 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond ImageNet Attack: Towards Crafting Adversarial Examples for Black-box Domains
Feb 10, 2022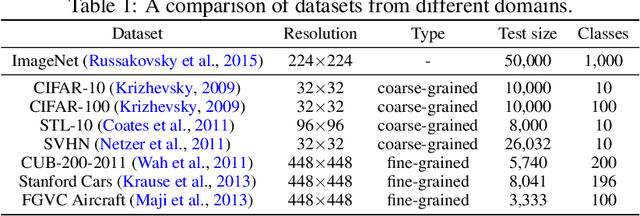
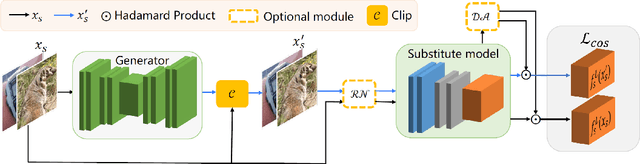
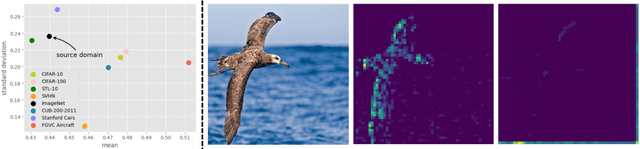
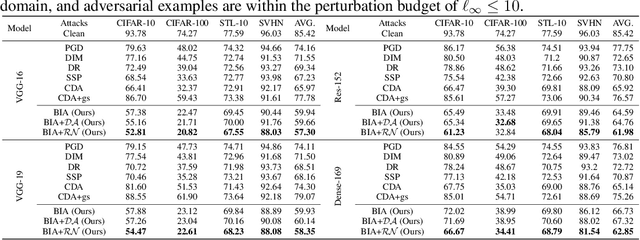
Adversarial examples have posed a severe threat to deep neural networks due to their transferable nature. Currently, various works have paid great efforts to enhance the cross-model transferability, which mostly assume the substitute model is trained in the same domain as the target model. However, in reality, the relevant information of the deployed model is unlikely to leak. Hence, it is vital to build a more practical black-box threat model to overcome this limitation and evaluate the vulnerability of deployed models. In this paper, with only the knowledge of the ImageNet domain, we propose a Beyond ImageNet Attack (BIA) to investigate the transferability towards black-box domains (unknown classification tasks). Specifically, we leverage a generative model to learn the adversarial function for disrupting low-level features of input images. Based on this framework, we further propose two variants to narrow the gap between the source and target domains from the data and model perspectives, respectively. Extensive experiments on coarse-grained and fine-grained domains demonstrate the effectiveness of our proposed methods. Notably, our methods outperform state-of-the-art approaches by up to 7.71\% (towards coarse-grained domains) and 25.91\% (towards fine-grained domains) on average. Our code is available at \url{https://github.com/qilong-zhang/Beyond-ImageNet-Attack}.
