 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification-Then-Grounding: Reformulating Video Scene Graphs as Temporal Bipartite Graphs
Dec 08, 2021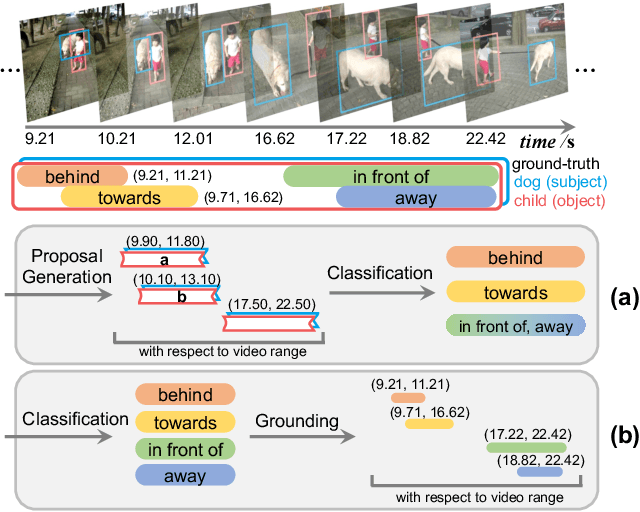
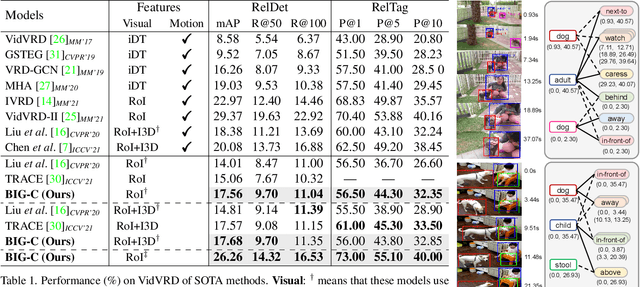
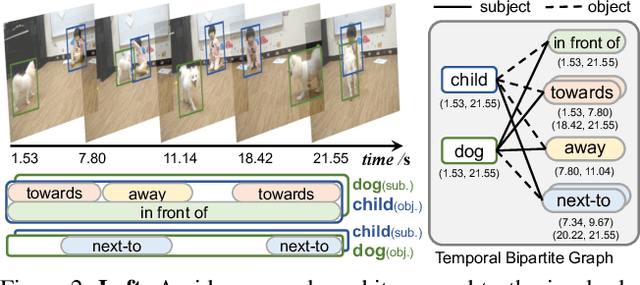
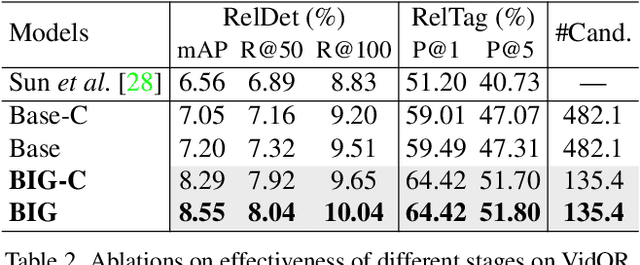
Today's VidSGG models are all proposal-based methods, i.e., they first generate numerous paired subject-object snippets as proposals, and then conduct predicate classification for each proposal. In this paper, we argue that this prevalent proposal-based framework has three inherent drawbacks: 1) The ground-truth predicate labels for proposals are partially correct. 2) They break the high-order relations among different predicate instances of a same subject-object pair. 3) VidSGG performance is upper-bounded by the quality of the proposals. To this end, we propose a new classification-then-grounding framework for VidSGG, which can avoid all the three overlooked drawbacks. Meanwhile, under this framework, we reformulate the video scene graphs as temporal bipartite graphs, where the entities and predicates are two types of nodes with time slots, and the edges denote different semantic roles between these nodes. This formulation takes full advantage of our new framework. Accordingly, we further propose a novel BIpartite Graph based SGG model: BIG. Specifically, BIG consists of two parts: a classification stage and a grounding stage, where the former aims to classify the categories of all the nodes and the edges, and the latter tries to localize the temporal location of each relation instance. Extensive ablations on two VidSGG datasets have attested to the effectiveness of our framework and BIG.
