 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Proof Generation via Iterative Backward Reasoning
May 24, 2022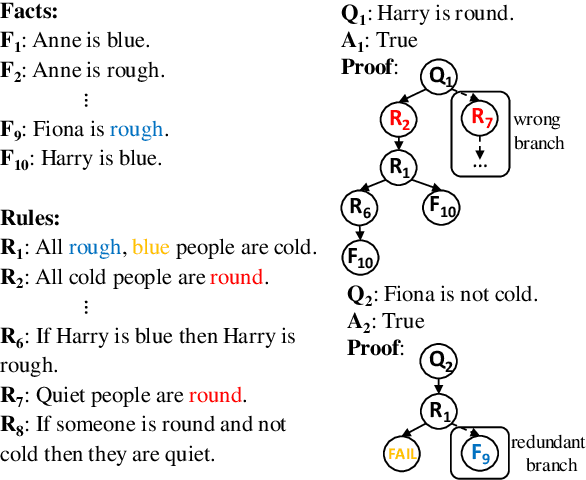
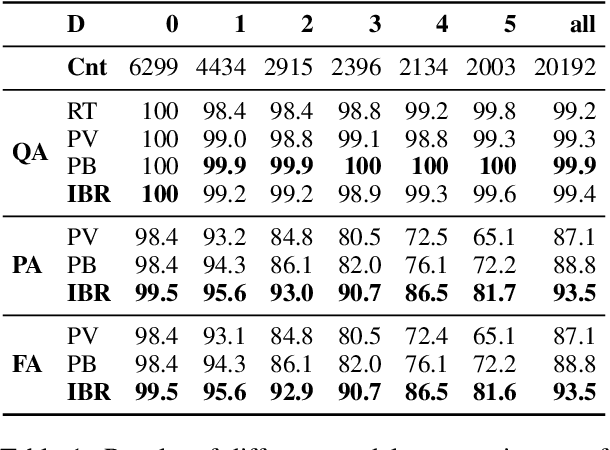
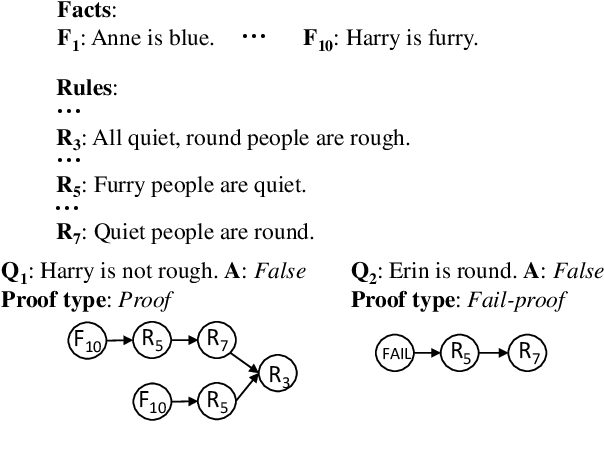
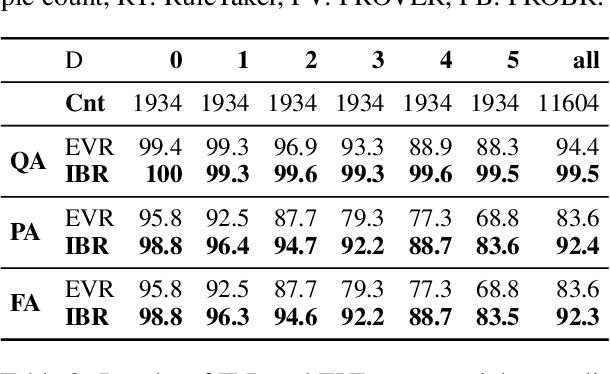
We present IBR, an Iterative Backward Reasoning model to solve the proof generation tasks on rule-based Question Answering (QA), where models are required to reason over a series of textual rules and facts to find out the related proof path and derive the final answer. We handle the limitations of existed works in two folds: 1) enhance the interpretability of reasoning procedures with detailed tracking, by predicting nodes and edges in the proof path iteratively backward from the question; 2) promote the efficiency and accuracy via reasoning on the elaborate representations of nodes and history paths, without any intermediate texts that may introduce external noise during proof generation. There are three main modules in IBR, QA and proof strategy prediction to obtain the answer and offer guidance for the following procedure; parent node prediction to determine a node in the existing proof that a new child node will link to; child node prediction to find out which new node will be added to the proof. Experiments on both synthetic and paraphrased datasets demonstrate that IBR has better in-domain performance as well as cross-domain transferability than several strong baselines. Our code and models are available at https://github.com/find-knowledge/IBR .
