 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANT: Exploiting Adaptive Numerical Data Type for Low-bit Deep Neural Network Quantization
Aug 30, 2022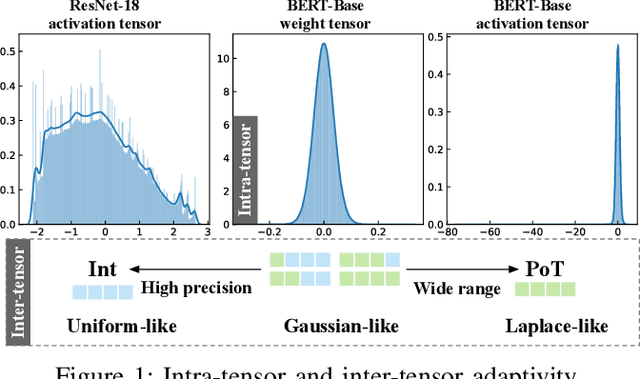
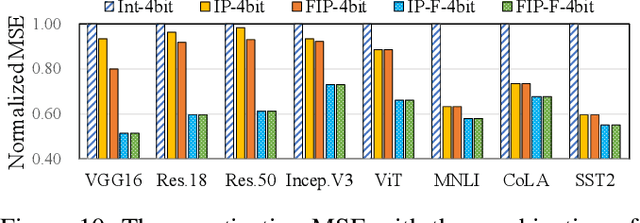
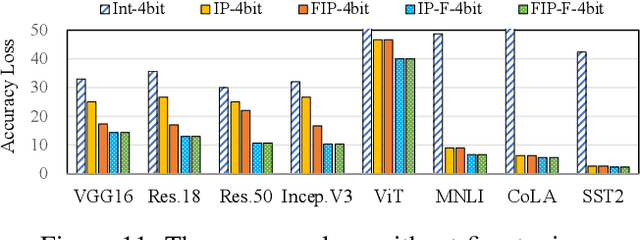
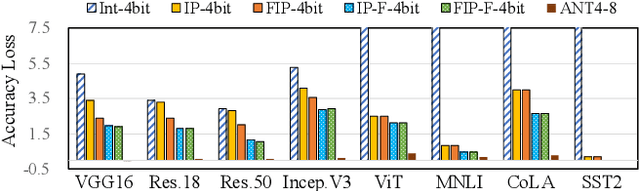
Quantization is a technique to reduce the computation and memory cost of DNN models, which are getting increasingly large. Existing quantization solutions use fixed-point integer or floating-point types, which have limited benefits, as both require more bits to maintain the accuracy of original models. On the other hand, variable-length quantization uses low-bit quantization for normal values and high-precision for a fraction of outlier values. Even though this line of work brings algorithmic benefits, it also introduces significant hardware overheads due to variable-length encoding and decoding. In this work, we propose a fixed-length adaptive numerical data type called ANT to achieve low-bit quantization with tiny hardware overheads. Our data type ANT leverages two key innovations to exploit the intra-tensor and inter-tensor adaptive opportunities in DNN models. First, we propose a particular data type, flint, that combines the advantages of float and int for adapting to the importance of different values within a tensor. Second, we propose an adaptive framework that selects the best type for each tensor according to its distribution characteristics. We design a unified processing element architecture for ANT and show its ease of integration with existing DNN accelerators. Our design results in 2.8$\times$ speedup and 2.5$\times$ energy efficiency improvement over the state-of-the-art quantization accelerators.
