 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubFlow: Sub-mode Conditioned Flow Matching for Diverse One-Step Generation
Apr 14, 2026Flow matching has emerged as a powerful generative framework, with recent few-step methods achieving remarkable inference acceleration. However, we identify a critical yet overlooked limitation: these models suffer from severe diversity degradation, concentrating samples on dominant modes while neglecting rare but valid variations of the target distribution. We trace this degradation to averaging distortion: when trained with MSE objectives, class-conditional flows learn a frequency-weighted mean over intra-class sub-modes, causing the model to over-represent high-density modes while systematically neglecting low-density ones. To address this, we propose SubFlow, Sub-mode Conditioned Flow Matching, which eliminates averaging distortion by decomposing each class into fine-grained sub-modes via semantic clustering and conditioning the flow on sub-mode indices. Each conditioned sub-distribution is approximately unimodal, so the learned flow accurately targets individual modes with no averaging distortion, restoring full mode coverage in a single inference step. Crucially, SubFlow is entirely plug-and-play: it integrates seamlessly into existing one-step models such as MeanFlow and Shortcut Models without any architectural modifications. Extensive experiments on ImageNet-256 demonstrate that SubFlow yields substantial gains in generation diversity (Recall) while maintaining competitive image quality (FID), confirming its broad applicability across different one-step generation frameworks. Project page: https://yexionglin.github.io/subflow.
Beyond Optimal Transport: Model-Aligned Coupling for Flow Matching
May 29, 2025Flow Matching (FM) is an effective framework for training a model to learn a vector field that transports samples from a source distribution to a target distribution. To train the model, early FM methods use random couplings, which often result in crossing paths and lead the model to learn non-straight trajectories that require many integration steps to generate high-quality samples. To address this, recent methods adopt Optimal Transport (OT) to construct couplings by minimizing geometric distances, which helps reduce path crossings. However, we observe that such geometry-based couplings do not necessarily align with the model's preferred trajectories, making it difficult to learn the vector field induced by these couplings, which prevents the model from learning straight trajectories. Motivated by this, we propose Model-Aligned Coupling (MAC), an effective method that matches training couplings based not only on geometric distance but also on alignment with the model's preferred transport directions based on its prediction error. To avoid the time-costly match process, MAC proposes to select the top-$k$ fraction of couplings with the lowest error for training. Extensive experiments show that MAC significantly improves generation quality and efficiency in few-step settings compared to existing methods. Project page: https://yexionglin.github.io/mac
Do We Need to Penalize Variance of Losses for Learning with Label Noise?
Jan 30, 2022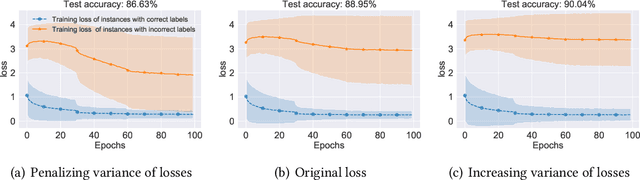
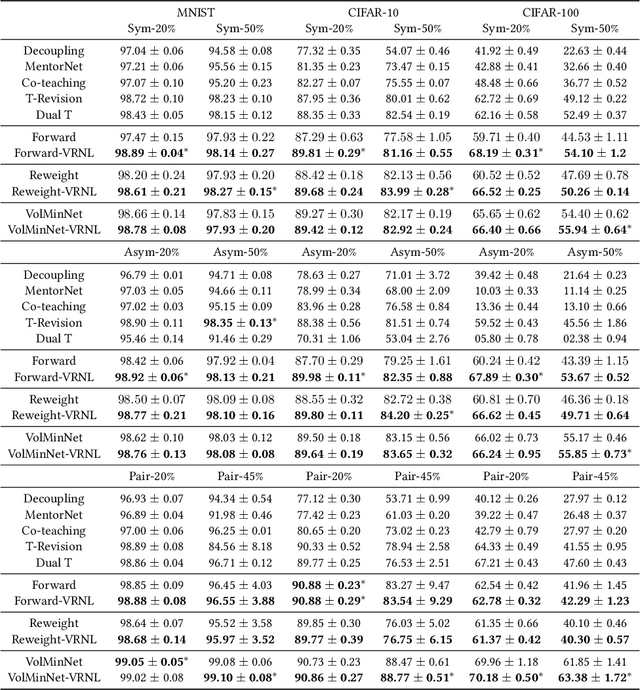
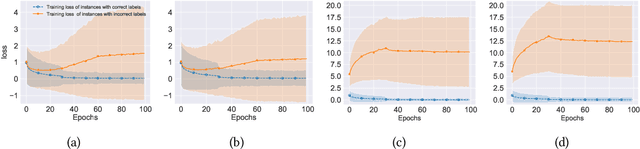

Algorithms which minimize the averaged loss have been widely designed for dealing with noisy labels. Intuitively, when there is a finite training sample, penalizing the variance of losses will improve the stability and generalization of the algorithms. Interestingly, we found that the variance should be increased for the problem of learning with noisy labels. Specifically, increasing the variance will boost the memorization effects and reduce the harmfulness of incorrect labels. By exploiting the label noise transition matrix, regularizers can be easily designed to reduce the variance of losses and be plugged in many existing algorithms. Empirically, the proposed method by increasing the variance of losses significantly improves the generalization ability of baselines on both synthetic and real-world datasets.