 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Deep Calibrated Salient Object Detection
Dec 10, 2020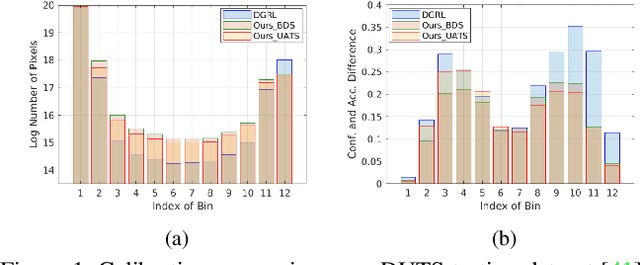
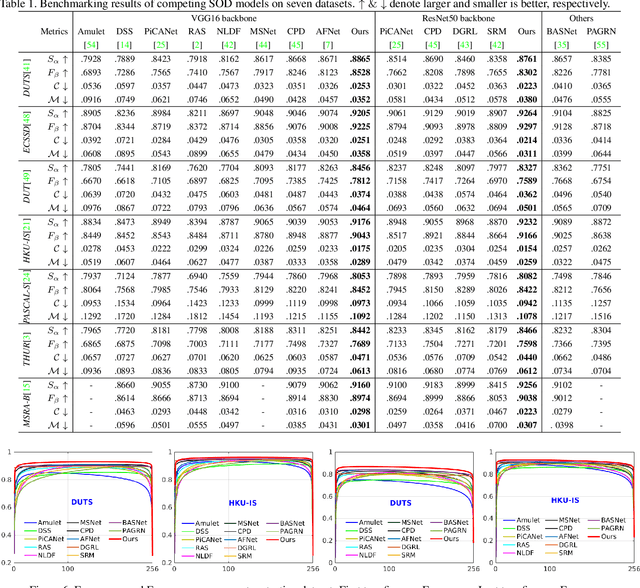

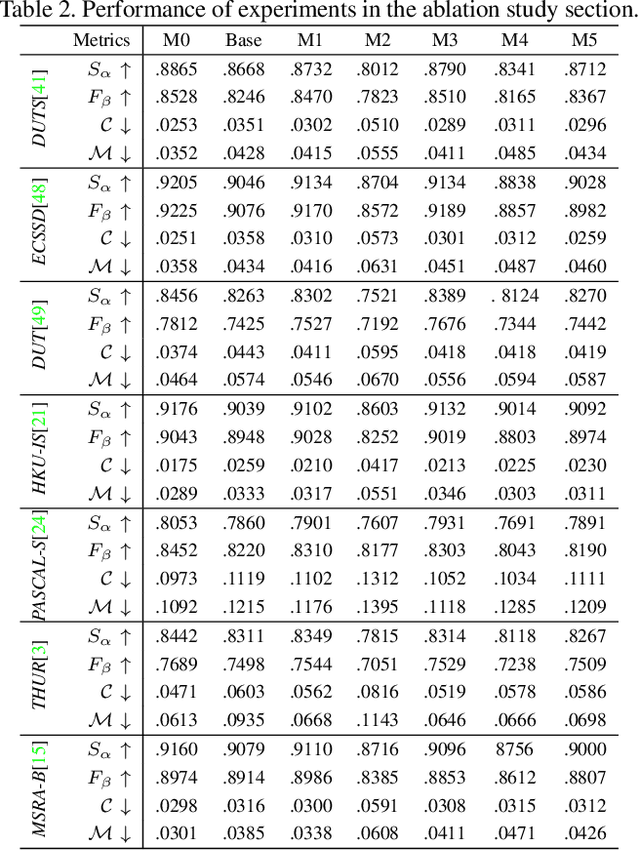
Existing deep neural network based salient object detection (SOD) methods mainly focus on pursuing high network accuracy. However, those methods overlook the gap between network accuracy and prediction confidence, known as the confidence uncalibration problem. Thus, state-of-the-art SOD networks are prone to be overconfident. In other words, the predicted confidence of the networks does not reflect the real probability of correctness of salient object detection, which significantly hinder their real-world applicability. In this paper, we introduce an uncertaintyaware deep SOD network, and propose two strategies from different perspectives to prevent deep SOD networks from being overconfident. The first strategy, namely Boundary Distribution Smoothing (BDS), generates continuous labels by smoothing the original binary ground-truth with respect to pixel-wise uncertainty. The second strategy, namely Uncertainty-Aware Temperature Scaling (UATS), exploits a relaxed Sigmoid function during both training and testing with spatially-variant temperature scaling to produce softened output. Both strategies can be incorporated into existing deep SOD networks with minimal efforts. Moreover, we propose a new saliency evaluation metric, namely dense calibration measure C, to measure how the model is calibrated on a given dataset. Extensive experimental results on seven benchmark datasets demonstrate that our solutions can not only better calibrate SOD models, but also improve the network accuracy.