Introspective Distillation for Robust Question Answering
Nov 01, 2021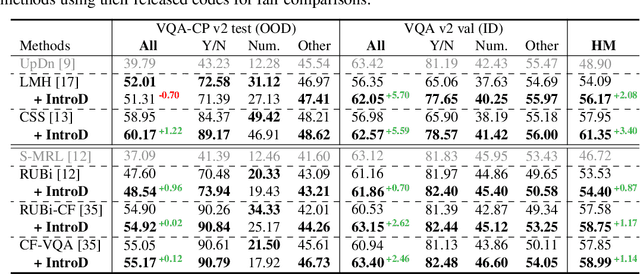

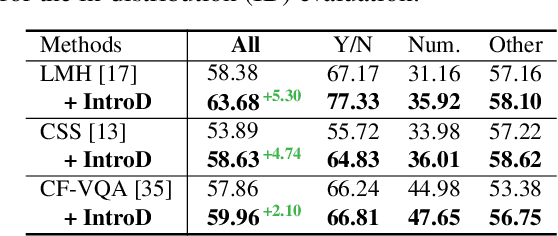
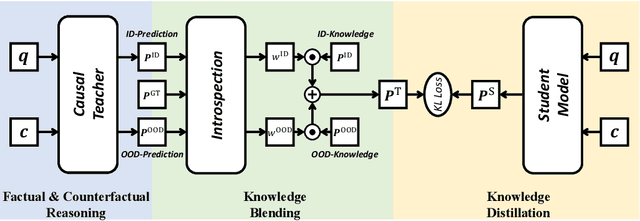
Question answering (QA) models are well-known to exploit data bias, e.g., the language prior in visual QA and the position bias in reading comprehension. Recent debiasing methods achieve good out-of-distribution (OOD) generalizability with a considerable sacrifice of the in-distribution (ID) performance. Therefore, they are only applicable in domains where the test distribution is known in advance. In this paper, we present a novel debiasing method called Introspective Distillation (IntroD) to make the best of both worlds for QA. Our key technical contribution is to blend the inductive bias of OOD and ID by introspecting whether a training sample fits in the factual ID world or the counterfactual OOD one. Experiments on visual QA datasets VQA v2, VQA-CP, and reading comprehension dataset SQuAD demonstrate that our proposed IntroD maintains the competitive OOD performance compared to other debiasing methods, while sacrificing little or even achieving better ID performance compared to the non-debiasing ones.
Counterfactual Samples Synthesizing and Training for Robust Visual Question Answering
Oct 03, 2021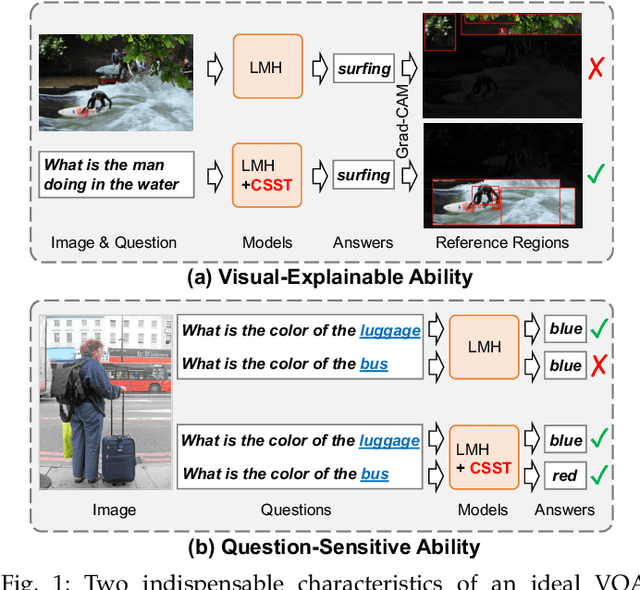
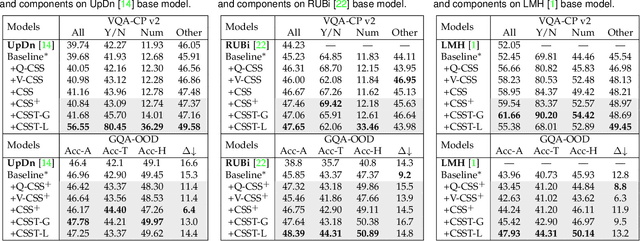
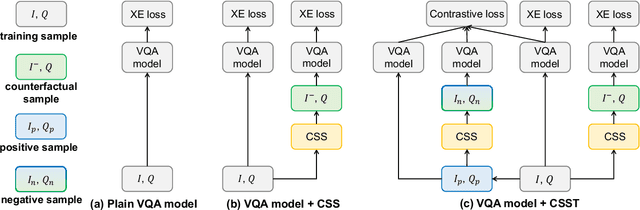
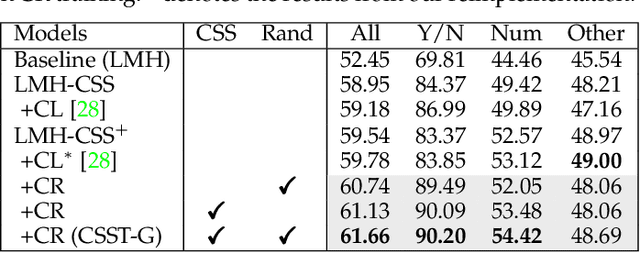
Today's VQA models still tend to capture superficial linguistic correlations in the training set and fail to generalize to the test set with different QA distributions. To reduce these language biases, recent VQA works introduce an auxiliary question-only model to regularize the training of targeted VQA model, and achieve dominating performance on diagnostic benchmarks for out-of-distribution testing. However, due to complex model design, these ensemble-based methods are unable to equip themselves with two indispensable characteristics of an ideal VQA model: 1) Visual-explainable: The model should rely on the right visual regions when making decisions. 