 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSP-DiffDose: A Conditional Diffusion Model for Radiation Dose Prediction Based on Multi-Scale Fusion of Anatomical Structures, Guided by SwinTransformer and Projector
Dec 11, 2023



Radiation therapy serves as an effective and standard method for cancer treatment. Excellent radiation therapy plans always rely on high-quality dose distribution maps obtained through repeated trial and error by experienced experts. However, due to individual differences and complex clinical situations, even seasoned expert teams may need help to achieve the best treatment plan every time quickly. Many automatic dose distribution prediction methods have been proposed recently to accelerate the radiation therapy planning process and have achieved good results. However, these results suffer from over-smoothing issues, with the obtained dose distribution maps needing more high-frequency details, limiting their clinical application. To address these limitations, we propose a dose prediction diffusion model based on SwinTransformer and a projector, SP-DiffDose. To capture the direct correlation between anatomical structure and dose distribution maps, SP-DiffDose uses a structural encoder to extract features from anatomical images, then employs a conditional diffusion process to blend noise and anatomical images at multiple scales and gradually map them to dose distribution maps. To enhance the dose prediction distribution for organs at risk, SP-DiffDose utilizes SwinTransformer in the deeper layers of the network to capture features at different scales in the image. To learn good representations from the fused features, SP-DiffDose passes the fused features through a designed projector, improving dose prediction accuracy. Finally, we evaluate SP-DiffDose on an internal dataset. The results show that SP-DiffDose outperforms existing methods on multiple evaluation metrics, demonstrating the superiority and generalizability of our method.
HyperLips: Hyper Control Lips with High Resolution Decoder for Talking Face Generation
Oct 15, 2023



Talking face generation has a wide range of potential applications in the field of virtual digital humans. However, rendering high-fidelity facial video while ensuring lip synchronization is still a challenge for existing audio-driven talking face generation approaches. To address this issue, we propose HyperLips, a two-stage framework consisting of a hypernetwork for controlling lips and a high-resolution decoder for rendering high-fidelity faces. In the first stage, we construct a base face generation network that uses the hypernetwork to control the encoding latent code of the visual face information over audio. First, FaceEncoder is used to obtain latent code by extracting features from the visual face information taken from the video source containing the face frame.Then, HyperConv, which weighting parameters are updated by HyperNet with the audio features as input, will modify the latent code to synchronize the lip movement with the audio. Finally, FaceDecoder will decode the modified and synchronized latent code into visual face content. In the second stage, we obtain higher quality face videos through a high-resolution decoder. To further improve the quality of face generation, we trained a high-resolution decoder, HRDecoder, using face images and detected sketches generated from the first stage as input.Extensive quantitative and qualitative experiments show that our method outperforms state-of-the-art work with more realistic, high-fidelity, and lip synchronization. Project page: https://semchan.github.io/HyperLips Project/
Can you text what is happening? Integrating pre-trained language encoders into trajectory prediction models for autonomous driving
Sep 13, 2023In autonomous driving tasks, scene understanding is the first step towards predicting the future behavior of the surrounding traffic participants. Yet, how to represent a given scene and extract its features are still open research questions. In this study, we propose a novel text-based representation of traffic scenes and process it with a pre-trained language encoder. First, we show that text-based representations, combined with classical rasterized image representations, lead to descriptive scene embeddings. Second, we benchmark our predictions on the nuScenes dataset and show significant improvements compared to baselines. Third, we show in an ablation study that a joint encoder of text and rasterized images outperforms the individual encoders confirming that both representations have their complementary strengths.
Energy-Guided Diffusion Model for CBCT-to-CT Synthesis
Aug 07, 2023Cone Beam CT (CBCT) plays a crucial role in Adaptive Radiation Therapy (ART) by accurately providing radiation treatment when organ anatomy changes occur. However, CBCT images suffer from scatter noise and artifacts, making relying solely on CBCT for precise dose calculation and accurate tissue localization challenging. Therefore, there is a need to improve CBCT image quality and Hounsfield Unit (HU) accuracy while preserving anatomical structures. To enhance the role and application value of CBCT in ART, we propose an energy-guided diffusion model (EGDiff) and conduct experiments on a chest tumor dataset to generate synthetic CT (sCT) from CBCT. The experimental results demonstrate impressive performance with an average absolute error of 26.87$\pm$6.14 HU, a structural similarity index measurement of 0.850$\pm$0.03, a peak signal-to-noise ratio of the sCT of 19.83$\pm$1.39 dB, and a normalized cross-correlation of the sCT of 0.874$\pm$0.04. These results indicate that our method outperforms state-of-the-art unsupervised synthesis methods in accuracy and visual quality, producing superior sCT images.
