 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Metadata on Scientific Literature Tagging: A Cross-Field Cross-Model Study
Feb 07, 2023Due to the exponential growth of scientific publications on the Web, there is a pressing need to tag each paper with fine-grained topics so that researchers can track their interested fields of study rather than drowning in the whole literature. Scientific literature tagging is beyond a pure multi-label text classification task because papers on the Web are prevalently accompanied by metadata information such as venues, authors, and references, which may serve as additional signals to infer relevant tags. Although there have been studies making use of metadata in academic paper classification, their focus is often restricted to one or two scientific fields (e.g., computer science and biomedicine) and to one specific model. In this work, we systematically study the effect of metadata on scientific literature tagging across 19 fields. We select three representative multi-label classifiers (i.e., a bag-of-words model, a sequence-based model, and a pre-trained language model) and explore their performance change in scientific literature tagging when metadata are fed to the classifiers as additional features. We observe some ubiquitous patterns of metadata's effects across all fields (e.g., venues are consistently beneficial to paper tagging in almost all cases), as well as some unique patterns in fields other than computer science and biomedicine, which are not explored in previous studies.
Representation Deficiency in Masked Language Modeling
Feb 04, 2023



Masked Language Modeling (MLM) has been one of the most prominent approaches for pretraining bidirectional text encoders due to its simplicity and effectiveness. One notable concern about MLM is that the special $\texttt{[MASK]}$ symbol causes a discrepancy between pretraining data and downstream data as it is present only in pretraining but not in fine-tuning. In this work, we offer a new perspective on the consequence of such a discrepancy: We demonstrate empirically and theoretically that MLM pretraining allocates some model dimensions exclusively for representing $\texttt{[MASK]}$ tokens, resulting in a representation deficiency for real tokens and limiting the pretrained model's expressiveness when it is adapted to downstream data without $\texttt{[MASK]}$ tokens. Motivated by the identified issue, we propose MAE-LM, which pretrains the Masked Autoencoder architecture with MLM where $\texttt{[MASK]}$ tokens are excluded from the encoder. Empirically, we show that MAE-LM improves the utilization of model dimensions for real token representations, and MAE-LM consistently outperforms MLM-pretrained models across different pretraining settings and model sizes when fine-tuned on the GLUE and SQuAD benchmarks.
Effective Seed-Guided Topic Discovery by Integrating Multiple Types of Contexts
Dec 12, 2022Instead of mining coherent topics from a given text corpus in a completely unsupervised manner, seed-guided topic discovery methods leverage user-provided seed words to extract distinctive and coherent topics so that the mined topics can better cater to the user's interest. To model the semantic correlation between words and seeds for discovering topic-indicative terms, existing seed-guided approaches utilize different types of context signals, such as document-level word co-occurrences, sliding window-based local contexts, and generic linguistic knowledge brought by pre-trained language models. In this work, we analyze and show empirically that each type of context information has its value and limitation in modeling word semantics under seed guidance, but combining three types of contexts (i.e., word embeddings learned from local contexts, pre-trained language model representations obtained from general-domain training, and topic-indicative sentences retrieved based on seed information) allows them to complement each other for discovering quality topics. We propose an iterative framework, SeedTopicMine, which jointly learns from the three types of contexts and gradually fuses their context signals via an ensemble ranking process. Under various sets of seeds and on multiple datasets, SeedTopicMine consistently yields more coherent and accurate topics than existing seed-guided topic discovery approaches.