2) Question-sensitive: The model should be sensitive to the linguistic variations in questions. To this end, we propose a novel model-agnostic Counterfactual Samples Synthesizing and Training (CSST) strategy. After training with CSST, VQA models are forced to focus on all critical objects and words, which significantly improves both visual-explainable and question-sensitive abilities. Specifically, CSST is composed of two parts: Counterfactual Samples Synthesizing (CSS) and Counterfactual Samples Training (CST). CSS generates counterfactual samples by carefully masking critical objects in images or words in questions and assigning pseudo ground-truth answers. CST not only trains the VQA models with both complementary samples to predict respective ground-truth answers, but also urges the VQA models to further distinguish the original samples and superficially similar counterfactual ones. To facilitate the CST training, we propose two variants of supervised contrastive loss for VQA, and design an effective positive and negative sample selection mechanism based on CSS. Extensive experiments have shown the effectiveness of CSST. Particularly, by building on top of model LMH+SAR, we achieve record-breaking performance on all OOD benchmarks.
Counterfactual Variable Control for Robust and Interpretable Question Answering
Oct 12, 2020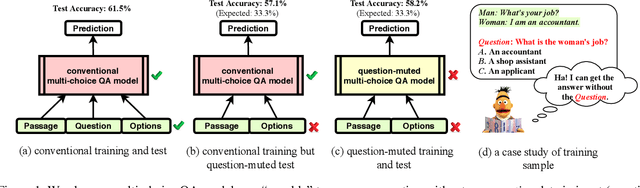
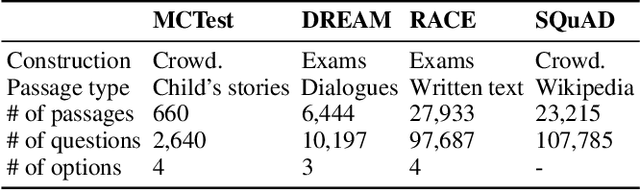
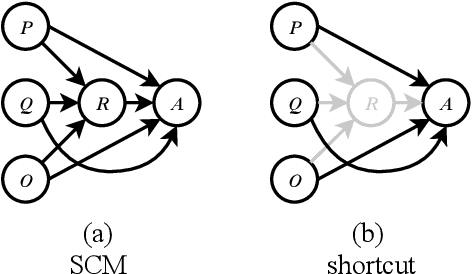
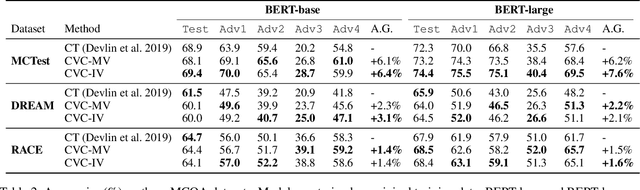
Deep neural network based question answering (QA) models are neither robust nor explainable in many cases. For example, a multiple-choice QA model, tested without any input of question, is surprisingly "capable" to predict the most of correct options. In this paper, we inspect such spurious "capability" of QA models using causal inference. We find the crux is the shortcut correlation, e.g., unrobust word alignment between passage and options learned by the models. We propose a novel approach called Counterfactual Variable Control (CVC) that explicitly mitigates any shortcut correlation and preserves the comprehensive reasoning for robust QA. Specifically, we leverage multi-branch architecture that allows us to disentangle robust and shortcut correlations in the training process of QA. We then conduct two novel CVC inference methods (on trained models) to capture the effect of comprehensive reasoning as the final prediction. For evaluation, we conduct extensive experiments using two BERT backbones on both multi-choice and span-extraction QA benchmarks. The results show that our CVC achieves high robustness against a variety of adversarial attacks in QA while maintaining good interpretation ability.
