 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMandarin Singing Voice Synthesis with Denoising Diffusion Probabilistic Wasserstein GAN
Sep 21, 2022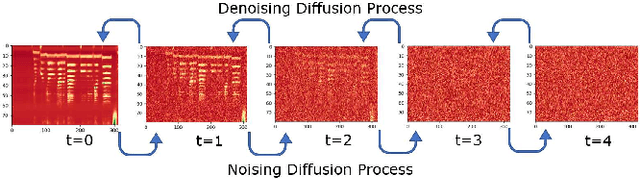

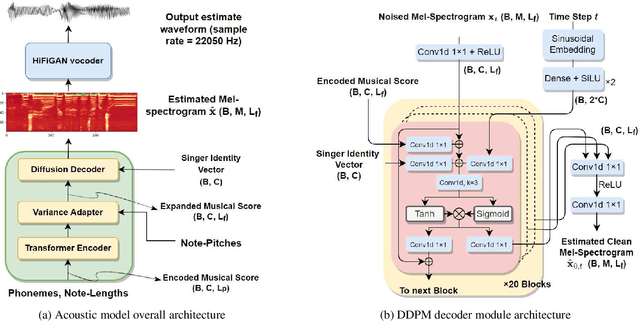
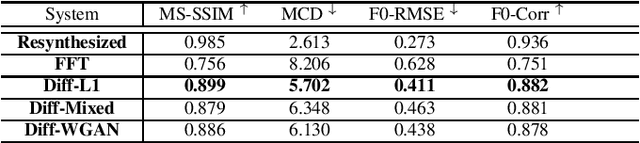
Singing voice synthesis (SVS) is the computer production of a human-like singing voice from given musical scores. To accomplish end-to-end SVS effectively and efficiently, this work adopts the acoustic model-neural vocoder architecture established for high-quality speech and singing voice synthesis. Specifically, this work aims to pursue a higher level of expressiveness in synthesized voices by combining the diffusion denoising probabilistic model (DDPM) and \emph{Wasserstein} generative adversarial network (WGAN) to construct the backbone of the acoustic model. On top of the proposed acoustic model, a HiFi-GAN neural vocoder is adopted with integrated fine-tuning to ensure optimal synthesis quality for the resulting end-to-end SVS system. This end-to-end system was evaluated with the multi-singer Mpop600 Mandarin singing voice dataset. In the experiments, the proposed system exhibits improvements over previous landmark counterparts in terms of musical expressiveness and high-frequency acoustic details. Moreover, the adversarial acoustic model converged stably without the need to enforce reconstruction objectives, indicating the convergence stability of the proposed DDPM and WGAN combined architecture over alternative GAN-based SVS systems.
ESPnet-SE++: Speech Enhancement for Robust Speech Recognition, Translation, and Understanding
Jul 19, 2022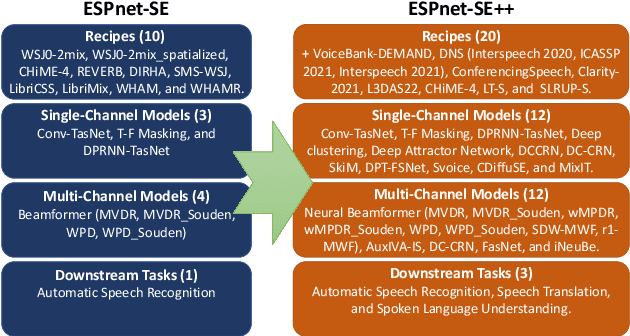
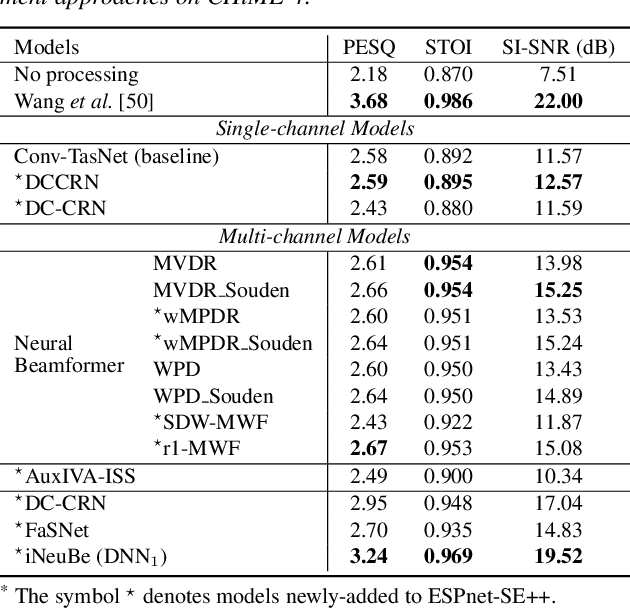
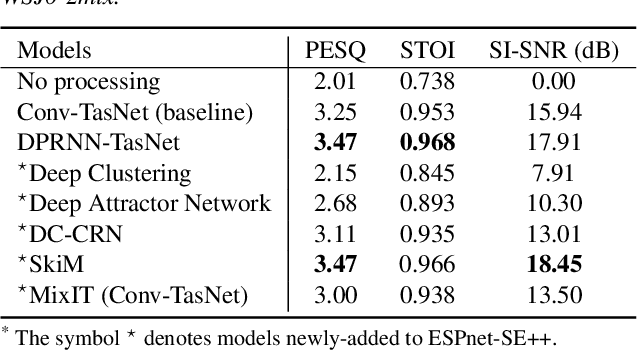
This paper presents recent progress on integrating speech separation and enhancement (SSE) into the ESPnet toolkit. Compared with the previous ESPnet-SE work, numerous features have been added, including recent state-of-the-art speech enhancement models with their respective training and evaluation recipes. Importantly, a new interface has been designed to flexibly combine speech enhancement front-ends with other tasks, including automatic speech recognition (ASR), speech translation (ST), and spoken