Perturbation Inactivation Based Adversarial Defense for Face Recognition
Jul 13, 2022



Deep learning-based face recognition models are vulnerable to adversarial attacks. To curb these attacks, most defense methods aim to improve the robustness of recognition models against adversarial perturbations. However, the generalization capacities of these methods are quite limited. In practice, they are still vulnerable to unseen adversarial attacks. Deep learning models are fairly robust to general perturbations, such as Gaussian noises. A straightforward approach is to inactivate the adversarial perturbations so that they can be easily handled as general perturbations. In this paper, a plug-and-play adversarial defense method, named perturbation inactivation (PIN), is proposed to inactivate adversarial perturbations for adversarial defense. We discover that the perturbations in different subspaces have different influences on the recognition model. There should be a subspace, called the immune space, in which the perturbations have fewer adverse impacts on the recognition model than in other subspaces. Hence, our method estimates the immune space and inactivates the adversarial perturbations by restricting them to this subspace. The proposed method can be generalized to unseen adversarial perturbations since it does not rely on a specific kind of adversarial attack method. This approach not only outperforms several state-of-the-art adversarial defense methods but also demonstrates a superior generalization capacity through exhaustive experiments. Moreover, the proposed method can be successfully applied to four commercial APIs without additional training, indicating that it can be easily generalized to existing face recognition systems. The source code is available at https://github.com/RenMin1991/Perturbation-Inactivate
SQuant: On-the-Fly Data-Free Quantization via Diagonal Hessian Approximation
Feb 14, 2022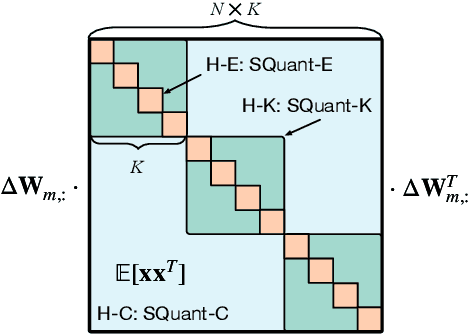
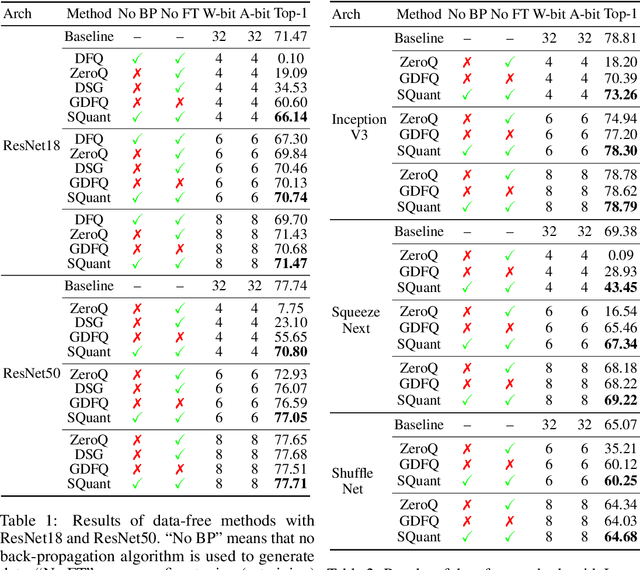
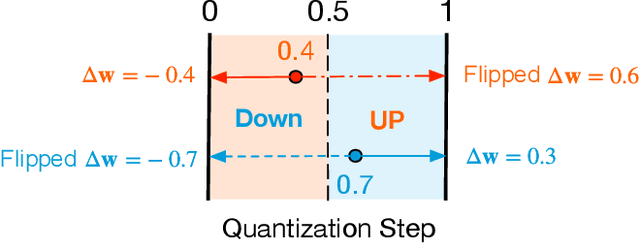
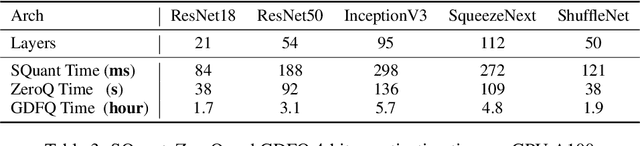
Quantization of deep neural networks (DNN) has been proven effective for compressing and accelerating DNN models. Data-free quantization (DFQ) is a promising approach without the original datasets under privacy-sensitive and confidential scenarios. However, current DFQ solutions degrade accuracy, need synthetic data to calibrate networks, and are time-consuming and costly. This paper proposes an on-the-fly DFQ framework with sub-second quantization time, called SQuant, which can quantize networks on inference-only devices with low computation and memory requirements. With the theoretical analysis of the second-order information of DNN task loss, we decompose and approximate the Hessian-based optimization objective into three diagonal sub-items, which have different areas corresponding to three dimensions of weight tensor: element-wise, kernel-wise, and output channel-wise. Then, we progressively compose sub-items and propose a novel data-free optimization objective in the discrete domain, minimizing Constrained Absolute Sum of Error (or CASE in short), which surprisingly does not need any dataset and is even not aware of network architecture. We also design an efficient algorithm without back-propagation to further reduce the computation complexity of the objective solver. Finally, without fine-tuning and synthetic datasets, SQuant accelerates the data-free quantization process to a sub-second level with >30% accuracy improvement over the existing data-free post-training quantization works, with the evaluated models under 4-bit quantization. We have open-sourced the SQuant framework at https://github.com/clevercool/SQuant.