Tuning Language Models as Training Data Generators for Augmentation-Enhanced Few-Shot Learning
Nov 06, 2022Recent studies have revealed the intriguing few-shot learning ability of pretrained language models (PLMs): They can quickly adapt to a new task when fine-tuned on a small amount of labeled data formulated as prompts, without requiring abundant task-specific annotations. Despite their promising performance, most existing few-shot approaches that only learn from the small training set still underperform fully supervised training by nontrivial margins. In this work, we study few-shot learning with PLMs from a different perspective: We first tune an autoregressive PLM on the few-shot samples and then use it as a generator to synthesize a large amount of novel training samples which augment the original training set. To encourage the generator to produce label-discriminative samples, we train it via weighted maximum likelihood where the weight of each token is automatically adjusted based on a discriminative meta-learning objective. A classification PLM can then be fine-tuned on both the few-shot and the synthetic samples with regularization for better generalization and stability. Our approach FewGen achieves an overall better result across seven classification tasks of the GLUE benchmark than existing few-shot learning methods, improving no-augmentation methods by 5+ average points, and outperforming augmentation methods by 3+ average points.
Few-Shot Fine-Grained Entity Typing with Automatic Label Interpretation and Instance Generation
Jun 28, 2022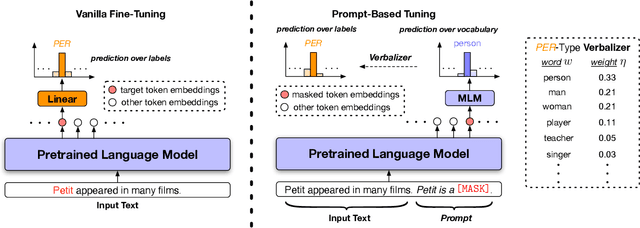
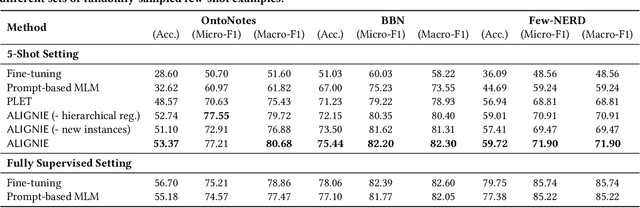
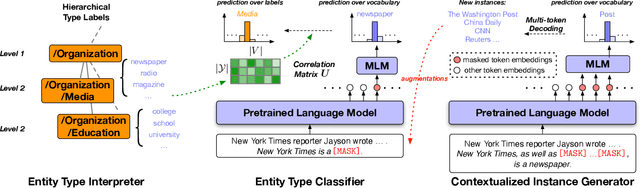
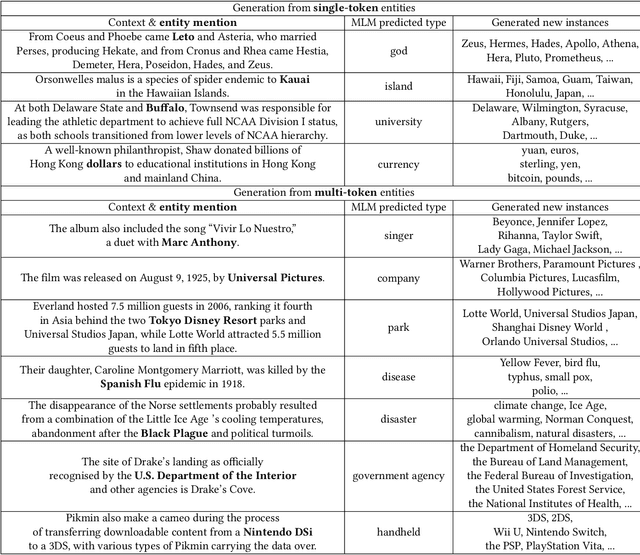
We study the problem of few-shot Fine-grained Entity Typing (FET), where only a few annotated entity mentions with contexts are given for each entity type. Recently, prompt-based tuning has demonstrated superior performance to standard fine-tuning in few-shot scenarios by formulating the entity type classification task as a ''fill-in-the-blank'' problem. This allows effective utilization of the strong language modeling capability of Pre-trained Language Models (PLMs). Despite the success of current prompt-based tuning approaches, two major challenges remain: (1) the verbalizer in prompts is either manually designed or constructed from external knowledge bases, without considering the target corpus and label hierarchy information, and (2) current approaches mainly utilize the representation power of PLMs, but have not explored their generation power acquired through extensive general-domain pre-training. In this work, we propose a novel framework for few-shot FET consisting of two modules: (1) an entity type label interpretation module automatically learns to relate type labels to the vocabulary by jointly leveraging few-shot instances and the label hierarchy, and (2) a type-based contextualized instance generator produces new instances based on given instances to enlarge the training set for better generalization. On three benchmark datasets, our model outperforms existing methods by significant margins. Code can be found at https://github.com/teapot123/Fine-Grained-Entity-Typing.