language understanding (SLU). To showcase such integration, we performed experiments on carefully designed synthetic datasets for noisy-reverberant multi-channel ST and SLU tasks, which can be used as benchmark corpora for future research. In addition to these new tasks, we also use CHiME-4 and WSJ0-2Mix to benchmark multi- and single-channel SE approaches. Results show that the integration of SE front-ends with back-end tasks is a promising research direction even for tasks besides ASR, especially in the multi-channel scenario. The code is available online at https://github.com/ESPnet/ESPnet. The multi-channel ST and SLU datasets, which are another contribution of this work, are released on HuggingFace.
NASTAR: Noise Adaptive Speech Enhancement with Target-Conditional Resampling
Jun 18, 2022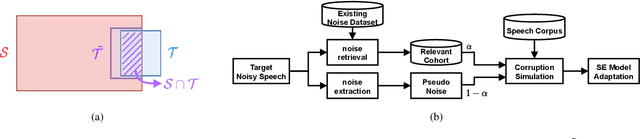
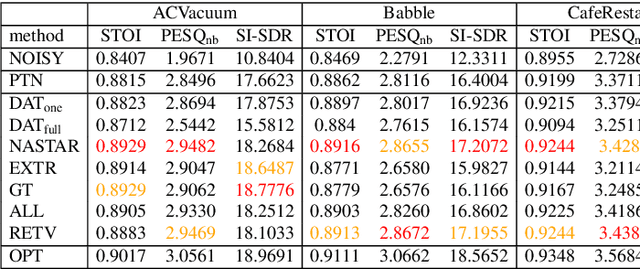
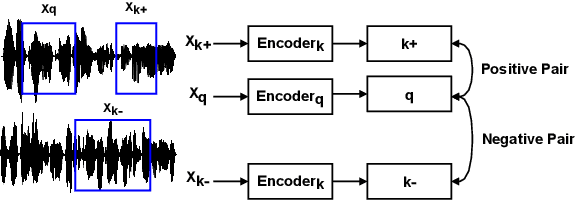
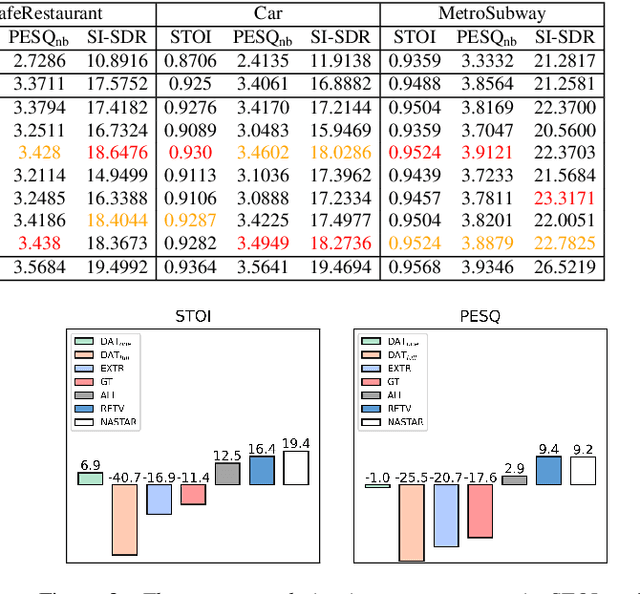
For deep learning-based speech enhancement (SE) systems, the training-test acoustic mismatch can cause notable performance degradation. To address the mismatch issue, numerous noise adaptation strategies have been derived. In this paper, we propose a novel method, called noise adaptive speech enhancement with target-conditional resampling (NASTAR), which reduces mismatches with only one sample (one-shot) of noisy speech in the target environment. NASTAR uses a feedback mechanism to simulate adaptive training data via a noise extractor and a retrieval model. The noise extractor estimates the target noise from the noisy speech, called pseudo-noise. The noise retrieval model retrieves relevant noise samples from a pool of noise signals according to the noisy speech, called relevant-cohort. The pseudo-noise and the relevant-cohort set are jointly sampled and mixed with the source speech corpus to prepare simulated training data for noise adaptation. Experimental results show that NASTAR can effectively use one noisy speech sample to adapt an SE model to a target condition. Moreover, both the noise extractor and the noise retrieval model contribute to model adaptation. To our best knowledge, NASTAR is the first work to perform one-shot noise adaptation through noise extraction and retrieval.