Block-Skim: Efficient Question Answering for Transformer
Dec 16, 2021

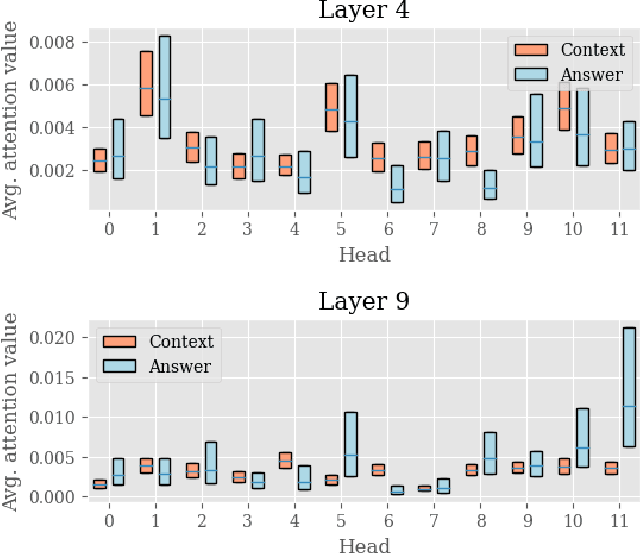
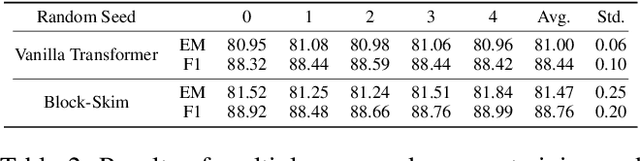
Transformer models have achieved promising results on natural language processing (NLP) tasks including extractive question answering (QA). Common Transformer encoders used in NLP tasks process the hidden states of all input tokens in the context paragraph throughout all layers. However, different from other tasks such as sequence classification, answering the raised question does not necessarily need all the tokens in the context paragraph. Following this motivation, we propose Block-skim, which learns to skim unnecessary context in higher hidden layers to improve and accelerate the Transformer performance. The key idea of Block-Skim is to identify the context that must be further processed and those that could be safely discarded early on during inference. Critically, we find that such information could be sufficiently derived from the self-attention weights inside the Transformer model. We further prune the hidden states corresponding to the unnecessary positions early in lower layers, achieving significant inference-time speedup. To our surprise, we observe that models pruned in this way outperform their full-size counterparts. Block-Skim improves QA models' accuracy on different datasets and achieves 3 times speedup on BERT-base model.
The Promise of Dataflow Architectures in the Design of Processing Systems for Autonomous Machines
Sep 15, 2021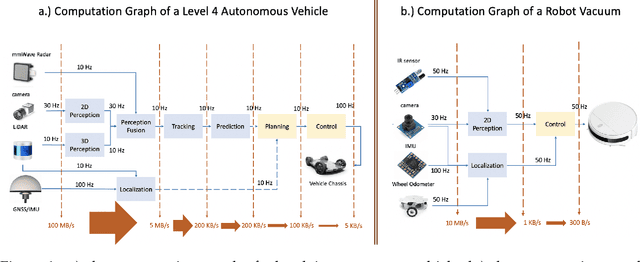
The commercialization of autonomous machines is a thriving sector, and likely to be the next major computing demand driver, after PC, cloud computing, and mobile computing. Nevertheless, a suitable computer architecture for autonomous machines is missing, and many companies are forced to develop ad hoc computing solutions that are neither scalable nor extensible. In this article, we analyze the demands of autonomous machine computing, and argue for the promise of dataflow architectures in autonomous machines.