Seed-Guided Topic Discovery with Out-of-Vocabulary Seeds
May 04, 2022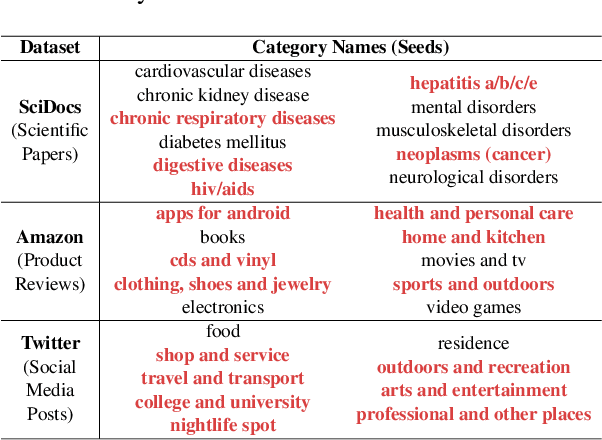
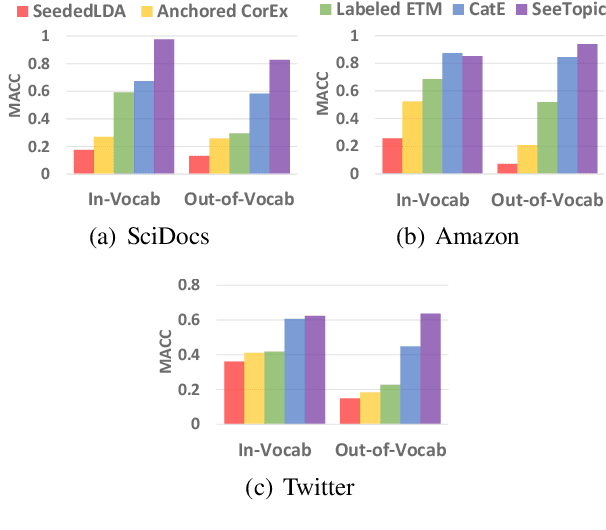
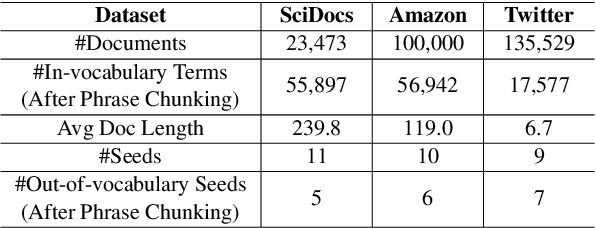
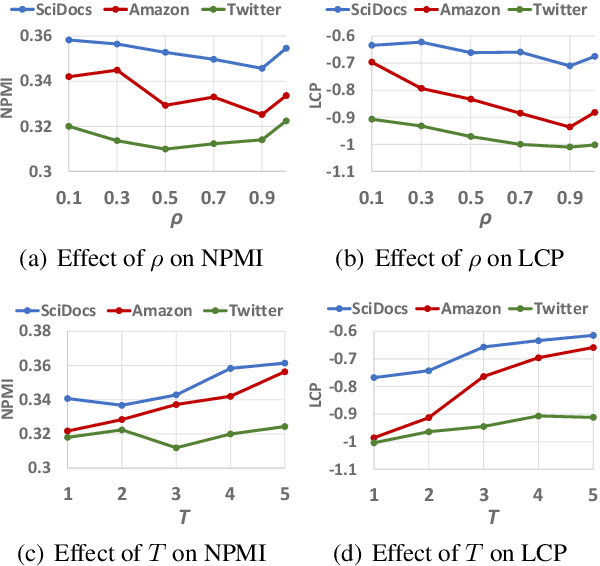
Discovering latent topics from text corpora has been studied for decades. Many existing topic models adopt a fully unsupervised setting, and their discovered topics may not cater to users' particular interests due to their inability of leveraging user guidance. Although there exist seed-guided topic discovery approaches that leverage user-provided seeds to discover topic-representative terms, they are less concerned with two factors: (1) the existence of out-of-vocabulary seeds and (2) the power of pre-trained language models (PLMs). In this paper, we generalize the task of seed-guided topic discovery to allow out-of-vocabulary seeds. We propose a novel framework, named SeeTopic, wherein the general knowledge of PLMs and the local semantics learned from the input corpus can mutually benefit each other. Experiments on three real datasets from different domains demonstrate the effectiveness of SeeTopic in terms of topic coherence, accuracy, and diversity.
Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators
Apr 07, 2022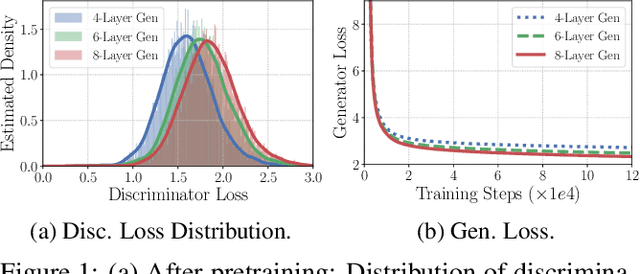
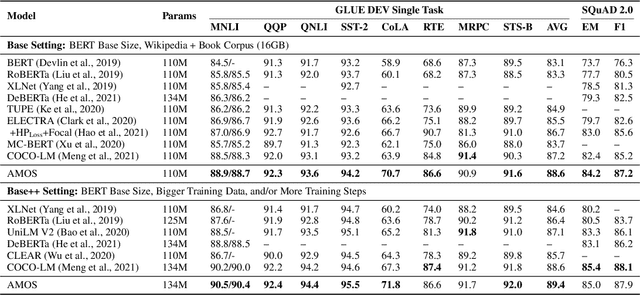
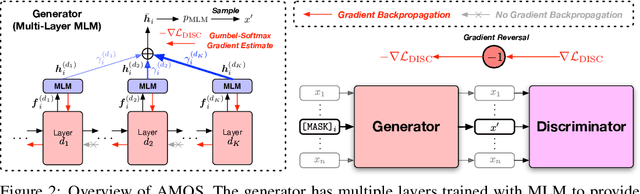
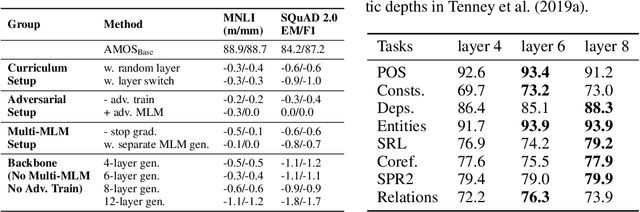
We present a new framework AMOS that pretrains text encoders with an Adversarial learning curriculum via a Mixture Of Signals from multiple auxiliary generators. Following ELECTRA-style pretraining, the main encoder is trained as a discriminator to detect replaced tokens generated by auxiliary masked language models (MLMs). Different from ELECTRA which trains one MLM as the generator, we jointly train multiple MLMs of different sizes to provide training signals at various levels of difficulty. To push the discriminator to learn better with challenging replaced tokens, we learn mixture weights over the auxiliary MLMs' outputs to maximize the discriminator loss by backpropagating the gradient from the discriminator via Gumbel-Softmax. For better pretraining efficiency, we propose a way to assemble multiple MLMs into one unified auxiliary model. AMOS outperforms ELECTRA and recent state-of-the-art pretrained models by about 1 point on the GLUE benchmark for BERT base-sized models.