Counterfactual VQA: A Cause-Effect Look at Language Bias
Jun 15, 2020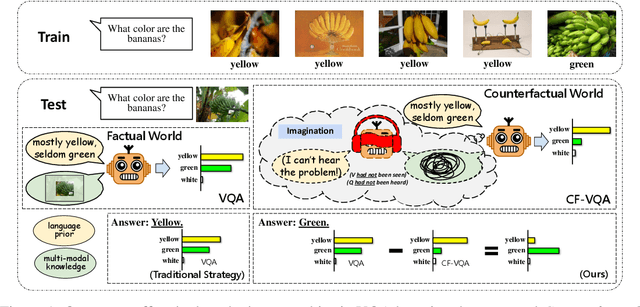
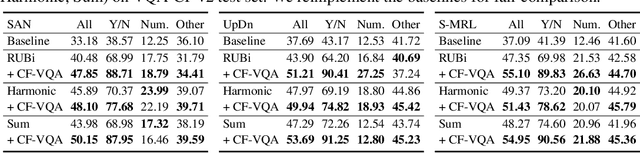
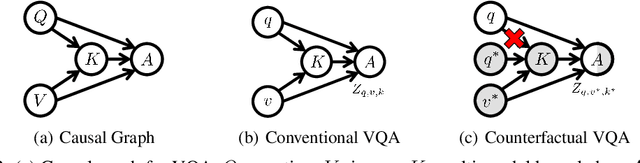
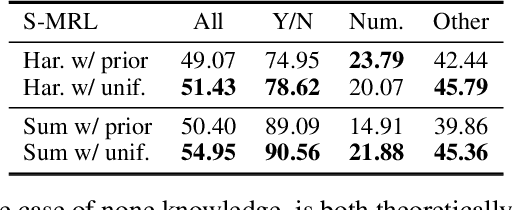
Visual Question Answering (VQA) models tend to rely on the language bias and thus fail to learn the reasoning from visual knowledge, which is however the original intention of VQA. In this paper, we propose a novel cause-effect look at the language bias, where the bias is formulated as the direct effect of question on answer from the view of causal inference. The effect can be captured by counterfactual VQA, where the image had not existed in an imagined scenario. Our proposed cause-effect look 1) is general to any baseline VQA architecture, 2) achieves significant improvement on the language-bias sensitive VQA-CP dataset, and 3) fills the theoretical gap in recent language prior based works.
Domain-Adaptive Few-Shot Learning
Mar 19, 2020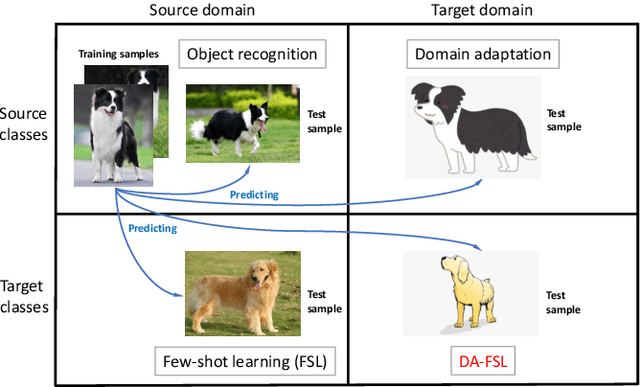
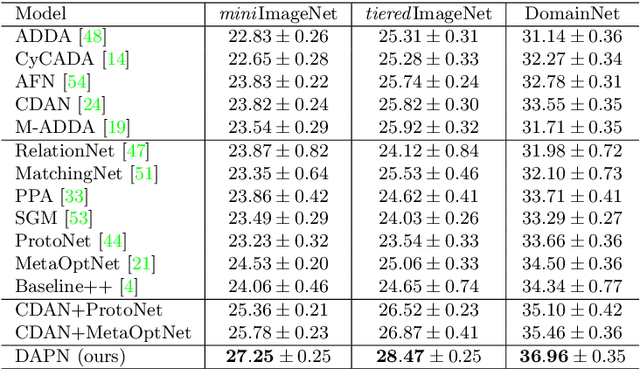
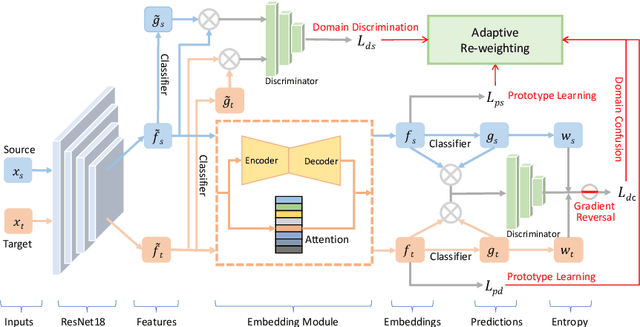
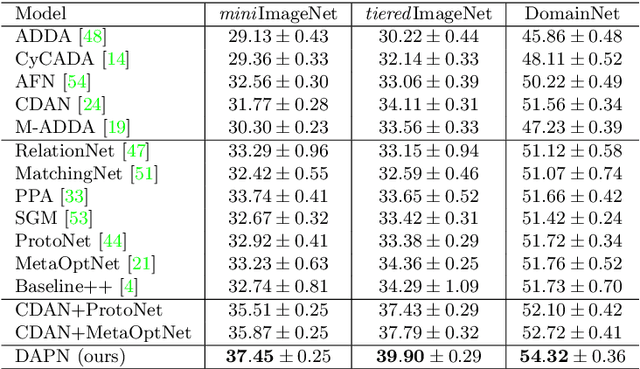
Existing few-shot learning (FSL) methods make the implicit assumption that the few target class samples are from the same domain as the source class samples. However, in practice this assumption is often invalid -- the target classes could come from a different domain. This poses an