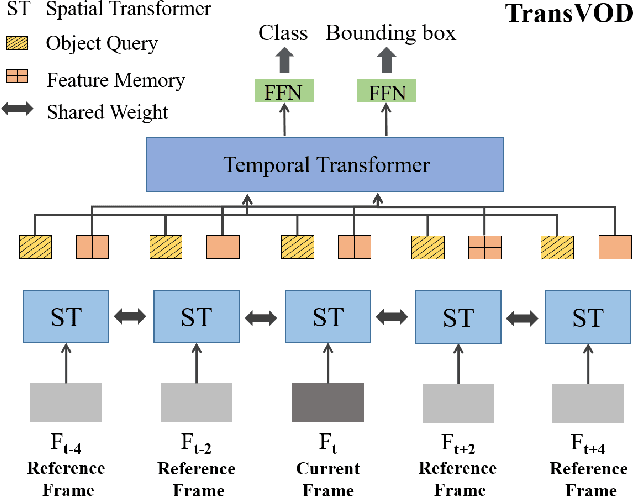
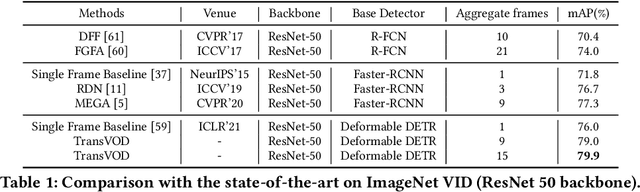
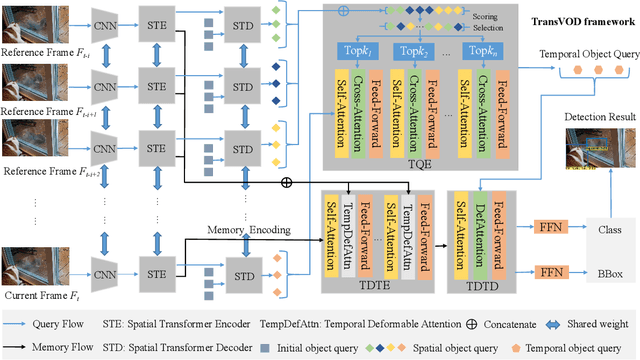
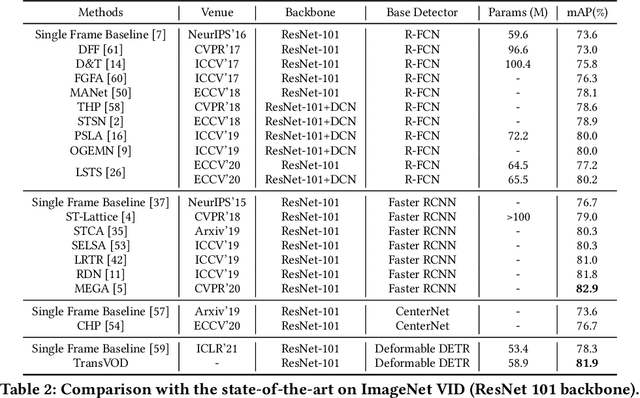
Detection Transformer (DETR) and Deformable DETR have been proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance as previous complex hand-crafted detectors. However, their performance on Video Object Detection (VOD) has not been well explored. In this paper, we present TransVOD, the first end-to-end video object detection system based on spatial-temporal Transformer architectures. The first goal of this paper is to streamline the pipeline of VOD, effectively removing the need for many hand-crafted components for feature aggregation, e.g., optical flow model, relation networks. Besides, benefited from the object query design in DETR, our method does not need complicated post-processing methods such as Seq-NMS. In particular, we present a temporal Transformer to aggregate both the spatial object queries and the feature memories of each frame. Our temporal transformer consists of two components: Temporal Query Encoder (TQE) to fuse object queries, and Temporal Deformable Transformer Decoder (TDTD) to obtain current frame detection results. These designs boost the strong baseline deformable DETR by a significant margin (3%-4% mAP) on the ImageNet VID dataset. Then, we present two improved versions of TransVOD including TransVOD++ and TransVOD Lite. The former fuses object-level information into object query via dynamic convolution while the latter models the entire video clips as the output to speed up the inference time. We give detailed analysis of all three models in the experiment part. In particular, our proposed TransVOD++ sets a new state-of-the-art record in terms of accuracy on ImageNet VID with 90.0% mAP. Our proposed TransVOD Lite also achieves the best speed and accuracy trade-off with 83.7% mAP while running at around 30 FPS on a single V100 GPU device. Code and models will be available for further research.