Topic Discovery via Latent Space Clustering of Pretrained Language Model Representations
Feb 09, 2022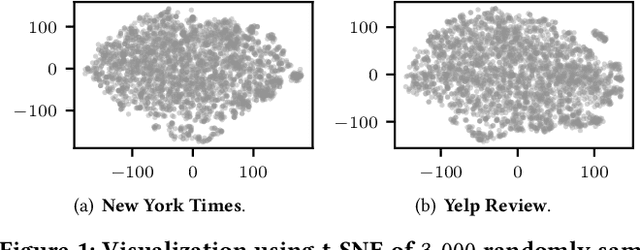
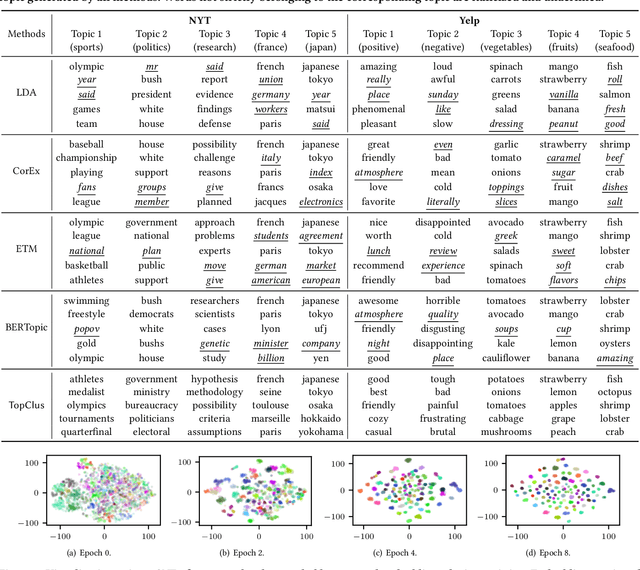
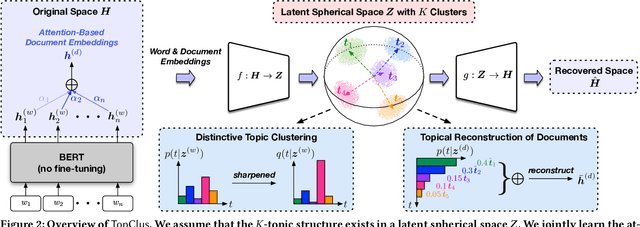
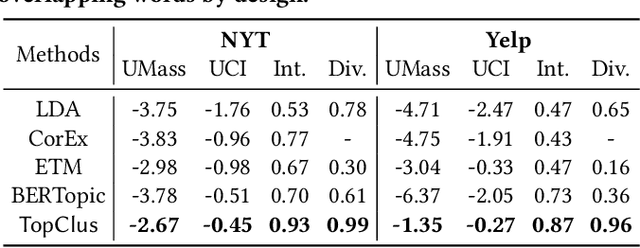
Topic models have been the prominent tools for automatic topic discovery from text corpora. Despite their effectiveness, topic models suffer from several limitations including the inability of modeling word ordering information in documents, the difficulty of incorporating external linguistic knowledge, and the lack of both accurate and efficient inference methods for approximating the intractable posterior. Recently, pretrained language models (PLMs) have brought astonishing performance improvements to a wide variety of tasks due to their superior representations of text. Interestingly, there have not been standard approaches to deploy PLMs for topic discovery as better alternatives to topic models. In this paper, we begin by analyzing the challenges of using PLM representations for topic discovery, and then propose a joint latent space learning and clustering framework built upon PLM embeddings. In the latent space, topic-word and document-topic distributions are jointly modeled so that the discovered topics can be interpreted by coherent and distinctive terms and meanwhile serve as meaningful summaries of the documents. Our model effectively leverages the strong representation power and superb linguistic features brought by PLMs for topic discovery, and is conceptually simpler than topic models. On two benchmark datasets in different domains, our model generates significantly more coherent and diverse topics than strong topic models, and offers better topic-wise document representations, based on both automatic and human evaluations.