additional challenge of domain adaptation (DA) with few training samples. In this paper, the problem of domain-adaptive few-shot learning (DA-FSL) is tackled, which requires solving FSL and DA in a unified framework. To this end, we propose a novel domain-adversarial prototypical network (DAPN) model. It is designed to address a specific challenge in DA-FSL: the DA objective means that the source and target data distributions need to be aligned, typically through a shared domain-adaptive feature embedding space; but the FSL objective dictates that the target domain per class distribution must be different from that of any source domain class, meaning aligning the distributions across domains may harm the FSL performance. How to achieve global domain distribution alignment whilst maintaining source/target per-class discriminativeness thus becomes the key. Our solution is to explicitly enhance the source/target per-class separation before domain-adaptive feature embedding learning in the DAPN, in order to alleviate the negative effect of domain alignment on FSL. Extensive experiments show that our DAPN outperforms the state-of-the-art FSL and DA models, as well as their na\"ive combinations. The code is available at https://github.com/dingmyu/DAPN.
Unbiased Scene Graph Generation from Biased Training
Mar 11, 2020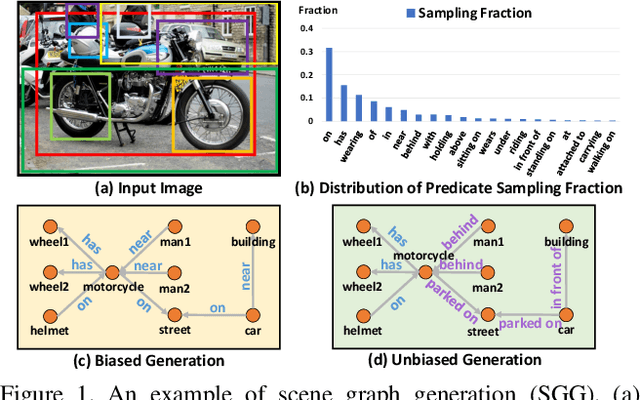
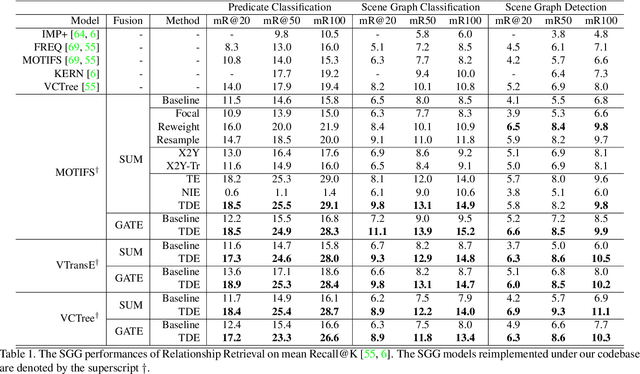
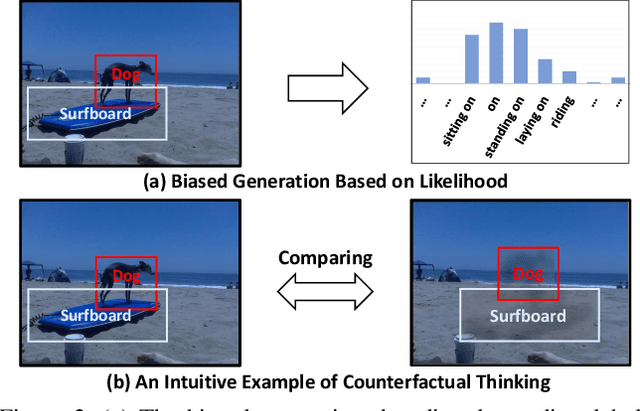