Unrestricted Adversarial Attacks on ImageNet Competition
Oct 25, 2021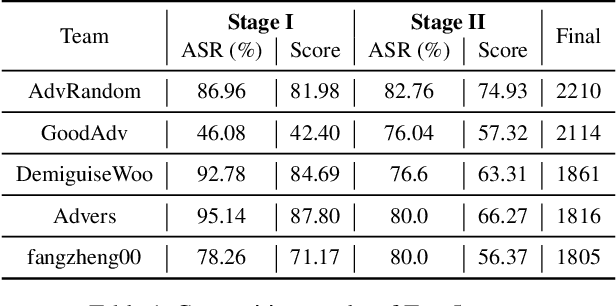
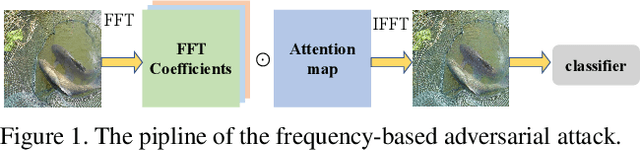
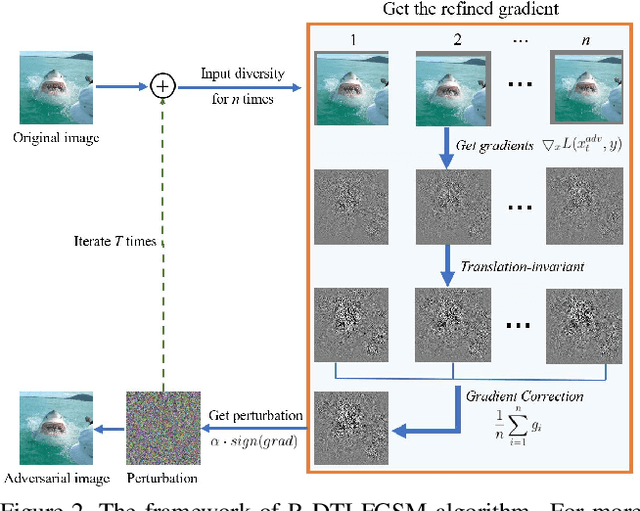
Many works have investigated the adversarial attacks or defenses under the settings where a bounded and imperceptible perturbation can be added to the input. However in the real-world, the attacker does not need to comply with this restriction. In fact, more threats to the deep model come from unrestricted adversarial examples, that is, the attacker makes large and visible modifications on the image, which causes the model classifying mistakenly, but does not affect the normal observation in human perspective. Unrestricted adversarial attack is a popular and practical direction but has not been studied thoroughly. We organize this competition with the purpose of exploring more effective unrestricted adversarial attack algorithm, so as to accelerate the academical research on the model robustness under stronger unbounded attacks. The competition is held on the TianChi platform (\url{https://tianchi.aliyun.com/competition/entrance/531853/introduction}) as one of the series of AI Security Challengers Program.
Adversarial Attacks on ML Defense Models Competition
Oct 15, 2021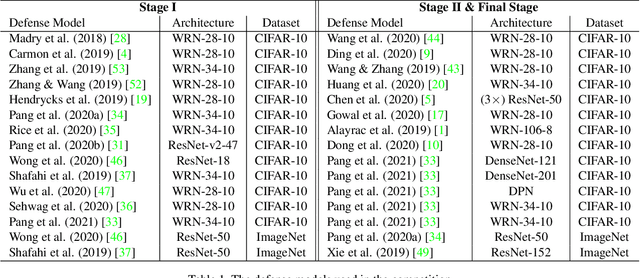
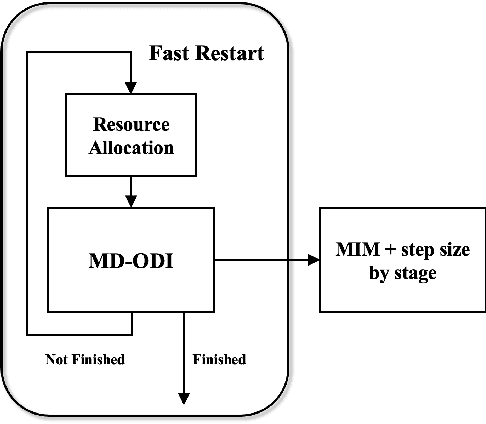
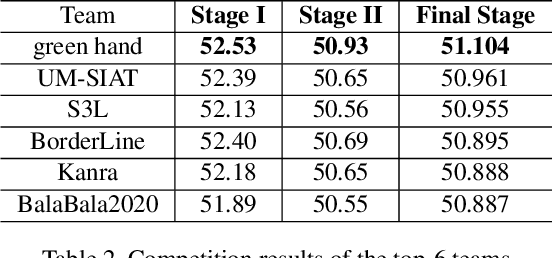
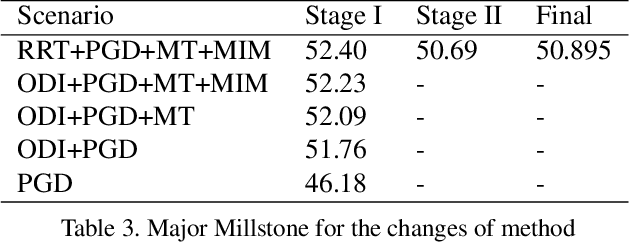
Due to the vulnerability of deep neural networks (DNNs) to adversarial examples, a large number of defense techniques have been proposed to alleviate this problem in recent years. However, the progress of building more robust models is usually hampered by the incomplete or incorrect robustness evaluation. To accelerate the research on reliable evaluation of adversarial robustness of the current defense models in image classification, the TSAIL group at Tsinghua University and the Alibaba Security group organized this competition along with a CVPR 2021 workshop on adversarial machine learning (https://aisecure-workshop.github.io/amlcvpr2021/). The purpose of this competition is to motivate novel attack algorithms to evaluate adversarial robustness more effectively and reliably. The participants were encouraged to develop stronger white-box attack algorithms to find the worst-case robustness of different defenses. This competition was conducted on an adversarial robustness evaluation platform -- ARES (https://github.com/thu-ml/ares), and is held on the TianChi platform (https://tianchi.aliyun.com/competition/entrance/531847/introduction) as one of the series of AI Security Challengers Program. After the competition, we summarized the results and established a new adversarial robustness benchmark at https://ml.cs.tsinghua.edu.cn/ares-bench/, which allows users to upload adversarial attack algorithms and defense models for evaluation.
AdvDrop: Adversarial Attack to DNNs by Dropping Information
Aug 20, 2021


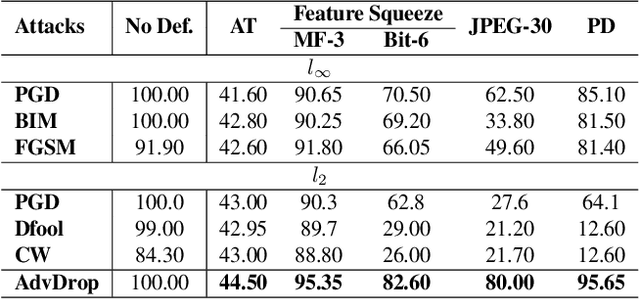
Human can easily recognize visual objects with lost information: even losing most details with only contour reserved, e.g. cartoon. However, in terms of visual perception of Deep Neural Networks (DNNs), the ability for recognizing abstract objects (visual objects with lost information) is still a challenge. In this work, we investigate this issue from an adversarial viewpoint: will the performance of DNNs decrease even for the images only losing a little information? Towards this end, we propose a novel adversarial attack, named \textit{AdvDrop}, which crafts adversarial examples by dropping existing information of images. Previously, most adversarial attacks add extra disturbing information on clean images explicitly. Opposite to previous works, our proposed work explores the adversarial robustness of DNN models in a novel perspective by dropping imperceptible details to craft adversarial examples. We demonstrate the effectiveness of \textit{AdvDrop} by extensive experiments, and show that this new type of adversarial examples is more difficult to be defended by current defense systems.
