 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClean-NeRF: Reformulating NeRF to account for View-Dependent Observations
Mar 26, 2023



While Neural Radiance Fields (NeRFs) had achieved unprecedented novel view synthesis results, they have been struggling in dealing with large-scale cluttered scenes with sparse input views and highly view-dependent appearances. Specifically, existing NeRF-based models tend to produce blurry rendering with the volumetric reconstruction often inaccurate, where a lot of reconstruction errors are observed in the form of foggy "floaters" hovering within the entire volume of an opaque 3D scene. Such inaccuracies impede NeRF's potential for accurate 3D NeRF registration, object detection, segmentation, etc., which possibly accounts for only limited significant research effort so far to directly address these important 3D fundamental computer vision problems to date. This paper analyzes the NeRF's struggles in such settings and proposes Clean-NeRF for accurate 3D reconstruction and novel view rendering in complex scenes. Our key insights consist of enforcing effective appearance and geometry constraints, which are absent in the conventional NeRF reconstruction, by 1) automatically detecting and modeling view-dependent appearances in the training views to prevent them from interfering with density estimation, which is complete with 2) a geometric correction procedure performed on each traced ray during inference. Clean-NeRF can be implemented as a plug-in that can immediately benefit existing NeRF-based methods without additional input. Codes will be released.
FLNeRF: 3D Facial Landmarks Estimation in Neural Radiance Fields
Nov 22, 2022This paper presents the first significant work on directly predicting 3D face landmarks on neural radiance fields (NeRFs), without using intermediate representations such as 2D images, depth maps, or point clouds. Our 3D coarse-to-fine Face Landmarks NeRF (FLNeRF) model efficiently samples from the NeRF on the whole face with individual facial features for accurate landmarks. To mitigate the limited number of facial expressions in the available data, local and non-linear NeRF warp is applied at facial features in fine scale to simulate large emotions range, including exaggerated facial expressions (e.g., cheek blowing, wide opening mouth, eye blinking), for training FLNeRF. With such expression augmentation, our model can predict 3D landmarks not limited to the 20 discrete expressions given in the data. Robust 3D NeRF facial landmarks contribute to many downstream tasks. As an example, we modify MoFaNeRF to enable high-quality face editing and swapping using face landmarks on NeRF, allowing more direct control and wider range of complex expressions. Experiments show that the improved model using landmarks achieves comparable to better results.
NeRF-RPN: A general framework for object detection in NeRFs
Nov 22, 2022

This paper presents the first significant object detection framework, NeRF-RPN, which directly operates on NeRF. Given a pre-trained NeRF model, NeRF-RPN aims to detect all bounding boxes of objects in a scene. By exploiting a novel voxel representation that incorporates multi-scale 3D neural volumetric features, we demonstrate it is possible to regress the 3D bounding boxes of objects in NeRF directly without rendering the NeRF at any viewpoint. NeRF-RPN is a general framework and can be applied to detect objects without class labels. We experimented the NeRF-RPN with various backbone architectures, RPN head designs and loss functions. All of them can be trained in an end-to-end manner to estimate high quality 3D bounding boxes. To facilitate future research in object detection for NeRF, we built a new benchmark dataset which consists of both synthetic and real-world data with careful labeling and clean up. Please click https://youtu.be/M8_4Ih1CJjE for visualizing the 3D region proposals by our NeRF-RPN. Code and dataset will be made available.
ONeRF: Unsupervised 3D Object Segmentation from Multiple Views
Nov 22, 2022We present ONeRF, a method that automatically segments and reconstructs object instances in 3D from multi-view RGB images without any additional manual annotations. The segmented 3D objects are represented using separate Neural Radiance Fields (NeRFs) which allow for various 3D scene editing and novel view rendering. At the core of our method is an unsupervised approach using the iterative Expectation-Maximization algorithm, which effectively aggregates 2D visual features and the corresponding 3D cues from multi-views for joint 3D object segmentation and reconstruction. Unlike existing approaches that can only handle simple objects, our method produces segmented full 3D NeRFs of individual objects with complex shapes, topologies and appearance. The segmented ONeRfs enable a range of 3D scene editing, such as object transformation, insertion and deletion.
H-VFI: Hierarchical Frame Interpolation for Videos with Large Motions
Nov 21, 2022



