 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyphonicFormer: Unified Query Learning for Depth-aware Video Panoptic Segmentation
Paper and Code
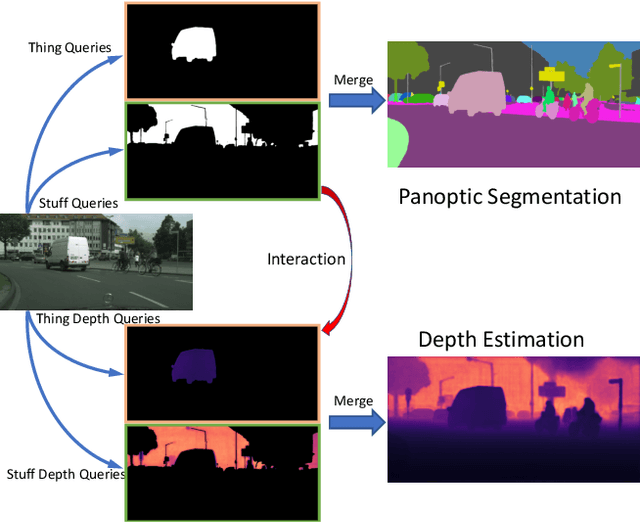
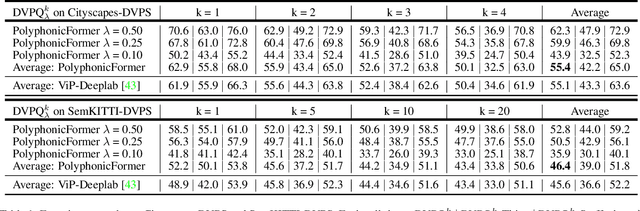
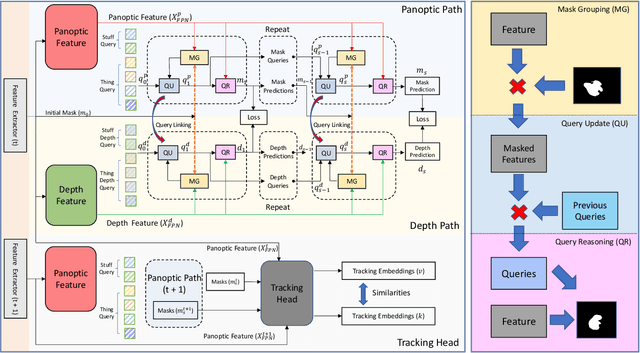
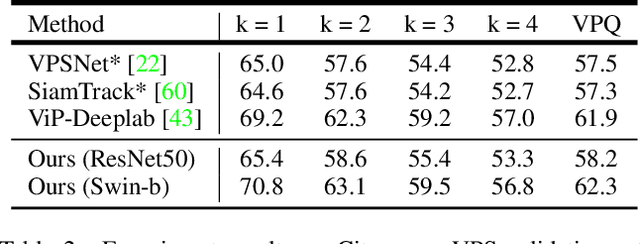
The recently proposed Depth-aware Video Panoptic Segmentation (DVPS) aims to predict panoptic segmentation results and depth maps in a video, which is a challenging scene understanding problem. In this paper, we present PolyphonicFormer, a vision transformer to unify all the sub-tasks under the DVPS task. Our method explores the relationship between depth estimation and panoptic segmentation via query-based learning. In particular, we design three different queries including thing query, stuff query, and depth query. Then we propose to learn the correlations among these queries via gated fusion. From the experiments, we prove the benefits of our design from both depth estimation and panoptic segmentation aspects. Since each thing query also encodes the instance-wise information, it is natural to perform tracking via cropping instance mask features with appearance learning. Our method ranks 1st on the ICCV-2021 BMTT Challenge video + depth track. Ablation studies are reported to show how we improve the performance. Code will be available at https://github.com/HarborYuan/PolyphonicFormer.