Phrase-level Textual Adversarial Attack with Label Preservation
May 24, 2022
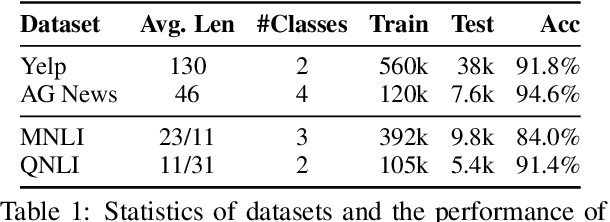
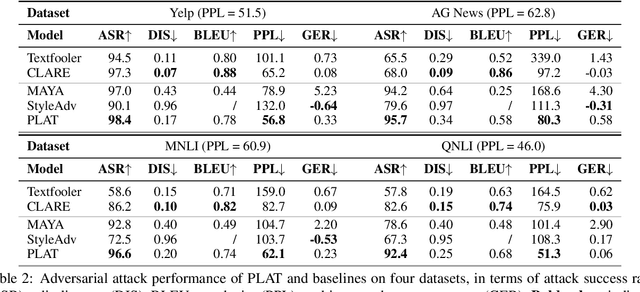
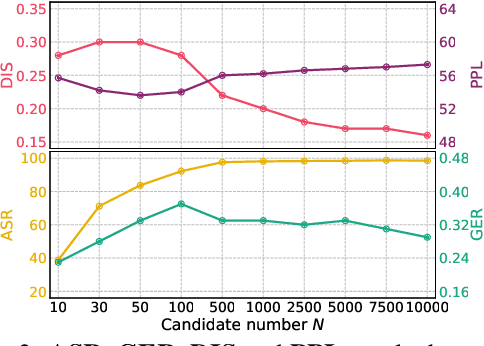
Generating high-quality textual adversarial examples is critical for investigating the pitfalls of natural language processing (NLP) models and further promoting their robustness. Existing attacks are usually realized through word-level or sentence-level perturbations, which either limit the perturbation space or sacrifice fluency and textual quality, both affecting the attack effectiveness. In this paper, we propose Phrase-Level Textual Adversarial aTtack (PLAT) that generates adversarial samples through phrase-level perturbations. PLAT first extracts the vulnerable phrases as attack targets by a syntactic parser, and then perturbs them by a pre-trained blank-infilling model. Such flexible perturbation design substantially expands the search space for more effective attacks without introducing too many modifications, and meanwhile maintaining the textual fluency and grammaticality via contextualized generation using surrounding texts. Moreover, we develop a label-preservation filter leveraging the likelihoods of language models fine-tuned on each class, rather than textual similarity, to rule out those perturbations that potentially alter the original class label for humans. Extensive experiments and human evaluation demonstrate that PLAT has a superior attack effectiveness as well as a better label consistency than strong baselines.