EPG2S: Speech Generation and Speech Enhancement based on Electropalatography and Audio Signals using Multimodal Learning
Jun 16, 2022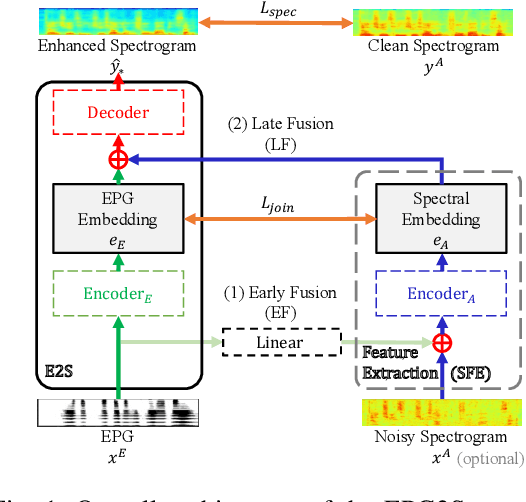
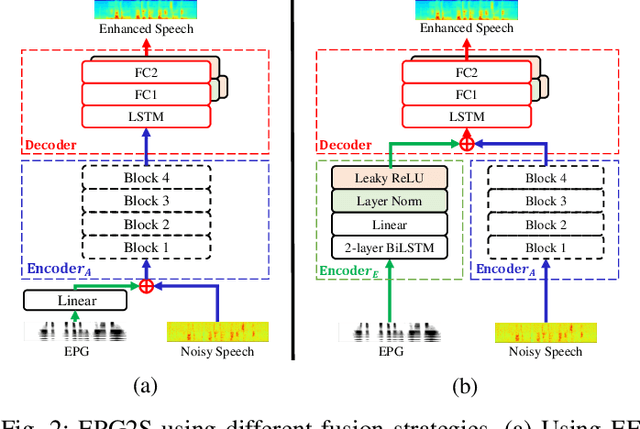
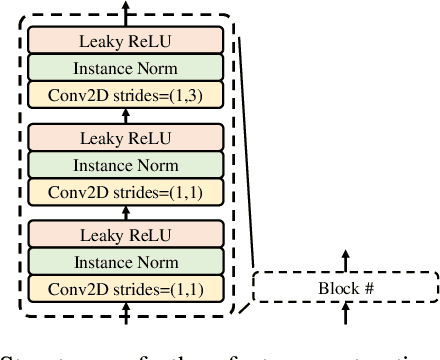
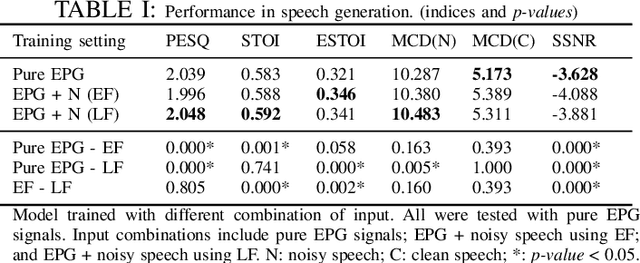
Speech generation and enhancement based on articulatory movements facilitate communication when the scope of verbal communication is absent, e.g., in patients who have lost the ability to speak. Although various techniques have been proposed to this end, electropalatography (EPG), which is a monitoring technique that records contact between the tongue and hard palate during speech, has not been adequately explored. Herein, we propose a novel multimodal EPG-to-speech (EPG2S) system that utilizes EPG and speech signals for speech generation and enhancement. Different fusion strategies based on multiple combinations of EPG and noisy speech signals are examined, and the viability of the proposed method is investigated. Experimental results indicate that EPG2S achieves desirable speech generation outcomes based solely on EPG signals. Further, the addition of noisy speech signals is observed to improve quality and intelligibility. Additionally, EPG2S is observed to achieve high-quality speech enhancement based solely on audio signals, with the addition of EPG signals further improving the performance. The late fusion strategy is deemed to be the most effective approach for simultaneous speech generation and enhancement.