S2TA: Exploiting Structured Sparsity for Energy-Efficient Mobile CNN Acceleration
Jul 16, 2021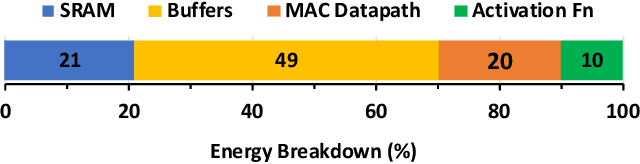
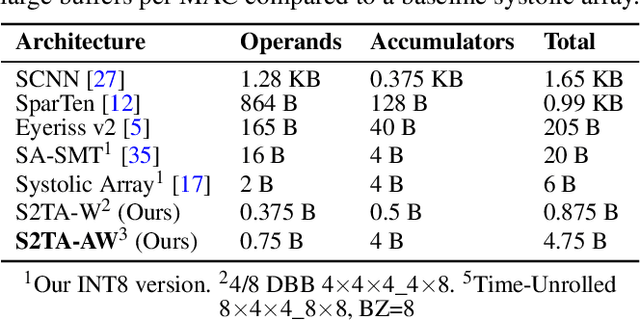
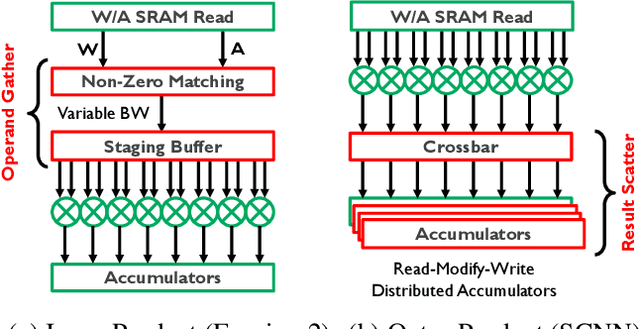
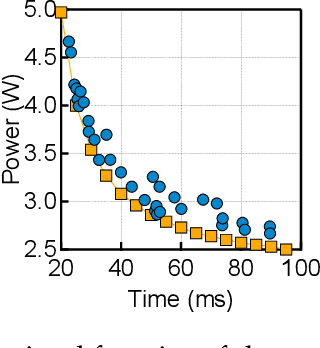
Exploiting sparsity is a key technique in accelerating quantized convolutional neural network (CNN) inference on mobile devices. Prior sparse CNN accelerators largely exploit un-structured sparsity and achieve significant speedups. Due to the unbounded, largely unpredictable sparsity patterns, however, exploiting unstructured sparsity requires complicated hardware design with significant energy and area overhead, which is particularly detrimental to mobile/IoT inference scenarios where energy and area efficiency are crucial. We propose to exploit structured sparsity, more specifically, Density Bound Block (DBB) sparsity for both weights and activations. DBB block tensors bound the maximum number of non-zeros per block. DBB thus exposes statically predictable sparsity patterns that enable lean sparsity-exploiting hardware. We propose new hardware primitives to implement DBB sparsity for (static) weights and (dynamic) activations, respectively, with very low overheads. Building on top of the primitives, we describe S2TA, a systolic array-based CNN accelerator that exploits joint weight and activation DBB sparsity and new dimensions of data reuse unavailable on the traditional systolic array. S2TA in 16nm achieves more than 2x speedup and energy reduction