Towards Robust Vision Transformer
May 26, 2021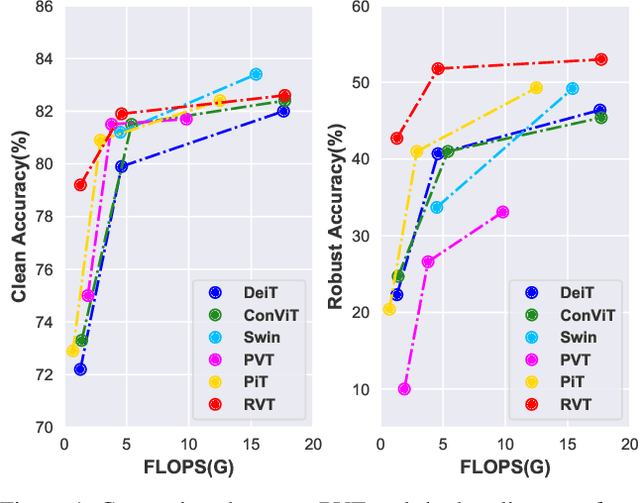
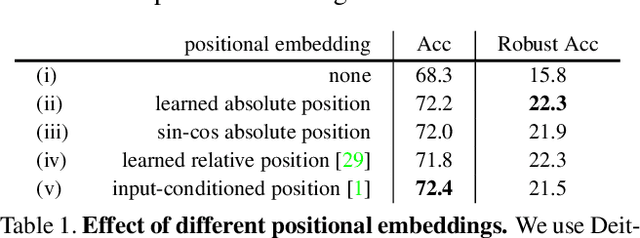
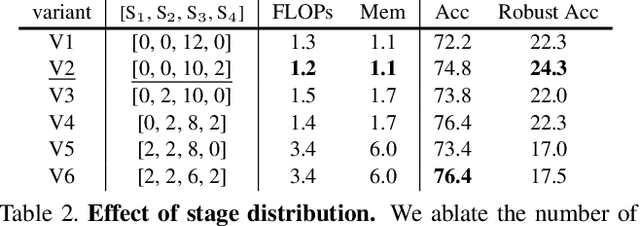
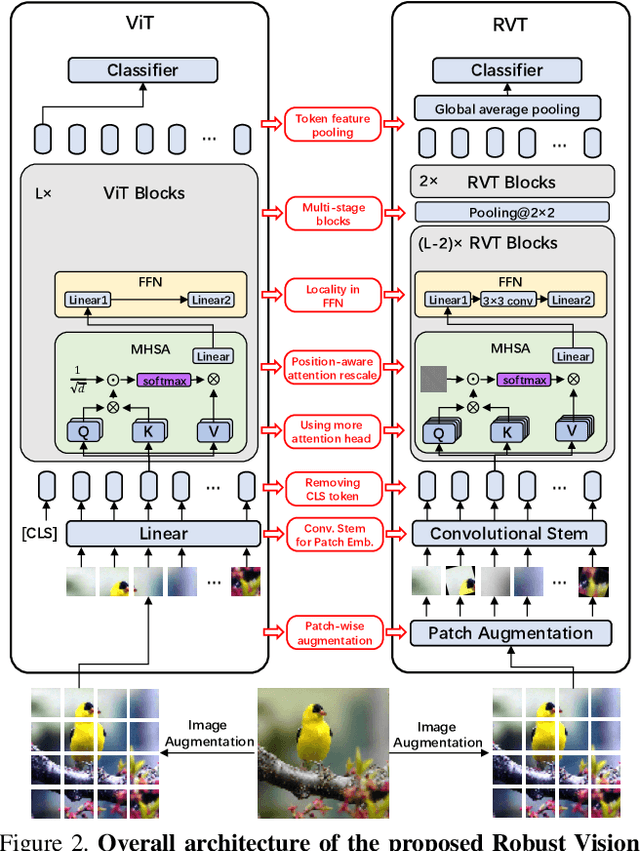
Recent advances on Vision Transformer (ViT) and its improved variants have shown that self-attention-based networks surpass traditional Convolutional Neural Networks (CNNs) in most vision tasks. However, existing ViTs focus on the standard accuracy and computation cost, lacking the investigation of the intrinsic influence on model robustness and generalization. In this work, we conduct systematic evaluation on components of ViTs in terms of their impact on robustness to adversarial examples, common corruptions and distribution shifts. We find some components can be harmful to robustness. By using and combining robust components as building blocks of ViTs, we propose Robust Vision Transformer (RVT), which is a new vision transformer and has superior performance with strong robustness. We further propose two new plug-and-play techniques called position-aware attention scaling and patch-wise augmentation to augment our RVT, which we abbreviate as RVT*. The experimental results on ImageNet and six robustness benchmarks show the advanced robustness and generalization ability of RVT compared with previous ViTs and state-of-the-art CNNs. Furthermore, RVT-S* also achieves Top-1 rank on multiple robustness leaderboards including ImageNet-C and ImageNet-Sketch. The code will be available at \url{https://git.io/Jswdk}.