Depth Completion using Piecewise Planar Model
Dec 06, 2020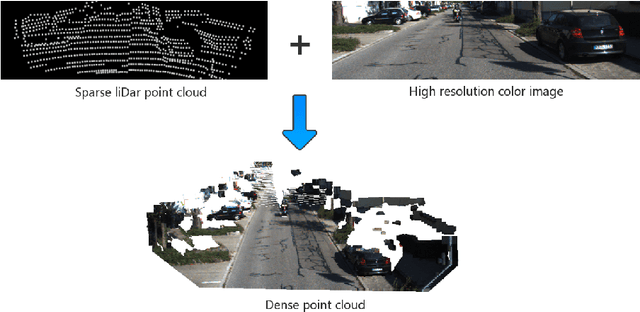


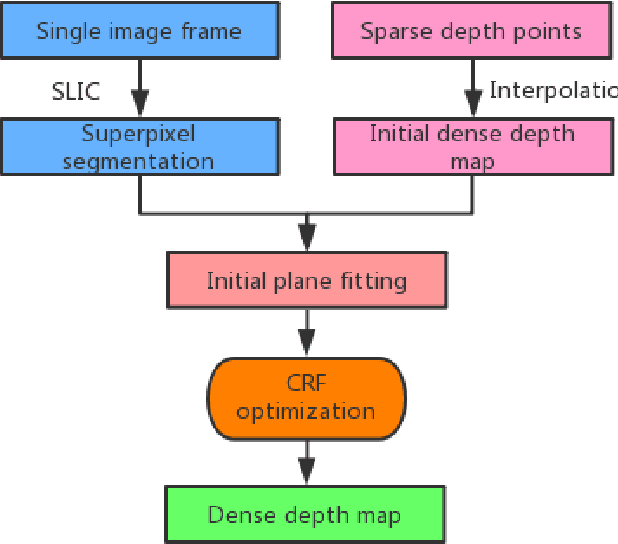
A depth map can be represented by a set of learned bases and can be efficiently solved in a closed form solution. However, one issue with this method is that it may create artifacts when colour boundaries are inconsistent with depth boundaries. In fact, this is very common in a natural image. To address this issue, we enforce a more strict model in depth recovery: a piece-wise planar model. More specifically, we represent the desired depth map as a collection of 3D planar and the reconstruction problem is formulated as the optimization of planar parameters. Such a problem can be formulated as a continuous CRF optimization problem and can be solved through particle based method (MP-PBP) \cite{Yamaguchi14}. Extensive experimental evaluations on the KITTI visual odometry dataset show that our proposed methods own high resistance to false object boundaries and can generate useful and visually pleasant 3D point clouds.
Efficient Depth Completion Using Learned Bases
Dec 02, 2020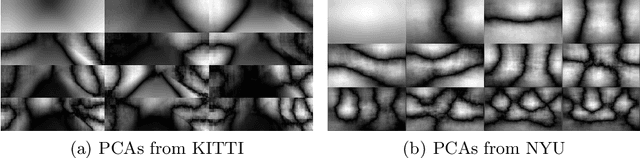



In this paper, we propose a new global geometry constraint for depth completion. By assuming depth maps often lay on low dimensional subspaces, a dense depth map can be approximated by a weighted sum of full-resolution principal depth bases. The principal components of depth fields can be learned from natural depth maps. The given sparse depth points are served as a data term to constrain the weighting process. When the input depth points are too sparse, the recovered dense depth maps are often over smoothed. To address this issue, we add a colour-guided auto-regression model as another regularization term. It assumes the reconstructed depth maps should share the same nonlocal similarity in the accompanying colour image. Our colour-guided PCA depth completion method has closed-form solutions, thus can be efficiently solved and is significantly more accurate than PCA only method. Extensive experiments on KITTI and Middlebury datasets demonstrate the superior performance of our proposed method.