COIN: Communication-Aware In-Memory Acceleration for Graph Convolutional Networks
May 15, 2022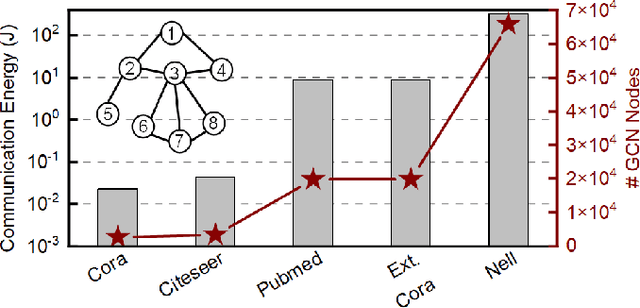
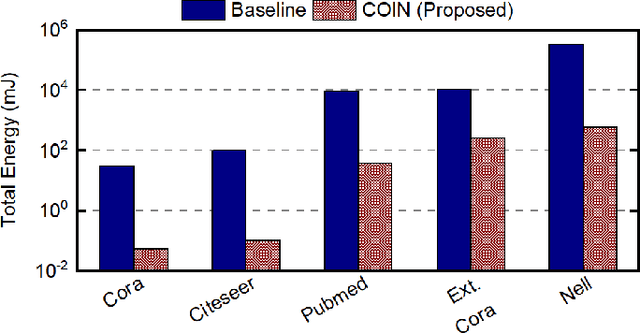
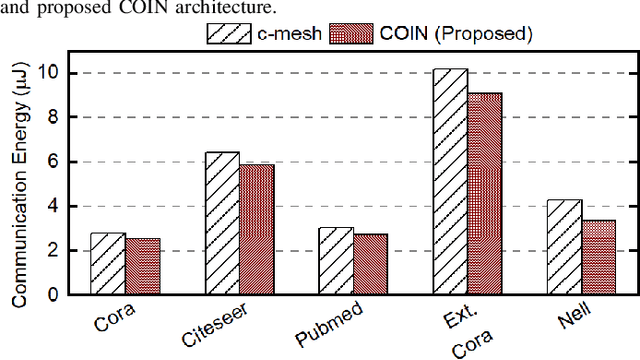
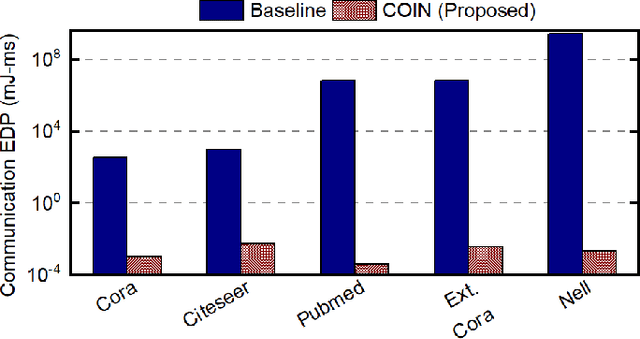
Graph convolutional networks (GCNs) have shown remarkable learning capabilities when processing graph-structured data found inherently in many application areas. GCNs distribute the outputs of neural networks embedded in each vertex over multiple iterations to take advantage of the relations captured by the underlying graphs. Consequently, they incur a significant amount of computation and irregular communication overheads, which call for GCN-specific hardware accelerators. To this end, this paper presents a communication-aware in-memory computing architecture (COIN) for GCN hardware acceleration. Besides accelerating the computation using custom compute elements (CE) and in-memory computing, COIN aims at minimizing the intra- and inter-CE communication in GCN operations to optimize the performance and energy efficiency. Experimental evaluations with widely used datasets show up to 105x improvement in energy consumption compared to state-of-the-art GCN accelerator.
A Model-Agnostic Data Manipulation Method for Persona-based Dialogue Generation
Apr 21, 2022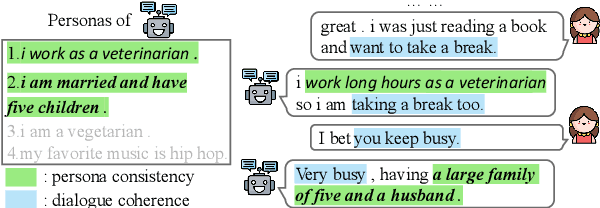
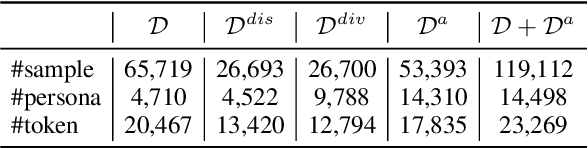
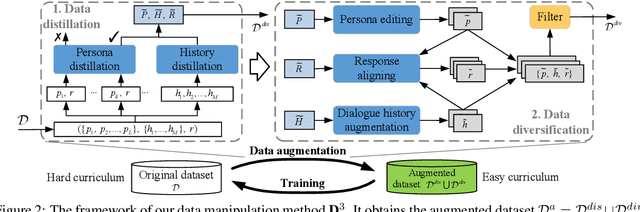
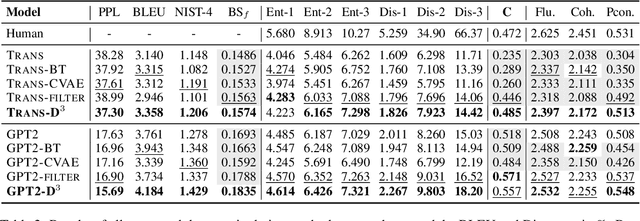
Towards building intelligent dialogue agents, there has been a growing interest in introducing explicit personas in generation models. However, with limited persona-based dialogue data at hand, it may be difficult to train a dialogue generation model well. We point out that the data challenges of this generation task lie in two aspects: first, it is expensive to scale up current persona-based dialogue datasets; second, each data sample in this task is more complex to learn with than conventional dialogue data. To alleviate the above data issues, we propose a data manipulation method, which is model-agnostic to be packed with any persona-based dialogue