PolyphonicFormer: Unified Query Learning for Depth-aware Video Panoptic Segmentation
Dec 05, 2021
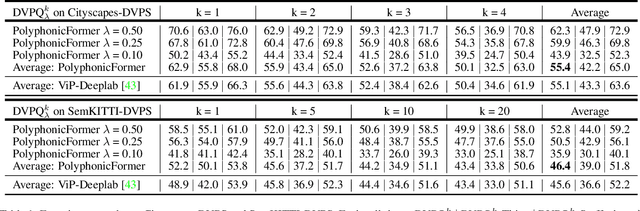
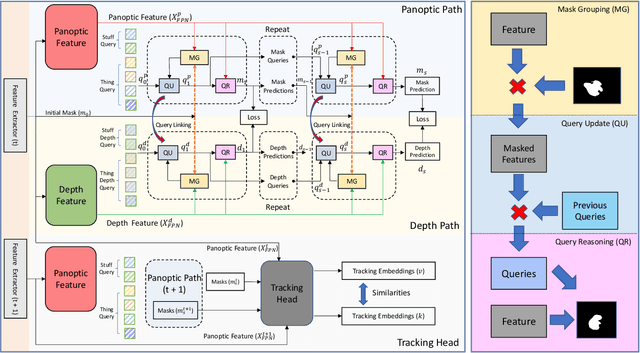
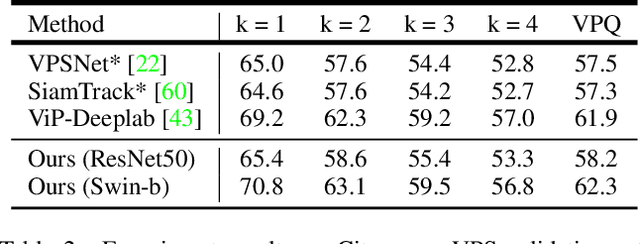
The recently proposed Depth-aware Video Panoptic Segmentation (DVPS) aims to predict panoptic segmentation results and depth maps in a video, which is a challenging scene understanding problem. In this paper, we present PolyphonicFormer, a vision transformer to unify all the sub-tasks under the DVPS task. Our method explores the relationship between depth estimation and panoptic segmentation via query-based learning. In particular, we design three different queries including thing query, stuff query, and depth query. Then we propose to learn the correlations among these queries via gated fusion. From the experiments, we prove the benefits of our design from both depth estimation and panoptic segmentation aspects. Since each thing query also encodes the instance-wise information, it is natural to perform tracking via cropping instance mask features with appearance learning. Our method ranks 1st on the ICCV-2021 BMTT Challenge video + depth track. Ablation studies are reported to show how we improve the performance. Code will be available at https://github.com/HarborYuan/PolyphonicFormer.
Graph Pointer Neural Networks
Oct 03, 2021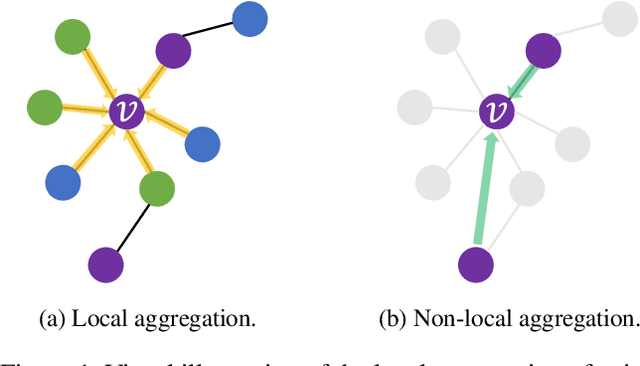
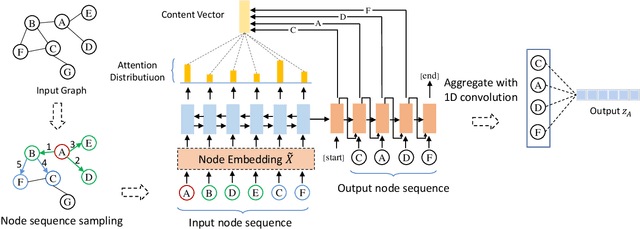
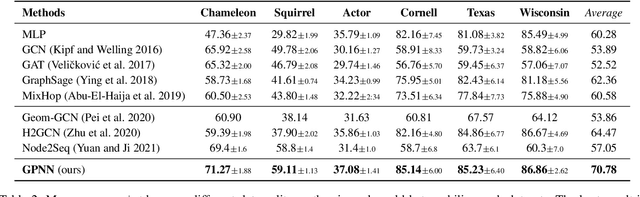
Graph Neural Networks (GNNs) have shown advantages in various graph-based applications. Most existing GNNs assume strong homophily of graph structure and apply permutation-invariant local aggregation of neighbors to learn a representation for each node. However, they fail to generalize to heterophilic graphs, where most neighboring nodes have different labels or features, and the relevant nodes are distant. Few recent studies attempt to address this problem by combining multiple hops of hidden representations of central nodes (i.e., multi-hop-based approaches) or sorting the neighboring nodes based on attention scores (i.e., ranking-based approaches). As a result, these approaches have some apparent limitations. On the one hand, multi-hop-based approaches do not explicitly distinguish relevant nodes from a large number of multi-hop neighborhoods, leading to a severe over-smoothing problem. On the other hand, ranking-based models do not joint-optimize node ranking with end tasks and result in sub-optimal solutions. In this work, we present Graph Pointer