 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating remote sensing data assimilation, deep learning and large language model for interactive wheat breeding yield prediction
Jan 08, 2025



Yield is one of the core goals of crop breeding. By predicting the potential yield of different breeding materials, breeders can screen these materials at various growth stages to select the best performing. Based on unmanned aerial vehicle remote sensing technology, high-throughput crop phenotyping data in breeding areas is collected to provide data support for the breeding decisions of breeders. However, the accuracy of current yield predictions still requires improvement, and the usability and user-friendliness of yield forecasting tools remain suboptimal. To address these challenges, this study introduces a hybrid method and tool for crop yield prediction, designed to allow breeders to interactively and accurately predict wheat yield by chatting with a large language model (LLM). First, the newly designed data assimilation algorithm is used to assimilate the leaf area index into the WOFOST model. Then, selected outputs from the assimilation process, along with remote sensing inversion results, are used to drive the time-series temporal fusion transformer model for wheat yield prediction. Finally, based on this hybrid method and leveraging an LLM with retrieval augmented generation technology, we developed an interactive yield prediction Web tool that is user-friendly and supports sustainable data updates. This tool integrates multi-source data to assist breeding decision-making. This study aims to accelerate the identification of high-yield materials in the breeding process, enhance breeding efficiency, and enable more scientific and smart breeding decisions.
Multi-Scale Representation Learning for Image Restoration with State-Space Model
Aug 19, 2024



Image restoration endeavors to reconstruct a high-quality, detail-rich image from a degraded counterpart, which is a pivotal process in photography and various computer vision systems. In real-world scenarios, different types of degradation can cause the loss of image details at various scales and degrade image contrast. Existing methods predominantly rely on CNN and Transformer to capture multi-scale representations. However, these methods are often limited by the high computational complexity of Transformers and the constrained receptive field of CNN, which hinder them from achieving superior performance and efficiency in image restoration. To address these challenges, we propose a novel Multi-Scale State-Space Model-based (MS-Mamba) for efficient image restoration that enhances the capacity for multi-scale representation learning through our proposed global and regional SSM modules. Additionally, an Adaptive Gradient Block (AGB) and a Residual Fourier Block (RFB) are proposed to improve the network's detail extraction capabilities by capturing gradients in various directions and facilitating learning details in the frequency domain. Extensive experiments on nine public benchmarks across four classic image restoration tasks, image deraining, dehazing, denoising, and low-light enhancement, demonstrate that our proposed method achieves new state-of-the-art performance while maintaining low computational complexity. The source code will be publicly available.
Adaptive Frequency Enhancement Network for Single Image Deraining
Jul 19, 2024Image deraining aims to improve the visibility of images damaged by rainy conditions, targeting the removal of degradation elements such as rain streaks, raindrops, and rain accumulation. While numerous single image deraining methods have shown promising results in image enhancement within the spatial domain, real-world rain degradation often causes uneven damage across an image's entire frequency spectrum, posing challenges for these methods in enhancing different frequency components. In this paper, we introduce a novel end-to-end Adaptive Frequency Enhancement Network (AFENet) specifically for single image deraining that adaptively enhances images across various frequencies. We employ convolutions of different scales to adaptively decompose image frequency bands, introduce a feature enhancement module to boost the features of different frequency components and present a novel interaction module for interchanging and merging information from various frequency branches. Simultaneously, we propose a feature aggregation module that efficiently and adaptively fuses features from different frequency bands, facilitating enhancements across the entire frequency spectrum. This approach empowers the deraining network to eliminate diverse and complex rainy patterns and to reconstruct image details accurately. Extensive experiments on both real and synthetic scenes demonstrate that our method not only achieves visually appealing enhancement results but also surpasses existing methods in performance.
MIPI 2024 Challenge on Nighttime Flare Removal: Methods and Results
Apr 30, 2024



The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
BP4ER: Bootstrap Prompting for Explicit Reasoning in Medical Dialogue Generation
Mar 28, 2024Medical dialogue generation (MDG) has gained increasing attention due to its substantial practical value. Previous works typically employ a sequence-to-sequence framework to generate medical responses by modeling dialogue context as sequential text with annotated medical entities. While these methods have been successful in generating fluent responses, they fail to provide process explanations of reasoning and require extensive entity annotation. To address these limitations, we propose the method Bootstrap Prompting for Explicit Reasoning in MDG (BP4ER), which explicitly model MDG's multi-step reasoning process and iteratively enhance this reasoning process. We employ a least-to-most prompting strategy to guide a large language model (LLM) in explicit reasoning, breaking down MDG into simpler sub-questions. These sub-questions build on answers from previous ones. Additionally, we also introduce two distinct bootstrapping techniques for prompting, which autonomously correct errors and facilitate the LLM's explicit reasoning. This approach eliminates the need for entity annotation and increases the transparency of the MDG process by explicitly generating the intermediate reasoning chain. The experimental findings on the two public datasets indicate that BP4ER outperforms state-of-the-art methods in terms of both objective and subjective evaluation metrics.
Dual-Path Coupled Image Deraining Network via Spatial-Frequency Interaction
Feb 07, 2024