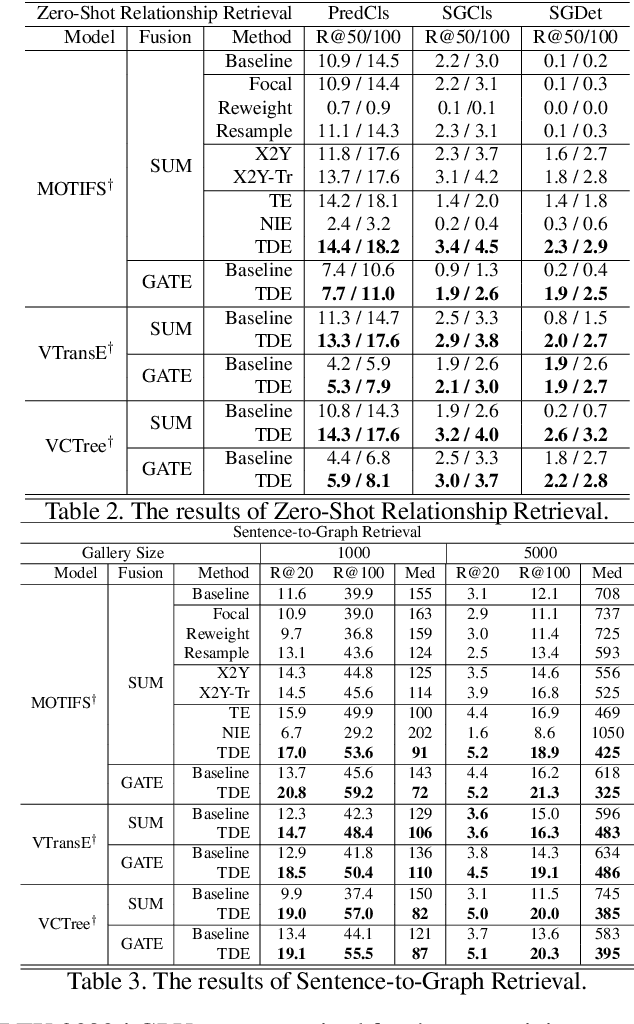
Today's scene graph generation (SGG) task is still far from practical, mainly due to the severe training bias, e.g., collapsing diverse "human walk on / sit on / lay on beach" into "human on beach". Given such SGG, the down-stream tasks such as VQA can hardly infer better scene structures than merely a bag of objects. However, debiasing in SGG is not trivial because traditional debiasing methods cannot distinguish between the good and bad bias, e.g., good context prior (e.g., "person read book" rather than "eat") and bad long-tailed bias (e.g., "near" dominating "behind / in front of"). In this paper, we present a novel SGG framework based on causal inference but not the conventional likelihood. We first build a causal graph for SGG, and perform traditional biased training with the graph. Then, we propose to draw the counterfactual causality from the trained graph to infer the effect from the bad bias, which should be removed. In particular, we use Total Direct Effect (TDE) as the proposed final predicate score for unbiased SGG. Note that our framework is agnostic to any SGG model and thus can be widely applied in the community who seeks unbiased predictions. By using the proposed Scene Graph Diagnosis toolkit on the SGG benchmark Visual Genome and several prevailing models, we observed significant improvements over the previous state-of-the-art methods.