QAIR: Practical Query-efficient Black-Box Attacks for Image Retrieval
Mar 23, 2021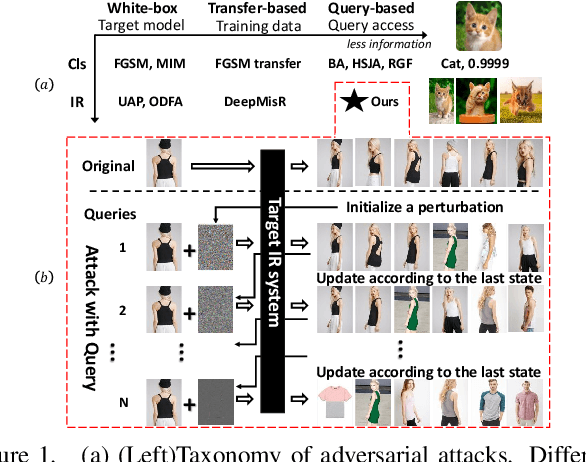
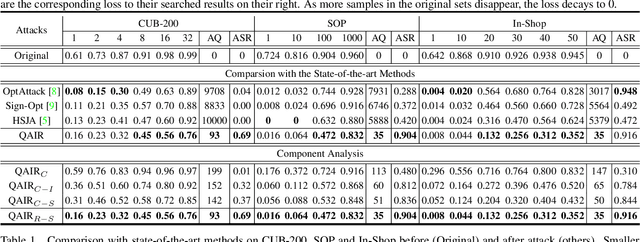
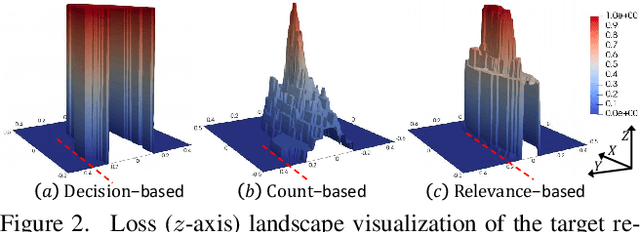
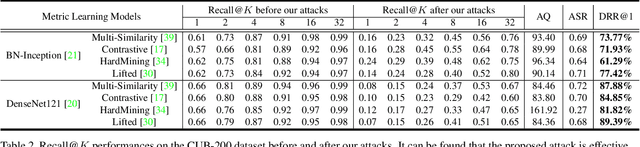
We study the query-based attack against image retrieval to evaluate its robustness against adversarial examples under the black-box setting, where the adversary only has query access to the top-k ranked unlabeled images from the database. Compared with query attacks in image classification, which produce adversaries according to the returned labels or confidence score, the challenge becomes even more prominent due to the difficulty in quantifying the attack effectiveness on the partial retrieved list. In this paper, we make the first attempt in Query-based Attack against Image Retrieval (QAIR), to completely subvert the top-k retrieval results. Specifically, a new relevance-based loss is designed to quantify the attack effects by measuring the set similarity on the top-k retrieval results before and after attacks and guide the gradient optimization. To further boost the attack efficiency, a recursive model stealing method is proposed to acquire transferable priors on the target model and generate the prior-guided gradients. Comprehensive experiments show that the proposed attack achieves a high attack success rate with few queries against the image retrieval systems under the black-box setting. The attack evaluations on the real-world visual search engine show that it successfully deceives a commercial system such as Bing Visual Search with 98% attack success rate by only 33 queries on average.