generation model to improve its performance. The original training samples will first be distilled and thus expected to be fitted more easily. Next, we show various effective ways that can diversify such easier distilled data. A given base model will then be trained via the constructed data curricula, i.e. first on augmented distilled samples and then on original ones. Experiments illustrate the superiority of our method with two strong base dialogue models (Transformer encoder-decoder and GPT2).
Bridging Cross-Lingual Gaps During Leveraging the Multilingual Sequence-to-Sequence Pretraining for Text Generation
Apr 16, 2022
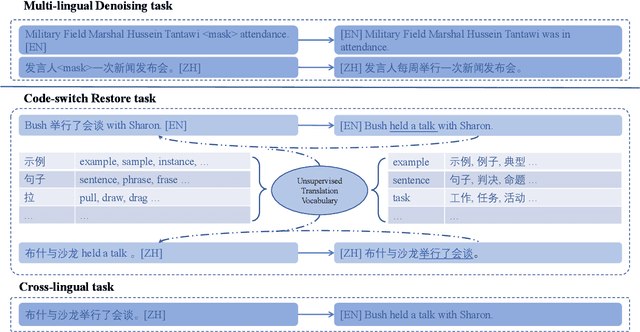
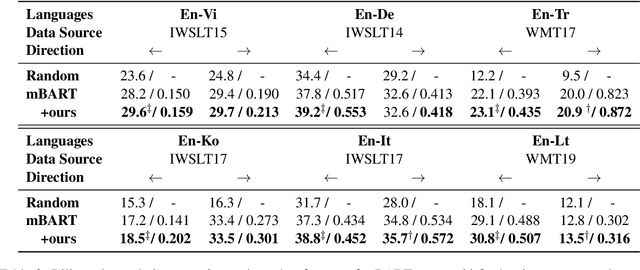
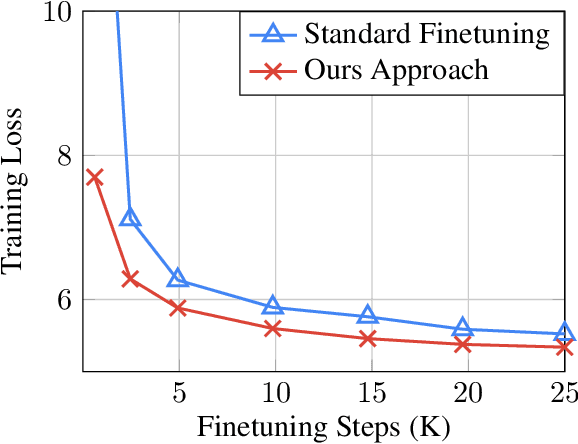
For multilingual sequence-to-sequence pretrained language models (multilingual Seq2Seq PLMs), e.g. mBART, the self-supervised pretraining task is trained on a wide range of monolingual languages, e.g. 25 languages from commoncrawl, while the downstream cross-lingual tasks generally progress on a bilingual language subset, e.g. English-German, making there exists the cross-lingual data discrepancy, namely \textit{domain discrepancy}, and cross-lingual learning objective discrepancy, namely \textit{task discrepancy}, between the pretrain and finetune stages. To bridge the above cross-lingual domain and task gaps, we extend the vanilla pretrain-finetune pipeline with extra code-switching restore task. Specifically, the first stage employs the self-supervised code-switching restore task as a pretext task, allowing the multilingual Seq2Seq PLM to acquire some in-domain alignment information. And for the second stage, we continuously fine-tune the model on labeled data normally. Experiments on a variety of cross-lingual NLG tasks, including 12 bilingual translation tasks, 36 zero-shot translation tasks, and cross-lingual summarization tasks show our model outperforms the strong baseline mBART consistently. Comprehensive analyses indicate our approach could narrow the cross-lingual sentence representation distance and improve low-frequency word translation with trivial computational cost.