XDBERT: Distilling Visual Information to BERT from Cross-Modal Systems to Improve Language Understanding
Apr 29, 2022
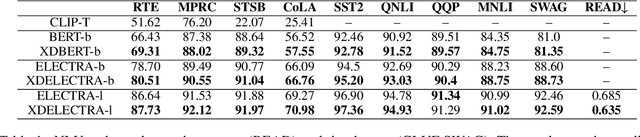
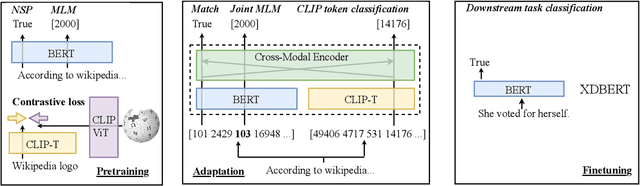

Transformer-based models are widely used in natural language understanding (NLU) tasks, and multimodal transformers have been effective in visual-language tasks. This study explores distilling visual information from pretrained multimodal transformers to pretrained language encoders. Our framework is inspired by cross-modal encoders' success in visual-language tasks while we alter the learning objective to cater to the language-heavy characteristics of NLU. After training with a small number of extra adapting steps and finetuned, the proposed XDBERT (cross-modal distilled BERT) outperforms pretrained-BERT in general language understanding evaluation (GLUE), situations with adversarial generations (SWAG) benchmarks, and readability benchmarks. We analyze the performance of XDBERT on GLUE to show that the improvement is likely visually grounded.
A Study of Using Cepstrogram for Countermeasure Against Replay Attacks
Apr 09, 2022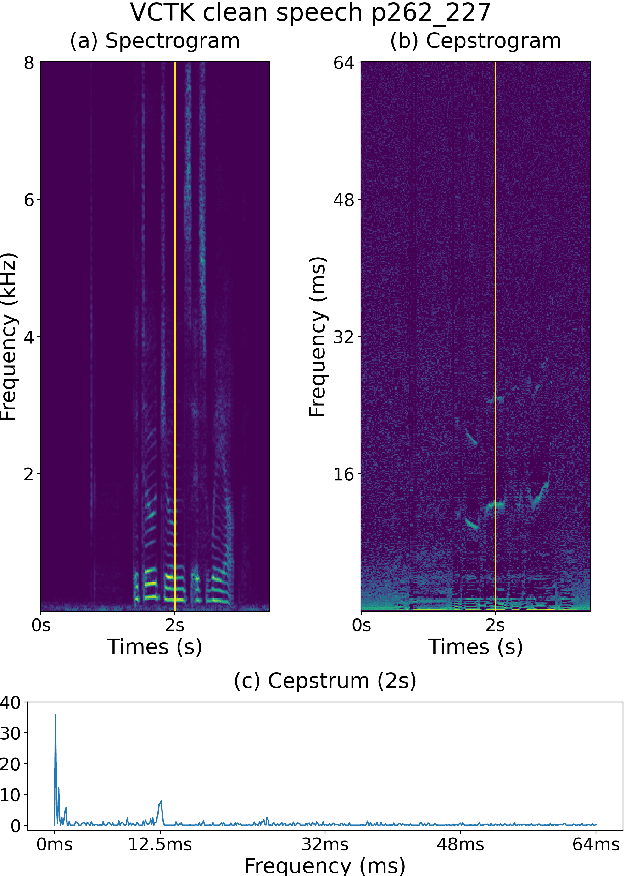
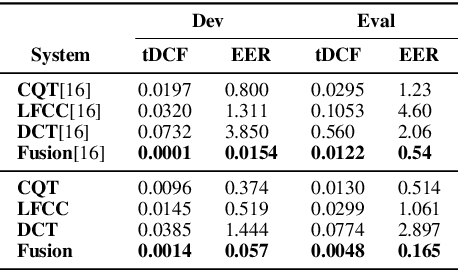
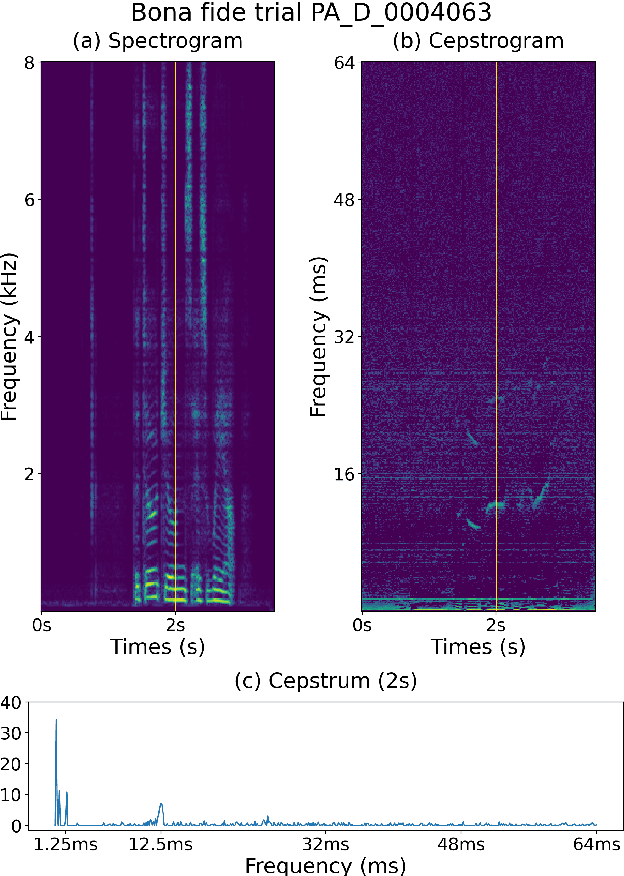
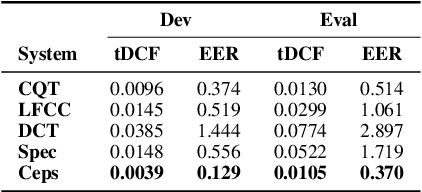
In this paper, we investigate the properties of the cepstrogram and demonstrate its effectiveness as a powerful feature for countermeasure against replay attacks. Cepstrum analysis of replay attacks suggests that crucial information for anti-spoofing against replay attacks may retain in the cepstrogram. Experimental results on the ASVspoof 2019 physical access (PA) database demonstrate that, compared with other features, the cepstrogram dominates in both single and fusion systems when building countermeasures against replay attacks. Our LCNN-based single and fusion systems with the cepstrogram feature outperform the corresponding LCNN-based systems without using the cepstrogram feature and several state-of-the-art (SOTA) single and fusion systems in the literature.