Adversarial Laser Beam: Effective Physical-World Attack to DNNs in a Blink
Mar 11, 2021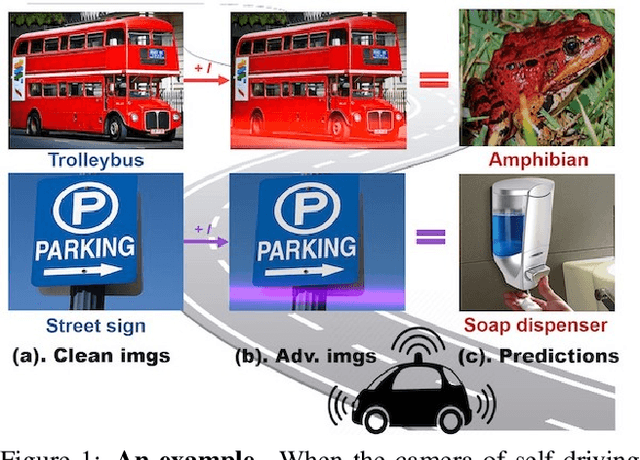

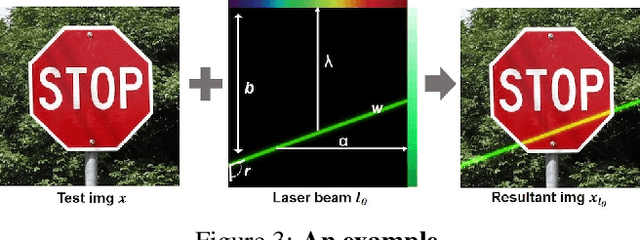
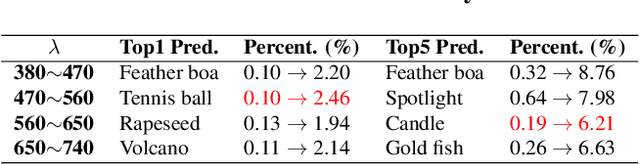
Though it is well known that the performance of deep neural networks (DNNs) degrades under certain light conditions, there exists no study on the threats of light beams emitted from some physical source as adversarial attacker on DNNs in a real-world scenario. In this work, we show by simply using a laser beam that DNNs are easily fooled. To this end, we propose a novel attack method called Adversarial Laser Beam ($AdvLB$), which enables manipulation of laser beam's physical parameters to perform adversarial attack. Experiments demonstrate the effectiveness of our proposed approach in both digital- and physical-settings. We further empirically analyze the evaluation results and reveal that the proposed laser beam attack may lead to some interesting prediction errors of the state-of-the-art DNNs. We envisage that the proposed $AdvLB$ method enriches the current family of adversarial attacks and builds the foundation for future robustness studies for light.
Spatial-Phase Shallow Learning: Rethinking Face Forgery Detection in Frequency Domain
Mar 10, 2021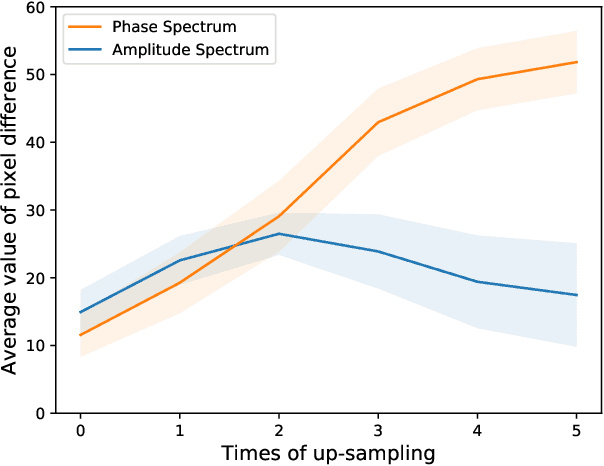
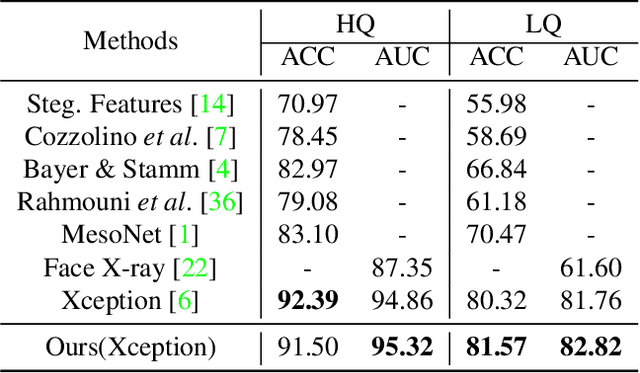
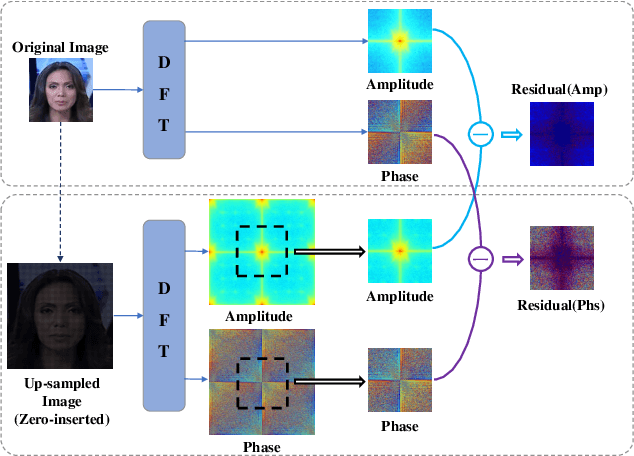
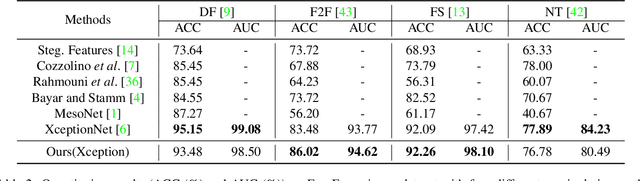
The remarkable success in face forgery techniques has received considerable attention in computer vision due to security concerns. We observe that up-sampling is a necessary step of most face forgery techniques, and cumulative up-sampling will result in obvious changes in the frequency domain, especially in the phase spectrum. According to the property of natural images, the phase spectrum preserves abundant frequency components that provide extra information and complement the loss of the amplitude spectrum. To this end, we