compared to a strong baseline of a systolic array with zero-value clock gating, over five popular CNN benchmarks. Compared to two recent non-systolic sparse accelerators, Eyeriss v2 (65nm) and SparTen (45nm), S2TA in 65nm uses about 2.2x and 3.1x less energy per inference, respectively.
One Shot Face Swapping on Megapixels
May 11, 2021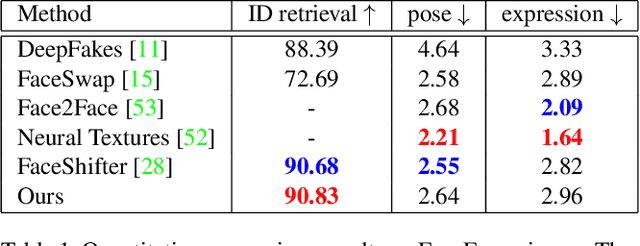
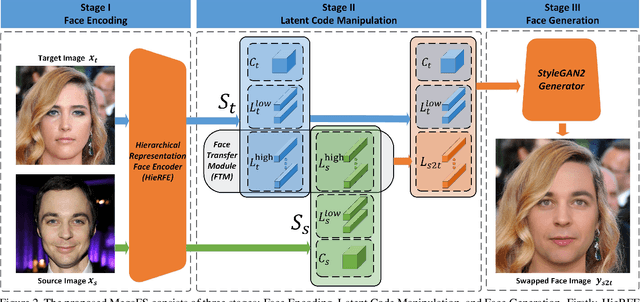

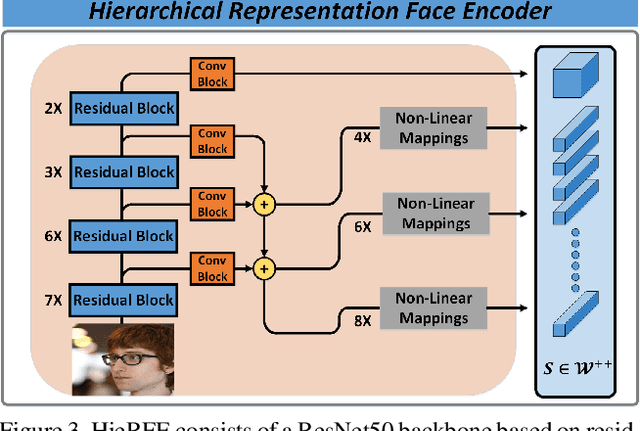
Face swapping has both positive applications such as entertainment, human-computer interaction, etc., and negative applications such as DeepFake threats to politics, economics, etc. Nevertheless, it is necessary to understand the scheme of advanced methods for high-quality face swapping and generate enough and representative face swapping images to train DeepFake detection algorithms. This paper proposes the first Megapixel level method for one shot Face Swapping (or MegaFS for short). Firstly, MegaFS organizes face representation hierarchically by the proposed Hierarchical Representation Face Encoder (HieRFE) in an extended latent space to maintain more facial details, rather than compressed representation in previous face swapping methods. Secondly, a carefully designed Face Transfer Module (FTM) is proposed to transfer the identity from a source image to the target by a non-linear trajectory without explicit feature disentanglement. Finally, the swapped faces can be synthesized by StyleGAN2 with the benefits of its training stability and powerful generative