Two Causal Principles for Improving Visual Dialog
Nov 24, 2019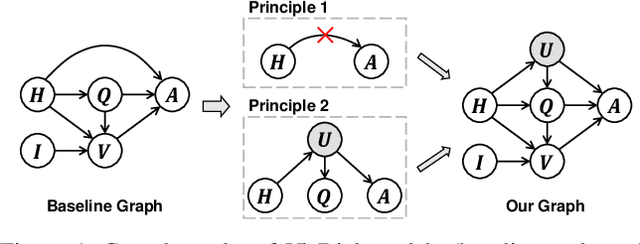
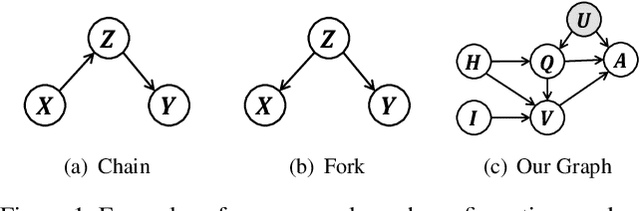

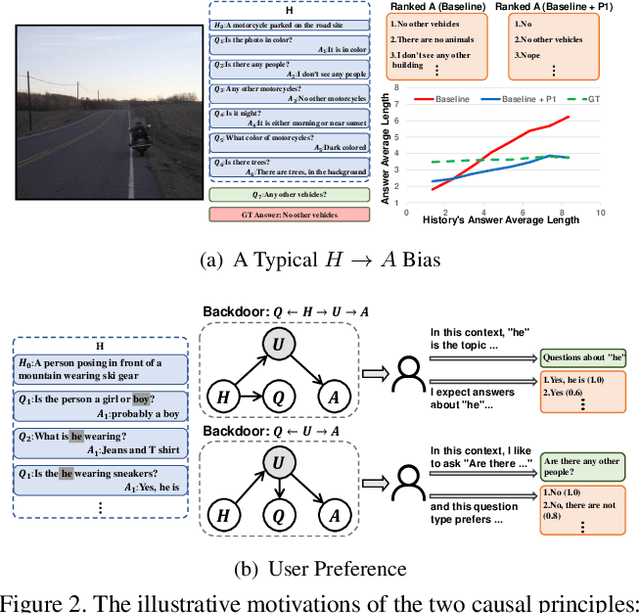
This paper is a winner report from team MReaL-BDAI for Visual Dialog Challenge 2019. We present two causal principles for improving Visual Dialog (VisDial). By "improving", we mean that they can promote almost every existing VisDial model to the state-of-the-art performance on Visual Dialog 2019 Challenge leader-board. Such a major improvement is only due to our careful inspection on the causality behind the model and data, finding that the community has overlooked two causalities in VisDial. Intuitively, Principle 1 suggests: we should remove the direct input of the dialog history to the answer model, otherwise the harmful shortcut bias will be introduced; Principle 2 says: there is an unobserved confounder for history, question, and answer, leading to spurious correlations from training data. In particular, to remove the confounder suggested in Principle 2, we propose several causal intervention algorithms, which make the training fundamentally different from the traditional likelihood estimation. Note that the two principles are model-agnostic, so they are applicable in any VisDial model.
Mobile Video Action Recognition
Aug 27, 2019
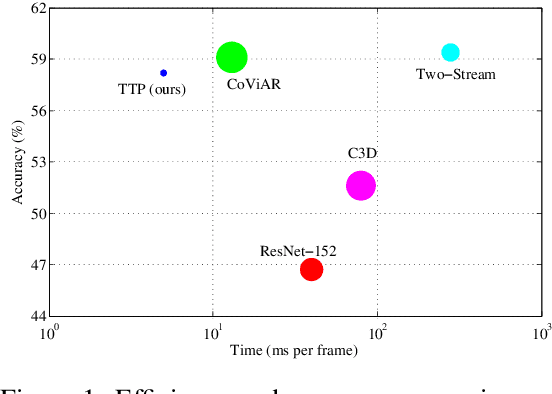
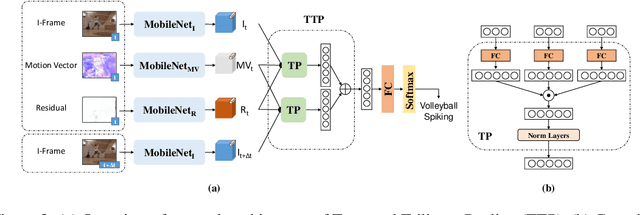

Video action recognition, which is topical in computer vision and video analysis, aims to allocate a short video clip to a pre-defined category such as brushing hair or climbing stairs. Recent works focus on action recognition with deep neural networks that achieve state-of-the-art results in need of high-performance platforms. Despite the fast development of mobile computing, video action recognition on mobile devices has not been fully discussed. In this paper, we focus on the novel mobile video action recognition task, where only the computational capabilities of mobile devices are accessible. Instead of raw videos with huge storage, we choose to extract multiple modalities (including I-frames, motion vectors, and residuals) directly from compressed videos. By employing MobileNetV2 as backbone, we propose a novel Temporal Trilinear Pooling (TTP) module to fuse the multiple modalities for mobile video action recognition. In addition to motion vectors, we also provide a temporal fusion method to explicitly induce the temporal context. The efficiency test on a mobile device indicates that our model can perform mobile video action recognition at about 40FPS. The comparative results on two benchmarks show that our model outperforms existing action recognition methods in model size and time consuming, but with competitive accuracy.