Displacement-Invariant Cost Computation for Efficient Stereo Matching
Dec 01, 2020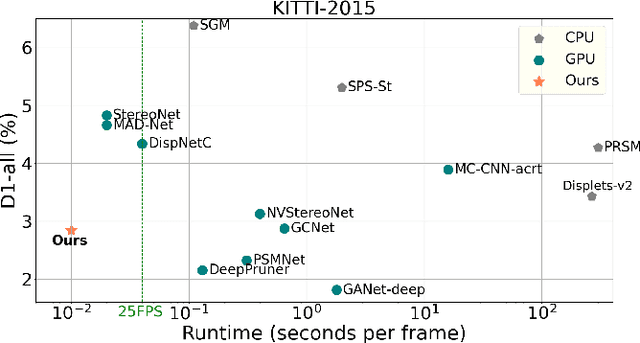

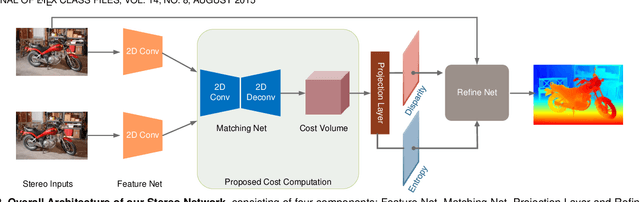
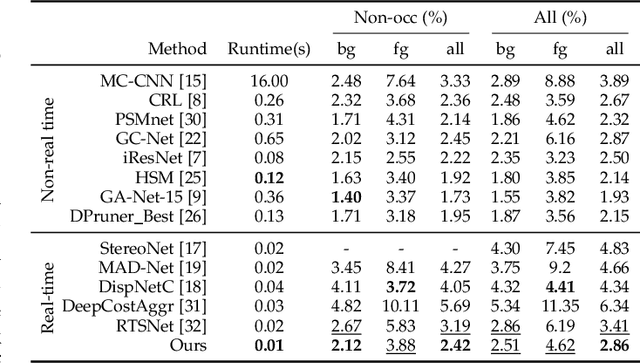
Although deep learning-based methods have dominated stereo matching leaderboards by yielding unprecedented disparity accuracy, their inference time is typically slow, on the order of seconds for a pair of 540p images. The main reason is that the leading methods employ time-consuming 3D convolutions applied to a 4D feature volume. A common way to speed up the computation is to downsample the feature volume, but this loses high-frequency details. To overcome these challenges, we propose a \emph{displacement-invariant cost computation module} to compute the matching costs without needing a 4D feature volume. Rather, costs are computed by applying the same 2D convolution network on each disparity-shifted feature map pair independently. Unlike previous 2D convolution-based methods that simply perform context mapping between inputs and disparity maps, our proposed approach learns to match features between the two images. We also propose an entropy-based refinement strategy to refine the computed disparity map, which further improves speed by avoiding the need to compute a second disparity map on the right image. Extensive experiments on standard datasets (SceneFlow, KITTI, ETH3D, and Middlebury) demonstrate that our method achieves competitive accuracy with much less inference time. On typical image sizes, our method processes over 100 FPS on a desktop GPU, making our method suitable for time-critical applications such as autonomous driving. We also show that our approach generalizes well to unseen datasets, outperforming 4D-volumetric methods.