present a novel Spatial-Phase Shallow Learning (SPSL) method, which combines spatial image and phase spectrum to capture the up-sampling artifacts of face forgery to improve the transferability, for face forgery detection. And we also theoretically analyze the validity of utilizing the phase spectrum. Moreover, we notice that local texture information is more crucial than high-level semantic information for the face forgery detection task. So we reduce the receptive fields by shallowing the network to suppress high-level features and focus on the local region. Extensive experiments show that SPSL can achieve the state-of-the-art performance on cross-datasets evaluation as well as multi-class classification and obtain comparable results on single dataset evaluation.
Adversarial Examples Detection beyond Image Space
Feb 23, 2021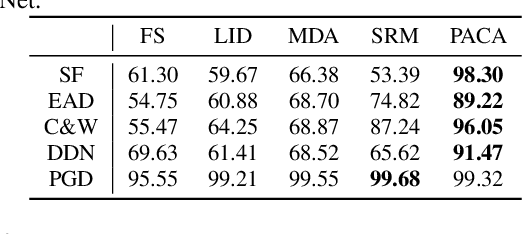

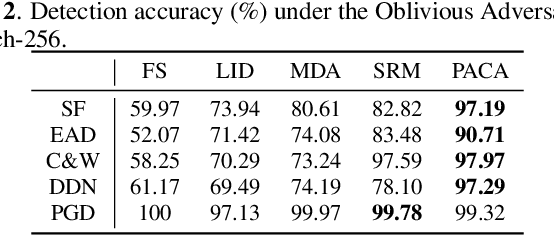
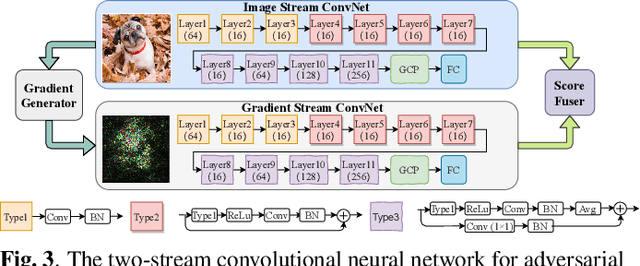
Deep neural networks have been proved that they are vulnerable to adversarial examples, which are generated by adding human-imperceptible perturbations to images. To defend these adversarial examples, various detection based methods have been proposed. However, most of them perform poorly on detecting adversarial examples with extremely slight perturbations. By exploring these adversarial examples, we find that there exists compliance between perturbations and prediction confidence, which guides us to detect few-perturbation attacks from the aspect of prediction confidence. To detect both few-perturbation attacks and large-perturbation attacks, we propose a method beyond image space by a two-stream architecture, in which the image stream focuses on the pixel artifacts and the gradient stream copes with the confidence artifacts. The experimental results show that the proposed method outperforms the existing methods under oblivious attacks and is verified effective to defend omniscient attacks as well.