PNT-Edge: Towards Robust Edge Detection with Noisy Labels by Learning Pixel-level Noise Transitions
Jul 26, 2023Relying on large-scale training data with pixel-level labels, previous edge detection methods have achieved high performance. However, it is hard to manually label edges accurately, especially for large datasets, and thus the datasets inevitably contain noisy labels. This label-noise issue has been studied extensively for classification, while still remaining under-explored for edge detection. To address the label-noise issue for edge detection, this paper proposes to learn Pixel-level NoiseTransitions to model the label-corruption process. To achieve it, we develop a novel Pixel-wise Shift Learning (PSL) module to estimate the transition from clean to noisy labels as a displacement field. Exploiting the estimated noise transitions, our model, named PNT-Edge, is able to fit the prediction to clean labels. In addition, a local edge density regularization term is devised to exploit local structure information for better transition learning. This term encourages learning large shifts for the edges with complex local structures. Experiments on SBD and Cityscapes demonstrate the effectiveness of our method in relieving the impact of label noise. Codes will be available at github.
Towards Safe Propofol Dosing during General Anesthesia Using Deep Offline Reinforcement Learning
Mar 17, 2023



Automated anesthesia promises to enable more precise and personalized anesthetic administration and free anesthesiologists from repetitive tasks, allowing them to focus on the most critical aspects of a patient's surgical care. Current research has typically focused on creating simulated environments from which agents can learn. These approaches have demonstrated good experimental results, but are still far from clinical application. In this paper, Policy Constraint Q-Learning (PCQL), a data-driven reinforcement learning algorithm for solving the problem of learning anesthesia strategies on real clinical datasets, is proposed. Conservative Q-Learning was first introduced to alleviate the problem of Q function overestimation in an offline context. A policy constraint term is added to agent training to keep the policy distribution of the agent and the anesthesiologist consistent to ensure safer decisions made by the agent in anesthesia scenarios. The effectiveness of PCQL was validated by extensive experiments on a real clinical anesthesia dataset. Experimental results show that PCQL is predicted to achieve higher gains than the baseline approach while maintaining good agreement with the reference dose given by the anesthesiologist, using less total dose, and being more responsive to the patient's vital signs. In addition, the confidence intervals of the agent were investigated, which were able to cover most of the clinical decisions of the anesthesiologist. Finally, an interpretable method, SHAP, was used to analyze the contributing components of the model predictions to increase the transparency of the model.
Constraining Multi-scale Pairwise Features between Encoder and Decoder Using Contrastive Learning for Unpaired Image-to-Image Translation
Nov 20, 2022Contrastive learning (CL) has shown great potential in image-to-image translation (I2I). Current CL-based I2I methods usually re-exploit the encoder of the generator to maximize the mutual information between the input and generated images, which does not exert an active effect on the decoder part. In addition, though negative samples play a crucial role in CL, most existing methods adopt a random sampling strategy, which may be less effective. In this paper, we rethink the CL paradigm in the unpaired I2I tasks from two perspectives and propose a new one-sided image translation framework called EnCo. First, we present an explicit constraint on the multi-scale pairwise features between the encoder and decoder of the generator to guarantee the semantic consistency of the input and generated images. Second, we propose a discriminative attention-guided negative sampling strategy to replace the random negative sampling, which significantly improves the performance of the generative model with an almost negligible computational overhead. Compared with existing methods, EnCo acts more effective and efficient. Extensive experiments on several popular I2I datasets demonstrate the effectiveness and advantages of our proposed approach, and we achieve several state-of-the-art compared to previous methods.
KD-EKF: A Kalman Decomposition Based Extended Kalman Filter for Multi-Robot Cooperative Localization
Oct 28, 2022



This paper investigates the consistency problem of EKF-based cooperative localization (CL) from the perspective of Kalman decomposition, which decomposes the observable and unobservable states and allows treating them individually. The factors causing the dimension reduction of the unobservable subspace, termed error discrepancy items, are explicitly isolated and identified in the state propagation and measurement Jacobians for the first time. We prove that the error discrepancy items lead to the global orientation being erroneously observable, which in turn causes the state estimation to be inconsistent. A CL algorithm, called Kalman decomposition-based EKF (KD-EKF), is proposed to improve consistency. The key idea is to perform state estimation using the Kalman observable canonical form in the transformed coordinates. By annihilating the error discrepancy items, proper observability properties are guaranteed. More importantly, the modified state propagation and measurement Jacobians are exactly equivalent to linearizing the nonlinear CL system at current best state estimates. Consequently, the inconsistency caused by the erroneous dimension reduction of the unobservable subspace is completely eliminated. The KD-EKF CL algorithm has been extensively verified in both Monte Carlo simulations and real-world experiments and shown to achieve better performance than state-of-the-art algorithms in terms of accuracy and consistency.