Capitalizing on the rapid development of neural networks, recent video frame interpolation (VFI) methods have achieved notable improvements. However, they still fall short for real-world videos containing large motions. Complex deformation and/or occlusion caused by large motions make it an extremely difficult problem in video frame interpolation. In this paper, we propose a simple yet effective solution, H-VFI, to deal with large motions in video frame interpolation. H-VFI contributes a hierarchical video interpolation transformer (HVIT) to learn a deformable kernel in a coarse-to-fine strategy in multiple scales. The learnt deformable kernel is then utilized in convolving the input frames for predicting the interpolated frame. Starting from the smallest scale, H-VFI updates the deformable kernel by a residual in succession based on former predicted kernels, intermediate interpolated results and hierarchical features from transformer. Bias and masks to refine the final outputs are then predicted by a transformer block based on interpolated results. The advantage of such a progressive approximation is that the large motion frame interpolation problem can be decomposed into several relatively simpler sub-tasks, which enables a very accurate prediction in the final results. Another noteworthy contribution of our paper consists of a large-scale high-quality dataset, YouTube200K, which contains videos depicting a great variety of scenarios captured at high resolution and high frame rate. Extensive experiments on multiple frame interpolation benchmarks validate that H-VFI outperforms existing state-of-the-art methods especially for videos with large motions.
Normalization Perturbation: A Simple Domain Generalization Method for Real-World Domain Shifts
Nov 09, 2022



Improving model's generalizability against domain shifts is crucial, especially for safety-critical applications such as autonomous driving. Real-world domain styles can vary substantially due to environment changes and sensor noises, but deep models only know the training domain style. Such domain style gap impedes model generalization on diverse real-world domains. Our proposed Normalization Perturbation (NP) can effectively overcome this domain style overfitting problem. We observe that this problem is mainly caused by the biased distribution of low-level features learned in shallow CNN layers. Thus, we propose to perturb the channel statistics of source domain features to synthesize various latent styles, so that the trained deep model can perceive diverse potential domains and generalizes well even without observations of target domain data in training. We further explore the style-sensitive channels for effective style synthesis. Normalization Perturbation only relies on a single source domain and is surprisingly effective and extremely easy to implement. Extensive experiments verify the effectiveness of our method for generalizing models under real-world domain shifts.
SDRTV-to-HDRTV Conversion via Spatial-Temporal Feature Fusion
Nov 04, 2022HDR(High Dynamic Range) video can reproduce realistic scenes more realistically, with a wider gamut and broader brightness range. HDR video resources are still scarce, and most videos are still stored in SDR (Standard Dynamic Range) format. Therefore, SDRTV-to-HDRTV Conversion (SDR video to HDR video) can significantly enhance the user's video viewing experience. Since the correlation between adjacent video frames is very high, the method utilizing the information of multiple frames can improve the quality of the converted HDRTV. Therefore, we propose a multi-frame fusion neural network \textbf{DSLNet} for SDRTV to HDRTV conversion. We first propose a dynamic spatial-temporal feature alignment module \textbf{DMFA}, which can align and fuse multi-frame. Then a novel spatial-temporal feature modulation module \textbf{STFM}, STFM extracts spatial-temporal information of adjacent frames for more accurate feature modulation. Finally, we design a quality enhancement module \textbf{LKQE} with large kernels, which can enhance the quality of generated HDR videos. To evaluate the performance of the proposed method, we construct a corresponding multi-frame dataset using HDR video of the HDR10 standard to conduct a comprehensive evaluation of different methods. The experimental results show that our method obtains state-of-the-art performance. The dataset and code will be released.
Scene Text Image Super-Resolution via Content Perceptual Loss and Criss-Cross Transformer Blocks
Oct 13, 2022