Boosting Self-Supervised Embeddings for Speech Enhancement
Apr 07, 2022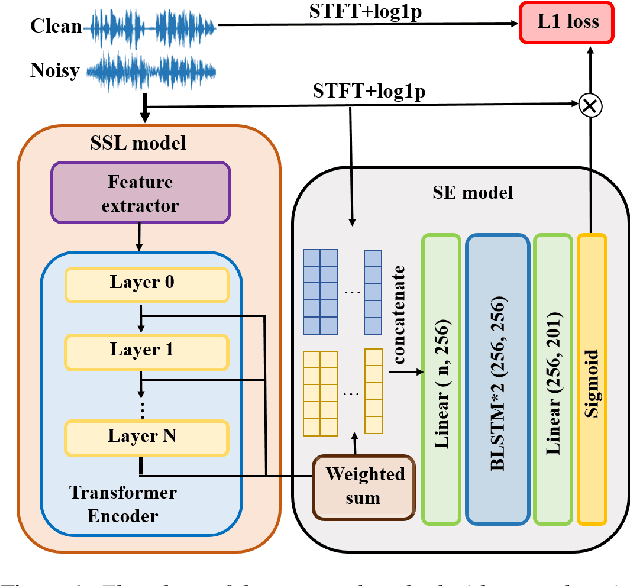
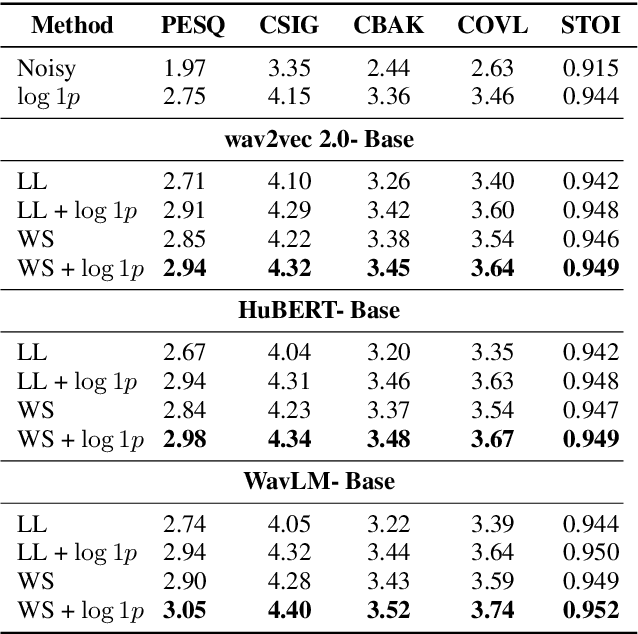
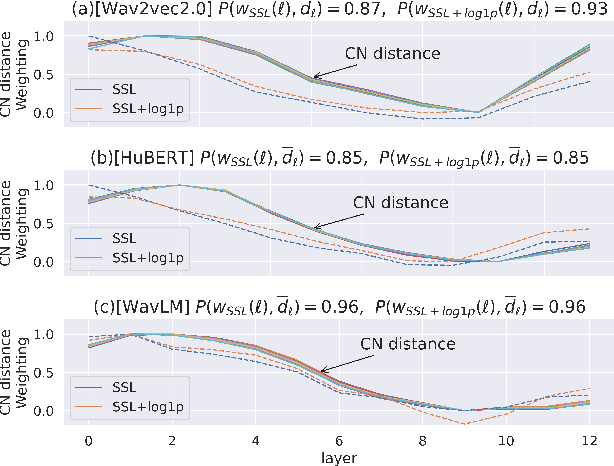
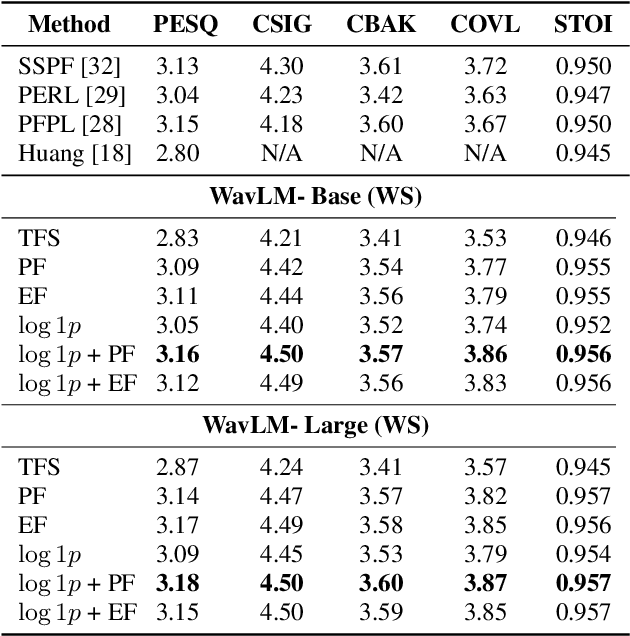
Self-supervised learning (SSL) representation for speech has achieved state-of-the-art (SOTA) performance on several downstream tasks. However, there remains room for improvement in speech enhancement (SE) tasks. In this study, we used a cross-domain feature to solve the problem that SSL embeddings may lack fine-grained information to regenerate speech signals. By integrating the SSL representation and spectrogram, the result can be significantly boosted. We further study the relationship between the noise robustness of SSL representation via clean-noisy distance (CN distance) and the layer importance for SE. Consequently, we found that SSL representations with lower noise robustness are more important. Furthermore, our experiments on the VCTK-DEMAND dataset demonstrated that fine-tuning an SSL representation with an SE model can outperform the SOTA SSL-based SE methods in PESQ, CSIG and COVL without invoking complicated network architectures. In later experiments, the CN distance in SSL embeddings was observed to increase after fine-tuning. These results verify our expectations and may help design SE-related SSL training in the future.
MTI-Net: A Multi-Target Speech Intelligibility Prediction Model