Generating Training Data with Language Models: Towards Zero-Shot Language Understanding
Feb 09, 2022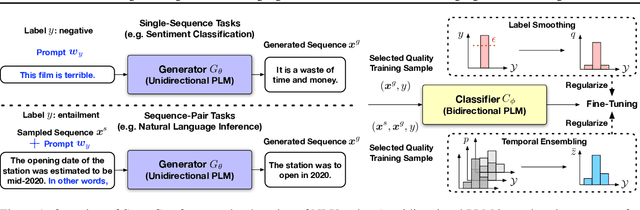
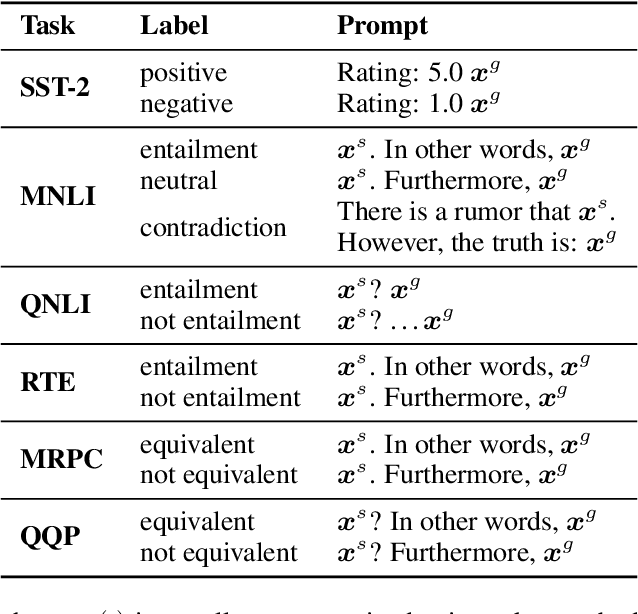
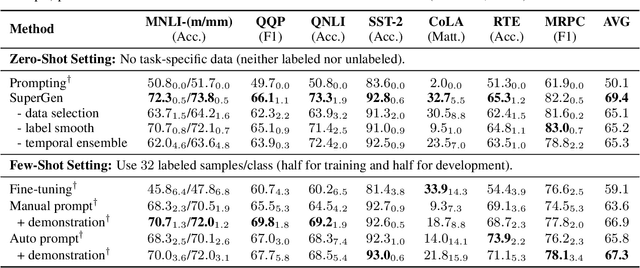
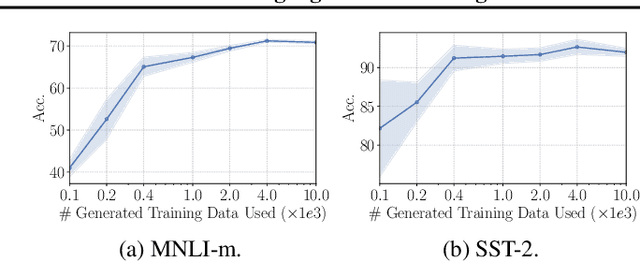
Pretrained language models (PLMs) have demonstrated remarkable performance in various natural language processing tasks: Unidirectional PLMs (e.g., GPT) are well known for their superior text generation capabilities; bidirectional PLMs (e.g., BERT) have been the prominent choice for natural language understanding (NLU) tasks. While both types of models have achieved promising few-shot learning performance, their potential for zero-shot learning has been underexplored. In this paper, we present a simple approach that uses both types of PLMs for fully zero-shot learning of NLU tasks without requiring any task-specific data: A unidirectional PLM generates class-conditioned texts guided by prompts, which are used as the training data for fine-tuning a bidirectional PLM. With quality training data selected based on the generation probability and regularization techniques (label smoothing and temporal ensembling) applied to the fine-tuning stage for better generalization and stability, our approach demonstrates strong performance across seven classification tasks of the GLUE benchmark (e.g., 72.3/73.8 on MNLI-m/mm and 92.8 on SST-2), significantly outperforming zero-shot prompting methods and achieving even comparable results to strong few-shot approaches using 32 training samples per class.
