 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETR: Entropy Trend Reward for Efficient Chain-of-Thought Reasoning
Apr 07, 2026Chain-of-thought (CoT) reasoning improves large language model performance on complex tasks, but often produces excessively long and inefficient reasoning traces. Existing methods shorten CoTs using length penalties or global entropy reduction, implicitly assuming that low uncertainty is desirable throughout reasoning. We show instead that reasoning efficiency is governed by the trajectory of uncertainty. CoTs with dominant downward entropy trends are substantially shorter. Motivated by this insight, we propose Entropy Trend Reward (ETR), a trajectory-aware objective that encourages progressive uncertainty reduction while allowing limited local exploration. We integrate ETR into Group Relative Policy Optimization (GRPO) and evaluate it across multiple reasoning models and challenging benchmarks. ETR consistently achieves a superior accuracy-efficiency tradeoff, improving DeepSeek-R1-Distill-7B by 9.9% in accuracy while reducing CoT length by 67% across four benchmarks. Code is available at https://github.com/Xuan1030/ETR
Real-time Appearance-based Gaze Estimation for Open Domains
Mar 27, 2026Appearance-based gaze estimation (AGE) has achieved remarkable performance in constrained settings, yet we reveal a significant generalization gap where existing AGE models often fail in practical, unconstrained scenarios, particularly those involving facial wearables and poor lighting conditions. We attribute this failure to two core factors: limited image diversity and inconsistent label fidelity across different datasets, especially along the pitch axis. To address these, we propose a robust AGE framework that enhances generalization without requiring additional human-annotated data. First, we expand the image manifold via an ensemble of augmentation techniques, including synthesis of eyeglasses, masks, and varied lighting. Second, to mitigate the impact of anisotropic inter-dataset label deviation, we reformulate gaze regression as a multi-task learning problem, incorporating multi-view supervised contrastive (SupCon) learning, discretized label classification, and eye-region segmentation as auxiliary objectives. To rigorously validate our approach, we curate new benchmark datasets designed to evaluate gaze robustness under challenging conditions, a dimension largely overlooked by existing evaluation protocols. Our MobileNet-based lightweight model achieves generalization performance competitive with the state-of-the-art (SOTA) UniGaze-H, while utilizing less than 1\% of its parameters, enabling high-fidelity, real-time gaze tracking on mobile devices.
CamDirector: Towards Long-Term Coherent Video Trajectory Editing
Feb 27, 2026Video (camera) trajectory editing aims to synthesize new videos that follow user-defined camera paths while preserving scene content and plausibly inpainting previously unseen regions, upgrading amateur footage into professionally styled videos. Existing VTE methods struggle with precise camera control and long-range consistency because they either inject target poses through a limited-capacity embedding or rely on single-frame warping with only implicit cross-frame aggregation in video diffusion models. To address these issues, we introduce a new VTE framework that 1) explicitly aggregates information across the entire source video via a hybrid warping scheme. Specifically, static regions are progressively fused into a world cache then rendered to target camera poses, while dynamic regions are directly warped; their fusion yields globally consistent coarse frames that guide refinement. 2) processes video segments jointly with their history via a history-guided autoregressive diffusion model, while the world cache is incrementally updated to reinforce already inpainted content, enabling long-term temporal coherence. Finally, we present iPhone-PTZ, a new VTE benchmark with diverse camera motions and large trajectory variations, and achieve state-of-the-art performance with fewer parameters.
Few-Shot-Based Modular Image-to-Video Adapter for Diffusion Models
Dec 23, 2025Diffusion models (DMs) have recently achieved impressive photorealism in image and video generation. However, their application to image animation remains limited, even when trained on large-scale datasets. Two primary challenges contribute to this: the high dimensionality of video signals leads to a scarcity of training data, causing DMs to favor memorization over prompt compliance when generating motion; moreover, DMs struggle to generalize to novel motion patterns not present in the training set, and fine-tuning them to learn such patterns, especially using limited training data, is still under-explored. To address these limitations, we propose Modular Image-to-Video Adapter (MIVA), a lightweight sub-network attachable to a pre-trained DM, each designed to capture a single motion pattern and scalable via parallelization. MIVAs can be efficiently trained on approximately ten samples using a single consumer-grade GPU. At inference time, users can specify motion by selecting one or multiple MIVAs, eliminating the need for prompt engineering. Extensive experiments demonstrate that MIVA enables more precise motion control while maintaining, or even surpassing, the generation quality of models trained on significantly larger datasets.