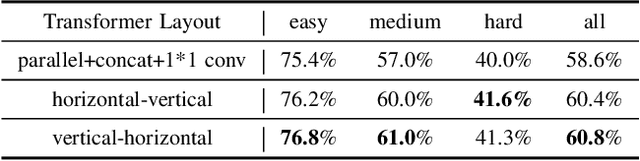

Text image super-resolution is a unique and important task to enhance readability of text images to humans. It is widely used as pre-processing in scene text recognition. However, due to the complex degradation in natural scenes, recovering high-resolution texts from the low-resolution inputs is ambiguous and challenging. Existing methods mainly leverage deep neural networks trained with pixel-wise losses designed for natural image reconstruction, which ignore the unique character characteristics of texts. A few works proposed content-based losses. However, they only focus on text recognizers' accuracy, while the reconstructed images may still be ambiguous to humans. Further, they often have weak generalizability to handle cross languages. To this end, we present TATSR, a Text-Aware Text Super-Resolution framework, which effectively learns the unique text characteristics using Criss-Cross Transformer Blocks (CCTBs) and a novel Content Perceptual (CP) Loss. The CCTB extracts vertical and horizontal content information from text images by two orthogonal transformers, respectively. The CP Loss supervises the text reconstruction with content semantics by multi-scale text recognition features, which effectively incorporates content awareness into the framework. Extensive experiments on various language datasets demonstrate that TATSR outperforms state-of-the-art methods in terms of both recognition accuracy and human perception.
Unsupervised Multi-View Object Segmentation Using Radiance Field Propagation
Oct 02, 2022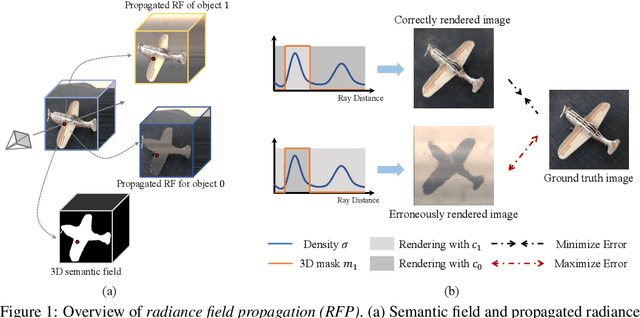
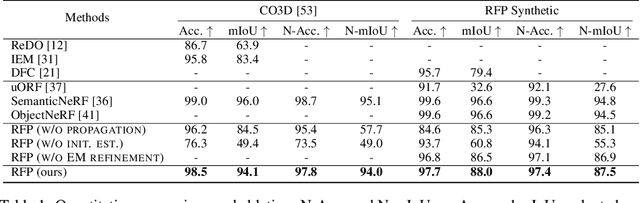