Apr 07, 2022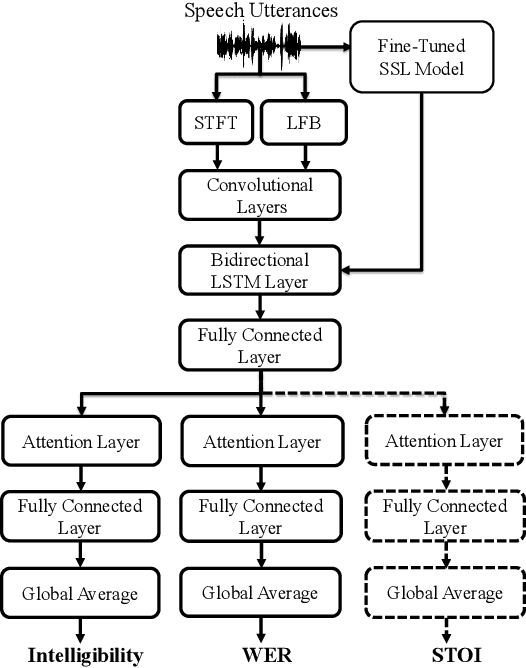
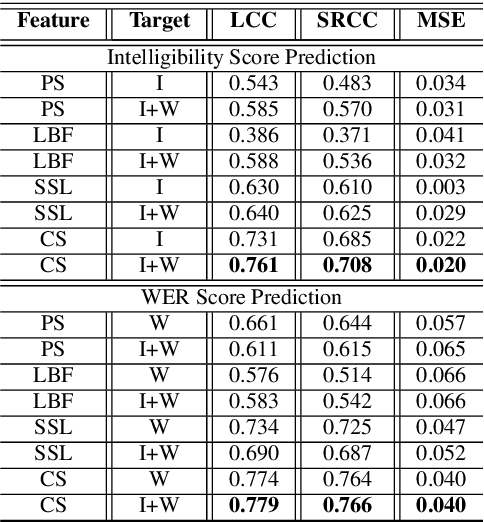
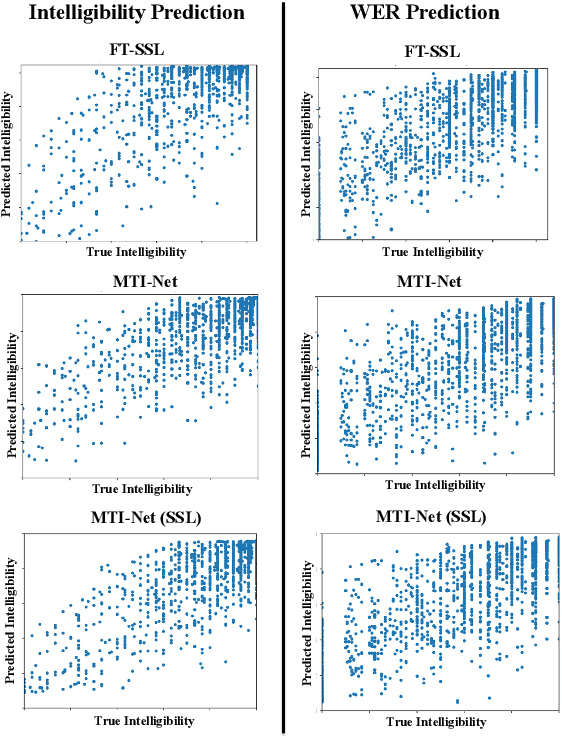
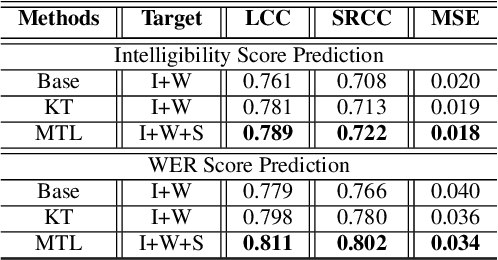
Recently, deep learning (DL)-based non-intrusive speech assessment models have attracted great attention. Many studies report that these DL-based models yield satisfactory assessment performance and good flexibility, but their performance in unseen environments remains a challenge. Furthermore, compared to quality scores, fewer studies elaborate deep learning models to estimate intelligibility scores. This study proposes a multi-task speech intelligibility prediction model, called MTI-Net, for simultaneously predicting human and machine intelligibility measures. Specifically, given a speech utterance, MTI-Net is designed to predict subjective listening test results and word error rate (WER) scores. We also investigate several methods that can improve the prediction performance of MTI-Net. First, we compare different features (including low-level features and embeddings from self-supervised learning (SSL) models) and prediction targets of MTI-Net. Second, we explore the effect of transfer learning and multi-tasking learning on training MTI-Net. Finally, we examine the potential advantages of fine-tuning SSL embeddings. Experimental results demonstrate the effectiveness of using cross-domain features, multi-task learning, and fine-tuning SSL embeddings. Furthermore, it is confirmed that the intelligibility and WER scores predicted by MTI-Net are highly correlated with the ground-truth scores.