Widget2Code: From Visual Widgets to UI Code via Multimodal LLMs
Dec 22, 2025User interface to code (UI2Code) aims to generate executable code that can faithfully reconstruct a given input UI. Prior work focuses largely on web pages and mobile screens, leaving app widgets underexplored. Unlike web or mobile UIs with rich hierarchical context, widgets are compact, context-free micro-interfaces that summarize key information through dense layouts and iconography under strict spatial constraints. Moreover, while (image, code) pairs are widely available for web or mobile UIs, widget designs are proprietary and lack accessible markup. We formalize this setting as the Widget-to-Code (Widget2Code) and introduce an image-only widget benchmark with fine-grained, multi-dimensional evaluation metrics. Benchmarking shows that although generalized multimodal large language models (MLLMs) outperform specialized UI2Code methods, they still produce unreliable and visually inconsistent code. To address these limitations, we develop a baseline that jointly advances perceptual understanding and structured code generation. At the perceptual level, we follow widget design principles to assemble atomic components into complete layouts, equipped with icon retrieval and reusable visualization modules. At the system level, we design an end-to-end infrastructure, WidgetFactory, which includes a framework-agnostic widget-tailored domain-specific language (WidgetDSL) and a compiler that translates it into multiple front-end implementations (e.g., React, HTML/CSS). An adaptive rendering module further refines spatial dimensions to satisfy compactness constraints. Together, these contributions substantially enhance visual fidelity, establishing a strong baseline and unified infrastructure for future Widget2Code research.
Constrained Gaussian Wasserstein Optimal Transport with Commutative Covariance Matrices
Mar 05, 2025



Optimal transport has found widespread applications in signal processing and machine learning. Among its many equivalent formulations, optimal transport seeks to reconstruct a random variable/vector with a prescribed distribution at the destination while minimizing the expected distortion relative to a given random variable/vector at the source. However, in practice, certain constraints may render the optimal transport plan infeasible. In this work, we consider three types of constraints: rate constraints, dimension constraints, and channel constraints, motivated by perception-aware lossy compression, generative principal component analysis, and deep joint source-channel coding, respectively. Special attenion is given to the setting termed Gaussian Wasserstein optimal transport, where both the source and reconstruction variables are multivariate Gaussian, and the end-to-end distortion is measured by the mean squared error. We derive explicit results for the minimum achievable mean squared error under the three aforementioned constraints when the covariance matrices of the source and reconstruction variables commute.
Adapting to Distribution Shift by Visual Domain Prompt Generation
May 05, 2024



In this paper, we aim to adapt a model at test-time using a few unlabeled data to address distribution shifts. To tackle the challenges of extracting domain knowledge from a limited amount of data, it is crucial to utilize correlated information from pre-trained backbones and source domains. Previous studies fail to utilize recent foundation models with strong out-of-distribution generalization. Additionally, domain-centric designs are not flavored in their works. Furthermore, they employ the process of modelling source domains and the process of learning to adapt independently into disjoint training stages. In this work, we propose an approach on top of the pre-computed features of the foundation model. Specifically, we build a knowledge bank to learn the transferable knowledge from source domains. Conditioned on few-shot target data, we introduce a domain prompt generator to condense the knowledge bank into a domain-specific prompt. The domain prompt then directs the visual features towards a particular domain via a guidance module. Moreover, we propose a domain-aware contrastive loss and employ meta-learning to facilitate domain knowledge extraction. Extensive experiments are conducted to validate the domain knowledge extraction. The proposed method outperforms previous work on 5 large-scale benchmarks including WILDS and DomainNet.
Test-Time Personalization with Meta Prompt for Gaze Estimation
Jan 03, 2024



Despite the recent remarkable achievement in gaze estimation, efficient and accurate personalization of gaze estimation without labels is a practical problem but rarely touched on in the literature. To achieve efficient personalization, we take inspiration from the recent advances in Natural Language Processing (NLP) by updating a negligible number of parameters, "prompts", at the test time. Specifically, the prompt is additionally attached without perturbing original network and can contain less than 1% of a ResNet-18's parameters. Our experiments show high efficiency of the prompt tuning approach. The proposed one can be 10 times faster in terms of adaptation speed than the methods compared. However, it is non-trivial to update the prompt for personalized gaze estimation without labels. At the test time, it is essential to ensure that the minimizing of particular unsupervised loss leads to the goals of minimizing gaze estimation error. To address this difficulty, we propose to meta-learn the prompt to ensure that its updates align with the goal. Our experiments show that the meta-learned prompt can be effectively adapted even with a simple symmetry loss. In addition, we experiment on four cross-dataset validations to show the remarkable advantages of the proposed method.