Pedestrian Trajectory Prediction via Spatial Interaction Transformer Network
Dec 13, 2021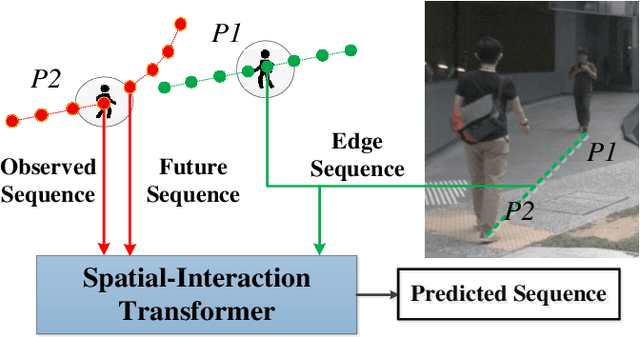
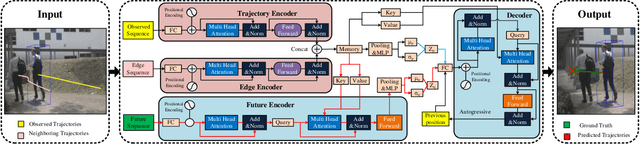
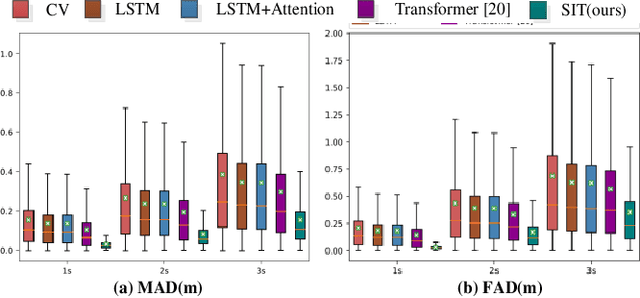
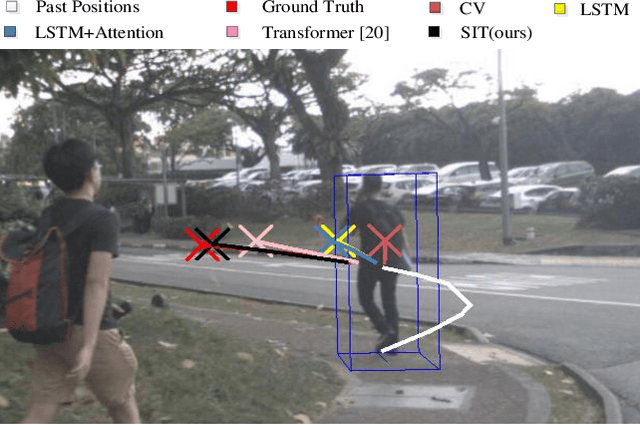
As a core technology of the autonomous driving system, pedestrian trajectory prediction can significantly enhance the function of active vehicle safety and reduce road traffic injuries. In traffic scenes, when encountering with oncoming people, pedestrians may make sudden turns or stop immediately, which often leads to complicated trajectories. To predict such unpredictable trajectories, we can gain insights into the interaction between pedestrians. In this paper, we present a novel generative method named Spatial Interaction Transformer (SIT), which learns the spatio-temporal correlation of pedestrian trajectories through attention mechanisms. Furthermore, we introduce the conditional variational autoencoder (CVAE) framework to model the future latent motion states of pedestrians. In particular, the experiments based on large-scale trafc dataset nuScenes [2] show that SIT has an outstanding performance than state-of-the-art (SOTA) methods. Experimental evaluation on the challenging ETH and UCY datasets conrms the robustness of our proposed model