MBI-Net: A Non-Intrusive Multi-Branched Speech Intelligibility Prediction Model for Hearing Aids
Apr 07, 2022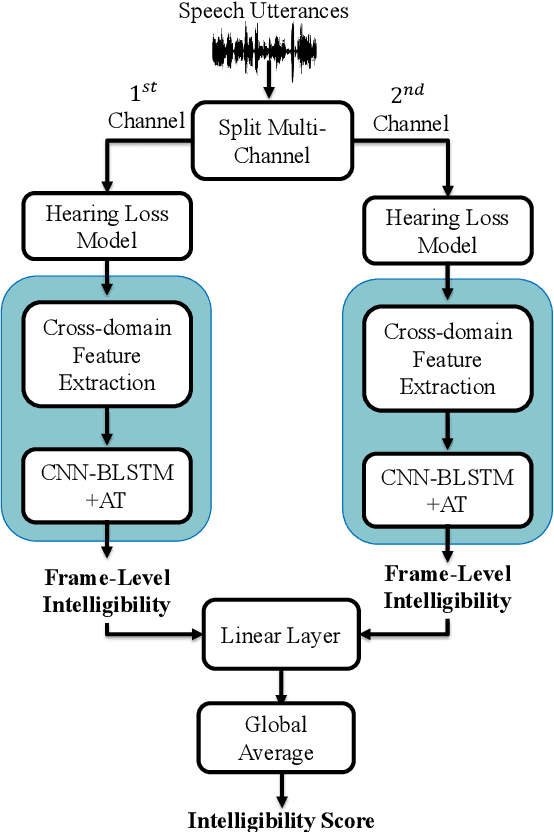
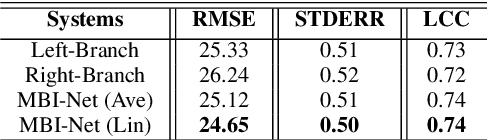
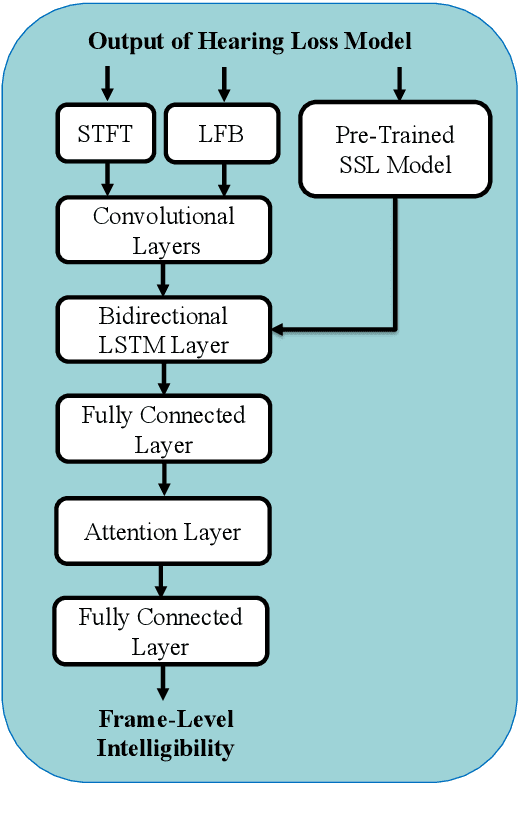
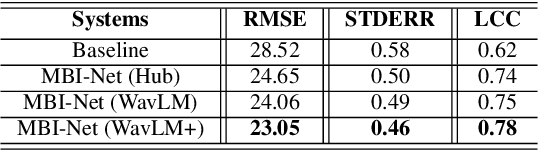
Improving the user's hearing ability to understand speech in noisy environments is critical to the development of hearing aid (HA) devices. For this, it is important to derive a metric that can fairly predict speech intelligibility for HA users. A straightforward approach is to conduct a subjective listening test and use the test results as an evaluation metric. However, conducting large-scale listening tests is time-consuming and expensive. Therefore, several evaluation metrics were derived as surrogates for subjective listening test results. In this study, we propose a multi-branched speech intelligibility prediction model (MBI-Net), for predicting the subjective intelligibility scores of HA users. MBI-Net consists of two branches of models, with each branch consisting of a hearing loss model, a cross-domain feature extraction module, and a speech intelligibility prediction model, to process speech signals from one channel. The outputs of the two branches are fused through a linear layer to obtain predicted speech intelligibility scores. Experimental results confirm the effectiveness of MBI-Net, which produces higher prediction scores than the baseline system in Track 1 and Track 2 on the Clarity Prediction Challenge 2022 dataset.