Dual-CLVSA: a Novel Deep Learning Approach to Predict Financial Markets with Sentiment Measurements
Jan 27, 2022



It is a challenging task to predict financial markets. The complexity of this task is mainly due to the interaction between financial markets and market participants, who are not able to keep rational all the time, and often affected by emotions such as fear and ecstasy. Based on the state-of-the-art approach particularly for financial market predictions, a hybrid convolutional LSTM Based variational sequence-to-sequence model with attention (CLVSA), we propose a novel deep learning approach, named dual-CLVSA, to predict financial market movement with both trading data and the corresponding social sentiment measurements, each through a separate sequence-to-sequence channel. We evaluate the performance of our approach with backtesting on historical trading data of SPDR SP 500 Trust ETF over eight years. The experiment results show that dual-CLVSA can effectively fuse the two types of data, and verify that sentiment measurements are not only informative for financial market predictions, but they also contain extra profitable features to boost the performance of our predicting system.
A Knowledge-Based Decision Support System for In Vitro Fertilization Treatment
Jan 27, 2022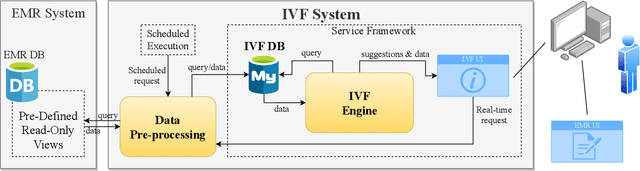
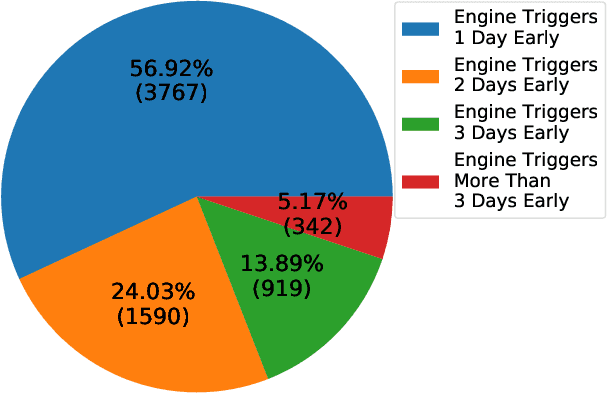
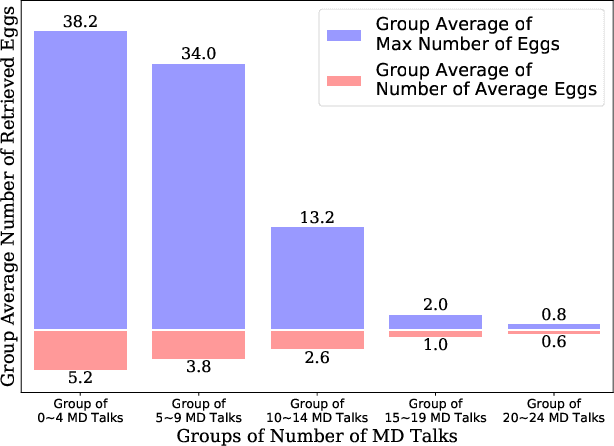
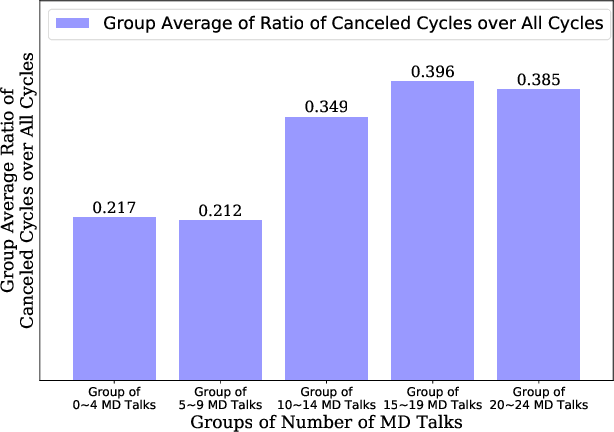
In Vitro Fertilization (IVF) is the most widely used Assisted Reproductive Technology (ART). IVF usually involves controlled ovarian stimulation, oocyte retrieval, fertilization in the laboratory with subsequent embryo transfer. The first two steps correspond with follicular phase of females and ovulation in their menstrual cycle. Therefore, we refer to it as the treatment cycle in our paper. The treatment cycle is crucial because the stimulation medications in IVF treatment are applied directly on patients. In order to optimize the stimulation effects and lower