Transformers have recently emerged as a significant force in the field of image deraining. Existing image deraining methods utilize extensive research on self-attention. Though showcasing impressive results, they tend to neglect critical frequency information, as self-attention is generally less adept at capturing high-frequency details. To overcome this shortcoming, we have developed an innovative Dual-Path Coupled Deraining Network (DPCNet) that integrates information from both spatial and frequency domains through Spatial Feature Extraction Block (SFEBlock) and Frequency Feature Extraction Block (FFEBlock). We have further introduced an effective Adaptive Fusion Module (AFM) for the dual-path feature aggregation. Extensive experiments on six public deraining benchmarks and downstream vision tasks have demonstrated that our proposed method not only outperforms the existing state-of-the-art deraining method but also achieves visually pleasuring results with excellent robustness on downstream vision tasks.
Latent Degradation Representation Constraint for Single Image Deraining
Sep 09, 2023Since rain streaks show a variety of shapes and directions, learning the degradation representation is extremely challenging for single image deraining. Existing methods are mainly targeted at designing complicated modules to implicitly learn latent degradation representation from coupled rainy images. This way, it is hard to decouple the content-independent degradation representation due to the lack of explicit constraint, resulting in over- or under-enhancement problems. To tackle this issue, we propose a novel Latent Degradation Representation Constraint Network (LDRCNet) that consists of Direction-Aware Encoder (DAEncoder), UNet Deraining Network, and Multi-Scale Interaction Block (MSIBlock). Specifically, the DAEncoder is proposed to adaptively extract latent degradation representation by using the deformable convolutions to exploit the direction consistency of rain streaks. Next, a constraint loss is introduced to explicitly constraint the degradation representation learning during training. Last, we propose an MSIBlock to fuse with the learned degradation representation and decoder features of the deraining network for adaptive information interaction, which enables the deraining network to remove various complicated rainy patterns and reconstruct image details. Experimental results on synthetic and real datasets demonstrate that our method achieves new state-of-the-art performance.
A study on the effects of compression on hyperspectral image classification
Apr 01, 2021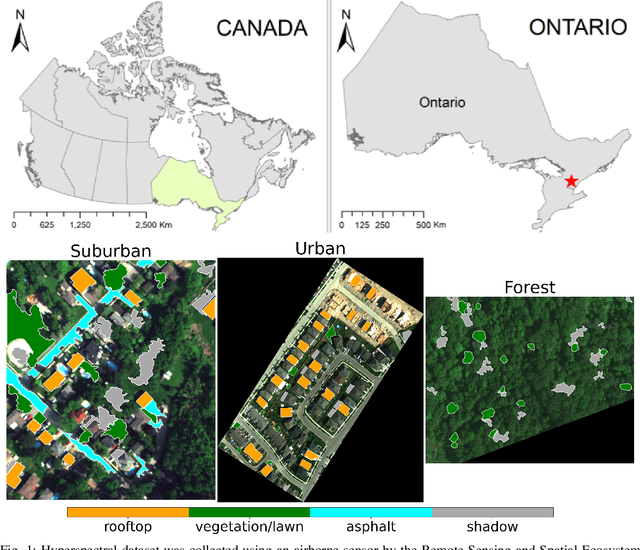
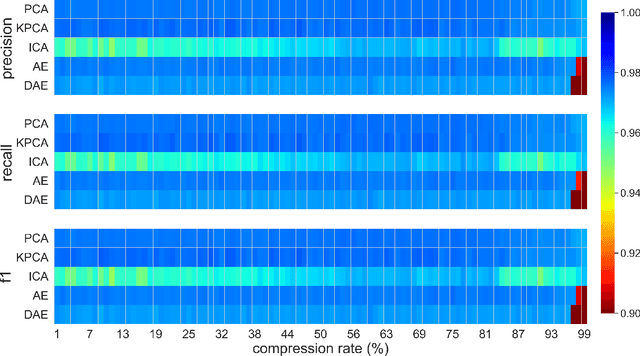
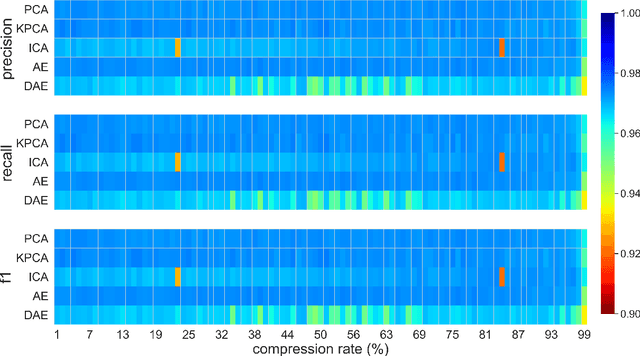
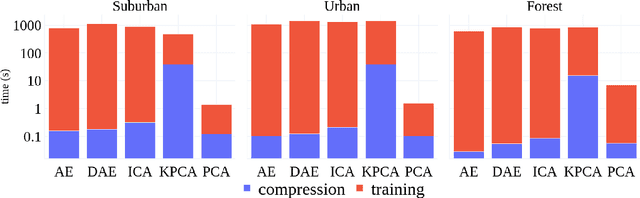
This paper presents a systematic study the effects of compression on hyperspectral pixel classification task. We use five dimensionality reduction methods -- PCA, KPCA, ICA, AE, and DAE -- to compress 301-dimensional hyperspectral pixels. Compressed pixels are subsequently used to perform pixel-based classifications. Pixel classification accuracies together with compression method, compression rates, and reconstruction errors provide a new lens to study the suitability of a compression method for the task of pixel-based classification. We use three high-resolution hyperspectral image datasets, representing three common landscape units (i.e. urban, transitional suburban, and forests) collected by the Remote Sensing and Spatial Ecosystem Modeling laboratory of the University of Toronto. We found that PCA, KPCA, and ICA post greater signal reconstruction capability; however, when compression rate is more than 90\% those methods showed lower classification scores. AE and DAE methods post better classification accuracy at 95\% compression rate, however decreasing again at 97\%, suggesting a sweet-spot at the 95\% mark. Our results demonstrate that the choice of a compression method with the compression rate are important considerations when designing a hyperspectral image classification pipeline.