A Many-ported and Shared Memory Architecture for High-Performance ADAS SoCs
Sep 13, 2022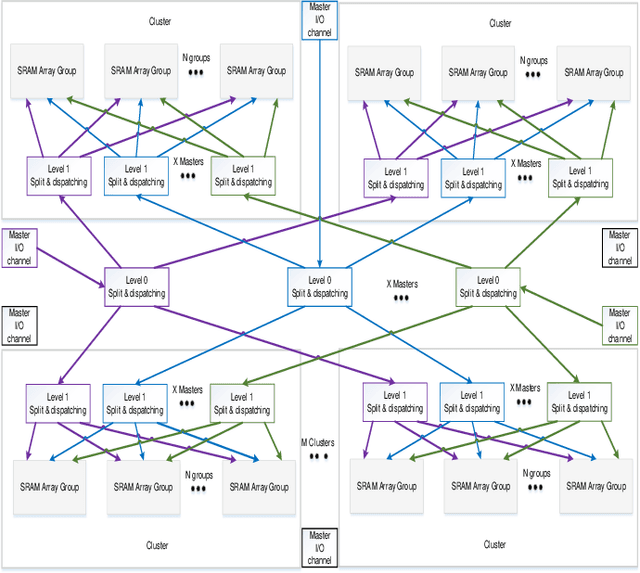
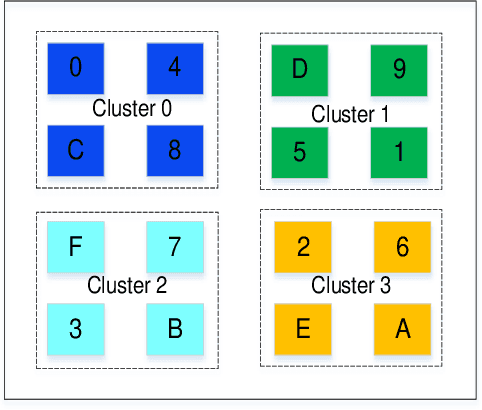
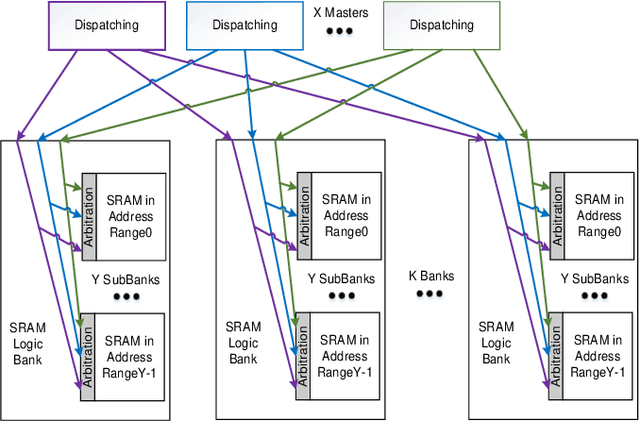
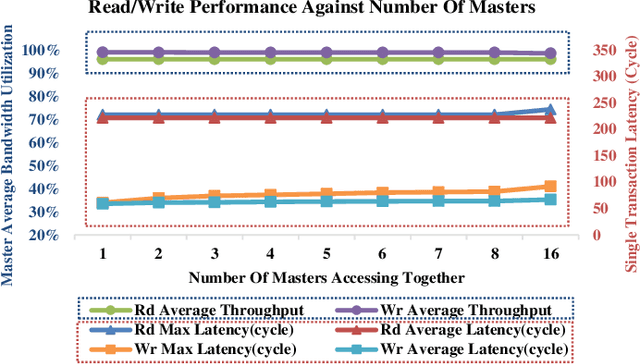
Increasing investment in computing technologies and the advancements in silicon technology has fueled rapid growth in advanced driver assistance systems (ADAS) and corresponding SoC developments. An ADAS SoC represents a heterogeneous architecture that consists of CPUs, GPUs and artificial intelligence (AI) accelerators. In order to guarantee its safety and reliability, it must process massive amount of raw data collected from multiple redundant sources such as high-definition video cameras, Radars, and Lidars to recognize objects correctly and to make the right decisions promptly. A domain specific memory architecture is essential to achieve the above goals. We present a shared memory architecture that enables high data throughput among multiple parallel accesses native to the ADAS applications. It also provides deterministic access latency with proper isolation under the stringent real-time QoS constraints. A prototype is built and analyzed. The results validate that the proposed architecture provides close to 100\% throughput for both read and write accesses generated simultaneously by many accessing masters with full injection rate. It can also provide consistent QoS to the domain specific payloads while enabling the scalability and modularity of the design.