Displacement-Invariant Matching Cost Learning for Accurate Optical Flow Estimation
Oct 28, 2020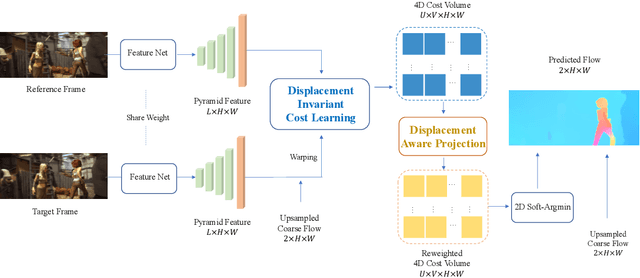

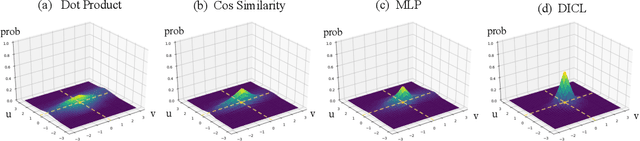
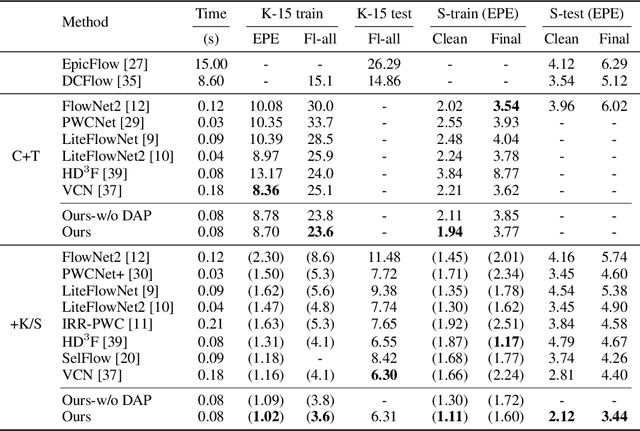
Learning matching costs has been shown to be critical to the success of the state-of-the-art deep stereo matching methods, in which 3D convolutions are applied on a 4D feature volume to learn a 3D cost volume. However, this mechanism has never been employed for the optical flow task. This is mainly due to the significantly increased search dimension in the case of optical flow computation, ie, a straightforward extension would require dense 4D convolutions in order to process a 5D feature volume, which is computationally prohibitive. This paper proposes a novel solution that is able to bypass the requirement of building a 5D feature volume while still allowing the network to learn suitable matching costs from data. Our key innovation is to decouple the connection between 2D displacements and learn the matching costs at each 2D displacement hypothesis independently, ie, displacement-invariant cost learning. Specifically, we apply the same 2D convolution-based matching net independently on each 2D displacement hypothesis to learn a 4D cost volume. Moreover, we propose a displacement-aware projection layer to scale the learned cost volume, which reconsiders the correlation between different displacement candidates and mitigates the multi-modal problem in the learned cost volume. The cost volume is then projected to optical flow estimation through a 2D soft-argmin layer. Extensive experiments show that our approach achieves state-of-the-art accuracy on various datasets, and outperforms all published optical flow methods on the Sintel benchmark.
Hierarchical Neural Architecture Search for Deep Stereo Matching
Oct 26, 2020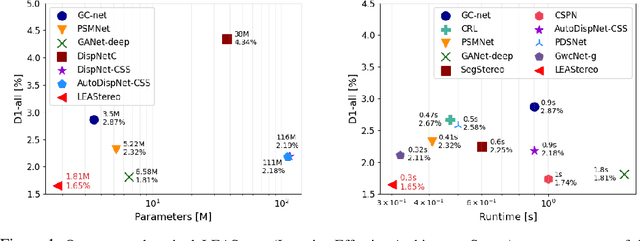
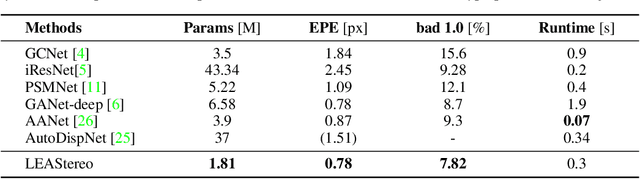
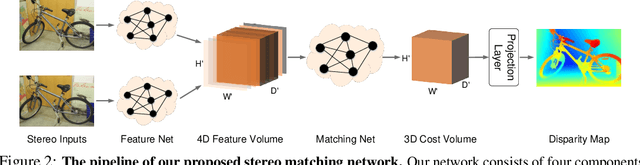
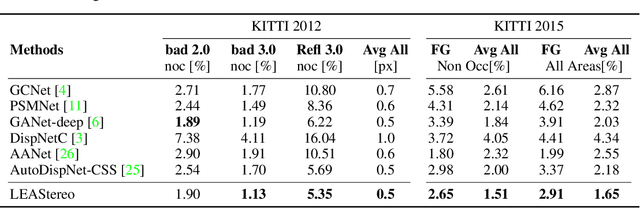
To reduce the human efforts in neural network design, Neural Architecture Search (NAS) has been applied with remarkable success to various high-level vision tasks such as classification and semantic segmentation. The underlying idea for the NAS algorithm is straightforward, namely, to enable the network the ability to choose among a set of operations (e.g., convolution with different filter sizes), one is able to find an optimal architecture that is better adapted to the problem at