capability. Each part of MegaFS can be trained separately so the requirement of our model for GPU memory can be satisfied for megapixel face swapping. In summary, complete face representation, stable training, and limited memory usage are the three novel contributions to the success of our method. Extensive experiments demonstrate the superiority of MegaFS and the first megapixel level face swapping database is released for research on DeepFake detection and face image editing in the public domain. The dataset is at this link.
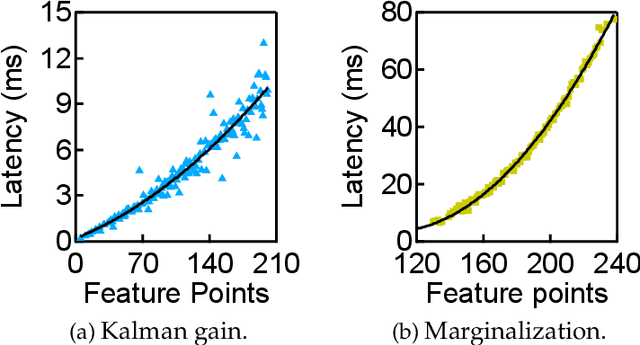
The Matter of Time -- A General and Efficient System for Precise Sensor Synchronization in Robotic Computing
Mar 30, 2021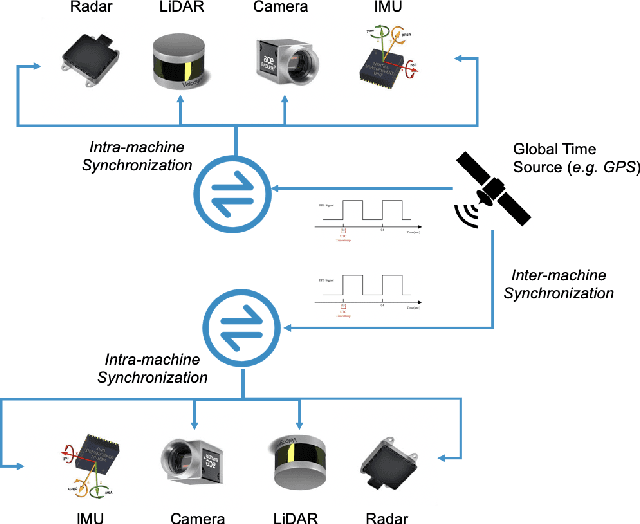
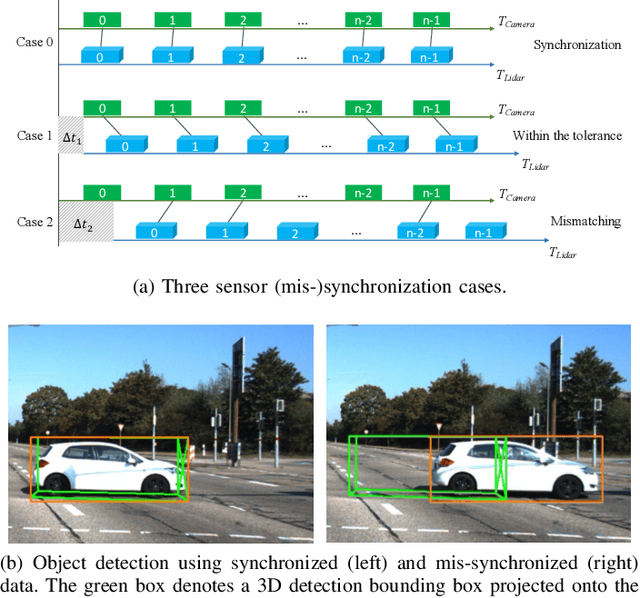
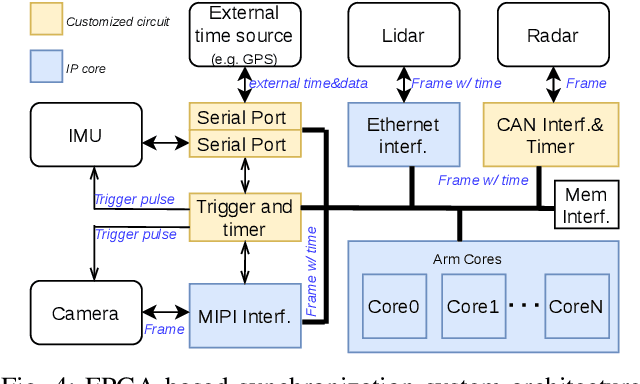
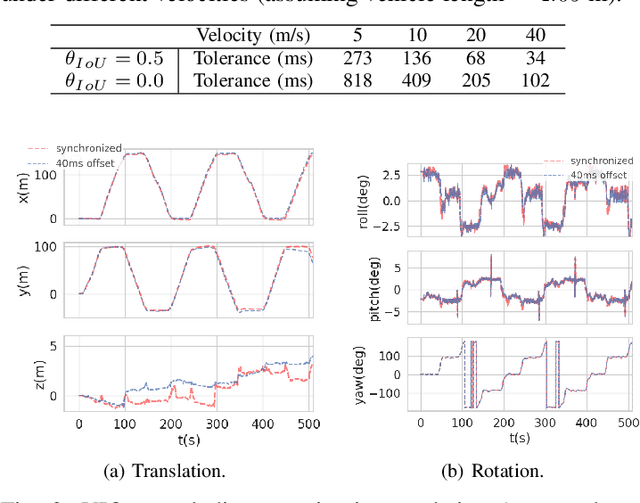
Time synchronization is a critical task in robotic computing such as autonomous driving. In the past few years, as we developed advanced robotic applications, our synchronization system has evolved as well. In this paper, we first introduce the time synchronization problem and explain the challenges of time synchronization, especially in robotic workloads. Summarizing these challenges, we then present a general hardware synchronization system for robotic computing, which delivers high synchronization accuracy while maintaining low energy and resource consumption. The proposed hardware synchronization system is a key building block in our future robotic products.