Composite Adversarial Attacks
Dec 10, 2020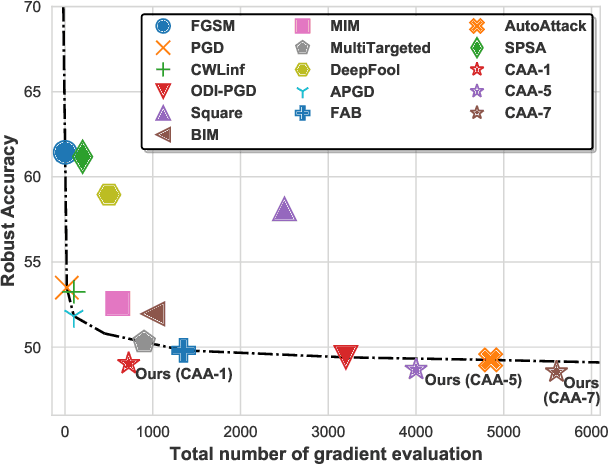

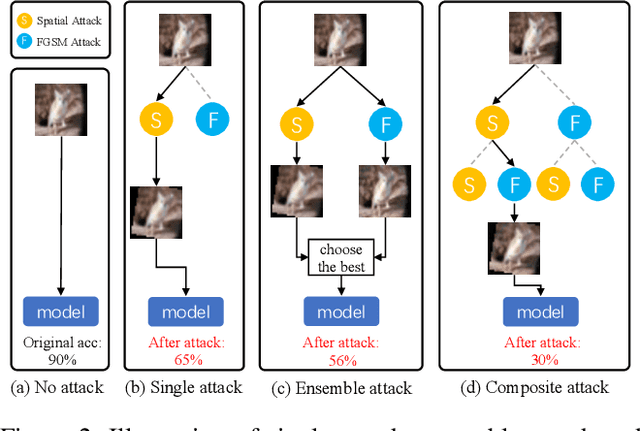
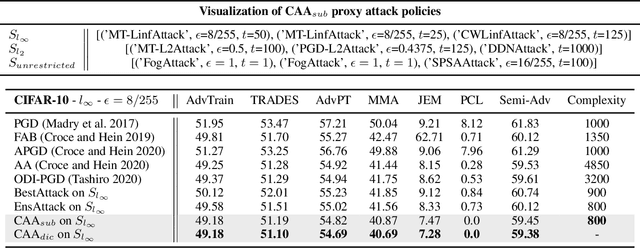
Adversarial attack is a technique for deceiving Machine Learning (ML) models, which provides a way to evaluate the adversarial robustness. In practice, attack algorithms are artificially selected and tuned by human experts to break a ML system. However, manual selection of attackers tends to be sub-optimal, leading to a mistakenly assessment of model security. In this paper, a new procedure called Composite Adversarial Attack (CAA) is proposed for automatically searching the best combination of attack algorithms and their hyper-parameters from a candidate pool of \textbf{32 base attackers}. We design a search space where attack policy is represented as an attacking sequence, i.e., the output of the previous attacker is used as the initialization input for successors. Multi-objective NSGA-II genetic algorithm is adopted for finding the strongest attack policy with minimum complexity. The experimental result shows CAA beats 10 top attackers on 11 diverse defenses with less elapsed time (\textbf{6 $\times$ faster than AutoAttack}), and achieves the new state-of-the-art on $l_{\infty}$, $l_{2}$ and unrestricted adversarial attacks.