Multi-scale Cooperative Multimodal Transformers for Multimodal Sentiment Analysis in Videos
Jun 17, 2022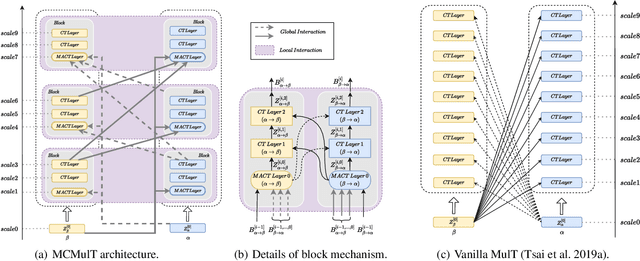
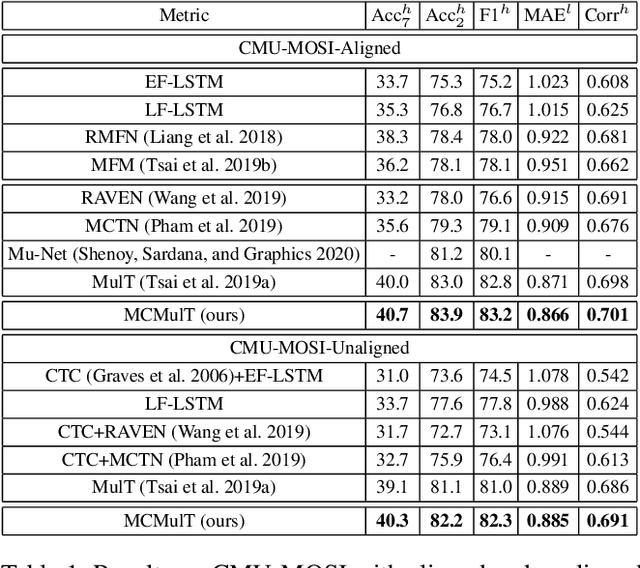
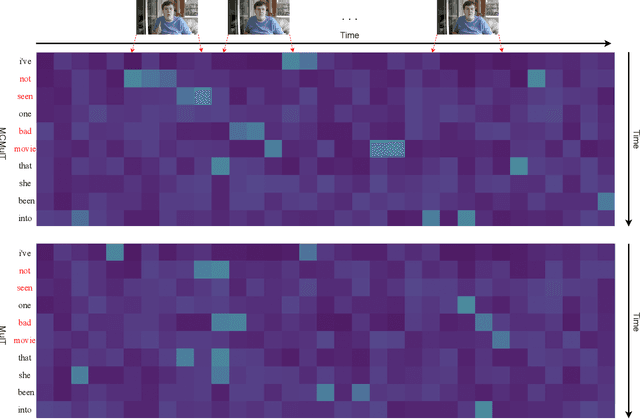
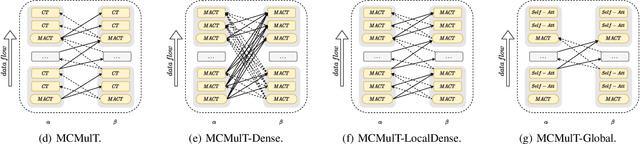
Multimodal sentiment analysis in videos is a key task in many real-world applications, which usually requires integrating multimodal streams including visual, verbal and acoustic behaviors. To improve the robustness of multimodal fusion, some of the existing methods let different modalities communicate with each other and modal the crossmodal interaction via transformers. However, these methods only use the single-scale representations during the interaction but forget to exploit multi-scale representations that contain different levels of semantic information. As a result, the representations learned by transformers could be biased especially for unaligned multimodal data. In this paper, we propose a multi-scale cooperative multimodal transformer (MCMulT) architecture for multimodal sentiment analysis. On the whole, the "multi-scale" mechanism is capable of exploiting the different levels of semantic information of each modality which are used for fine-grained crossmodal interactions. Meanwhile, each modality learns its feature hierarchies via integrating the crossmodal interactions from multiple level features of its source modality. In this way, each pair of modalities progressively builds feature hierarchies respectively in a cooperative manner. The empirical results illustrate that our MCMulT model not only outperforms existing approaches on unaligned multimodal sequences but also has strong performance on aligned multimodal sequences.