Meta-DMoE: Adapting to Domain Shift by Meta-Distillation from Mixture-of-Experts
Oct 08, 2022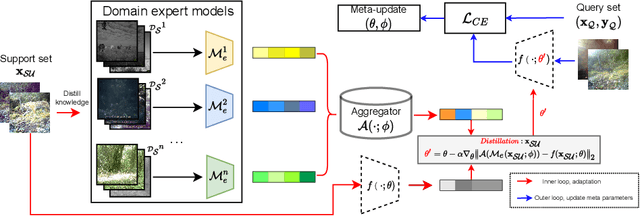
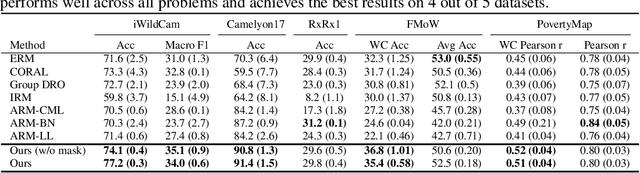
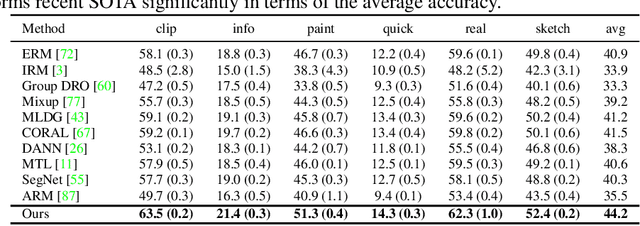

In this paper, we tackle the problem of domain shift. Most existing methods perform training on multiple source domains using a single model, and the same trained model is used on all unseen target domains. Such solutions are sub-optimal as each target domain exhibits its own speciality, which is not adapted. Furthermore, expecting the single-model training to learn extensive knowledge from the multiple source domains is counterintuitive. The model is more biased toward learning only domain-invariant features and may result in negative knowledge transfer. In this work, we propose a novel framework for unsupervised test-time adaptation, which is formulated as a knowledge distillation process to address domain shift. Specifically, we incorporate Mixture-of-Experts (MoE) as teachers, where each expert is separately trained on different source domains to maximize their speciality. Given a test-time target domain, a small set of unlabeled data is sampled to query the knowledge from MoE. As the source domains are correlated to the target domains, a transformer-based aggregator then combines the domain knowledge by examining the interconnection among them. The output is treated as a supervision signal to adapt a student prediction network toward the target domain. We further employ meta-learning to enforce the aggregator to distill positive knowledge and the student network to achieve fast adaptation. Extensive experiments demonstrate that the proposed method outperforms the state-of-the-art and validates the effectiveness of each proposed component. Our code is available at https://github.com/n3il666/Meta-DMoE.
Improving ProtoNet for Few-Shot Video Object Recognition: Winner of ORBIT Challenge 2022
Oct 01, 2022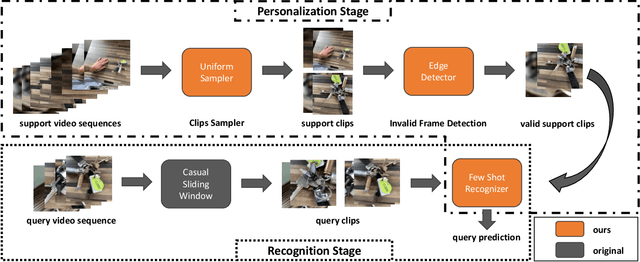
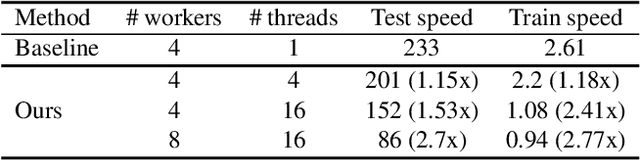
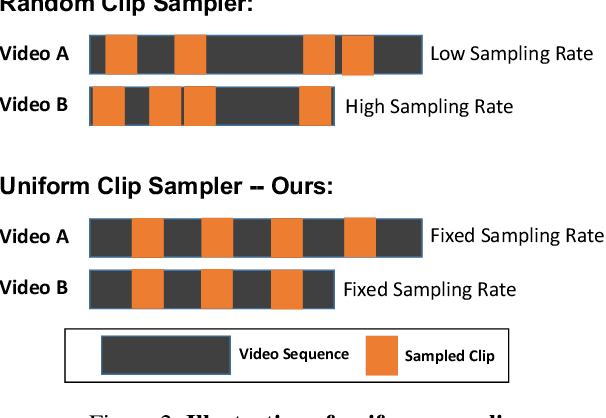
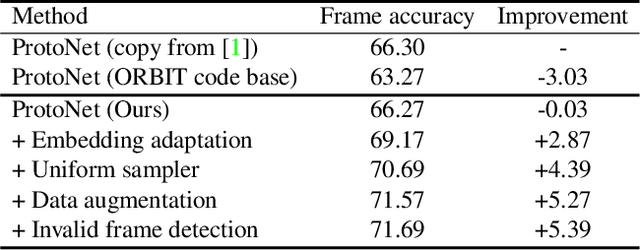
In this work, we present the winning solution for ORBIT Few-Shot Video Object Recognition Challenge 2022. Built upon the ProtoNet baseline, the performance of our method is improved with three effective techniques. These techniques include the embedding adaptation, the uniform video clip sampler and the invalid frame detection. In addition, we re-factor and re-implement the official codebase to encourage modularity, compatibility and improved performance. Our implementation accelerates the data loading in both training and testing.