Perceptual Contrast Stretching on Target Feature for Speech Enhancement
Apr 01, 2022
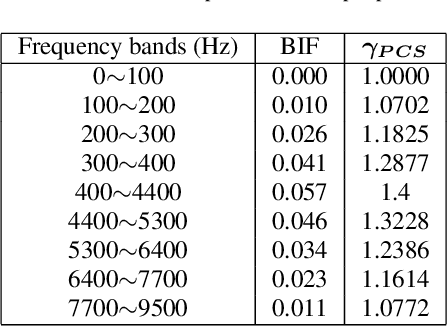
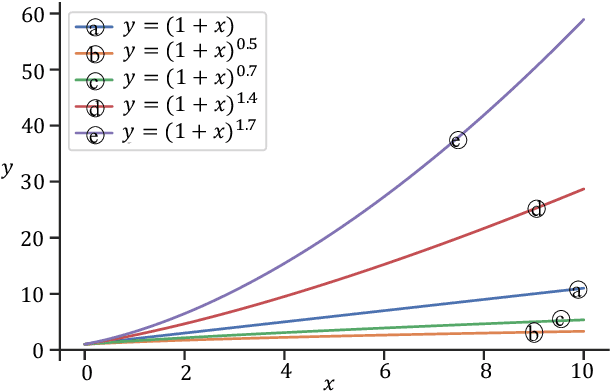
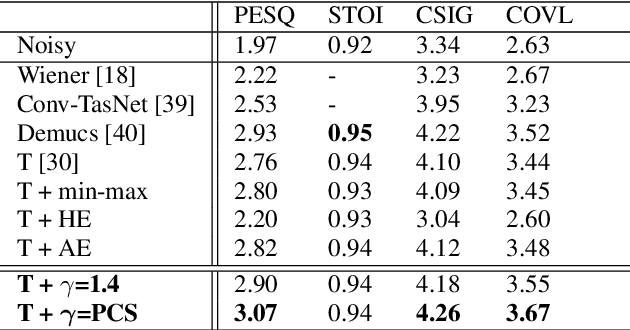
Speech enhancement (SE) performance has improved considerably since the use of deep learning (DL) models as a base function. In this study, we propose a perceptual contrast stretching (PCS) approach to further improve SE performance. PCS is derived based on the critical band importance function and applied to modify the targets of the SE model. Specifically, PCS stretches the contract of target features according to perceptual importance, thereby improving the overall SE performance. Compared to post-processing based implementations, incorporating PCS into the training phase preserves performance and reduces online computation. It is also worth noting that PCS can be suitably combined with different SE model architectures and training criteria. Meanwhile, PCS does not affect the causality or convergence of the SE model training. Experimental results on the VoiceBank-DEMAND dataset showed that the proposed method can achieve state-of-the-art performance on both causal (PESQ=3.07) and non-causal (PESQ=3.35) SE tasks.