hand. However, so far the success of NAS has not been enjoyed by low-level geometric vision tasks such as stereo matching. This is partly due to the fact that state-of-the-art deep stereo matching networks, designed by humans, are already sheer in size. Directly applying the NAS to such massive structures is computationally prohibitive based on the currently available mainstream computing resources. In this paper, we propose the first end-to-end hierarchical NAS framework for deep stereo matching by incorporating task-specific human knowledge into the neural architecture search framework. Specifically, following the gold standard pipeline for deep stereo matching (i.e., feature extraction -- feature volume construction and dense matching), we optimize the architectures of the entire pipeline jointly. Extensive experiments show that our searched network outperforms all state-of-the-art deep stereo matching architectures and is ranked at the top 1 accuracy on KITTI stereo 2012, 2015 and Middlebury benchmarks, as well as the top 1 on SceneFlow dataset with a substantial improvement on the size of the network and the speed of inference. The code is available at https://github.com/XuelianCheng/LEAStereo.
Novel View Synthesis from only a 6-DoF Camera Pose by Two-stage Networks
Oct 22, 2020
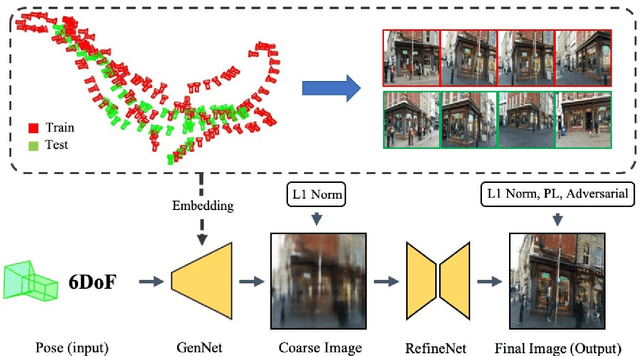


Novel view synthesis is a challenging problem in computer vision and robotics. Different from the existing works, which need the reference images or 3D models of the scene to generate images under novel views, we propose a novel paradigm to this problem. That is, we synthesize the novel view from only a 6-DoF camera pose directly. Although this setting is the most straightforward way, there are few works addressing it. While, our experiments demonstrate that, with a concise CNN, we could get a meaningful parametric model that could reconstruct the correct scenery images only from the 6-DoF pose. To this end, we propose a two-stage learning strategy, which consists of two consecutive CNNs: GenNet and RefineNet. GenNet generates a coarse image from a camera pose. RefineNet is a generative adversarial network that refines the coarse image. In this way, we decouple the geometric relationship between mapping and texture detail rendering. Extensive experiments conducted on the public datasets prove the effectiveness of our method. We believe this paradigm is of high research and application value and could be an important direction in novel view synthesis.