the side effects of the stimulation medications, prompt treatment adjustments are in need. In addition, the quality and quantity of the retrieved oocytes have a significant effect on the outcome of the following procedures. To improve the IVF success rate, we propose a knowledge-based decision support system that can provide medical advice on the treatment protocol and medication adjustment for each patient visit during IVF treatment cycle. Our system is efficient in data processing and light-weighted which can be easily embedded into electronic medical record systems. Moreover, an oocyte retrieval oriented evaluation demonstrates that our system performs well in terms of accuracy of advice for the protocols and medications.
Swin-Pose: Swin Transformer Based Human Pose Estimation
Jan 19, 2022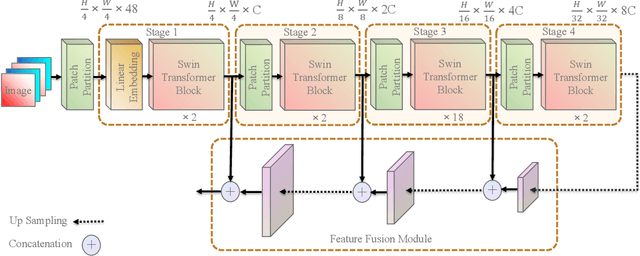
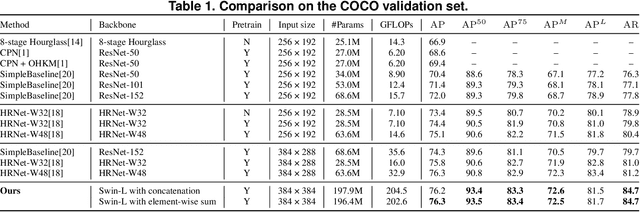
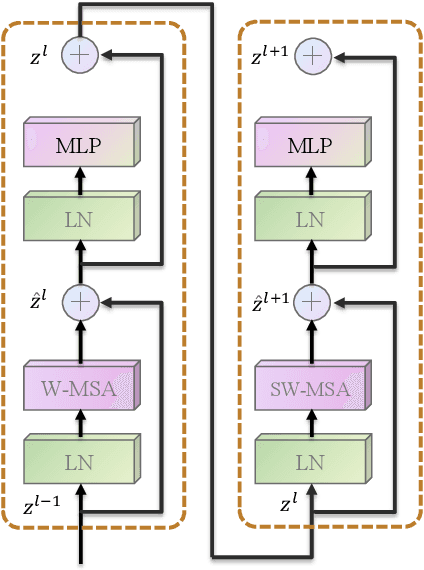
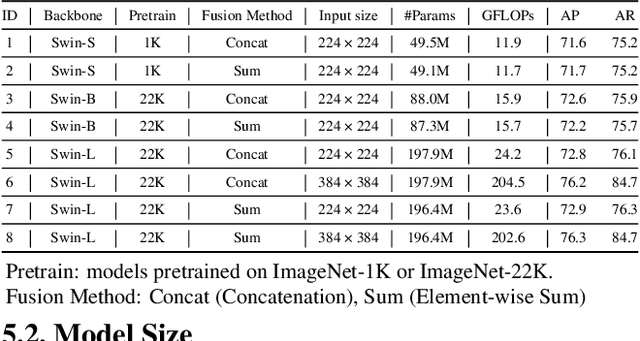
Convolutional neural networks (CNNs) have been widely utilized in many computer vision tasks. However, CNNs have a fixed reception field and lack the ability of long-range perception, which is crucial to human pose estimation. Due to its capability to capture long-range dependencies between pixels, transformer architecture has been adopted to computer vision applications recently and is proven to be a highly effective architecture. We are interested in exploring its capability in human pose estimation, and thus propose a novel model based on transformer architecture, enhanced with a feature pyramid fusion structure. More specifically, we use pre-trained Swin Transformer as our backbone and extract features from input images, we leverage a feature pyramid structure to extract feature maps from different stages. By fusing the features together, our model predicts the keypoint heatmap. The experiment results of our study have demonstrated that the proposed transformer-based model can achieve better performance compared to the state-of-the-art CNN-based models.