Neural Networks (GPNN) to tackle the challenges mentioned above. We leverage a pointer network to select the most relevant nodes from a large amount of multi-hop neighborhoods, which constructs an ordered sequence according to the relationship with the central node. 1D convolution is then applied to extract high-level features from the node sequence. The pointer-network-based ranker in GPNN is joint-optimized with other parts in an end-to-end manner. Extensive experiments are conducted on six public node classification datasets with heterophilic graphs. The results show that GPNN significantly improves the classification performance of state-of-the-art methods. In addition, analyses also reveal the privilege of the proposed GPNN in filtering out irrelevant neighbors and reducing over-smoothing.
Competence-based Curriculum Learning for Multilingual Machine Translation
Sep 09, 2021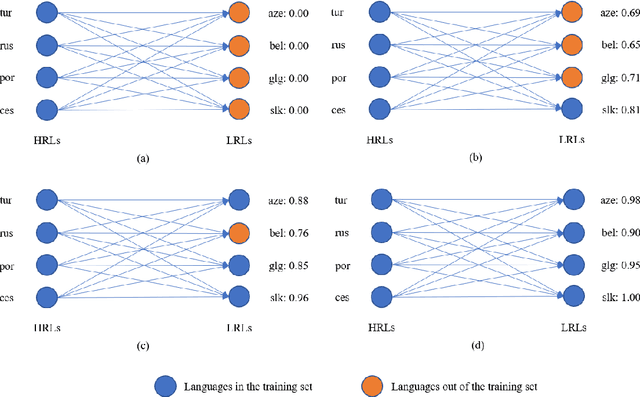
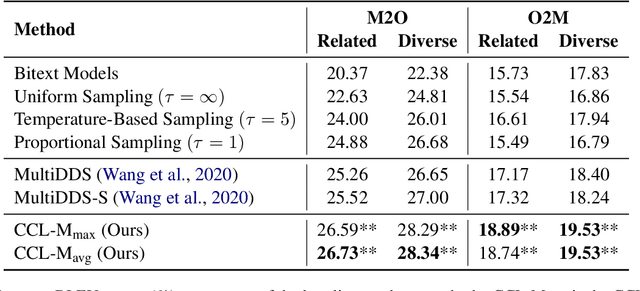
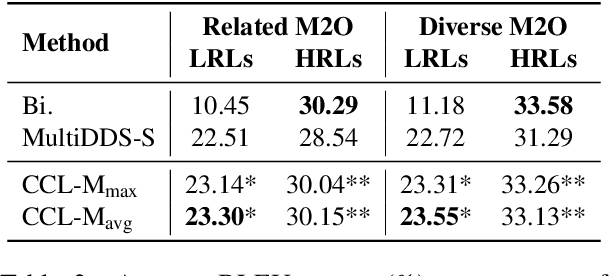
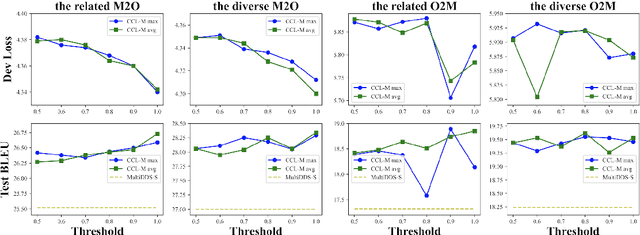
Currently, multilingual machine translation is receiving more and more attention since it brings better performance for low resource languages (LRLs) and saves more space. However, existing multilingual machine translation models face a severe challenge: imbalance. As a result, the translation performance of different languages in multilingual translation models are quite different. We argue that this imbalance problem stems from the different learning competencies of different languages. Therefore, we focus on balancing the learning competencies of different languages and propose Competence-based Curriculum Learning for Multilingual Machine Translation, named CCL-M. Specifically, we firstly define two competencies to help schedule the high resource languages (HRLs) and the low resource languages: 1) Self-evaluated Competence, evaluating how well the language itself has been learned; and 2) HRLs-evaluated Competence, evaluating whether an LRL is ready to be learned according to HRLs' Self-evaluated Competence. Based on the above competencies, we utilize the proposed CCL-M algorithm to gradually add new languages into the training set in a curriculum learning manner. Furthermore, we propose a novel competenceaware dynamic balancing sampling strategy for better selecting training samples in multilingual training. Experimental results show that our approach has achieved a steady and significant performance gain compared to the previous state-of-the-art approach on the TED talks dataset.