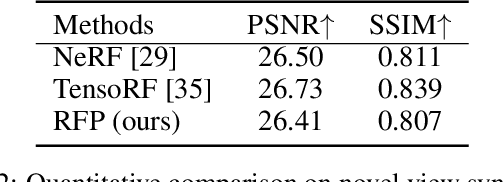
We present radiance field propagation (RFP), a novel approach to segmenting objects in 3D during reconstruction given only unlabeled multi-view images of a scene. RFP is derived from emerging neural radiance field-based techniques, which jointly encodes semantics with appearance and geometry. The core of our method is a novel propagation strategy for individual objects' radiance fields with a bidirectional photometric loss, enabling an unsupervised partitioning of a scene into salient or meaningful regions corresponding to different object instances. To better handle complex scenes with multiple objects and occlusions, we further propose an iterative expectation-maximization algorithm to refine object masks. To the best of our knowledge, RFP is the first unsupervised approach for tackling 3D scene object segmentation for neural radiance field (NeRF) without any supervision, annotations, or other cues such as 3D bounding boxes and prior knowledge of object class. Experiments demonstrate that RFP achieves feasible segmentation results that are more accurate than previous unsupervised image/scene segmentation approaches, and are comparable to existing supervised NeRF-based methods. The segmented object representations enable individual 3D object editing operations.
DeViT: Deformed Vision Transformers in Video Inpainting
Sep 28, 2022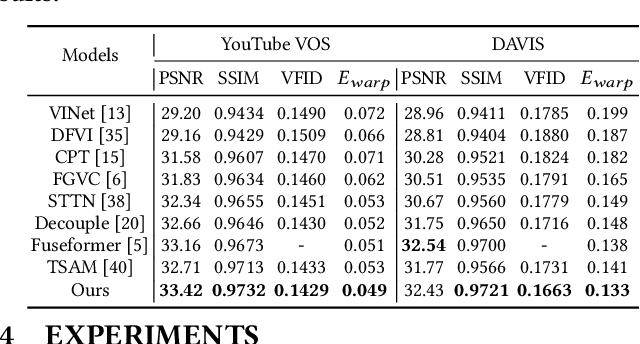
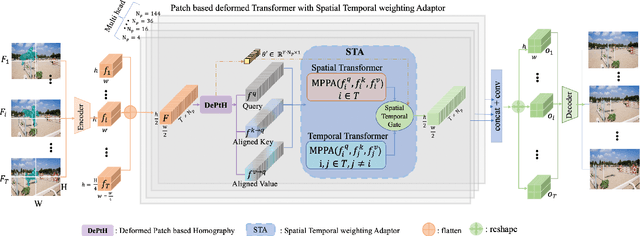
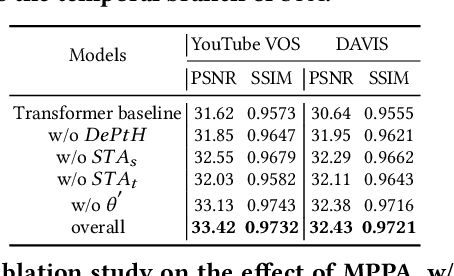
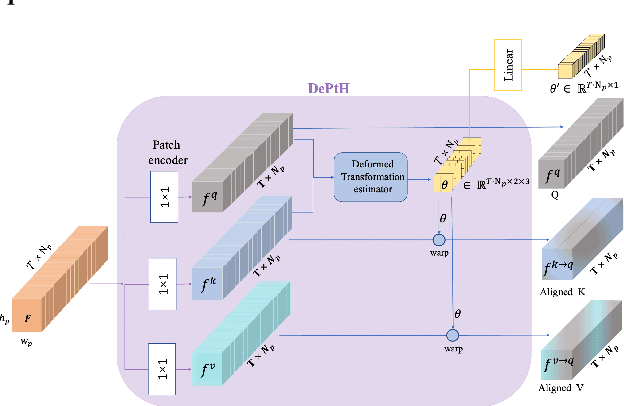
This paper proposes a novel video inpainting method. We make three main contributions: First, we extended previous Transformers with patch alignment by introducing Deformed Patch-based Homography (DePtH), which improves patch-level feature alignments without additional supervision and benefits challenging scenes with various deformation. Second, we introduce Mask Pruning-based Patch Attention (MPPA) to improve patch-wised feature matching by pruning out less essential features and using saliency map. MPPA enhances matching accuracy between warped tokens with invalid pixels. Third, we introduce a Spatial-Temporal weighting Adaptor (STA) module to obtain accurate attention to spatial-temporal tokens under the guidance of the Deformation Factor learned from DePtH, especially for videos with agile motions. Experimental results demonstrate that our method outperforms recent methods qualitatively and quantitatively and achieves a new state-of-the-art.