A Joint Beamforming Design and Integrated CPM-LFM Signal for Dual-functional Radar-communication Systems
Dec 18, 2021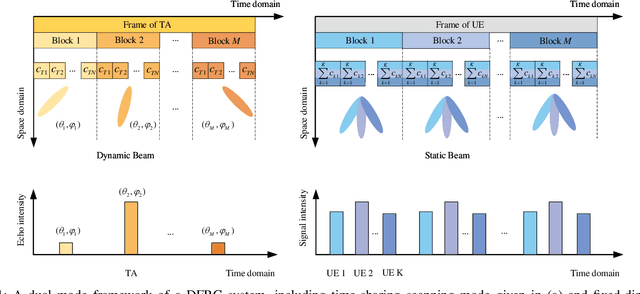
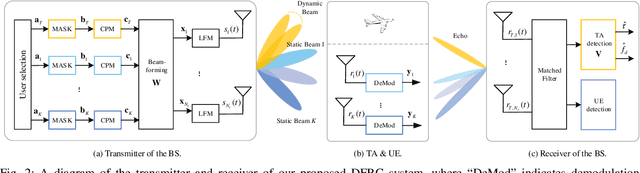
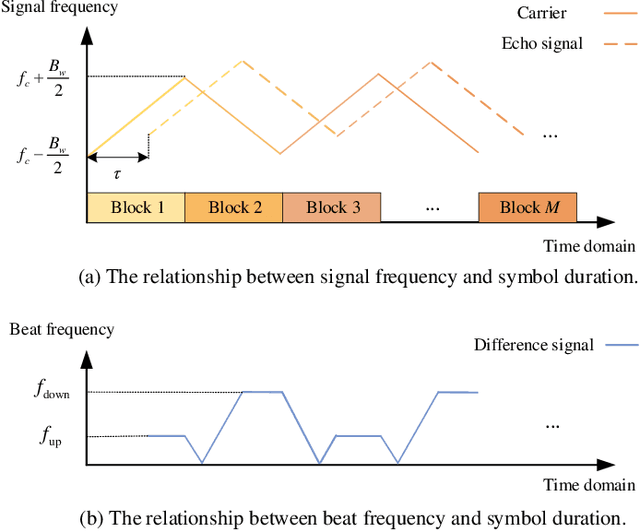
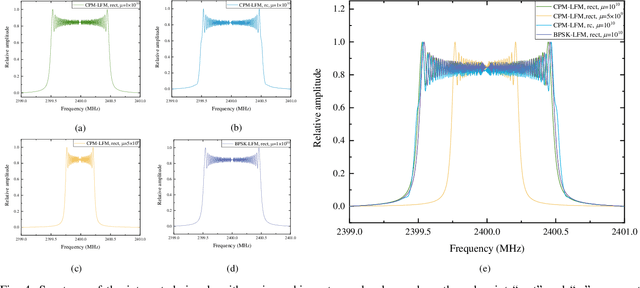
The dual-functional radar-communication (DFRC) system is an attractive technique, since it can support both wireless communications and radar by a unified hardware platform with real-time cooperation. Considering the appealing feature of multiple beams, this paper proposes a precoding scheme that simultaneously support multiuser transmission and target detection, with an integrated continuous phase modulation (CPM) and linear frequency modulation (LFM) signal, based on the designed dual mode framework. Similarly to the conception of communication rate, this paper defines radar rate to unify the DFRC system. Then, the maximum sum-rate that includes both the communication and radar rates is set to be the objective function. Regarding as the optimal issue is non-convex, the optimal problem is divided into two sub-issues, one is the user selection issue, and the other is the joint beamforming design and power allocation issue. A successive maximum iteration (SMI) algorithm is presented for the former issue, which can balance the performances between the sum-rate and complexity; and maximum minimization Lagrange multiplier (MMLM) iteration algorithm is utilized to solve the latter optimal issue. Moreover, we deduce the spectrum characteristic, bit error rate (BER) and ambiguity function (AF) for the proposed system. Simulation results show that our proposed system can provide appreciated sum-rate than the classical schemes, validating the efficiency of the proposed system.