Variational Context: Exploiting Visual and Textual Context for Grounding Referring Expressions
Jul 08, 2019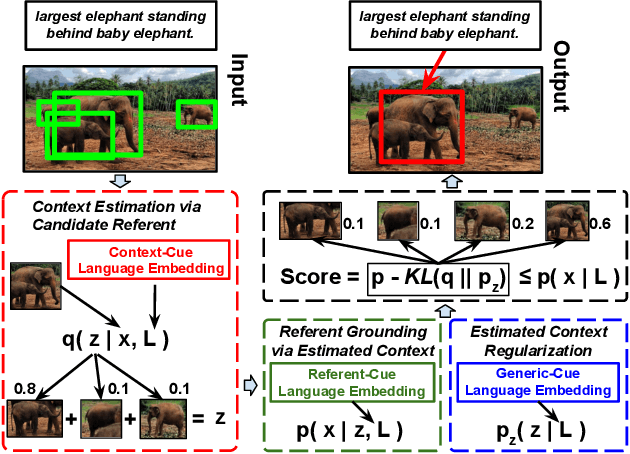
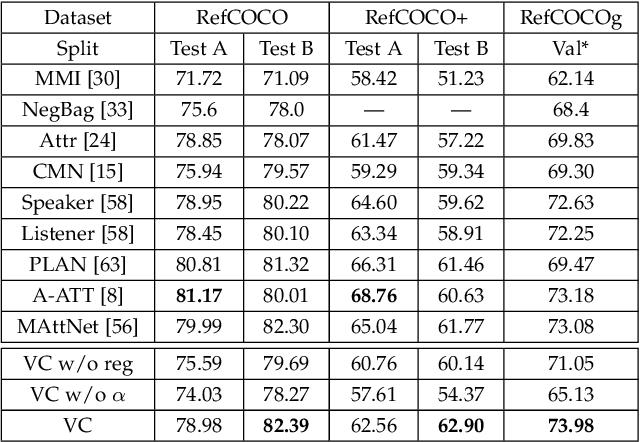

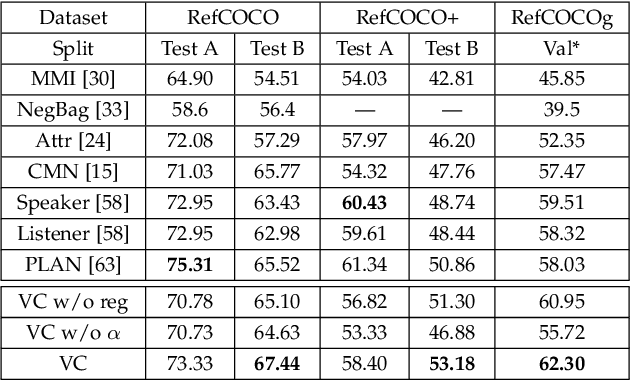
We focus on grounding (i.e., localizing or linking) referring expressions in images, e.g., ``largest elephant standing behind baby elephant''. This is a general yet challenging vision-language task since it does not only require the localization of objects, but also the multimodal comprehension of context -- visual attributes (e.g., ``largest'', ``baby'') and relationships (e.g., ``behind'') that help to distinguish the referent from other objects, especially those of the same category. Due to the exponential complexity involved in modeling the context associated with multiple image regions, existing work oversimplifies this task to pairwise region modeling by multiple instance learning. In this paper, we propose a variational Bayesian method, called Variational Context, to solve the problem of complex context modeling in referring expression grounding. Specifically, our framework exploits the reciprocal relation between the referent and context, i.e., either of them influences estimation of the posterior distribution of the other, and thereby the search space of context can be greatly reduced. In addition to reciprocity, our framework considers the semantic information of context, i.e., the referring expression can be reproduced based on the estimated context. We also extend the model to unsupervised setting where no annotation for the referent is available. Extensive experiments on various benchmarks show consistent improvement over state-of-the-art methods in both supervised and unsupervised settings.