Improving Video Instance Segmentation via Temporal Pyramid Routing
Jul 28, 2021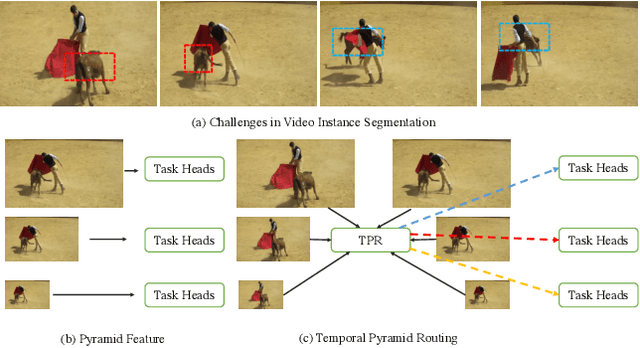
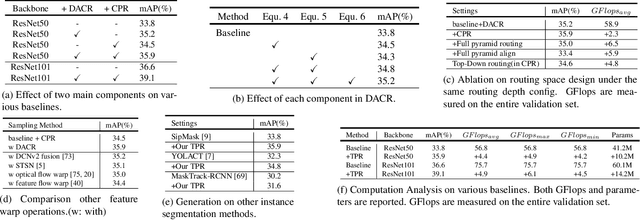
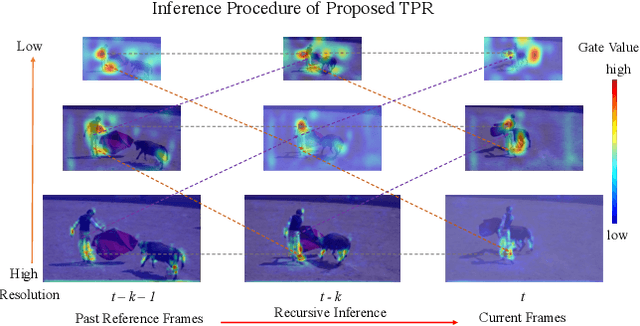
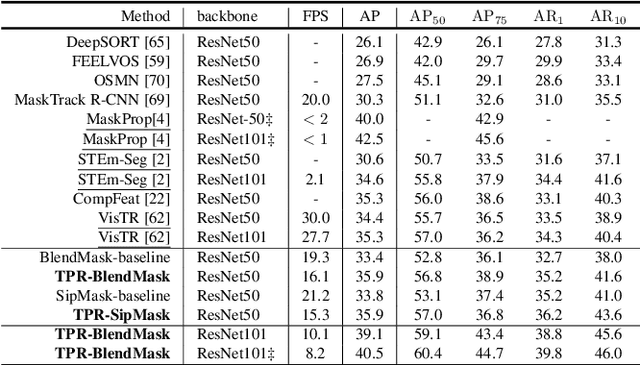
Video Instance Segmentation (VIS) is a new and inherently multi-task problem, which aims to detect, segment and track each instance in a video sequence. Existing approaches are mainly based on single-frame features or single-scale features of multiple frames, where temporal information or multi-scale information is ignored. To incorporate both temporal and scale information, we propose a Temporal Pyramid Routing (TPR) strategy to conditionally align and conduct pixel-level aggregation from a feature pyramid pair of two adjacent frames. Specifically, TPR contains two novel components, including Dynamic Aligned Cell Routing (DACR) and Cross Pyramid Routing (CPR), where DACR is designed for aligning and gating pyramid features across temporal dimension, while CPR transfers temporally aggregated features across scale dimension. Moreover, our approach is a plug-and-play module and can be easily applied to existing instance segmentation methods. Extensive experiments on YouTube-VIS dataset demonstrate the effectiveness and efficiency of the proposed approach on several state-of-the-art instance segmentation methods. Codes and trained models will be publicly available to facilitate future research.(\url{https://github.com/lxtGH/TemporalPyramidRouting}).