A LiDAR-Guided Framework for Video Enhancement
Mar 15, 2021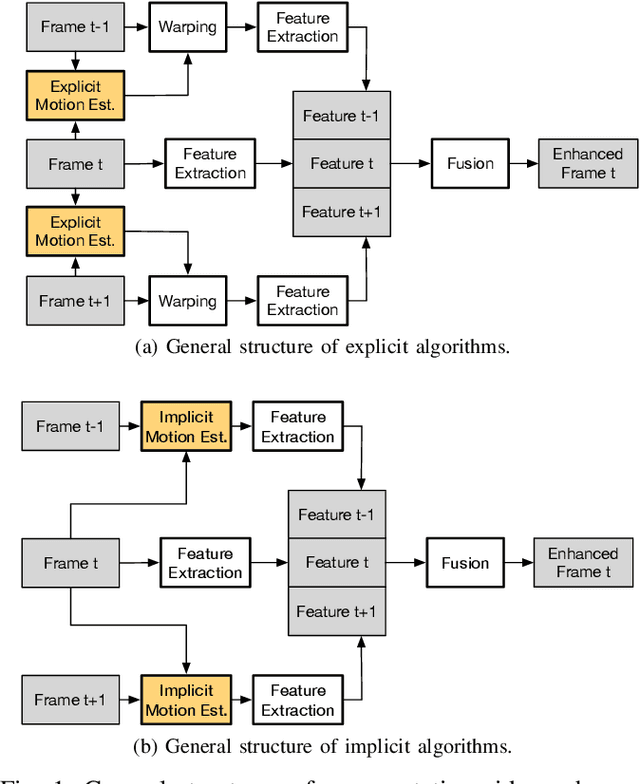

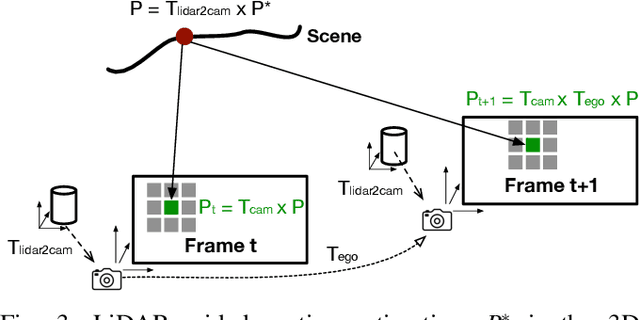

This paper presents a general framework that simultaneously improves the quality and the execution speed of a range of video enhancement tasks, such as super-sampling, deblurring, and denoising. The key to our framework is a pixel motion estimation algorithm that generates accurate motion from low-quality videos while being computationally very lightweight. Our motion estimation algorithm leverages point cloud information, which is readily available in today's autonomous devices and will only become more common in the future. We demonstrate a generic framework that leverages the motion information to guide high-quality image reconstruction. Experiments show that our framework consistently outperforms the state-of-the-art video enhancement algorithms while improving the execution speed by an order of magnitude.
End-to-End Framework for Efficient Deep Learning Using Metasurfaces Optics
Nov 23, 2020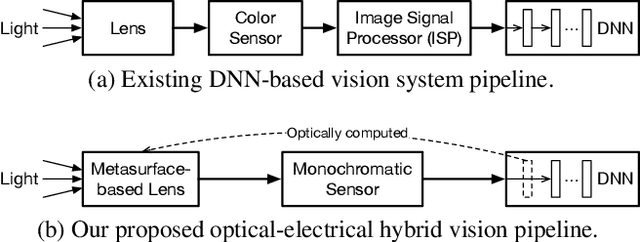
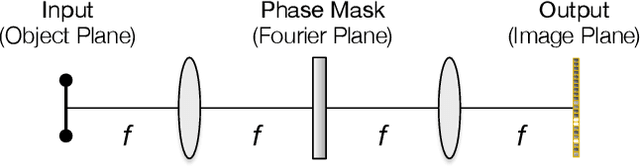
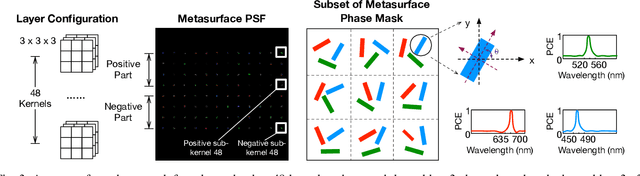
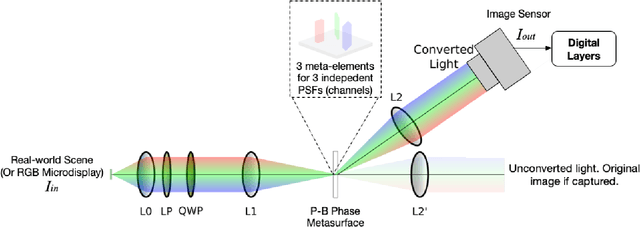
Deep learning using Convolutional Neural Networks (CNNs) has been shown to significantly out-performed many conventional vision algorithms. Despite efforts to increase the CNN efficiency both algorithmically and with specialized hardware, deep learning remains difficult to deploy in resource-constrained environments. In this paper, we propose an end-to-end framework to explore optically compute the CNNs in free-space, much like a computational camera. Compared to existing free-space optics-based approaches which are limited to processing single-channel (i.e., grayscale) inputs, we propose the first general approach, based on nanoscale meta-surface optics, that can process RGB data directly from the natural scenes. Our system achieves up to an order of magnitude energy saving, simplifies the sensor design, all the while sacrificing little network accuracy.