PRAFlow_RVC: Pyramid Recurrent All-Pairs Field Transforms for Optical Flow Estimation in Robust Vision Challenge 2020
Sep 14, 2020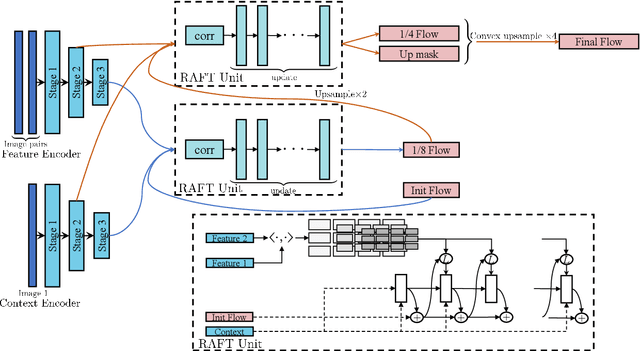
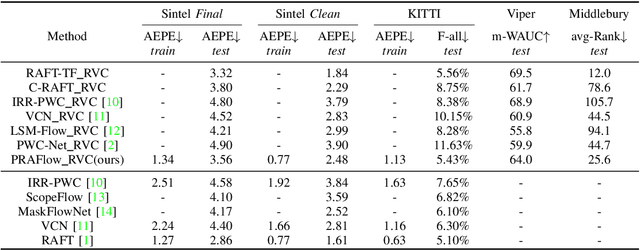
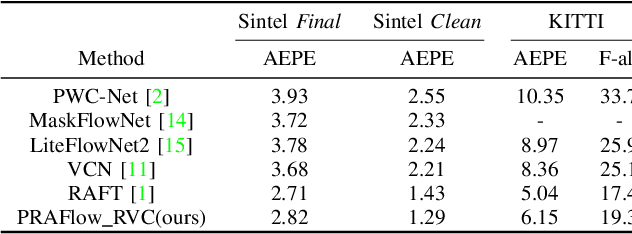

Optical flow estimation is an important computer vision task, which aims at estimating the dense correspondences between two frames. RAFT (Recurrent All Pairs Field Transforms) currently represents the state-of-the-art in optical flow estimation. It has excellent generalization ability and has obtained outstanding results across several benchmarks. To further improve the robustness and achieve accurate optical flow estimation, we present PRAFlow (Pyramid Recurrent All-Pairs Flow), which builds upon the pyramid network structure. Due to computational limitation, our proposed network structure only uses two pyramid layers. At each layer, the RAFT unit is used to estimate the optical flow at the current resolution. Our model was trained on several simulate and real-image datasets, submitted to multiple leaderboards using the same model and parameters, and won the 2nd place in the optical flow task of ECCV 2020 workshop: Robust Vision Challenge.
Uncertainty Inspired RGB-D Saliency Detection
Sep 07, 2020
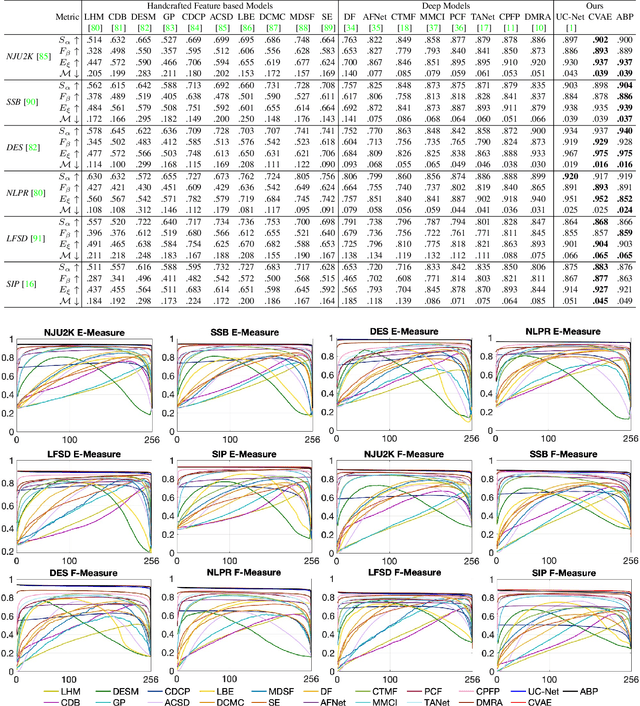
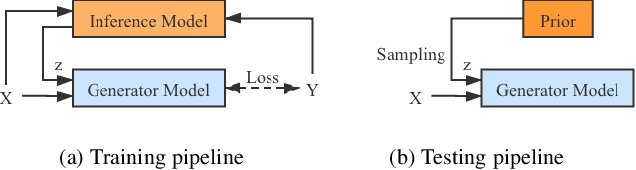

We propose the first stochastic framework to employ uncertainty for RGB-D saliency detection by learning from the data labeling process. Existing RGB-D saliency detection models treat this task as a point estimation problem by predicting a single saliency map following a deterministic learning pipeline. We argue that, however, the deterministic solution is relatively ill-posed. Inspired by the saliency data labeling process, we propose a generative architecture to achieve probabilistic RGB-D saliency detection which utilizes a latent variable to model the labeling variations. Our framework includes two main models: 1) a generator model, which maps the input image and latent variable to stochastic saliency prediction, and 2) an inference model, which gradually updates the latent variable by sampling it from the true or approximate posterior distribution. The generator model is an encoder-decoder saliency network. To infer the latent variable, we introduce two different solutions: i) a Conditional Variational Auto-encoder with an extra encoder to approximate the posterior distribution of the latent variable; and ii) an Alternating Back-Propagation technique, which directly samples the latent variable from the true posterior distribution. Qualitative and quantitative results on six challenging RGB-D benchmark datasets show our approach's superior performance in learning the distribution of saliency maps. The source code is publicly available via our project page: https://github.com/JingZhang617/UCNet.