Gradient-based Novelty Detection Boosted by Self-supervised Binary Classification
Dec 18, 2021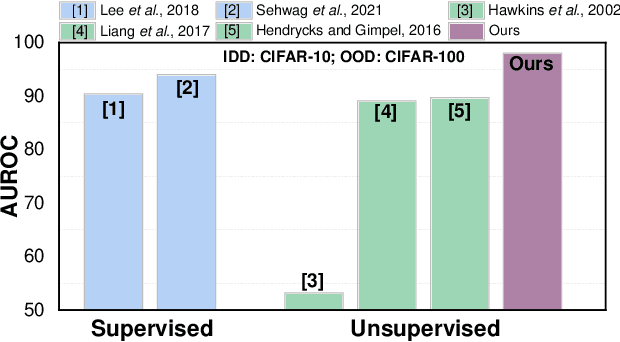
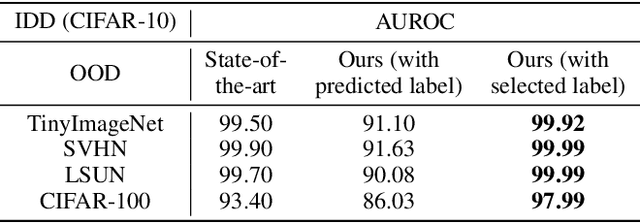
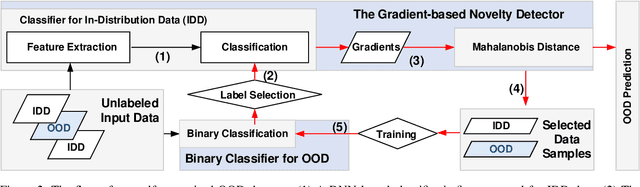
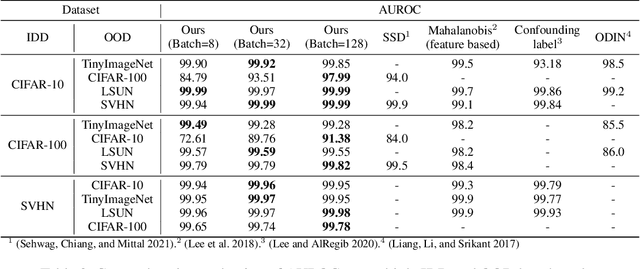
Novelty detection aims to automatically identify out-of-distribution (OOD) data, without any prior knowledge of them. It is a critical step in data monitoring, behavior analysis and other applications, helping enable continual learning in the field. Conventional methods of OOD detection perform multi-variate analysis on an ensemble of data or features, and usually resort to the supervision with OOD data to improve the accuracy. In reality, such supervision is impractical as one cannot anticipate the anomalous data. In this paper, we propose a novel, self-supervised approach that does not rely on any pre-defined OOD data: (1) The new method evaluates the Mahalanobis distance of the gradients between the in-distribution and OOD data. (2) It is assisted by a self-supervised binary classifier to guide the label selection to generate the gradients, and maximize the Mahalanobis distance. In the evaluation with multiple datasets, such as CIFAR-10, CIFAR-100, SVHN and TinyImageNet, the proposed approach consistently outperforms state-of-the-art supervised and unsupervised methods in the area under the receiver operating characteristic (AUROC) and area under the precision-recall curve (AUPR) metrics. We further demonstrate that this detector is able to accurately learn one OOD class in continual learning.