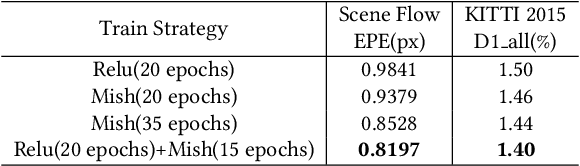
MSMD-Net: Deep Stereo Matching with Multi-scale and Multi-dimension Cost Volume
Jun 23, 2020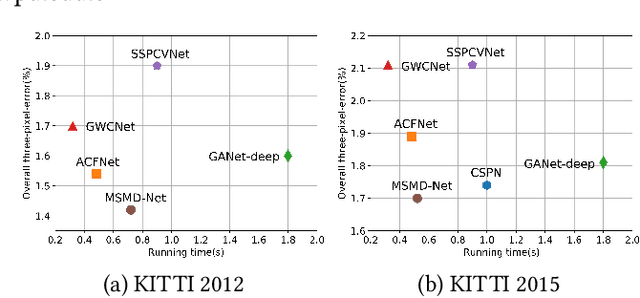

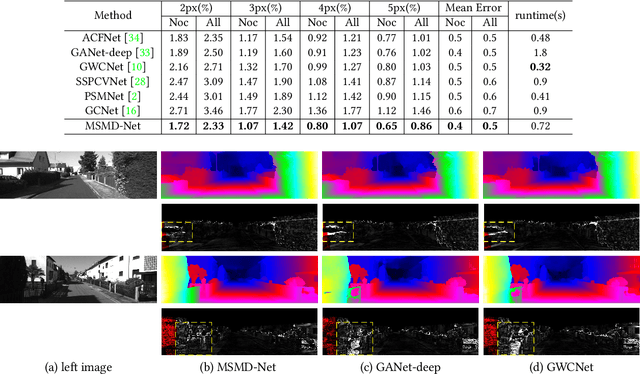
Deep end-to-end learning based stereo matching methods have achieved great success as witnessed by the leaderboards across different benchmarking datasets (KITTI, Middlebury, ETH3D, etc), where the cost volume representation is an indispensable step to the success. However, most existing work only employs a single cost volume, which cannot fully exploit the multi-scale cues in stereo matching and provide guidance for disparity refinement. What's more, the single cost volume representation also limits the disparity range and the resolution of the disparity estimation. In this paper, we propose MSMD-Net (Multi-Scale and Multi-Dimension) to construct multi-scale and multi-dimension cost volume. At the multi-scale level, we generate four 4D combination volumes at different scales and integrate them in 3D cost aggregation to predict an initial disparity estimation. At the multi-dimension level, we construct a 3D warped correlation volume and use it to refine the initial disparity map with residual learning. These two dimensional cost volumes are complementary to each other and can boost the performance of disparity estimation. Additionally, we propose a switch training strategy to further improve the accuracy of disparity estimation, where we switch two kinds of different activation functions to alleviate the overfitting issue in the pre-training process. Our proposed method was evaluated on several benchmark datasets and ranked first on KITTI 2012 leaderboard and second on KITTI 2015 leaderboard as of June 23.The code of MSMD-Net is available at https://github.com/gallenszl/MSMD-Net.